Your team probably already knows the textbook rule. Change the structure, change the property. In practice, that rule often breaks down the moment a project leaves the whiteboard and enters the lab, pilot line, or plant.
A formulation looks promising in early screening, then performance drifts after a processing change. A polymer behaves one way in a controlled dataset and another after aging, contamination, or scale-up. Meanwhile, the data you need sits in instrument files, ELNs, old spreadsheets, and the memory of the scientist who ran the trial two years ago. That's where most structure property relationships stop being an academic topic and become an operational problem.
The useful question isn't just what structure affects what property. It's how to build a repeatable system that can capture structure, connect it to outcomes, explain why the relationship holds, and warn you when it probably won't. That's where AI helps, not as a replacement for materials judgment, but as a way to turn scattered observations into a working R&D engine.
Table of Contents
- What Are Structure Property Relationships and Why They Matter
- Why the hierarchy matters
- Where teams get misled
- Start with the decision, then build the dataset around it
- Build features that reflect the mechanism
- Test model stability, not just fit
- Close the loop with targeted experiments
What Are Structure Property Relationships and Why They Matter
A familiar R&D scenario goes like this. The team has already tested the obvious formulations, tuned the easy process settings, and collected a stack of mixed results across labs and pilot lines. Progress slows because each new experiment answers a narrow question, while the bigger one remains unresolved: which change in structure will move the property that matters?
Structure property relationships turn that situation into a design problem. Instead of screening options until something works, teams map how a material's structure influences measurable behavior, then use that map to choose the next experiment, formulation, or process adjustment with a reason behind it.
In textbook form, the principle is simple: structure affects properties, and properties affect function. In practice, the useful question is narrower and more operational. Which aspects of structure explain the variation your team sees in tensile strength, permeability, conductivity, stability, adhesion, or release rate?
That is why methods such as QSAR and QSPR matter. They connect structural descriptors to performance outcomes through statistical models and machine learning. But in an enterprise lab, those models often fail when process history, raw material variance, measurement drift, or inconsistent metadata never make it into the descriptors. A model built only on idealized chemistry often misses what development teams are trying to control.
The business value is straightforward.
- Better experiment selection: teams can test structural hypotheses that are likely to change the target property, instead of covering a broad search space by habit.
- More useful negative results: failed runs still add value when they sharpen the boundary between structures that work and structures that do not.
- Stronger scale-up decisions: lab results become easier to transfer when the team understands which structural features must be preserved through mixing, curing, thermal history, or downstream processing.
Practical rule: If your team cannot name the structural features tied to a target property, you are still searching, not designing.
A common pitfall is treating structure property relationships as a library of static facts. That approach breaks down fast in real programs. The same polymer backbone can produce different outcomes depending on molecular weight distribution, residual solvent, crystallinity, filler dispersion, cooling rate, or storage conditions before testing.
That is why this topic matters beyond theory. In enterprise R&D, structure is not just a formula on paper. It includes the history of how the material was made, handled, measured, and recorded. Teams that capture that full context build models that improve decision quality. Teams that ignore it get attractive correlations that fail during transfer, scale-up, or supplier change.
The Core Principle From Molecules to Microstructures
A useful way to think about materials is as a layered build. Like a Lego structure, the final performance depends not only on which pieces you chose, but on how they connect, how they're arranged, and what larger patterns they create. Two builds can use similar pieces and still behave very differently once load, heat, or moisture enters the picture.
That's the logic behind the classic chain: structure → properties → function.
