Your R&D team probably didn't decide to create a risky access model. It usually happens by drift. One formulation spreadsheet lives in a shared drive. Raw instrument output sits in a lab folder everyone can open. A data scientist gets copied onto a project they only need for a week, but the access never gets cleaned up. An external partner receives a results export by email because there isn't a controlled way to share just one dataset.
That's manageable when the team is small and the project portfolio is narrow. It breaks down fast when you add more scientists, more product lines, more vendors, and more pressure to move from experiment to scale-up without leaking IP. Then access control stops being an IT hygiene issue and becomes an R&D operating problem.
For materials organizations, the stakes are specific. It's not just customer records or generic documents. It's formulation logic, processing windows, experimental outcomes, and the know-how that turns a promising polymer or chemical system into a commercial advantage. If too many people can see everything, you increase exposure. If too few people can access what they need, collaboration slows down.
Role-based access control is one of the cleanest ways to fix that tension. It gives teams a structured way to decide who should access what, based on work responsibility rather than ad hoc sharing habits. That's why the model has lasted. A NIST analysis of RBAC's impact estimated an annual operating benefit of $43.71 per employee and projected a net benefit of $671 million through 2006, tied to lower administrative overhead and faster adoption as a scalable alternative to older models of access control (NIST RBAC economic analysis).
Table of Contents
- It protects the crown jewels without freezing the lab
- It makes cross-functional work safer
- It supports cleaner audits and governance
- Start with the assets and decisions that matter
- Engineer roles around workflow not org charts
- Build review into the design
Introduction The R&D Data Dilemma
A familiar pattern shows up in growing materials teams. The chemistry group stores formulations one way. Process engineers keep trial notes somewhere else. Quality has its own results repository. Data science pulls copies into notebooks and analysis folders. Everyone can still get work done, but nobody can answer a basic governance question with confidence: who can access which experiments, and why?
That uncertainty creates two different failures at once. One is overexposure. Sensitive formulation data, failed experiments, and scale-up learnings end up visible to people who don't need them. The other is friction. A scientist who should be able to compare results across a project can't find the latest version, or asks three different managers for access because nothing is structured.
When sharing habits become a security model
Most R&D access patterns begin informally. Team leads approve folder access. Project owners add names to workspaces. Someone forwards a file because a contractor needs quick visibility. Each decision sounds reasonable in isolation.
Together, they produce a permission environment nobody designed.
The problem usually isn't one bad access decision. It's hundreds of temporary decisions that quietly become permanent.
For technical leaders, this becomes painful during audits, partner reviews, and internal investigations. If a formulation changed, or a result was exported, you need to know who had access. If a scientist changed teams, you need confidence that their old permissions didn't follow them indefinitely.
Why RBAC belongs in the R&D operating model
Role-based access control gives R&D leaders a way to replace ad hoc sharing with a predictable system. Access is tied to work functions like formulation scientist, lab manager, process engineer, or external collaborator. That doesn't remove flexibility. It creates a controlled baseline so collaboration happens inside a known model instead of around it.
For organizations protecting trade secrets, that baseline matters as much as any firewall or endpoint control. Sensitive IP isn't only stolen by dramatic attacks. It's often exposed because access was broad, inherited, and poorly reviewed.
