The value of an expression is the single result you get when you replace variables with known quantities and then carry out the operations in the correct order. In practice, that means substitution first, then a disciplined evaluation sequence so the formula resolves to one definitive answer.
If you're working in a lab, this doesn't feel like a school exercise. It feels like the spreadsheet cell that drives a formulation decision, the script that transforms instrument output into model features, or the property calculation that determines whether a sample moves forward. A tiny mistake in how an expression is evaluated can push a team toward the wrong experiment, the wrong conclusion, or the wrong training data.
That is why the question "what is the value of expression" matters far beyond algebra. In materials R&D, the value of an expression is where abstract notation meets operational reality. If that value is wrong, your downstream analysis is wrong too. And once incorrect calculated values enter a pipeline, they become hard to detect because they often still look plausible.
Table of Contents
From Formulas to Formulations Why Expressions Matter
A formulation scientist pulls density, viscosity, and composition data into a spreadsheet. The sheet contains a derived property formula with nested terms, a correction factor, and a normalization step. The result looks reasonable, so the team uses it to choose the next set of experiments.
Later, the result can't be reproduced. The issue isn't the instrument. It isn't the chemistry. A parenthesis in the spreadsheet formula grouped the wrong terms, so the expression was evaluated differently from the method described in the protocol.
That kind of failure is common because expression errors rarely announce themselves. They don't always produce nonsense. More often, they produce a neat-looking number that survives long enough to influence decisions.
When a small calculation error becomes a research problem
In R&D, expressions sit everywhere:
- In spreadsheets: cell formulas convert raw readings into reported properties.
- In scripts: Python or R code computes engineered features for models.
- In reports: equations summarize test methods and acceptance criteria.
- In automation: pipelines transform instrument exports into structured datasets.
Each of those systems asks the same underlying question. Given an expression, what value does it produce under these inputs?
Practical rule: If a formula affects a go or no-go decision, nobody should treat its evaluation as obvious.
The stakes rise when teams work across tools. One scientist may write the formula in a notebook, another may implement it in Excel, and a third may rebuild it in code for model training. If those implementations don't evaluate the expression the same way, the organization creates multiple versions of the truth.
Why this matters for AI-driven discovery
AI models don't rescue bad calculated values. They absorb them. If a training set contains inconsistently evaluated expressions, the model learns from noise that looks structured. That weakens interpretability and makes later debugging expensive.
For materials R&D, data integrity starts before the model. It starts at the level of every expression that turns observations into usable variables. Teams that master this basic discipline usually move faster because they spend less time reconciling contradictory outputs and more time interpreting results that hold up.
