Most materials R&D teams are already sitting on years of useful data. The problem isn't volume. It's fragmentation. Formulation results live in spreadsheets. Instrument outputs sit in proprietary file formats on local machines. Characterization images are buried in shared drives. Experimental rationale ends up in ELNs, slide decks, or somebody's memory.
That setup works until the team tries to answer a simple question with confidence. Which additive combinations consistently improved impact strength? What changed between two similar batches with different outcomes? Which historical experiments are clean enough to train a predictive model? In many labs, finding the answer still means opening folders, reconciling filenames, and hoping the original scientist documented enough context.
An SDMS stops being a back-office archive and becomes strategic infrastructure. In materials science, the value of an SDMS isn't just that it stores files. It creates the data backbone that makes experimental knowledge reusable by scientists, process engineers, and machine learning systems alike.
Table of Contents
The Hidden Data Problem in Materials R&D
Materials R&D rarely fails because scientists lack ideas. It stalls because data from past work can't be found, trusted, or reused fast enough.
A polymer team might have formulation tables in Excel, rheology data in instrument software, microscopy images on a shared drive, and conclusions summarized in PowerPoint. Each piece makes sense on its own. Together, they don't form a usable knowledge system. When teams need to compare experiments across chemistries, sites, or years, the seams show immediately.
The operational cost is familiar. Scientists repeat tests because old data is hard to locate. New team members inherit folders without context. Process engineers receive results without enough provenance to understand what really happened at the bench. Digital teams start AI initiatives and discover that historical data exists, but not in a form that can be normalized and modeled.
Why this hurts innovation speed
The biggest loss isn't storage efficiency. It's decision quality.
Without a coherent data backbone, teams struggle to answer questions like:
- What changed: Was the result driven by composition, processing condition, instrument setting, or operator choice?
- What can be trusted: Is the file final, corrected, or duplicated?
- What can be reused: Can this experiment support formulation optimization, root-cause analysis, or model training?
- Who can access it: Does another site or function even know the work exists?
Practical rule: If a scientist can't retrieve prior experimental context quickly, the lab will pay for that gap later in repeated work and slower decisions.
This is why an SDMS matters in materials science. It addresses the hidden layer beneath experimentation. Not the chemistry itself, but the structure around the data that chemistry produces. When that structure is missing, AI projects disappoint, collaboration stays manual, and institutional knowledge leaks out every time someone changes role.
What an SDMS Is for Materials Science
An SDMS, or Scientific Data Management System, is best understood as the catalog and control layer for scientific data. If an ELN is where researchers describe what they planned and observed, the SDMS is the system that ingests, organizes, and makes the underlying files usable across the organization.
In materials science, that matters because so much of the important evidence is unstructured or semi-structured. Instrument images, PDFs, spreadsheets, spectra exports, and proprietary machine outputs don't fit neatly into standard business databases. An SDMS is built for exactly that problem. As described by Uncountable's overview of Scientific Data Management Systems, an SDMS is a specialized electronic software solution designed to manage unstructured and diverse data sets, such as PDFs, spreadsheets, and images from laboratory equipment, which standard systems often fail to handle.
More than storage
A weak SDMS implementation behaves like a digital warehouse. Files go in. Search is poor. Context is thin. Scientists still rely on tribal knowledge to interpret what they find.
A strong SDMS does more than archive:
- Captures raw experimental outputs from instruments and lab workflows
- Adds metadata so data can be searched by project, material, method, operator, date, or formulation
- Preserves provenance so teams know where a result came from and how it changed
- Creates links across systems so raw data, experimental notes, and downstream analysis don't drift apart
That last point is where many teams underestimate the strategic value. In materials informatics, raw files are only useful when they can be connected to formulation variables, process conditions, and measured properties. The SDMS is the layer that makes those links durable.
Why FAIR matters in practice
Teams often talk about FAIR data. Findable, Accessible, Interoperable, and Reusable. In practice, FAIR isn't a policy statement. It's an operating condition.
When an SDMS is doing its job, scientists can find prior work without asking three colleagues. Data engineers can pull records without manual cleanup on every project. Machine learning teams can distinguish complete experiments from partial ones. Global teams can work from a shared evidence base instead of rebuilding local copies.
A modern SDMS should make data understandable to both humans and machines. If it only solves one side of that equation, it won't support intelligent experimentation.
For materials R&D, that shift is decisive. The lab stops treating data as a byproduct of experiments and starts treating it as a reusable asset that improves each next experiment.
SDMS vs ELN LIMS and Data Lakes Compared
The confusion around SDMS usually comes from overlap. ELNs, LIMS, and data lakes all touch scientific data. But they don't do the same job, and trying to force one system to act like another usually creates friction.