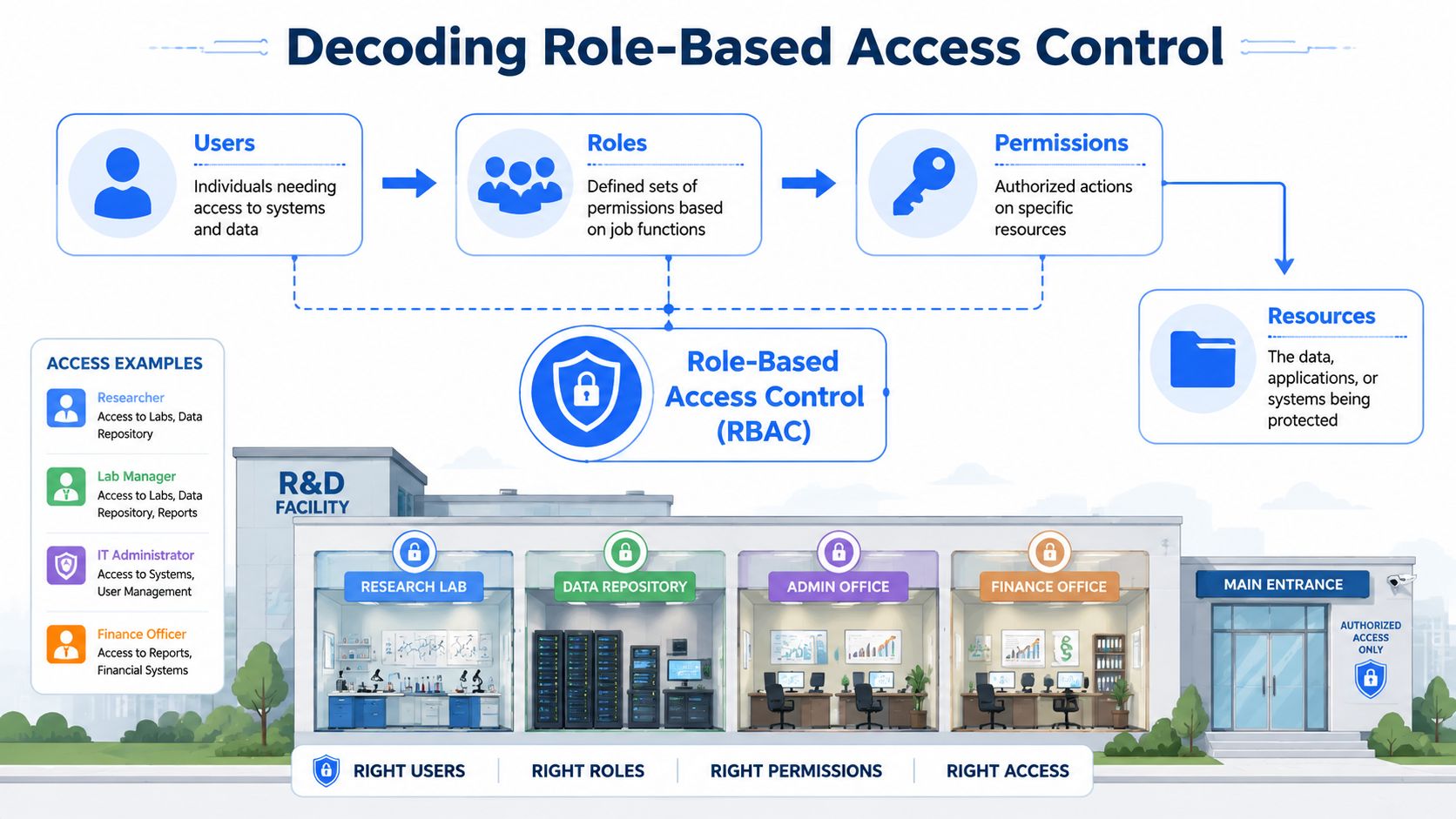
Decoding Role-Based Access Control
The easiest way to understand role-based access control is to stop thinking about accounts and start thinking about doors. In a materials R&D facility, you wouldn't hand every employee a master key. You'd issue access based on what they need to do. A formulation scientist might enter the formulation lab and project database. A quality engineer might access test results and release workflows. A contractor might enter only one project area, and only for a limited time.
That's how RBAC works in software and data systems. Users don't get broad access because someone remembers their name. They receive a role, and the role carries the permissions.
The keycard model fits R&D better than most people think
R&D environments have more zones than people realize. There are project spaces, raw data repositories, formulation libraries, analytics environments, scale-up records, supplier documentation, and approval workflows. If you manage access one person at a time across all of that, administration expands quickly and consistency disappears.
NIST's definition gets to the core of why RBAC works. In RBAC, permitted actions are identified with roles rather than individual user identities, which reduces direct user-to-permission assignments and helps prevent privilege creep over time (NIST glossary definition of RBAC).
