Your materials team probably already has more useful data than it can use.
One polymer formulation lives in a spreadsheet on a shared drive. Thermal analysis results sit in instrument software that only one specialist can export correctly. Microscopy images are stored in folder trees named by date, operator, or whatever made sense that afternoon. A senior scientist has the process context in an ELN entry, but the sample IDs don't quite match the characterization files. Six months later, another team repeats a similar experiment because nobody can reliably find, trust, and compare what already exists.
That isn't a storage problem. It's a knowledge compounding problem. When data stays fragmented across spreadsheets, ELNs, instrument outputs, and local conventions, R&D loses the cumulative effect that should make every experiment improve the next one. That's why scientific data management has become strategic infrastructure rather than admin overhead. The scientific data management system market was valued at USD 121.95 million in 2024 and is projected to grow at a 44.00% CAGR from 2025 to 2034, according to Polaris Market Research's SDMS market analysis.
For materials science, that shift matters even more. Your data isn't just tabular. It includes formulations, process conditions, spectra, images, time series, batch histories, scale-up notes, and property measurements collected under different protocols. If you want AI to help with formulation design, property prediction, or experiment planning, you need a backbone that treats all of that as connected scientific evidence. Teams thinking through that transition often benefit from concrete operating patterns such as the Woolf Software discovery model kit, which frames how discovery programs move from scattered experiments to structured decision systems.
Table of Contents
- Why Your R&D Data Is a Trapped Asset
- What good scientific data management actually delivers
- FAIR as a lab library system
- What the backbone must contain
- Why metadata quality determines whether AI scales
- Centralized does not mean rigid
- The operational workflow that keeps data usable
- Governance controls that scientists usually resist until they need them
- Phase 1 and 2 audit, strategy, and pilot
- Phase 3 and 4 build, integrate, and roll out
- Phase 5 optimize and make the system self-improving
Why Your R&D Data Is a Trapped Asset
A materials organization can be scientifically advanced and still operate with a brittle data layer.
One team may have excellent bench practice, careful notebooks, and strong analytical methods, yet still struggle to answer simple cross-project questions. Which dispersant families improved viscosity stability for similar resin systems? Which curing conditions repeatedly created edge-case failures? Which supplier lots correlated with unexpected property drift? Those are not advanced AI questions. They're retrieval questions. Most labs can't answer them quickly because the evidence is spread across file types, naming habits, and disconnected systems.
The cost shows up in behavior. Scientists rerun characterization because prior raw data can't be found. Formulators trust summary tables over raw observations because context has been stripped out. New hires depend on tribal knowledge because the historical record isn't searchable enough to stand on its own.
Data becomes trapped when a team can store it but can't reliably connect, interpret, and reuse it.
That trapped value is why scientific data management matters. In practice, it creates a usable chain from sample creation to test method, instrument file, processed output, interpretation, and downstream decision. Once that chain exists, historical work stops being static archive material and starts becoming a decision asset.
Three symptoms usually signal that data debt is already slowing innovation:
- Repeated work: Scientists redo experiments because earlier runs are hard to trust or hard to locate.
- Slow handoffs: Process development, analytical, and formulation teams use different identifiers and lose context during transfer.
- Weak learning loops: Project reviews summarize outcomes, but the underlying evidence never becomes reusable for later modeling.
For CTOs in materials R&D, this is the important reframing. Scientific data management isn't a compliance project dressed up as infrastructure. It's the system that lets your experimental program accumulate intelligence instead of resetting at the start of every project.
The Core Goals and Foundational Principles
The backbone only works if the organization agrees on what it's for. In materials R&D, the answer usually comes down to four outcomes: reproducibility, provenance, accessibility, and long-term reuse.
That sounds abstract until you compare the lab to a specialized research library. If every book arrives without title, author, subject tags, edition history, or shelf location, the library technically owns knowledge but can't serve it. Most R&D environments treat scientific data that way. Files exist, but they aren't cataloged with enough structure to make them operational.