Each system has a different job
An ELN is where scientists document experimental intent, procedures, observations, and conclusions. A LIMS manages operational workflow around samples, tests, and lab process control. A data lake stores large volumes of raw data with broad flexibility, often without domain-specific scientific context. An SDMS focuses on collecting, indexing, securing, and contextualizing scientific files that would otherwise remain scattered.
The easiest way to choose correctly is to ask a plain question: what problem are you trying to solve?
| System | Primary Purpose | Typical Data Managed | Key Focus |
|---|---|---|---|
| SDMS | Centralize and contextualize scientific data files | Instrument outputs, PDFs, spreadsheets, images, semi-structured scientific records | Data capture, indexing, provenance, retrieval, reuse |
| ELN | Document experiments and scientific reasoning | Experimental procedures, observations, notes, attachments | Scientific documentation and collaboration |
| LIMS | Manage lab operations and workflows | Samples, tests, results, inventory, workflows | Process control, sample tracking, compliance workflows |
| Data Lake | Store large volumes of raw enterprise data | Structured, semi-structured, and unstructured data from many systems | Scalable storage for downstream engineering and analytics |
Where teams get this wrong
A common mistake is expecting the ELN to become the master store for all scientific evidence. That usually breaks down when teams need raw instrument files, version control, machine-readable metadata, or long-term retrieval across projects.
Another mistake is assuming a data lake solves scientific reuse by default. It can store almost anything, but storage without context doesn't help a formulation scientist trying to compare historical experiments. Unless the team adds strong metadata discipline and scientific data modeling, the lake becomes a larger silo.
What works better is a complementary stack:
- Use the ELN for protocol and experimental narrative.
- Use the LIMS for sample and workflow orchestration.
- Use the SDMS for scientific file capture, metadata, and provenance.
- Use the data lake when enterprise-scale analytics need a broader platform.
The right question isn't which system wins. It's which system owns which responsibility.
For materials organizations, the SDMS often becomes the bridge between scientific generation and computational use. It's where messy, heterogeneous lab outputs gain enough structure to support cross-project search, analytics, and eventually predictive modeling.
Core Features of a Modern AI-Ready SDMS
A modern SDMS has to do more than hold files safely. It has to prepare scientific data for reuse. That means the feature checklist should be judged by downstream outcomes, not just by whether a vendor can demonstrate ingestion and search.
Capabilities that matter in real labs
Automated instrument data capture is one of the first capabilities to evaluate. If scientists still have to manually upload core files, quality drops fast. People forget. Naming conventions drift. Context gets added later, which usually means incompletely. Direct capture from instruments or watched locations is far more reliable.
Flexible metadata design matters just as much. Materials teams work across formulations, processing conditions, test methods, and characterization techniques that don't fit a rigid schema. The system should let teams define metadata that reflects actual scientific work, while still enforcing enough consistency for search and analysis.
Version control and provenance separate a usable record from a risky one. Teams need to know which file is original, which result was reprocessed, and which dataset supported a decision. Without that chain, historical analysis becomes fragile.
Audit trails and access controls are not just for regulated industries. They matter whenever IP protection, cross-site collaboration, or review discipline is important. Role-based access prevents open-folder chaos while still letting teams work across functions.
What looks good in demos but fails in deployment
Some features sound impressive but don't survive real lab conditions.
- Rigid templates: They create administrative compliance but often don't match how materials scientists work across evolving projects.
- Search without scientific context: Keyword search alone won't help if the system can't distinguish resin grade, processing method, characterization type, or property endpoint.
- Closed architectures: If the SDMS can't connect outward through APIs, the data stays trapped even after it's centralized.
- Manual metadata enrichment: This becomes a backlog almost immediately.
A better buying lens is to ask whether each feature helps the organization do one of three things better:
- Trust the record
- Find the right experiment
- Reuse the data for analytics or AI
That's the standard for AI readiness. Not whether the vendor uses the word AI, but whether the system produces contextualized, governed data that models can learn from.