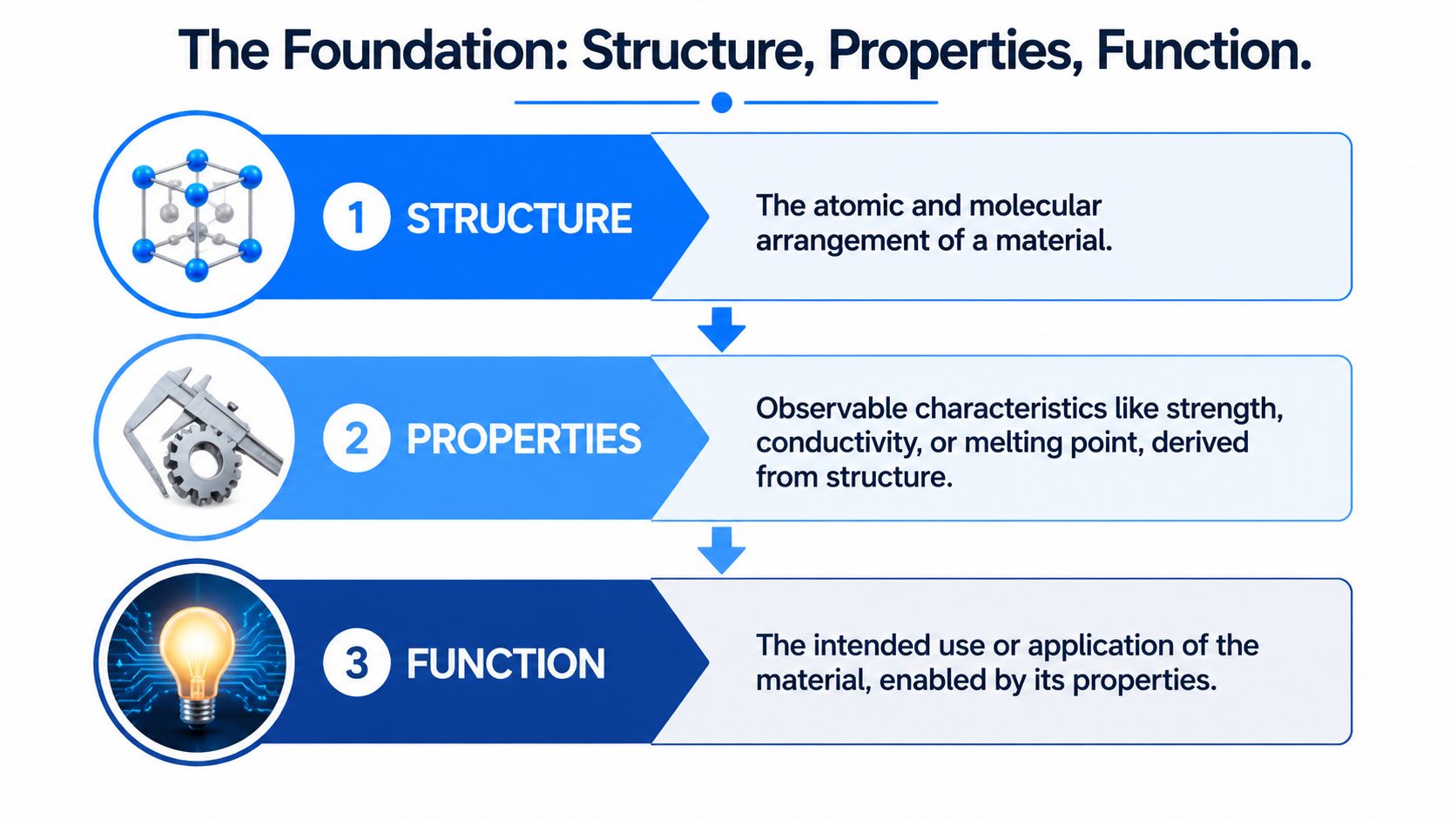
Why the hierarchy matters
At the smallest scale, structure starts with atoms, bonds, and molecular arrangement. In polymers, that includes backbone chemistry, side groups, molecular weight distribution, branching, and crosslink density. In small molecules, it includes the motifs that influence interactions with solvents, surfaces, or neighboring species.
Those low-level choices shape measurable properties. A change in bonding environment can alter stiffness, thermal behavior, permeability, or optical response. In a product context, those properties then enable or block function. A membrane separates, a coating protects, an encapsulant survives thermal cycling, a composite carries load.