What good scientific data management actually delivers
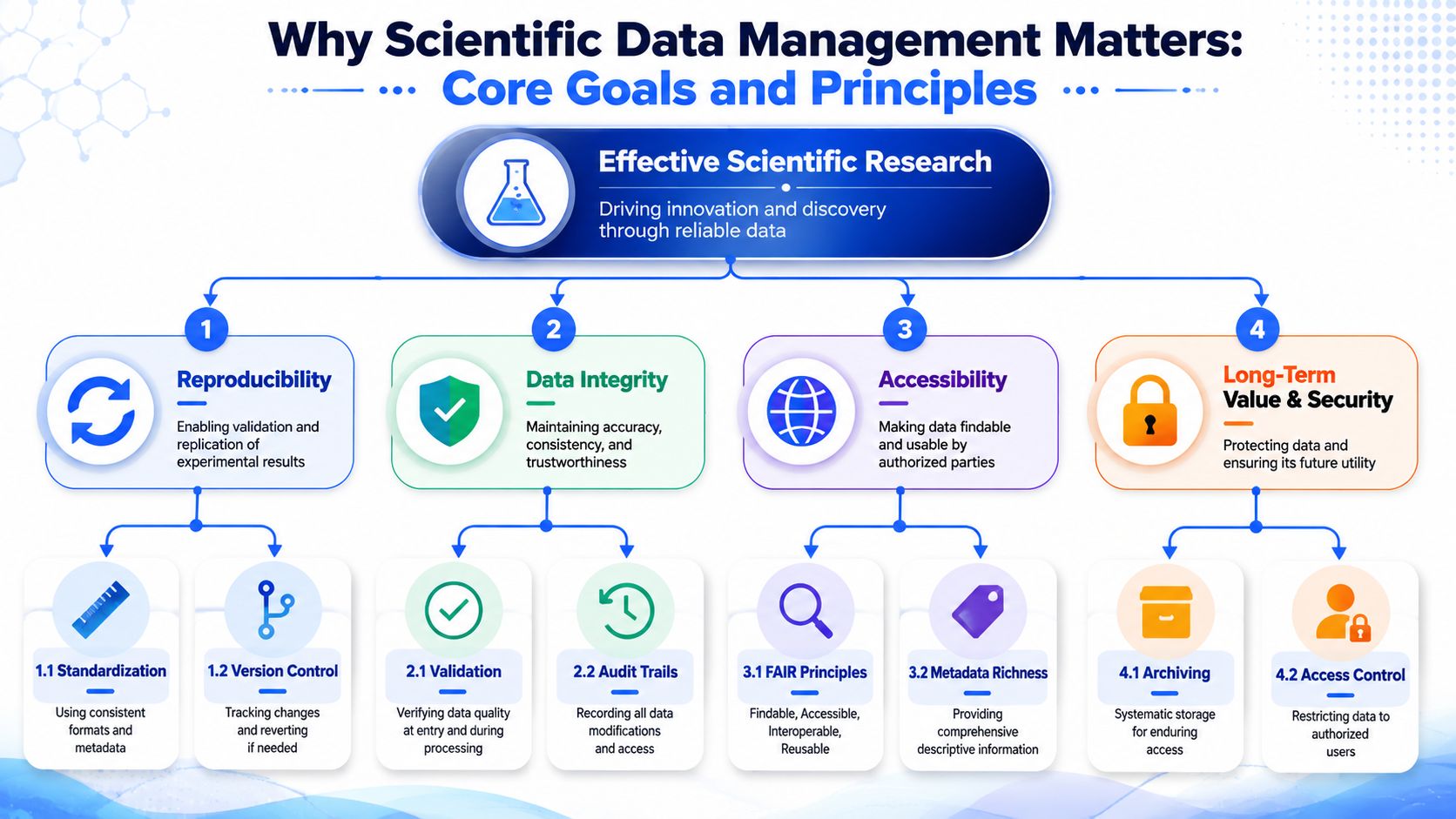
Good scientific data management does a few concrete things well:
- It preserves provenance: Teams can trace a property result back to the sample, recipe, protocol, instrument method, and operator context that produced it.
