Your team probably has the same problem I see across polymer R&D groups. Valuable knowledge sits in too many places at once: spreadsheets on shared drives, ELN entries with inconsistent naming, instrument files no one can search, simulation outputs disconnected from lab results, and scale-up notes trapped in email threads. Scientists still make decisions, but they often do it with partial context.
That's why “polymer software” has become a strategic topic rather than a niche IT purchase. The issue isn't just computation. It's whether your organization can turn polymer data into a repeatable decision system that helps scientists choose better experiments, explain outcomes, and transfer knowledge from one project to the next. The most useful platforms don't behave like point tools. They behave like systems of intelligence built on a reusable data backbone first, with modeling and AI layered on top.
Table of Contents
- A unified data backbone
- Predictive modeling that scientists can actually use
- Experiment planning instead of experiment accumulation
- Scale-up support and operational handoff
Beyond Trial-and-Error in Modern Polymer R&D
Most polymer organizations still say they want AI when what they need is continuity. They need a way to connect formulation history, processing conditions, characterization results, and simulation outputs so a scientist can answer a basic question without opening five systems. Until that exists, trial-and-error remains the default operating model.
The commercial stakes are high enough that this is no longer a lab-only issue. The global polymers market was valued at over USD 1.3 trillion in 2025 and is projected to reach USD 2.1 trillion by 2035 according to Research Nester's polymers market outlook. When the underlying market is that large, software that improves R&D decisions, knowledge reuse, and manufacturing readiness becomes part of enterprise strategy.

Why the pain shows up everywhere
In polymer work, data fragmentation hits harder than in many small-molecule settings because the material itself is more complicated. A polymer isn't a single fixed entity with one clean descriptor. It has distributions, additives, process history, and often multiple characterization methods that need to be interpreted together.
That's why teams get stuck in loops like these:
- Repeated experiments: Scientists rerun work because they can't find prior results in a usable form.
- Weak comparisons: Two samples look similar on paper, but the processing route or formulation details aren't captured consistently.
- Slow handoffs: Development teams struggle to transfer insight from discovery to scale-up because process context is incomplete.
- AI disappointment: Leaders buy prediction tools before they've created a clean, governed, connected data layer.
Practical rule: If your scientists still spend more time reconstructing context than analyzing results, you don't have an AI problem. You have a data architecture problem.
Why a system of intelligence matters
A point tool can solve one narrow task. A simulator predicts a property. A dashboard summarizes a project. An ELN records an experiment. Those are useful, but none of them creates organizational memory by itself.
A system of intelligence does something different. It captures the full chain from structure to process to property, keeps that chain searchable, and makes it available to both humans and models. That's the shift happening in polymer software now. The winning approach isn't “add AI to the mess.” It's “build the backbone that makes AI trustworthy and reusable.”
What Is Polymer Software Really
Polymer software isn't just a digital lab notebook with a prettier interface. It's purpose-built informatics infrastructure for representing polymer materials the way scientists work with them.
The easiest analogy is this: traditional data handling is like driving with scattered paper maps in the passenger seat. You can still reach the destination, but you're constantly stopping to reconcile conflicting information. Polymer software works more like a live navigation system. It brings structure notation, synthesis routes, processing history, properties, analytical outputs, and simulations into one environment so decisions happen with context, not guesswork.
From paper maps to a live navigation system
Good polymer software usually combines several layers that used to be separate:
- Representation layer that can describe polymer structures and formulations in polymer-native ways.
- Context layer that stores synthesis, processing, and test history.
- Analytics layer that connects characterization and simulation outputs.
- Decision layer that helps scientists choose the next experiment or rank candidate materials.
That combination matters because polymer R&D decisions are rarely driven by a single number. A resin may look promising until someone checks molecular-weight distribution, residual monomer, thermal behavior, or the exact compounding path used to make the sample. Generic systems tend to flatten that complexity. Polymer software should preserve it.