Integrating an SDMS into Your R&D Ecosystem
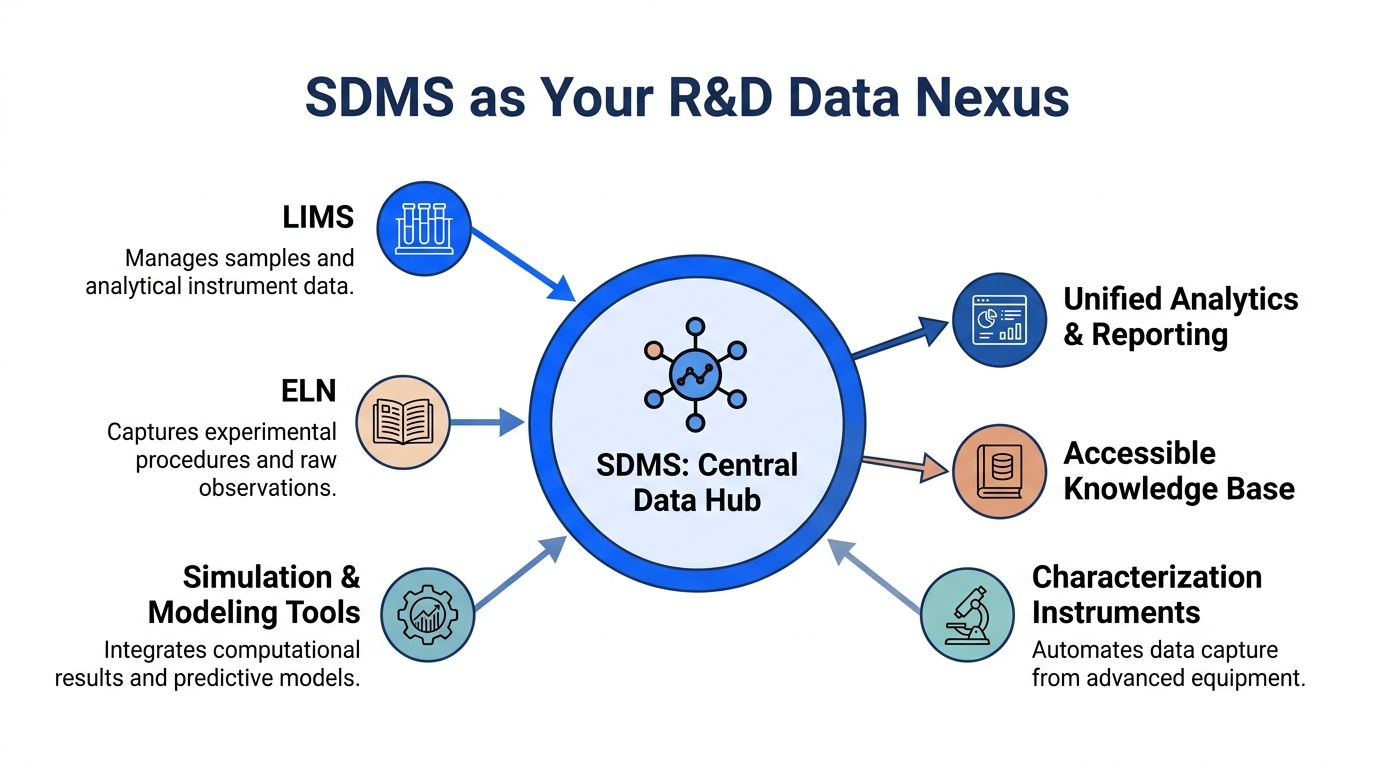
Most labs don't need another isolated platform. They need a center of gravity for data. That's why the most effective SDMS integrations follow a hub-and-spoke pattern. Instruments, ELNs, LIMS, simulation tools, and analytics environments connect to the SDMS rather than building brittle point-to-point links everywhere else.
Think hub and spoke
In a well-designed setup, the SDMS doesn't replace every tool in the lab. It stabilizes how data moves between them.
A characterization instrument produces a raw file. The SDMS captures it automatically, indexes key metadata, and stores it with provenance. The ELN record references that dataset instead of carrying around disconnected attachments. A LIMS can link sample identifiers to the same underlying data object. Analytics environments pull curated data from the SDMS or through connected services rather than scraping ad hoc folders.
This approach reduces duplicate storage and avoids the common problem of conflicting copies. It also gives digital teams one place to apply governance, retention rules, and metadata standards.
A practical data flow
A useful integration model usually looks like this:
- At the edge: Instruments and local applications generate raw outputs.
- At capture: Parsers, connectors, or ingestion agents move those outputs into the SDMS.
- At context: Metadata gets attached based on instrument, project, sample, operator, method, or workflow.
- At usage: ELNs, LIMS, reporting tools, and analytics systems consume linked data rather than unmanaged files.
If your architecture still depends on scientists manually dragging files between systems, the data backbone isn't finished.
The strongest designs also account for simulation and modeling data, not just wet-lab output. Materials programs increasingly combine experimental and computational evidence. If those streams stay separate, teams can't compare prediction and outcome cleanly.