- It supports reproducibility: A later scientist can understand what changed between runs, not just compare final values.
- It creates a reliable shared record: Teams stop maintaining parallel versions of the same truth in spreadsheets, slide decks, and email threads.
- It makes reuse realistic: Historical data becomes usable for comparison, modeling, scale-up decisions, and AI workflows.
Best-practice guidance on research data management emphasizes that FAIR-aligned metadata and lifecycle controls are the technical basis for reuse, including version control, rich metadata capture such as project, creator, and keywords, and consistency that preserves traceability from raw observations to processed datasets, as described in SciNote's research data management guidance.
FAIR as a lab library system
FAIR is often explained as a policy idea. It's more useful to treat it as an engineering requirement.
Here's what each principle means inside a materials lab:
| Principle | In practice for materials R&D | What fails without it |
|---|---|---|
| Findable | Sample, batch, formulation, and test data can be located by identifiers, metadata, and searchable attributes | Scientists search folder trees, old ELNs, and memory |
| Accessible | Authorized users can retrieve the data and understand how to request or use it | Data exists but sits behind personal ownership or opaque systems |
| Interoperable | Data can move between analysis tools, pipelines, and teams without manual rework | Every export becomes a custom cleanup exercise |
| Reusable | Context, method, and lineage are rich enough for another project to trust and apply the data | Results can be viewed, but not confidently reused |
A practical FAIR implementation for materials science usually includes:
- Stable identifiers for samples, formulations, batches, lots, and experiments.
- Required metadata fields that capture enough process context to interpret results later.
- Controlled vocabularies so “anneal temp,” “annealing temperature,” and “post-cure temp” don't become separate concepts by accident.
- Version-aware records for methods, derived data, and corrected datasets.
Practical rule: If a scientist can't tell what a dataset means without calling the original author, the metadata is still incomplete.
The point isn't to burden scientists with paperwork. It's to make each experiment durable. AI readiness comes later, but FAIR discipline is what makes that later stage possible.
Unifying Your Diverse R&D Data Sources
Materials R&D rarely fails because there's no data. It fails because the data estate is uneven.
A typical program runs across spreadsheets, ELNs, analytical instruments, image repositories, pilot line systems, and slide decks that hold the only surviving interpretation of a result. Each source creates a different kind of integration problem. If you treat them all the same, the unification effort stalls.
What sits in the typical materials data estate
Start with the usual categories.
Spreadsheets are flexible, familiar, and dangerous. They're often the home of formulation matrices, screening summaries, supplier comparisons, and manually combined test results. They also hide the most schema drift. Column names change by person. Units are mixed. Tabs become undocumented versions of one another.
ELNs capture narrative context well, especially around intent, observations, and procedural details. The problem is structure. A scientist may describe a solvent swap, a mixing anomaly, or a failed cure in useful prose, but unless those details are linked to structured entities, they're hard to query across projects.
Instrument outputs bring the opposite problem. SEM files, spectroscopy outputs, rheology traces, thermal analysis exports, and chromatography results can be highly structured within the vendor software and awkward outside it. Proprietary formats, inconsistent export settings, and detached method files break downstream comparability.
Images and complex files are especially difficult in materials science. Micrographs, spectra collections, and multivariate characterization datasets need descriptive metadata that goes beyond generic file labels. Researchers have specifically identified metadata quality control, more expressive metadata for complex files, and better machine-readable search across variables as a gap in data management, as reported in this Scientific Data focus-group study.
The hardest materials data to reuse is usually the data that looked easiest to save at the time.