The Core Concept An Expression and Its Value
An expression is a formal statement built from quantities and operations. The value of that expression is the single output you get when the statement is evaluated correctly. That distinction sounds simple, but many workflow errors come from blending the two ideas together.
A formula on a page is not the result. A line of code is not the result. A spreadsheet cell formula is not the result. Those are expressions. The value appears only after evaluation.
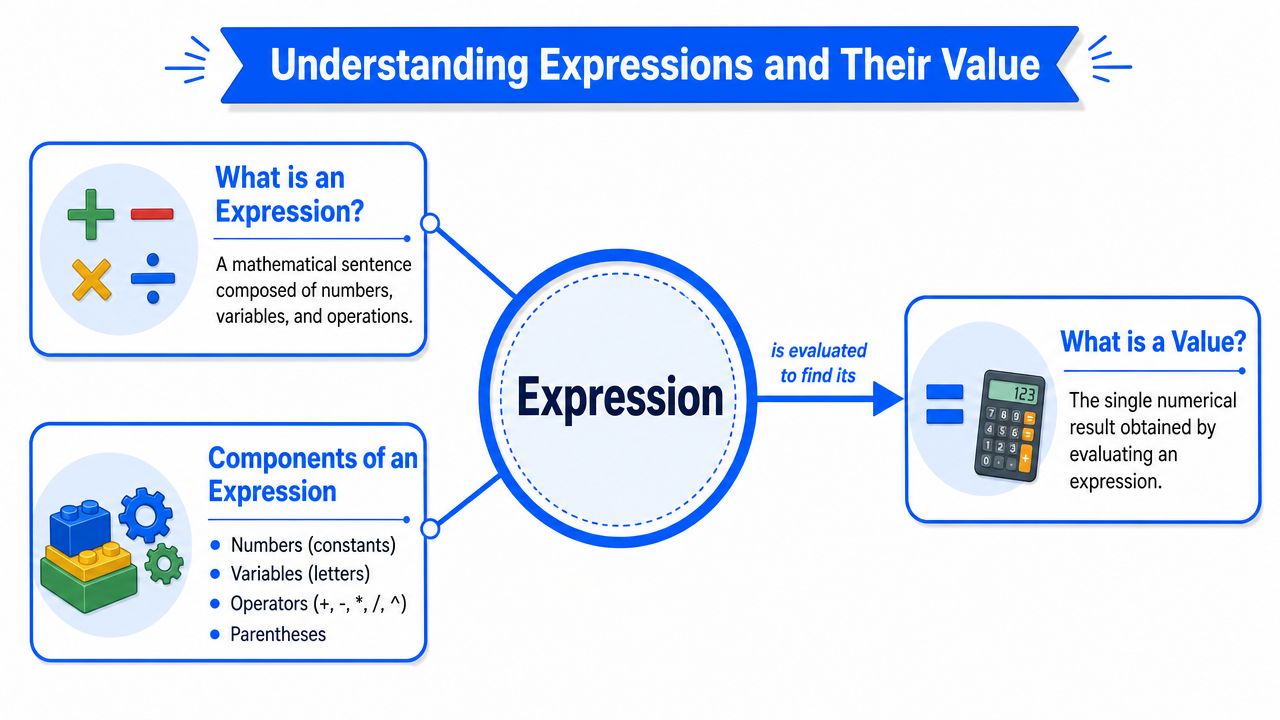
What counts as an expression
An expression can contain several kinds of parts:
- Constants: fixed quantities such as whole numbers, decimals, or known coefficients.
- Variables: symbols that stand for values, such as temperature, concentration, or time.
- Operators: actions such as addition, subtraction, multiplication, and division.
- Functions: named operations such as logarithms or trigonometric functions.
- Grouping symbols: parentheses or brackets that control evaluation.
A useful way to think about it is as a recipe. The expression lists ingredients and instructions. The value is the finished dish. If the ingredients change, or if the instructions are followed in the wrong sequence, the outcome changes too.
Why the value is a separate idea
That separation matters in both math and computation. From a computer-science perspective, an expression is a syntactic entity that can be evaluated to a value or remain undefined, and the result may be a primitive type such as an integer, floating-point number, Boolean, or string, as described in the computer-science definition of expressions). That broader view is useful in scientific work because modern R&D teams don't evaluate expressions only by hand. They evaluate them in software systems that may return different kinds of outputs.
An expression is the instruction. The value is the resolved outcome.
In the lab, that difference shows up constantly. A formula for a derived property is an expression. Once you feed in the measured inputs and evaluate it, you get a value that can enter a database, a control chart, or a model feature table.
If you're trying to answer what is the value of expression, the clean answer is this: it is the final resolved output of a symbolic statement after the required inputs and operations have been handled correctly. The phrase sounds elementary, but the discipline behind it is what makes calculated data trustworthy.
Evaluating Expressions A Universal Step-by-Step Method
The most reliable way to evaluate an expression is boring on purpose. You substitute known values, follow the order of operations exactly, and verify the result in a second form when the calculation matters. That's how you avoid ambiguity.
A standard algebra workflow defines the process this way: substitute the given variable values and then apply order of operations, emphasizing parentheses, exponents, multiplication and division, then addition and subtraction. That sequence is described in this explanation of evaluating expressions and PEMDAS.
For teams working across notebooks, spreadsheets, and scripts, that sequence is more than classroom procedure. It's a reproducibility protocol.