The concept later became formalized for prediction through QSAR/QSPR, which convert structure into descriptors and use statistical methods to estimate property outcomes. More recently, researchers have extended that thinking beyond molecules into microstructures. One published workflow combined two-point statistics, principal component analysis, and Ridge regression to build a structure-property linkage from small microstructures, organized as a five-step process covering dataset preparation, preprocessing, microstructural information extraction, optimization, and linkage construction, as reported in this study on microstructure-based structure property linkages.
Where teams get misled
The hard part is that “structure” isn't one thing. It exists across scales.
| Scale | What teams examine | What it often influences |
|---|---|---|
| Molecular | Bonds, functional groups, chain architecture | Solubility, reactivity, transport behavior |
| Crystalline or phase level | Crystal form, phase distribution, orientation | Strength, deformation response, electronic behavior |
| Microstructural | Grain boundaries, pores, domains, dispersion, topology | Fracture mode, durability, heterogeneity, reliability |
A team can optimize one level and miss another. For example, the nominal chemistry may be correct, while the phase distribution or filler network ruins the intended property. That's why structure property relationships become more useful when scientists stop treating materials as composition-only problems.
A material doesn't fail because its datasheet looked wrong. It fails because its real structure at the relevant scale didn't support the property the application demanded.
The practical takeaway is simple. Don't ask only what the material is made of. Ask how it is arranged, what history created that arrangement, and which scale controls the performance you care about.
Mapping Structures to Properties With Experimental and Computational Methods
Teams usually get into trouble when they overcommit to one mode of evidence. Some trust characterization alone and drown in disconnected measurements. Others trust modeling too early and build predictions on weak structural definitions. Good structure property work needs both.
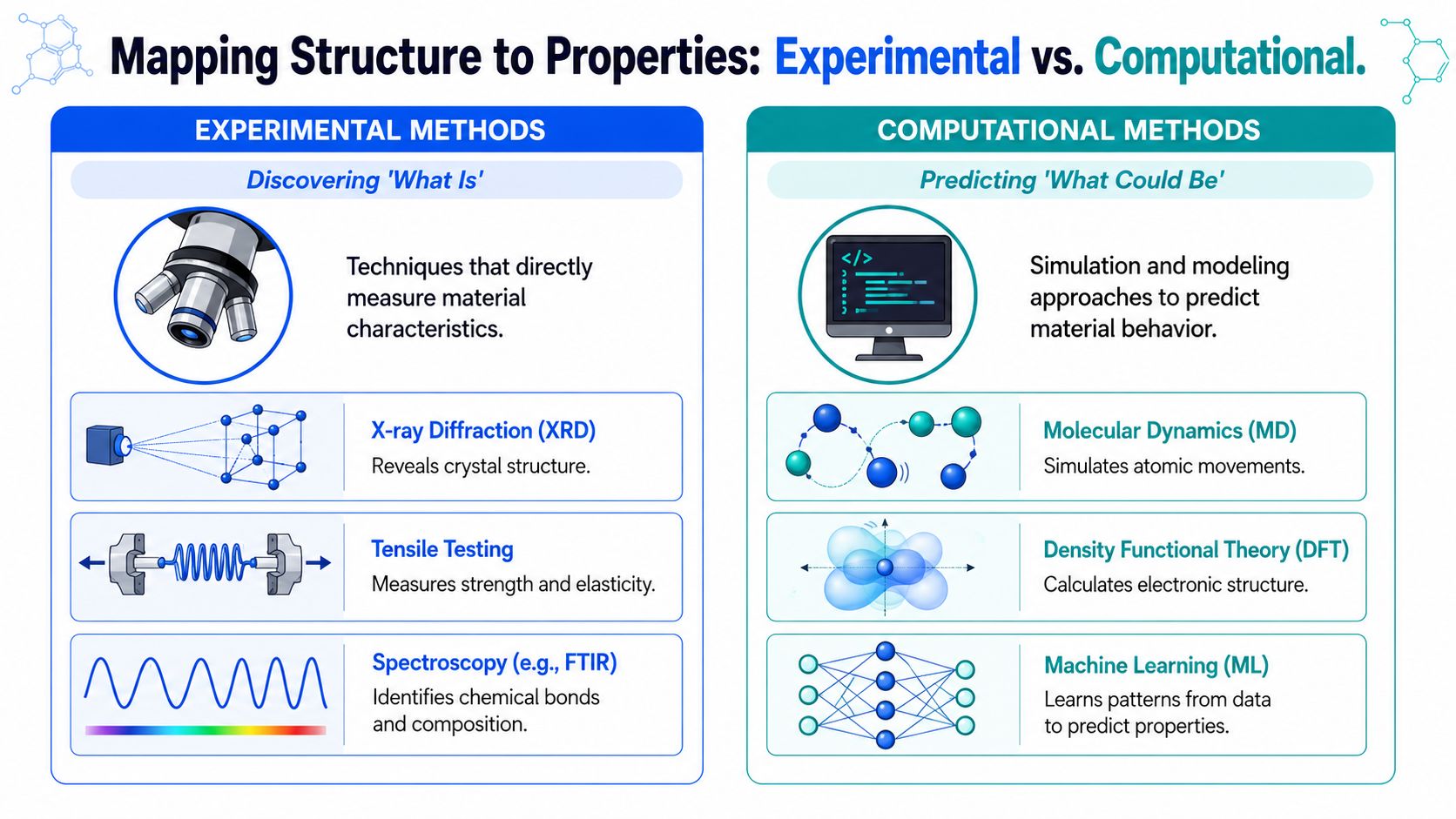
What experiments actually tell you
Experimental methods give you direct evidence of what the material is and how it behaves. They anchor the entire workflow. Without them, you don't have ground truth. You have assumptions.
A few tools show up repeatedly because they answer different structural questions:
- X-ray diffraction: Useful when crystal structure, phase identity, or crystallinity drives performance.
- SEM and TEM: Helpful for morphology, interfaces, dispersion quality, porosity, and defect visualization.
- Spectroscopy such as FTIR: Good for identifying bonding environments, composition shifts, and chemical changes after processing or aging.