Start with a data audit, not a platform demo
Poor data management wastes resources through repeated experiments and lost context, while stronger practices improve data quality across accuracy, integrity, integration, and timeliness and support long-term reuse that can save labor and material costs, according to the USGS value of data management guidance.
That's why the first serious move isn't tool selection. It's a data audit that tells you what you have.
A useful audit for materials R&D should answer five questions:
- Which data sources matter most: Rank systems and file collections by their value to formulation, characterization, scale-up, and quality decisions.
- Which entities need consistent identity: List the objects that must be linked, such as sample, recipe, lot, instrument run, method, operator, and result.
- Where context is being lost: Find the handoffs where raw data gets separated from preparation details, processing logic, or interpretation.
- Which formats are structurally difficult: Flag proprietary files, image-heavy workflows, and machine outputs that need custom parsing or metadata wrappers.
- Which workflows are repeated enough to standardize: Focus on recurring assay and characterization patterns before edge cases.
A simple classification model helps:
| Data source | Typical issue | First unification move |
|---|---|---|
| Spreadsheet trackers | Inconsistent fields and units | Define canonical schema and unit normalization |
| ELN entries | Rich text without queryable structure | Extract key entities and link to experiment records |
| Instrument exports | Proprietary or inconsistent formats | Standardize export pattern and attach method metadata |
| Images and spectra | Weak searchability | Add descriptive metadata and sample linkage |
| Presentations and reports | Conclusions detached from source data | Link decisions back to underlying records |
The organizations that do this well don't try to centralize everything at once. They identify where reuse breaks first, then design the backbone around that fracture point.
Architecting a Centralized AI-Ready Data Backbone
A materials team reaches the same point sooner or later. Promising historical data exists across spreadsheets, ELNs, instrument folders, shared drives, and slide decks, but no one can answer a basic cross-project question without a week of manual cleanup. At that stage, centralization stops being an IT project. It becomes the foundation for faster formulation cycles, better model training, and fewer repeated experiments.