That separation matters because jobs change more slowly than individual requests. “Formulation scientist on Project A” is stable enough to design around. “Please give Dana edit rights to these seven folders and this one dashboard” is not.
The three objects that matter
A practical RBAC design in R&D revolves around three objects:
- Users: Scientists, engineers, technicians, data scientists, managers, and external collaborators.
- Roles: Business functions such as Formulation Scientist, Lab Manager, Process Engineer, Quality Reviewer, or External Partner.
- Permissions: Specific allowed actions like view experiment records, edit formulations, approve workflows, export datasets, or administer project settings.
Once you separate those three objects, access decisions become much cleaner. You can review the role, not just the person. You can ask whether a Formulation Scientist should export raw data, rather than whether a specific individual should keep one-off access forever.
Practical rule: If your team is still granting access mostly by exception, you don't have an RBAC model yet. You have manual sharing with role labels on top.
This same logic applies beyond application permissions. Teams that are also thinking about physical and network entry points often benefit from understanding how to secure digital doorways, because access discipline breaks down when systems, devices, and identities are governed separately.
Strategic Advantages of RBAC in Materials R&D
Materials R&D has a different security profile from general enterprise IT. Your most valuable assets often aren't financial records or customer support tickets. They're formulation recipes, processing parameters, experimental designs, scale-up lessons, and negative results that competitors would love to avoid reproducing at their own cost.
A good RBAC program protects those assets without forcing scientists into a maze of ticket requests and workarounds.

It protects the crown jewels without freezing the lab
The first advantage is selective visibility. Not every chemist needs access to every formulation family. Not every process engineer needs access to upstream exploratory experiments. Not every external partner should see the full history behind a candidate material.
RBAC gives you a way to enforce that selective visibility consistently. Because permissions are attached to roles, administrators can control access at a level that's manageable across large environments. That scalability is one reason the model remains central to modern cloud security. Common implementations such as Azure RBAC support permissions at the management group, subscription, resource group, or individual resource scope, which is useful when sensitive assets need both central governance and fine-grained control (RBAC and cloud governance overview).
In practice, that means you can protect high-value datasets without building custom permission logic for every project.
It makes cross-functional work safer
Materials programs are rarely single-discipline efforts. A development program may involve formulation chemists, analytical scientists, quality teams, process engineers, procurement, and outside labs. Collaboration is necessary, but broad default access isn't.
RBAC helps teams collaborate by defining what each function can see and do. That's a better fit for real programs than all-or-nothing project sharing.
Consider how this looks in daily work:
- Formulation teams need to create and modify experiment records within active project spaces.
- Quality reviewers may need read access to methods and results, but not permission to alter experimental history.
- Process teams often need access to downstream scale-up data, batch notes, and selected formulation attributes, not the entire research archive.
- External labs may need read-only access to a narrow subset of project data tied to contracted work.
It supports cleaner audits and governance
When access follows a role model, access review becomes far more intelligible. Auditors, security teams, and R&D leaders can ask structured questions. Which roles can export data? Which roles can approve project changes? Which users still hold privileged access after moving teams?
That matters for organizations working toward controlled environments and documented governance. RBAC doesn't guarantee compliance by itself, but it makes compliance evidence much easier to assemble because access decisions are tied to named functions and repeatable policy.
How RBAC Compares to Other Access Models
RBAC is not the only way to manage access. It's just the one that tends to hold up best when organizations need consistency across many users, many systems, and many kinds of sensitive data.
In materials R&D, the alternatives often show up by accident before anyone names them. Shared folders with owner-controlled permissions behave like discretionary access control. More advanced policy engines that consider time, device, or location start to look like attribute-based access control.
Access Control Model Comparison
| Model | Access Decision Based On | Best For | Key Challenge |
|---|---|---|---|
| RBAC | Role tied to job function or responsibility | Enterprise R&D environments with recurring responsibilities and shared governance needs | Can become rigid if every exception is forced into a static role |
| DAC | Resource owner decides who gets access | Small teams and informal collaboration | Consistency breaks down as projects, people, and files multiply |
| ABAC | Dynamic attributes such as location, device, time, or other context | Sensitive actions and fast-changing access conditions | Policy design and troubleshooting are more complex |
DAC is common because it's easy to start with. A project owner shares a folder, a dashboard, or a results workbook with whoever needs it. The problem is that the owner's judgment becomes the policy engine. Different owners make different decisions, and nobody gets a clean enterprise view of exposure.