- DSC and related thermal methods: Important when transitions, cure state, or thermal history affect the property window.
- Mechanical testing: Necessary when the design objective involves load-bearing behavior, elasticity, or failure mode.
The mistake is assuming any one technique captures “the structure.” It doesn't. Each method samples part of the story. If your property depends on both chemistry and morphology, a single measurement stream will leave blind spots.
What models add to the picture
Computational methods do something experiments can't do efficiently. They help you organize patterns across many observations and ask counterfactual questions before you run the next batch.
Traditional QSPR approaches are still useful, especially when the system is chemically constrained and descriptor quality is high. They're often better than teams expect because they force discipline. You must define the structure representation, the target property, and the training boundary clearly.
Simulation tools such as molecular dynamics and density functional theory help when mechanism matters and the cost is justified. They're especially valuable for testing hypotheses about interactions, conformations, and local environments. But they aren't substitutes for production data. They describe possible behavior under modeled conditions, not necessarily what your plant will create on a Tuesday afternoon.
Machine learning becomes powerful when the organization has enough historical breadth to learn from mixed signals across projects. That's when models can connect descriptors, process metadata, characterization outputs, and property measurements into one predictive layer.
Field note: The best model in materials R&D usually isn't the most sophisticated one. It's the one trained on the cleanest representation of the problem.
A practical division of labor
Here's the split that works in real programs:
- Experiments establish reality: They confirm structure, reveal defects, and measure outcome.
- Models rank hypotheses: They narrow design space and highlight likely drivers.
- Scientists arbitrate trade-offs: They decide whether a predicted gain is chemically plausible, manufacturable, and worth the risk.
When teams skip the first step, they get brittle predictions. When they skip the second, they move too slowly. When they skip the third, they generate technically impressive outputs that nobody trusts enough to use.
That's why the most effective structure property relationships programs don't ask whether experimental or computational methods are better. They ask how each method reduces uncertainty at the right moment in the project.
From Correlation to Causation With Explainable AI
A model flags three formulations as high-potential for stiffness retention after thermal aging. The chemistry team asks which structural feature to change. The process team asks whether the result will hold after a different cure cycle. If the model cannot answer either question, the prediction has limited value in an R&D program.