A centralized backbone links raw observations, derived datasets, metadata, process context, and analytical outputs in one queryable environment. For materials science, that matters because models depend on relationships, not file counts. The system has to connect a formulation to its ingredients, batch history, process conditions, intermediate signals, test methods, and measured properties. If those links are weak, you may have years of data and still only a narrow set that is usable for AI.
A clear target architecture helps teams make good decisions early.
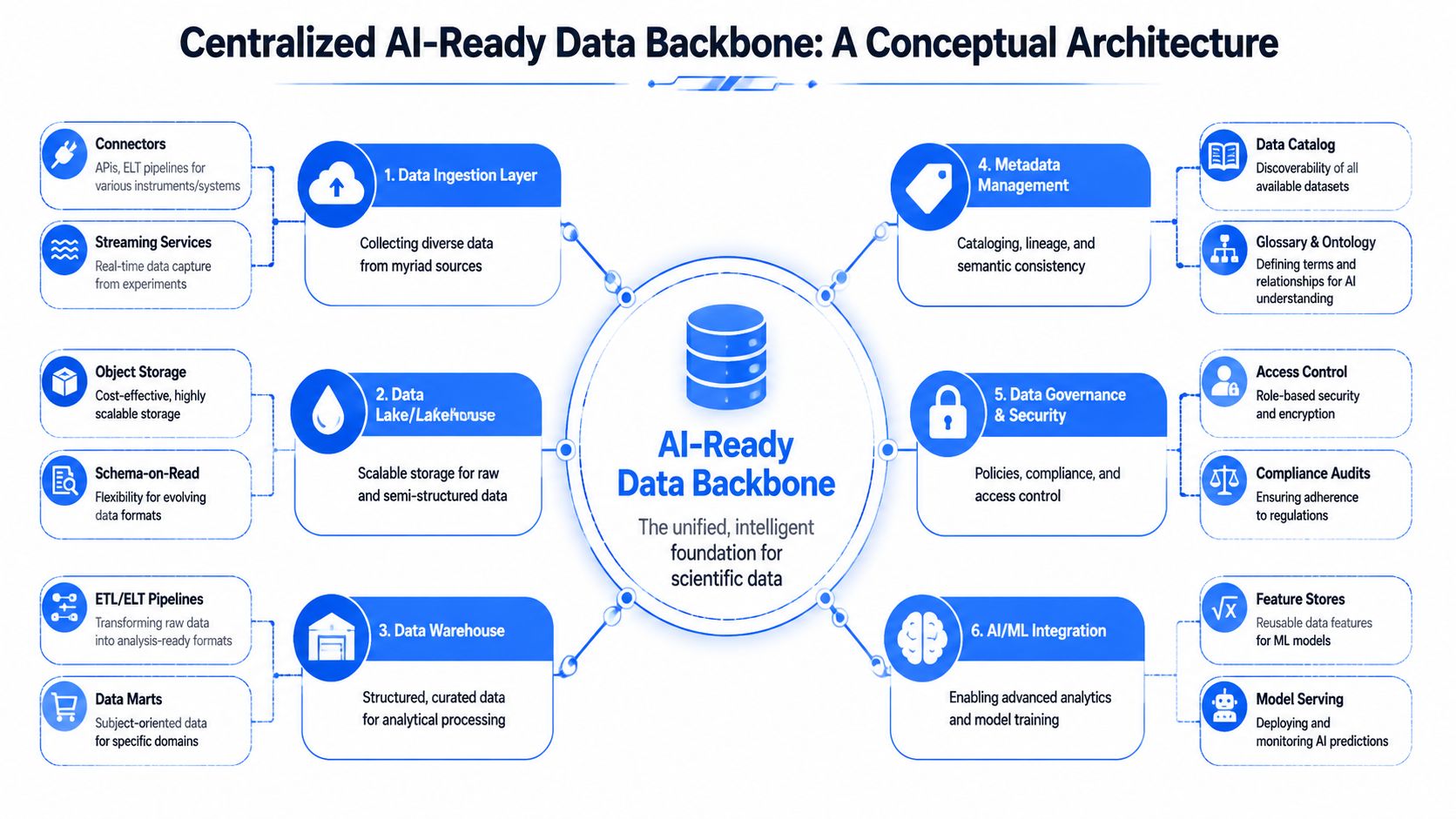
What the backbone must contain
In practice, a useful backbone has six layers that serve different purposes:
- Ingestion connectors that collect data from ELNs, spreadsheets, instrument software, shared drives, and lab applications.
- Raw storage that preserves original files and outputs in their native form.
- Curated analytical structures that hold standardized records analysts and models can query across studies.
- Metadata management that tracks definitions, lineage, search terms, and record relationships.
- Governance controls that manage permissions, audit history, and intellectual property boundaries.
- AI and analytics interfaces that expose approved data to modeling workflows, dashboards, and experiment planning tools.
The main architecture decision is not a generic debate over lake versus warehouse. The fundamental question is where each scientific object should live, how it should be represented, and how its identity persists across the stack. In materials R&D, raw files need to remain intact, while formulations, processing conditions, and property data need standardized representations that can be compared without reconstructing context by hand each time.
That trade-off matters. If you over-structure too early, scientists work around the system and dump data elsewhere. If you preserve everything as unstructured files, the backbone turns into a more expensive archive. The right design keeps raw complexity where it belongs and imposes structure where reuse, comparison, and modeling depend on it.
Why metadata quality determines whether AI scales
Teams usually discover the same problem during their first serious modeling effort. The limitation is rarely access to algorithms. The limitation is whether anyone can find comparable historical observations and trust that the surrounding conditions mean the same thing.
This short walkthrough gives a useful mental model for why architecture matters in practice.
A scientist searching for an impact-modified epoxy with a glass transition above target and viscosity inside a production window needs far more than filenames or project tags. They need structured composition data, method metadata, process conditions, lot history, and property records that have been checked for unit consistency and method comparability. Without that layer, search depends on memory, and AI outputs become hard to trust.