Why generic databases fall short
This isn't a new complaint. The field has already moved beyond the idea that ordinary chemistry databases are enough. A useful milestone was the 2023 publication of PolyDAT, described as a generic data schema for polymer characterization, reflecting recognition that polymer-specific tools are required for molecular-weight variability and complex distributions, as discussed in the ACS publication on polymer data schema and analysis tools.
That historical shift matters in practice. It means mature polymer software should already assume:
- Distributions matter more than single values in many workflows.
- Characterization is multi-modal, not one instrument and one output.
- Compliance and reporting fields are specialized for polymer materials.
- Searchability depends on polymer-native schema, not just filenames and tags.
A platform that stores polymer data like ordinary chemical records will eventually force your scientists to do the real integration work manually.
When buyers miss this point, they often evaluate polymer software the wrong way. They focus on visual dashboards or isolated AI features instead of asking whether the platform can represent the material faithfully. That's backwards. If the representation is weak, every prediction, query, and comparison built on top of it becomes less reliable.
Core Capabilities That Accelerate Innovation
The strongest polymer software platforms create value in four places at once. They organize messy data, support prediction, guide experimentation, and carry decisions forward into scale-up. If one of those pieces is missing, the workflow usually breaks at the handoff.
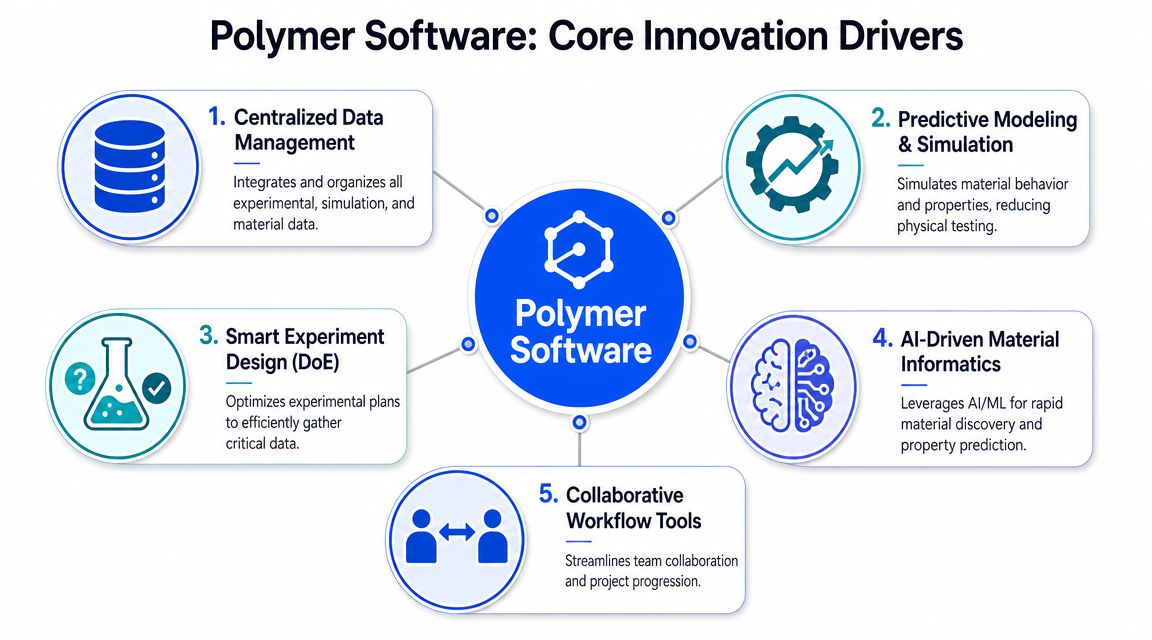
A unified data backbone
This is the foundation. Without it, “AI-enabled R&D” usually means scientists exporting CSV files from different systems and cleaning them by hand before each project. That doesn't scale, and it doesn't preserve knowledge.
The technical reason is straightforward. Effective polymer software captures path-dependent properties, and data models such as CRIPT were designed to unify synthesis, processing, characterization, and simulation data so teams can link structure-to-process-to-property relationships and reduce ambiguity, as described in the CRIPT data model paper in PMC.