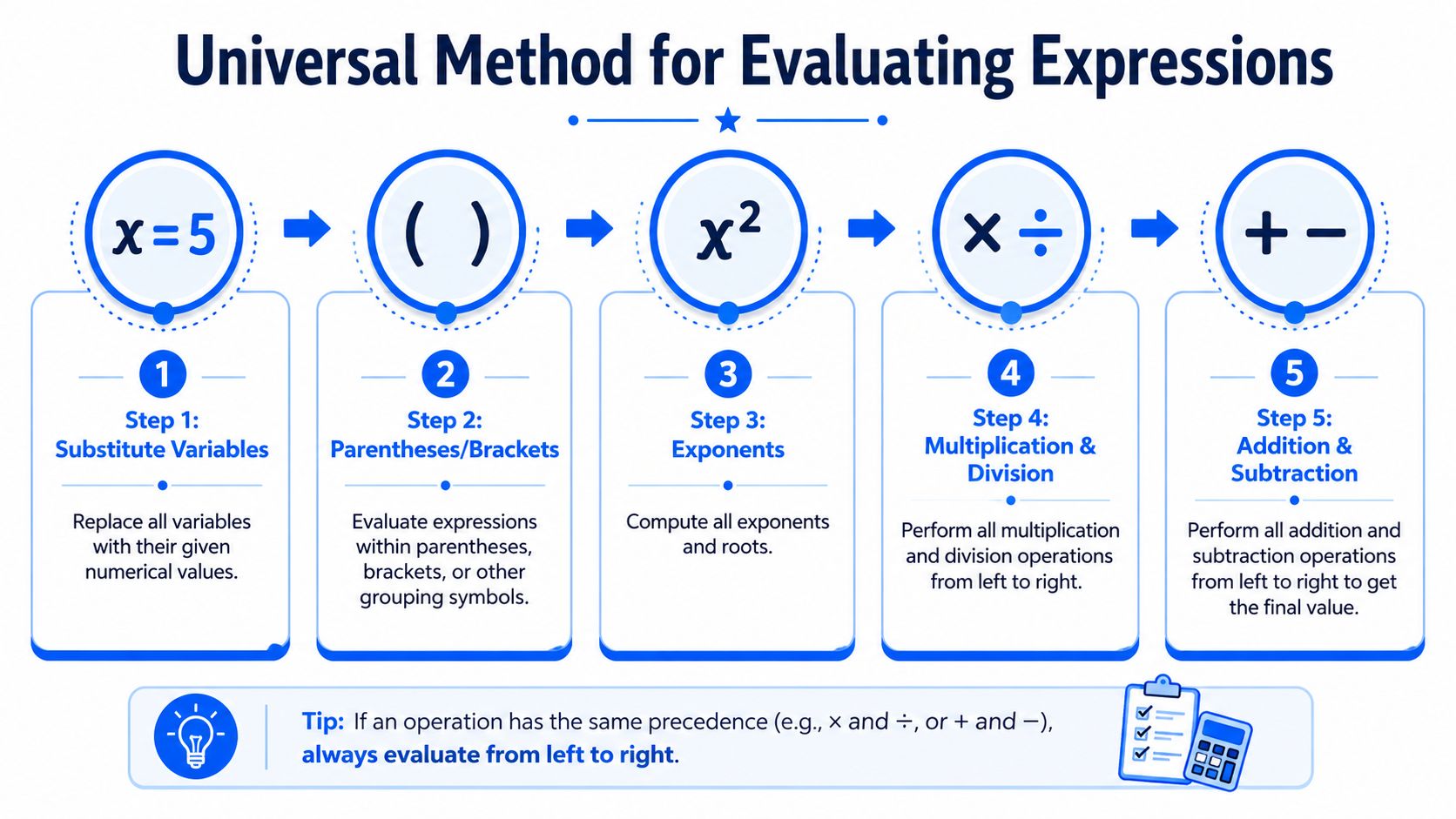
Start with substitution
Before doing any arithmetic, replace every variable with its actual value. Don't mix symbolic and numeric forms casually if you're checking a result by hand. Write the substituted expression out fully.
In lab work, this is also where unit discipline starts. If one variable is recorded in one unit system and another in a different one, substitution without conversion creates a formally evaluated result that is still scientifically wrong.
A practical workflow looks like this:
- List each input explicitly: write the variable name beside the measured quantity.
- Confirm the units: make sure the values belong in the formula as written.
- Rewrite the full expression: don't skip straight to keystrokes in a calculator.
Apply order with no shortcuts
Once the variables are in place, evaluate in the prescribed order. Parentheses come first. Then exponents. Then multiplication and division. Finally, addition and subtraction.