That gap shows up all the time in enterprise materials work. High accuracy can help rank candidates, but ranking alone does not explain mechanism, support scale-up, or build confidence across functions.
Why black box accuracy isn't enough
In production-facing R&D, teams do not evaluate models on accuracy alone. They also ask whether the model is using a chemically meaningful signal or a shortcut buried in the dataset.
That distinction matters. Many materials datasets mix structural descriptors with process artifacts, instrument settings, operator conventions, and sparse labels collected across years of projects. A black-box model can learn from those patterns and still miss the actual driver of the property. The result is a model that looks strong in validation and weak in deployment.
The failure modes are familiar:
- Proxy variables replace physical drivers: The model latches onto a correlated measurement or batch identifier instead of the structure that affects performance.
- Predictions break outside the training window: A formulation tweak, new supplier lot, or process shift changes the relationship the model learned.
- Knowledge does not accumulate: Teams get a recommendation, but they do not get a usable explanation that can guide the next round of experiments.
That is the difference between correlation and causation in practice. Correlation helps sort options. Causal reasoning helps decide what to change, what to hold constant, and which experiment is worth running next.
What explainability changes in practice
Explainable AI helps connect a prediction back to something a scientist can test. Instead of stopping at "sample A is likely to outperform sample B," the model can point to the descriptors, local environments, or microstructural regions that contributed most to the prediction.
For example, one SCANN framework paper showed that attention-based models can do more than predict materials behavior. They can also highlight which local structural features influenced the output, which makes the result more useful for hypothesis generation and review with domain experts.
That changes the conversation in a project meeting. Scientists can check whether the model emphasis matches known mechanisms, whether the signal survives process variation, and whether the recommended direction is manufacturable. If the explanation conflicts with fracture analysis, spectroscopy, or plant experience, the team has a reason to challenge the model early instead of carrying a bad assumption into the next sprint.
A short overview of the mindset shift is worth watching:
“If the model can't suggest what to vary next, it hasn't reduced much experimental uncertainty.”
Explainability also matters for governance. In enterprise R&D, adoption depends on traceability. Program leads want to know why a recommendation was made. Technical teams want to see whether the logic aligns with known structure-property behavior. Manufacturing wants confidence that the model is not overfitting to lab-only conditions.