API-first systems are essential. They let organizations connect upstream generation with downstream analysis. In practice, that could include a platform such as Polymerize, which unifies fragmented experimental data across spreadsheets, ELNs, and silos into a centralized data backbone and supports AI-driven materials workflows. The key point isn't the brand. It's the architecture. Data should move through governed, connected pathways instead of through email attachments and local folders.
Your Practical Guide to SDMS Implementation
SDMS adoption works when it's run as an operating model change, not a software purchase. The market momentum reflects that shift. The global Scientific Data Management Systems market reached USD 183.75 million in 2025 and is projected to reach USD 2,417.09 million by 2032, according to Reanin's Scientific Data Management Systems market analysis. That growth says more than vendor enthusiasm. It shows that labs now treat scientific data infrastructure as a strategic requirement.
A useful rollout starts smaller than is commonly expected.
Start with the business case
Don't begin with a feature list. Begin with one painful workflow.
Pick a problem that scientists and leadership both recognize. Examples include repeated characterization work because prior files can't be found, slow handoff from formulation to scale-up, or weak reuse of historical test data. The business case gets stronger when it names a real bottleneck instead of promising generic digital transformation.
Then map your highest-value data sources. In materials R&D, those often include:
- Instrument outputs: Spectra, thermal analysis files, microscopy images, mechanical test exports
- Experimental records: ELN entries, spreadsheets, formulation logs
- Context records: Sample IDs, batch information, processing parameters, approval status
Choose the first rollout carefully
The best pilot isn't the biggest one. It's the one with clear pain, manageable system boundaries, and a user group willing to participate.
A strong first scope often has three traits:
- One scientific domain with repeatable workflows
- A small number of core instruments that generate important files
- A direct downstream use case such as search, comparison, reporting, or model preparation
Avoid trying to clean every historical archive at once. That turns implementation into a data archaeology project.
Field advice: Migrate what teams need to use, not everything they've ever produced.
After the pilot is stable, extend by adjacent workflow. Add another instrument class, another team, or another site. That sequence gives governance and metadata standards time to mature under real usage.
A short technical walkthrough helps teams visualize what “good” looks like in practice:
What to ask vendors
Vendor evaluations often overemphasize interface polish and underweight data architecture. Ask harder questions.
- How is data captured? If capture depends heavily on manual upload, adoption risk rises.
- How flexible is the metadata model? Materials teams need structure, but not a schema so rigid that every new project needs custom work.
- How does the system handle provenance? You need clear lineage from raw file to reused dataset.
- What integration options exist? APIs, connectors, and export capabilities matter more than standalone dashboards.
- How does access control work? R&D organizations need project-based visibility and strong IP protection.
- What's the migration strategy? Good vendors distinguish active, high-value data from cold archive material.
The implementation leader's job is to keep everyone focused on one outcome: creating a data backbone scientists will use because it removes friction from daily work. If the system adds documentation burden without improving retrieval, trust, and reuse, people will route around it.
Measuring ROI and Future-Proofing Your R&D
The ROI of an SDMS shows up first in behavior. Scientists spend less time hunting for files. Cross-functional teams argue less about which dataset is current. Historical work gets reused instead of recreated. Those changes are easy to recognize even before finance puts a model around them.
The stronger payoff is strategic. An SDMS creates the conditions for better experimentation. Teams can compare broader experimental histories, preserve context around failures, and feed cleaner data into analytics workflows. That changes how projects are prioritized and how quickly hypotheses are tested.
What to measure
A practical scorecard usually includes:
- Search and retrieval efficiency: How long it takes to find complete experimental evidence
- Data reuse: Whether teams can use historical work in new projects
- Workflow continuity: How reliably data moves from instrument to scientist to analytics environment
- Decision confidence: Whether teams can trace conclusions back to governed source data
The market direction reinforces why this matters. The global SDMS market was valued at USD 59.13 million in 2022 and is projected to reach USD 1,840.23 million by 2030, expanding at a 44.2% CAGR, according to Data Bridge Market Research on the global SDMS market. That growth reflects a broader shift toward AI-ready data backbones in scientific R&D.
Future-proofing doesn't mean buying software with the loudest AI message. It means building a governed experimental memory your organization can trust. If your materials data stays fragmented, every future modeling effort starts with cleanup. If your SDMS is done well, each new experiment makes the whole system smarter.
If your team is trying to turn scattered materials data into an AI-ready R&D backbone, Polymerize is one option to evaluate. It combines centralized experimental data management with explainable models for formulation development, property prediction, and next-experiment planning, which makes it relevant for organizations that want the SDMS layer and AI workflow to work together.