RBAC fixes that by centralizing the logic around work functions. It's usually the better default when teams need scale, repeatability, and clear review.
Why hybrid authorization is showing up more often
RBAC does have limits. Some access decisions shouldn't depend only on job title or function. A contractor may need access for a short project window. A senior scientist may need emergency access outside normal scope. A privileged action may be acceptable only from a managed device or within a controlled environment.
That's where ABAC becomes useful. ABAC evaluates dynamic attributes such as user location, device type, or time. Current guidance increasingly points toward a hybrid model: use RBAC for baseline permissions, then layer ABAC-style controls for exceptions and highly sensitive actions (RBAC and ABAC hybrid guidance).
Use RBAC to answer “what does this person normally need?” Use contextual controls to answer “should this action happen right now, under these conditions?”
For materials organizations, that hybrid split is practical. Keep routine access tied to stable roles. Add temporary, event-based, or risk-based controls where the workflow is dynamic.
Best Practices for Enterprise RBAC Implementation
The hardest part of role-based access control isn't turning the feature on. It's designing roles that match actual work. If your role model is wrong, the system becomes noisy, brittle, and full of exceptions.
The strongest implementations start with business operations, not software menus.
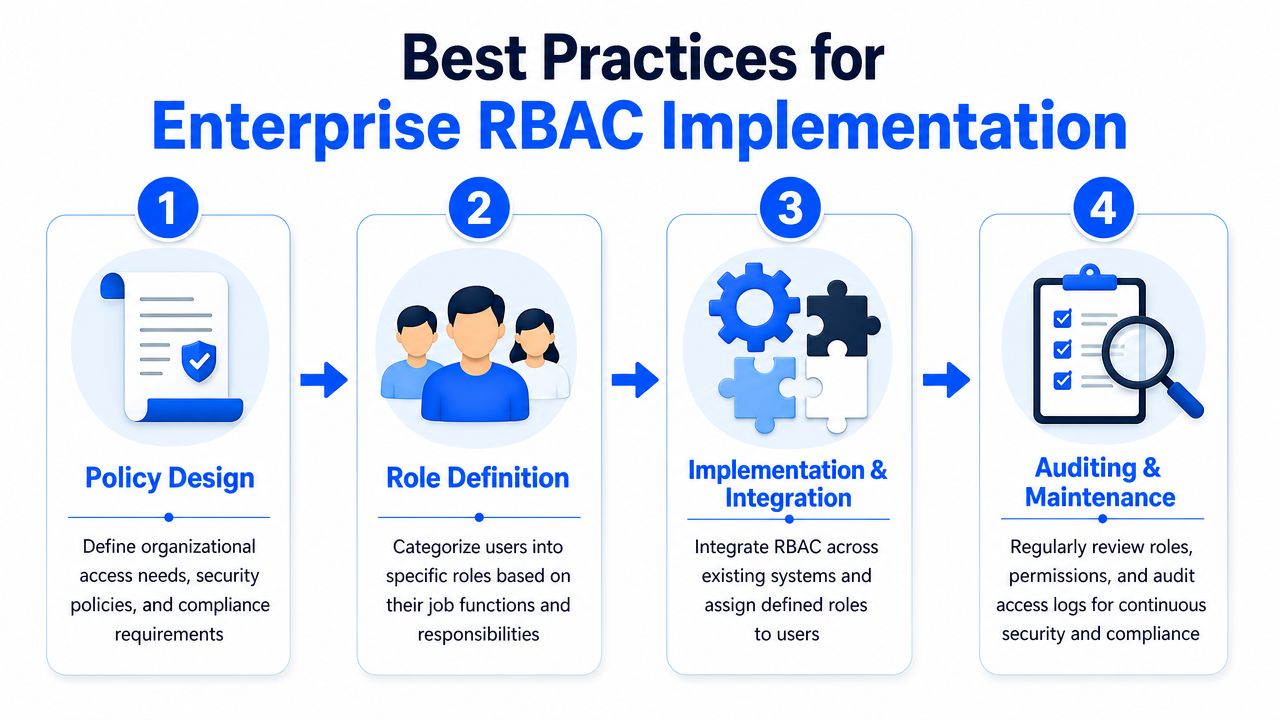
Start with the assets and decisions that matter
Before defining a single role, identify the assets that need control. In materials R&D, that usually includes formulation records, raw and processed experiment data, project workspaces, approval workflows, dashboards, and export functions.