I treat explainability as a required part of the workflow for serious structure property work. The point is not to make every model simple. The point is to make its reasoning inspectable enough that scientists can connect predictions to mechanisms, challenge weak signals, and turn model output into faster experimental decisions.
A Practical Workflow for Data-Driven Materials R&D
A team misses a property target, reruns the experiment, and gets a different result even though the formulation looks unchanged on paper. In enterprise R&D, that usually points to a workflow problem, not a theory problem. The structure was never the whole story by itself. The missing context sits in batch history, processing conditions, instrument settings, and how those records were captured.
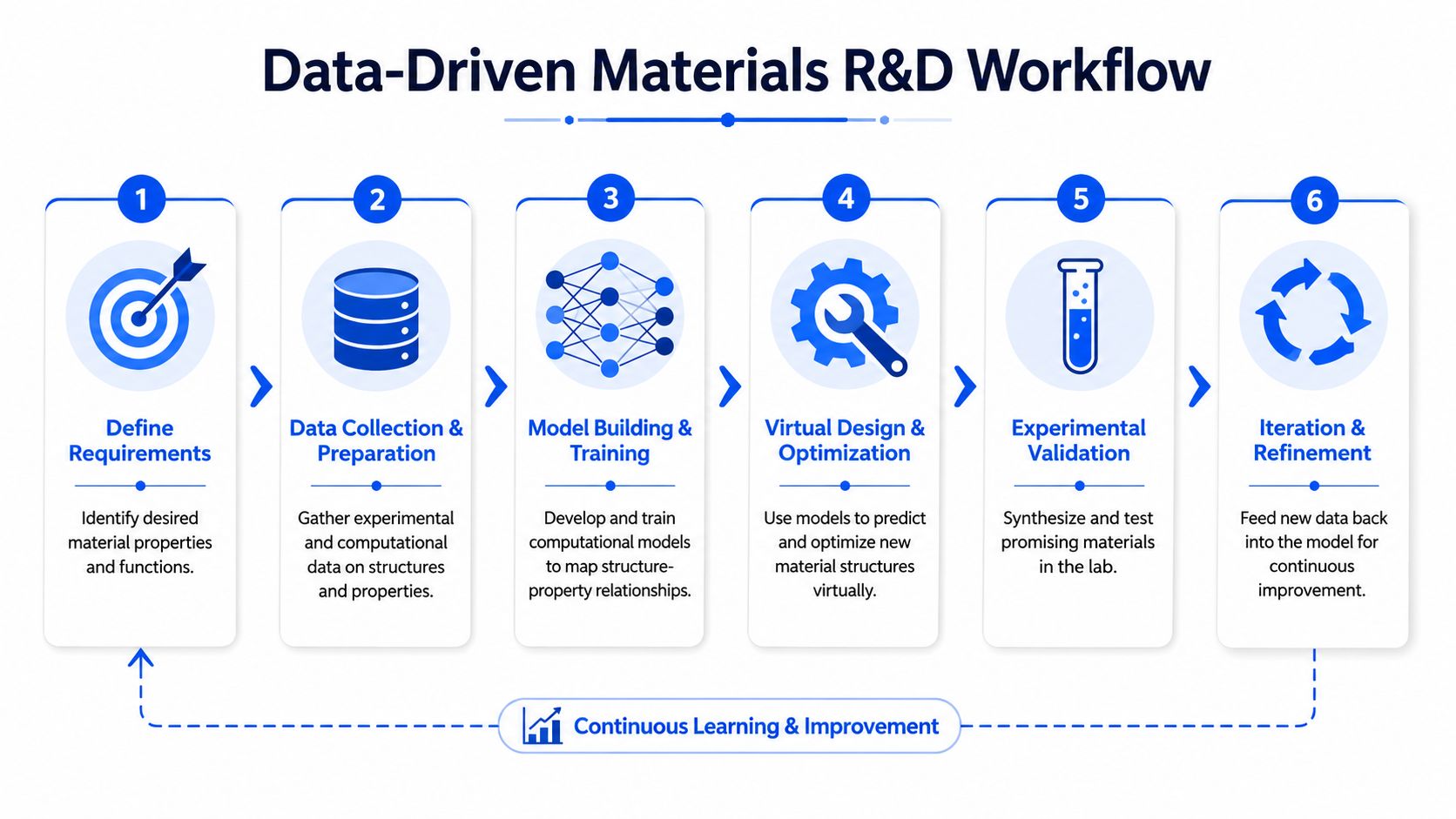
Start with the decision, then build the dataset around it
The workflow starts with a decision the team needs to make. Which formulation should move forward? Which processing change is worth pilot time? Which failure mode needs to be reduced under actual use conditions?
That changes how data gets assembled. Instead of pulling every available record into a generic model, connect the specific property target to the evidence needed to explain it. Define the property window, the test method, the service environment, and the failure criterion. A tensile result without humidity, sample preparation, and thermal history is often less useful than scientists expect.
In practice, the intake usually pulls from ELNs, LIMS, instrument exports, formulation spreadsheets, and plant or pilot notes. The hard part is not collection. It is alignment.
A usable record set keeps lineage intact:
- Material identity: Composition, grade, supplier naming conflicts, internal aliases
- Structural evidence: Spectra, microscopy, diffraction, thermal analysis, engineered descriptors
- Process history: Mixing order, residence time, cure profile, shear exposure, aging, contamination events
- Measured outcomes: Property values, test conditions, pass-fail calls, analyst notes, anomalous observations
Build features that reflect the mechanism
Feature generation should match the material system and the decision at hand. For a polymer formulation problem, that may mean composition ratios, molecular descriptors, crystallinity markers, and cure-state indicators. For a microstructure-sensitive coating or composite, it may mean phase distribution, pore statistics, orientation metrics, or features derived from image analysis.
Many programs lose credibility with scientists when the model gets fed variables that are easy to export but weakly tied to mechanism. The fit can still look good, at least for one campaign. The recommendation quality usually does not.