A practical backbone should do the following well:
- Ingest heterogeneous sources: spreadsheets, ELNs, LIMS exports, instrument outputs, and simulation files.
- Standardize vocabulary: sample names, formulation components, test methods, and units.
- Preserve lineage: what was made, how it was made, how it was tested, and what changed.
- Support polymer-native representation: not just molecules, but distributions, formulations, and processing context.
This is also where many manufacturing organizations start to see alignment between R&D digitization and broader operational transformation. Teams thinking about lab-to-plant continuity often benefit from adjacent guidance on optimizing mid-market manufacturing with AI, especially when data quality and decision support need to span technical and operational teams.
Predictive modeling that scientists can actually use
Prediction matters, but only after the data foundation is in place. The useful question isn't “Does the model use AI?” The useful question is “Can the model rank realistic candidates using inputs our team trusts?”
In polymer settings, good predictive tools help scientists screen candidate chemistries, formulations, or processing windows before they commit to synthesis. They don't eliminate lab work. They make lab work more selective.
What works:
- Models linked to well-defined experimental context
- Predictions tied to properties relevant to formulation or scale-up decisions
- Outputs that show confidence, comparable precedents, or causal drivers
What usually fails:
- Black-box scores detached from material history
- Models trained on inconsistent legacy data
- Predictions presented with no explanation of applicability limits
Experiment planning instead of experiment accumulation
Polymer software begins to distinguish itself from ordinary record systems. Once the backbone and models are connected, the platform can recommend the next best experiment instead of just storing completed ones.
That changes scientist behavior in a useful way. Instead of running broad, poorly structured experimental grids, teams can run narrower programs designed to answer specific uncertainty gaps. The software's role is not to replace domain judgment. It's to show where one additional run is likely to teach more than five loosely chosen runs.
A few signals that this capability is real rather than cosmetic:
| Signal | What it looks like in practice |
|---|---|
| Recommendation quality | Suggested experiments are tied to target properties and prior evidence |
| Decision traceability | Scientists can see why the recommendation was made |
| Feedback loop | New results update the knowledge base and improve later planning |
The best experiment-planning tools don't chase novelty for its own sake. They reduce wasted learning cycles.
One example of this systems approach is Polymerize, which combines unified R&D data management with explainable models that predict properties, optimize formulations, and surface causal drivers and confidence scores. That kind of architecture is more useful than a standalone predictor because it ties recommendations back to governed historical data.
Scale-up support and operational handoff
A lot of software looks impressive in early discovery and becomes irrelevant once process engineers get involved. That's usually a sign the platform was built for prediction demos rather than real development programs.
Scale-up support means the system can carry forward details that matter outside the lab:
- Process conditions: reaction route, mixing history, cure profile, or compounding settings
- Validation context: which measurements confirmed performance and under what protocol
- Comparability rules: whether a pilot sample is comparable to a bench sample
The payoff is less ambiguity when a promising lab result needs to become a manufacturable material. In practice, the software should help teams keep cause and effect visible across stages, not reset the project every time responsibility changes hands.