Then define permissions before roles. That sequence matters. Expert guidance recommends defining permissions first, then grouping them into roles that reflect business functions, and only then assigning users to those roles. It also recommends validating the design with user-role and role-permission matrices before rollout (structured RBAC implementation guidance).
A useful working sequence looks like this:
- List protected resources: Experiments, formulations, methods, datasets, reports, admin settings.
- Define allowed actions: View, create, edit, approve, export, delete, administer.
- Map those actions to real work: Who requires each action, and in what context?
- Create roles from stable work patterns: Not from one-time requests.
Engineer roles around workflow not org charts
A common mistake is copying the HR org chart into the permission system. That rarely works in R&D. Two people with the same title can need very different access depending on project stage, product line, or lab responsibility.
A better approach is workflow-first role engineering.
- Project-centered roles: A scientist may need edit rights inside assigned project workspaces, but only read rights outside them.
- Function-centered roles: A quality reviewer may approve or comment on records without changing source experiment data.
- Control roles: Lab managers or platform admins may need broader visibility, but not unrestricted editing everywhere.
If a role can't be explained in plain business language, it usually isn't ready for production.
This is also where connected digital systems matter. Teams modernizing lab and business workflows should think about security in adjacent tooling too, including areas like AI website builder security, because access assumptions often spread across connected platforms faster than governance does.
Build review into the design
RBAC works only when review is part of the operating rhythm. Role assignment should connect to onboarding, internal transfers, contractor access, and offboarding. Sensitive permissions should have named owners. Temporary access should expire by design.
A simple review model often works better than an elaborate one nobody follows:
- Quarterly role review: Validate whether roles still reflect live workflows.
- Project transition review: Remove access that belonged to a finished program or reassigned team.
- Privileged permission review: Scrutinize export, delete, admin, and approval rights more closely.
- Exception cleanup: Turn repeated exceptions into formal design decisions or remove them.
One practical option for materials organizations is to manage these controls inside a platform designed for secure R&D data operations. Polymerize includes role-based permissions and controlled access as part of a centralized materials data environment, which can help teams move away from fragmented sharing across spreadsheets, ELNs, and siloed systems.
Common RBAC Pitfalls to Avoid
Most RBAC failures don't come from the model itself. They come from entropy. Teams start with a clean design, then real work introduces exceptions, temporary access, duplicated roles, and inherited permissions that nobody rechecks.
The result is an access model that still looks organized on paper but behaves like a patchwork.
Role sprawl starts with good intentions
Role sprawl happens when teams keep creating slightly different roles to handle edge cases. One role becomes three. Three become nine. Soon you have overlapping definitions like “Senior Formulation Scientist,” “Formulation Scientist Advanced,” and “Project Formulation Editor,” each carrying almost the same rights with small differences no one can explain.
That pattern is widely recognized as a core RBAC weakness. Guidance on implementation challenges calls out role sprawl and privilege creep as common failure modes, especially in environments where work is cross-functional and roles don't line up neatly with static job titles (common RBAC implementation challenges).
In materials R&D, cross-functional work makes this more likely. Scientists move between exploratory work, customer-specific reformulation, pilot support, and analytical review. If every temporary variation becomes a new permanent role, the system decays.