Tooling matters because it shapes what can be traced and reused. Some groups build this stack in Python with custom pipelines. Others use materials informatics platforms. Polymerize is one example of a system built to centralize experimental records and support explainable property prediction and formulation work. The trade-off is familiar. Flexible internal tools give control, while dedicated platforms reduce setup time and improve consistency across teams.
Decision test: If a scientist cannot explain why a descriptor might matter, it should not carry the model by itself.
Test model stability, not just fit
A model that performs well on cleaned lab data can still fail as soon as a new operator, line, or processing window enters the picture. That is a common failure mode in materials programs because the same nominal chemistry can produce different properties after process history changes morphology, defects, or interfacial structure. This is exactly why teams need to account for process-structure-property relationships, and why predictive analytics for applications is relevant when sequence effects, drift, and time-dependent behavior start to matter.
Good teams treat prediction as one stage in a decision loop, not the endpoint. They ask whether the relationship transfers across batches, whether the signal survives routine variation, and whether the recommendation still makes sense under manufacturing constraints.
| Workflow stage | What good teams ask |
|---|---|
| Model training | Did we include the structural and process variables that plausibly drive the property? |
| Recommendation review | Does the suggested change align with known chemistry, morphology, and failure behavior? |
| Experimental validation | Did the property shift under the intended conditions, not just in a favorable lab setup? |
| Scale check | Does the relationship persist after processing, aging, operator variation, and normal plant noise? |
One reference worth keeping in view is this discussion of how process history changes microstructure and performance. It captures a point that gets lost in simplified workflows. Processing is not metadata. It is part of the causal path.
Close the loop with targeted experiments
The strongest workflow uses the model to narrow options, then uses experiments to test the proposed driver. That distinction matters. If the model suggests a formulation change because a descriptor tracks crosslink density, the next experiment should check whether crosslink density is the reason the property moved.
Negative results matter here. So do partial wins.
A failed recommendation can still show where a relationship stops holding, which variables were confounded, or which process step dominates the outcome. Teams that capture those cases well build a knowledge base that gets better with each cycle. Teams that only log successful formulations keep repeating the same blind spots.
The payoff is practical. Scientists spend less time screening low-value combinations. Project leads get a clearer basis for go or no-go decisions. Manufacturing sees earlier whether a lab result is likely to survive scale. That is how structure-property theory becomes an operating workflow for faster R&D, rather than a principle everyone agrees with and few teams can use consistently.
The Future of Materials Design Is Predictive
The old model of materials development was search-heavy. Teams explored, screened, adjusted, and hoped the next iteration would land closer to the target. That approach still works for some problems, but it doesn't scale well when property windows tighten, sustainability constraints grow, and product cycles speed up.
The stronger model is predictive by design. Start with a target function. Connect it to the properties that matter. Map those properties to the structures and process conditions most likely to produce them. Then use data and explainable models to decide which experiments are worth running.
That shift changes more than lab efficiency. It changes how organizations learn. Instead of scattering insight across projects, scientists build a reusable structure property knowledge base. Instead of treating scale-up surprises as isolated setbacks, teams can trace which relationships were consistent and which were conditional on process history. Instead of rewarding only successful formulations, they can extract value from every informative experiment.
For leaders building that capability, adjacent disciplines can help. The logic behind predictive analytics for applications is useful here because many materials programs also need to reason about drift, sequence effects, and behavior over time, not just static formulation snapshots.
The companies that adopt this mindset aren't just discovering materials. They're designing them with more intent, better evidence, and clearer trade-offs. That doesn't remove uncertainty from R&D. It makes uncertainty manageable.
Mastering structure property relationships now means more than understanding the textbook principle. It means building the data, models, and decision habits that let that principle work under real conditions.
Polymerize helps materials teams turn fragmented experimental records into an AI-ready foundation, apply explainable models to structure and property questions, and support faster iteration from lab work to scale-up. If you're building a data-first workflow for polymers, chemicals, or advanced materials, it's worth evaluating Polymerize as part of your R&D stack.