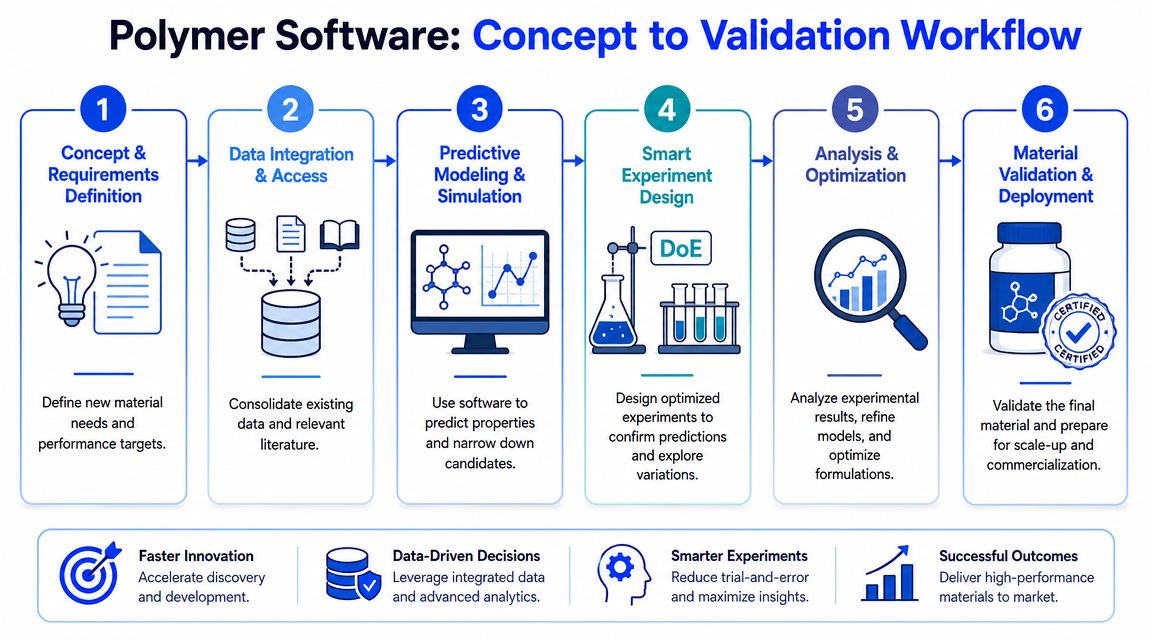
Example Workflow From Concept to Validated Material
The value of polymer software becomes obvious when you compare how a project moves before and after the data layer is fixed.
A typical team might start with a target like improved barrier performance, thermal stability, or processability in a new formulation family. The chemistry team pulls prior formulations from one spreadsheet, test data from an ELN, and a few characterization files from instrument folders. A modeler runs simulations separately. Weeks later, the project meeting still centers on basic reconciliation questions: Are these samples comparable? Which additives changed? Was the processing route the same?
To anchor the workflow visually, use this process view:
Before the platform
In the old flow, teams often proceed in this order:
- Formulate broadly: generate many variants because prior knowledge is hard to search.
- Test reactively: characterize what was made, then decide what to try next.
- Interpret late: compare outcomes only after a batch of experiments is complete.
- Transfer manually: package conclusions into slide decks for process or manufacturing teams.
Nothing about that sequence is irrational. It's just expensive in time and organizational attention. The science may be sound, but the workflow doesn't learn efficiently.
Later in the cycle, many teams also turn to simulation. According to Schrödinger's polymeric materials overview, polymer simulation software is used to predict key properties such as thermo-mechanical performance and degradation pathways before costly synthesis, helping teams reduce failed experiments and prioritize the “next best experiment” with greater confidence.
Here's a short walkthrough that illustrates the shift in mindset:
After the data backbone is in place
Once the team works inside an integrated polymer software environment, the sequence changes.
First, existing internal data gets normalized so the team can query prior formulations, process conditions, and property outcomes in one place. Then the model layer narrows the candidate space. Scientists don't stop designing experiments. They design fewer, better-targeted experiments because the software can connect precedent, predicted performance, and uncertainty.
The workflow usually becomes:
- Define requirements clearly
- Pull comparable historical data
- Screen candidate directions computationally
- Run a focused confirmation set in the lab
- Update the model with observed results
- Carry validated knowledge into scale-up planning
If the platform is working properly, every experiment should either move a candidate forward or reduce a specific uncertainty. “We ran it because we had capacity” should disappear from the workflow.
The result is not magic. It's operational discipline encoded in software.
An Evaluation Checklist for Enterprise Polymer Software
Most enterprise buyers make one of two mistakes. They either buy too early based on a polished demo, or they buy too narrowly and end up with another silo. Both problems come from evaluating polymer software as a feature set instead of as critical R&D infrastructure.