Three metadata domains deserve special attention in materials programs:
- Provenance metadata: the source of the record, the instrument or workflow that produced it, and the method version used
- Process metadata: mixing order, thermal history, cure profile, environmental exposure, hold times, and documented deviations
- Semantic metadata: controlled terms for materials, properties, methods, and units so records can be searched and compared computationally
A model can tolerate noisy measurements. It cannot recover missing identity or missing experimental context.
Centralized does not mean rigid
CTOs often worry that centralization will force every lab into one narrow operating model. In materials organizations, that concern is reasonable. A polymer synthesis workflow, a coating formulation study, and a battery materials characterization program will never produce data in the same way at the bench.
The better pattern is a centralized backbone with flexible edges. Let teams keep the tools that fit their work. Standardize the data contract at ingestion and curation. In practical terms, that means agreeing on core entities, identifiers, metadata minimums, and lineage rules, then mapping local workflows into that structure.
That approach is what makes the backbone AI-ready. It treats scientific context as part of the asset, not as cleanup work for analysts after the fact. Once that context is preserved consistently, data stops being trapped in project silos and starts supporting retrieval, comparison, prediction, and faster discovery across the portfolio.
Essential Workflows and Governance Practices
Architecture gives you a structure. Workflows keep it alive.
Most scientific data management efforts don't fail because the data model was impossible. They fail because ingestion is inconsistent, curation is optional, versioning is an afterthought, and permissions are handled informally until someone needs an audit trail. In materials R&D, that's where trust breaks.
The operational workflow that keeps data usable
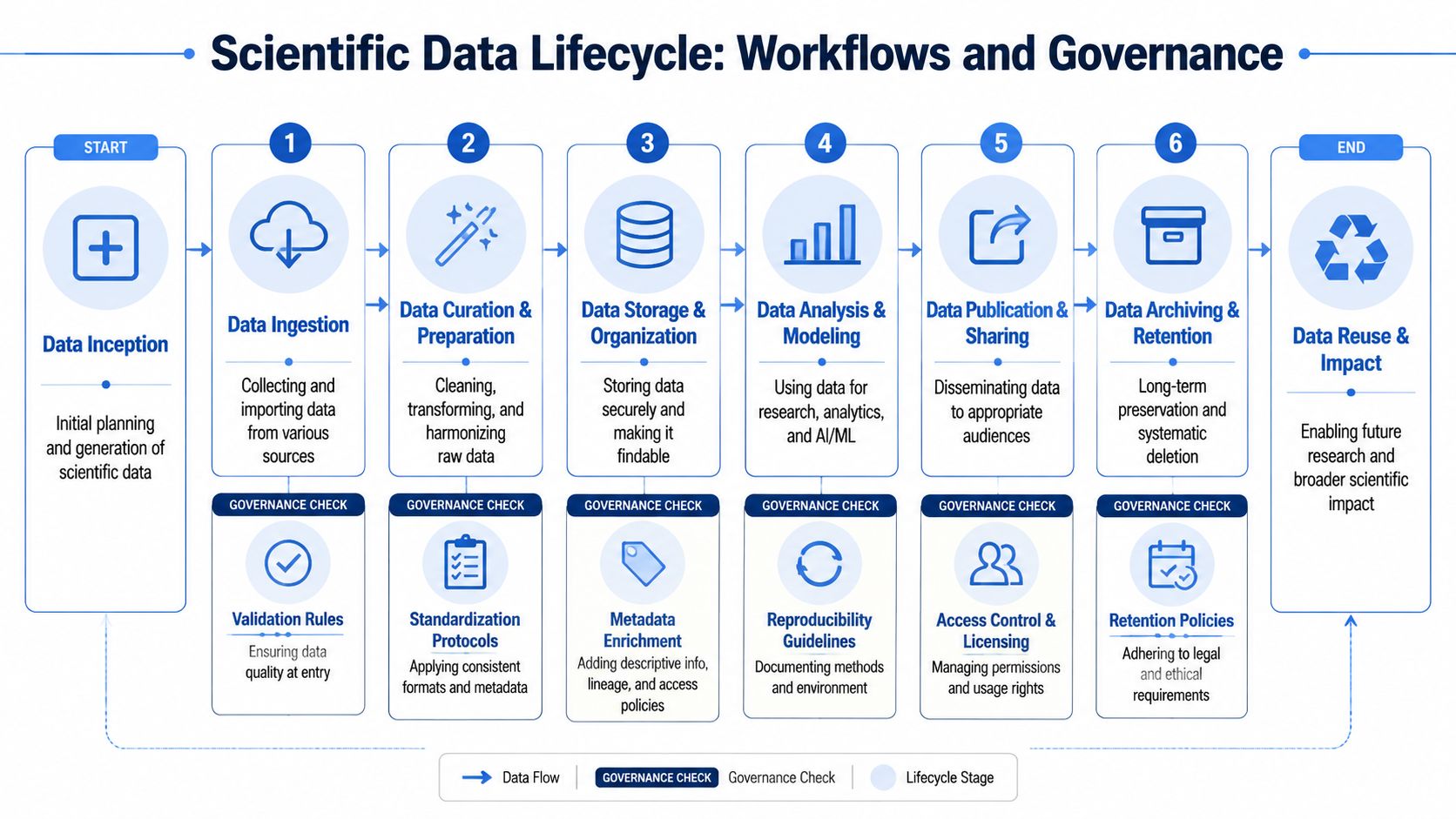
A durable operating model usually follows this sequence.
Ingestion should be as automated as possible for recurring sources. Instrument exports, assay outputs, and structured templates should land in the backbone with identifiers attached at the point of creation, not later through manual reconciliation. Manual upload is acceptable for edge cases, but if a workflow is frequent, automate it.