That sequence matters because many expressions can be interpreted more than one way if grouping isn't respected. Software tools often have fixed precedence rules, but human readers still make mistakes when formulas are copied between systems.
Here's a simple scientific-style example. Suppose a derived metric is written as:
(temperature correction + baseline factor) × concentration
If the correction term and baseline factor must be combined before scaling by concentration, dropping the parentheses changes the meaning of the formula. The value you get may still look smooth across a dataset, which is why these errors are dangerous.
A short visual explanation helps when training teams on this evaluation sequence:
Check yourself: if two people could read the same formula and reasonably perform different first operations, the expression needs clearer grouping.
Use a repeatable check
For critical calculations, one pass isn't enough. Use a second check that differs from the first implementation.
Good options include:
- Manual spot check: evaluate a few rows by hand.
- Alternate tool check: compare spreadsheet output with a small Python or R script.
- Boundary check: test the expression with extreme but valid inputs.
- Null behavior check: confirm what happens when an expected input is missing or undefined.
What works is redundancy with intent. What doesn't work is re-running the same flawed spreadsheet and calling that validation.
When scientists ask what is the value of expression in a real workflow, they usually mean something deeper than "what number comes out?" They mean, "what result can the team defend, reproduce, and trace back to the original formula?" That answer only comes from a method that is explicit enough to survive handoff.
The Value of an Expression in Different Contexts
The core idea stays stable across domains. The implementation doesn't. A chemist solving a symbolic formula, a data scientist evaluating Python code, and an analyst building a spreadsheet model are all dealing with expressions, but the meaning of the resulting value changes with context.
A comparison across domains
| Domain | Example Expression | Nature of Value | Key Consideration |
|---|---|---|---|
| Math | A symbolic formula with variables | A resolved numerical result after evaluation | Precision in substitution and formal order |
| Code | A statement in Python or R | A computed output that may be numeric, Boolean, text, or undefined | Data types and execution rules |
| Spreadsheets | A cell formula referencing other cells | A dynamic result that updates as inputs change | Hidden dependencies and cell reference errors |
| R&D lab | A property equation using measured inputs | A derived scientific value used for decisions | Units, measurement quality, and method consistency |
In mathematics, the emphasis is symbolic clarity. The question is whether the expression resolves correctly from the stated variables and operations.
In code, the expression enters a stricter environment. The syntax must be valid, and the resulting value may control logic flow, filtering, or model behavior. A Boolean result can decide whether data gets included at all. A string result where a number was expected can break a pipeline or coerce incorrectly in the wrong direction.
Why context changes risk
Spreadsheets introduce a different failure mode. They make expressions feel accessible, but they also hide a lot. A formula may reference distant cells, named ranges, or copied logic that drifted over time. The value updates automatically, which is useful until nobody remembers the assumptions baked into the original cell.
Lab workflows add another layer. The expression may be mathematically fine and computationally valid, yet scientifically weak because inputs came from inconsistent methods or mixed unit conventions. In this environment, evaluating an expression isn't just arithmetic. It's method execution.
One place this shows up is external data ingestion. Teams often pull technical data from supplier pages, public repositories, or documentation systems before mapping those inputs into downstream expressions. If you're standardizing that step, tools like Scrapfly's web scraping API can help structure extraction workflows so the values entering your formulas are easier to normalize and audit.
The same expression logic can be correct in math, valid in code, and still fail in R&D because the measurement context wasn't controlled.
That is the operational lesson. The phrase "value of an expression" sounds universal because it is. But the reliability of that value depends on the domain-specific controls around how the expression is implemented, fed, and interpreted.
Common Mistakes and How to Avoid Them
Most expression errors don't come from advanced math. They come from ordinary habits: rushing substitution, trusting defaults, copying formulas without checking assumptions, and forgetting that software has opinions about types and precedence.

Errors that look harmless
The first class of mistakes is familiar. Someone evaluates multiplication before resolving grouped terms, or they substitute the wrong input into the right formula. Those are obvious in retrospect and still expensive in practice.
The more damaging class is subtle:
- Unit mismatch: the expression is evaluated exactly as written, but one input arrived in a different unit basis.
- Type mismatch: a spreadsheet or script treats a text value as if it were numeric, or vice versa.