The market's biggest friction point is often upstream of modeling. NIST's Polymer Analytics project highlights a “lack of large datasets for machine learning” and fragmented resources, which is why the highest-value software tends to focus first on FAIR, connected, reusable data foundations, as noted by NIST Polymer Analytics.
What separates an enterprise platform from a demo
Ask vendors questions that expose whether the system can survive contact with your actual environment.
Some of the most important ones are qualitative, not flashy:
- Can it unify legacy data without forcing a full lab process redesign?
- Can scientists understand why the model made a recommendation?
- Can process, quality, and R&D teams all work from the same material history?
- Can the platform protect IP at the level your legal and IT teams require?
A strong answer usually includes specifics about integration patterns, metadata handling, role-based access, and explainability. A weak answer usually circles back to a dashboard.
Enterprise Polymer Software Evaluation Checklist
| Criterion | Why It Matters | Key Questions to Ask |
|---|---|---|
| Data unification | Legacy spreadsheets, ELNs, instrument files, and simulation outputs are where value is trapped | How do you ingest heterogeneous historical data? What has to be standardized manually? |
| Polymer-native data model | Polymers require more than ordinary chemical records | How do you represent formulations, distributions, process history, and characterization context? |
| Explainable AI | Scientists won't trust recommendations they can't interrogate | Do you provide confidence scores, precedent comparisons, or feature-level reasoning? |
| Workflow fit | Scientists adopt tools that reduce friction, not tools that create clerical work | How does the platform fit current formulation, testing, and review workflows? |
| Integration | Enterprise value depends on connecting existing systems rather than replacing everything | Which ELNs, LIMS, data warehouses, and file systems can you connect to? |
| Security and IP protection | R&D software often becomes a repository of core know-how | What controls exist for access, auditability, encryption, and deployment governance? |
| Scale-up continuity | Discovery value is limited if process teams can't use the output | How do you capture manufacturing-relevant variables and validation history? |
| ROI model | The wrong ROI story overpromises AI and underestimates change management | Where have customers seen value first: data retrieval, experiment planning, prediction, or handoff speed? |
A practical buying discipline helps. Ask the vendor to show one workflow using your own messy data, not a curated demo dataset. If they can create material lineage, support a real query, and generate a defensible recommendation from that environment, you're evaluating a platform. If they can't, you're evaluating software theater.
Your Roadmap to Successful Implementation and Adoption
The fastest path to value usually starts with one program, not an enterprise-wide rollout. Pick a use case where the pain is already visible. Formulation screening, candidate ranking, or lab-to-scale handoff are common starting points because teams can see the friction clearly and judge improvement quickly.
Start narrow and tie it to one business problem
A good first deployment has three traits:
- Clear material objective: a specific performance target or formulation problem
- Available historical data: imperfect is fine, inaccessible is not
- Committed scientific owner: someone respected enough to challenge the model and improve it
Don't begin with “enterprise AI transformation.” Begin with one question your team already cares about, then instrument the workflow around that question.
Build scientist trust early
Adoption fails when leaders frame polymer software as automation replacing scientific judgment. That's the wrong mental model. The software should function as a decision support environment that preserves context, surfaces useful patterns, and reduces avoidable trial-and-error.
Two habits help a lot:
- Review recommendations against known historical cases. Scientists trust systems faster when they can compare model logic to outcomes they already understand.
- Make explainability visible in routine meetings. If teams only see final predictions, they won't learn how to work with the platform.
Training matters, but so does governance. Someone has to own taxonomy, data quality rules, and feedback loops from new experiments into the system. Without that discipline, even smart models decay into another underused application.
The organizations that get this right don't treat polymer software as a standalone digital purchase. They treat it as the operating layer for modern materials development. That's what moves R&D from disconnected effort to repeatable learning.
If your team is trying to build that kind of AI-ready backbone, Polymerize is one option to evaluate. It's designed as a system of intelligence for materials R&D, combining data unification across fragmented sources with explainable models for prediction, formulation optimization, and experiment planning so scientists can work from a connected foundation rather than isolated tools.