Privilege creep is usually a process failure
Privilege creep shows up when people keep old access after role changes, project changes, or temporary assignments. A scientist who helped on one sensitive project retains data access long after moving on. A contractor keeps visibility after a statement of work ends. A manager keeps approval rights that no longer match current responsibilities.
The fixes are operational, not theoretical:
- Use time-bound access for contractors, temporary staff, and project-based exceptions.
- Review access quarterly so duplicate and unused roles don't accumulate.
- Tie offboarding and team moves to access removal instead of treating revocation as a separate manual task.
- Limit exceptions by asking whether a repeated exception should become part of a formal role design.
A clean RBAC model is maintained, not declared.
If your team treats RBAC as a one-time implementation project, maintenance debt will show up quickly. The organizations that keep RBAC healthy are the ones that treat it like product governance. Someone owns the definitions, someone reviews the drift, and someone has authority to retire roles that no longer reflect real work.
RBAC in Action Securing Data in Polymerize
In a materials platform, RBAC becomes useful only when the role boundaries line up with how scientists and engineers work. The goal isn't to create abstract security categories. It's to protect formulation logic, experimental results, and project context without blocking the people who need to move a program forward.
Here's what that looks like in practice inside a controlled R&D environment.
How role boundaries look in a materials platform
A Formulation Scientist role might be able to create and edit experiments within assigned projects, attach observations, compare results, and update formulation variants. That same role doesn't need to delete the project, manage tenant-wide settings, or alter broader governance controls.
A Lab Manager role typically needs wider visibility. That may include reviewing experiments across multiple projects, approving workflows, and monitoring dashboards used to coordinate lab activity. This level of visibility makes sense here, but it still shouldn't automatically imply unrestricted administrative control over everything in the environment.
An External Collaborator role is where RBAC proves its value quickly. This user may need read-only access to one bounded dataset or one shared project area. They usually shouldn't see adjacent experiments, unrelated formulations, or internal dashboards that expose broader program direction.
Those distinctions are what let teams collaborate without defaulting to full-project exposure.
Where temporary and elevated access fit
Materials R&D rarely runs on static roles alone. A scale-up event may require short-term access for a process engineer. A compliance review may require temporary visibility for an auditor. A partner may need narrow access for a limited project phase.
That's where controlled exceptions matter. The cleanest model is to keep baseline access role-based, then apply temporary elevation or expiry rules around the edge cases. That avoids creating a permanent new role every time work changes for a short period.
The short walkthrough below is a useful way to visualize how controlled access fits into an R&D workflow:
For organizations operating in regulated or security-conscious environments, this structure also supports clearer governance. When access is tied to defined roles and bounded exceptions, it's easier to show how teams protect sensitive data while supporting requirements associated with frameworks such as GDPR, SOC 2, and ISO 27001.
Conclusion Building a Secure Foundation for Innovation
Role-based access control works because it solves a practical problem. Growing R&D teams need people to collaborate across projects, labs, and disciplines without exposing everything to everyone. Shared drives and manual permission decisions don't scale to that requirement. They create confusion, weak auditability, and too much accidental visibility around sensitive IP.
For materials organizations, the value is concrete. RBAC helps protect formulation knowledge, experimental history, and project data by aligning access with real work responsibilities. It also makes operations more manageable. Onboarding is cleaner, offboarding is safer, and reviews become intelligible because teams can examine roles and permissions instead of untangling years of one-off sharing.
The important trade-off is that RBAC isn't self-sustaining. If roles aren't engineered around workflows, or if temporary exceptions become permanent, the model decays into maintenance overhead. That's why strong RBAC programs combine a clear baseline with continuous review, and increasingly, with contextual controls for edge cases.
For R&D leaders building AI-ready data environments, this is not optional. If your data backbone is fragmented and your access model is informal, your security posture and your innovation velocity will both suffer. The organizations that move fastest are usually the ones that know exactly who can access which data, under what conditions, and for what purpose.
If your team is trying to centralize experimental data while keeping formulation IP, project workspaces, and collaborator access under control, Polymerize is built for that operating model. It gives materials R&D organizations a secure system for unifying fragmented data, applying role-based access, and supporting controlled collaboration across scientists, engineers, and external partners.