- Floating-point assumptions: equality checks fail because computed values are close, not identical.
- Boundary mistakes: a loop, range, or subset omits the first or last valid case.
A spreadsheet #VALUE! error is at least visible. A coerced value that looks numeric is worse because it can pass unnoticed into reports or models.
Habits that prevent rework
The best defenses are procedural, not heroic. Teams don't need more cleverness here. They need more consistency.
- Use explicit parentheses: even when operator precedence would resolve the expression correctly, extra grouping improves readability and lowers copy errors.
- Audit input mapping: before evaluating, confirm that each variable is tied to the right column, cell, or field.
- Check units at the point of substitution: don't assume upstream conversion happened.
- Test edge cases: run the expression on minimum, maximum, missing, and unusual inputs.
- Separate display from calculation: formatted outputs can hide rounding or type issues that matter downstream.
"If a formula matters, rewrite it once in plain language and once in machine-readable form. Disagreement between the two versions usually reveals the bug."
What doesn't work is relying on familiarity. Scientists often trust expressions they've seen many times. That trust becomes a liability when the formula gets adapted for a new material system, a new data source, or a new toolchain.
A useful review habit is to ask three short questions before accepting a calculated value:
- Is the expression itself written unambiguously?
- Were the inputs substituted correctly, including units and types?
- Was the result checked independently in at least one alternate way?
That short audit catches a surprising amount of avoidable rework.
Ensuring Reproducibility in R&D Workflows
One correct calculation isn't enough. Teams need the same expression to yield the same defensible value every time, across people, projects, and systems. That is where reproducibility starts to matter more than convenience.
Spreadsheets remain useful for early exploration. They are fast, flexible, and familiar. But for recurring, high-consequence calculations, they age poorly because logic gets buried in cells, copied across tabs, and modified without a clean audit trail.
Why ad hoc calculation breaks down
A hand-built sheet can survive for a while on local knowledge. Then a scientist leaves, a method changes, or a model pipeline needs the same formula in code. At that point, the team discovers that the expression exists in several slightly different forms.
That fragmentation creates avoidable conflict. One version becomes the reporting standard, another feeds analytics, and a third sits in a lab template that no longer matches either. Everyone believes they are using the same formula. They aren't.

What reliable teams standardize
The fix is straightforward, even if implementation takes discipline. Put critical expressions into controlled systems and treat them like governed assets.
A strong workflow usually includes:
- Version-controlled scripts: define the formula once in Python or R and track every change.
- Documented assumptions: record units, variable meanings, valid ranges, and expected behavior for missing inputs.
- Reference test cases: keep a small set of known input-output examples to verify implementations.
- Review before release: have another scientist or engineer inspect the expression and its outputs.
- Centralized execution: calculate derived values in one trusted location rather than in scattered personal files.
Operational standard: If a calculated field affects scale-up, quality, or model training, it should be traceable from result back to expression and from expression back to method.
This isn't bureaucracy. It's how teams keep calculated data fit for reuse. Once an organization adopts that standard, expressions stop being hidden liabilities and become reusable building blocks for analytics, optimization, and AI.
Conclusion From Calculation to Insight
The value of an expression is the final result produced when a formula is evaluated correctly. That idea begins in algebra, but it becomes much more consequential in scientific work, where calculated values drive experiments, reports, and models.
The difference between an expression and its value is small in wording and enormous in practice. Expressions define the logic. Values become the evidence. If the evaluation process is sloppy, the evidence is compromised before anyone starts interpreting it.
For materials R&D teams, that makes expression handling a foundational discipline. Clean substitution, unambiguous grouping, careful implementation across tools, and reproducible calculation workflows all matter because every later insight depends on them.
AI doesn't change that. It raises the importance. Predictive systems only inherit what the data pipeline gives them. When teams evaluate expressions consistently and audit the resulting values, they create data that can support real scientific acceleration instead of polished confusion.
If your team is trying to move critical calculations out of fragmented spreadsheets and into a more auditable, AI-ready workflow, Polymerize is worth a look. It helps materials R&D organizations unify experimental data, standardize how derived values are generated, and build a cleaner foundation for property prediction, formulation optimization, and reproducible decision-making.