Curation is where raw records become usable records. Scientists often resist this stage because it feels like data janitorial work. The fix is to narrow the requirement. Curate the fields that matter for retrieval, comparability, and downstream analysis. Don't ask for a perfect ontology before the first dataset is usable.
Quality assurance needs explicit checks. Validate units, ranges, missingness, duplicate identifiers, and referential links. In materials workflows, one of the highest-value checks is consistency between sample identity, method identity, and reported result type.
Versioning is essential when methods, derived variables, or corrected datasets change. A high-performing data stack enforces consistent schemas, versioning, access control, and auditing, and expert guidance for scientific team data workflows recommends version-aware approaches that preserve history and support reproducible reporting, as described in this PMC framework for clinical and translational data engineering.
Governance controls that scientists usually resist until they need them
Governance should be visible enough to protect the system and quiet enough not to get in the way.
The minimum set looks like this:
- Schema control: Lock the core entities and required fields that define what a valid sample, experiment, or result record is.
- Audit trails: Record who changed what, when, and why, especially for corrected data and interpreted outputs.
- Access control: Separate open internal visibility from restricted projects, partner data, and high-value IP.
- Release rules: Distinguish raw, curated, approved, and published states so downstream teams know what they can trust.
- Retention logic: Keep raw data, methods, and lineage long enough to support later investigation and reuse.
A common mistake is treating governance as a policy binder. Scientists don't work in binders. They work in interfaces, templates, and default behaviors.
So the implementation question becomes practical:
| Workflow stage | What works | What doesn't |
|---|---|---|
| Ingestion | Instrument-linked capture and structured templates | Ad hoc uploads with no identifiers |
| Curation | Minimal required metadata and controlled vocabularies | Asking users to fill every field manually |
| QA | Automated validation plus steward review for exceptions | Spot checks after analysis is already underway |
| Versioning | Immutable raw layer and tracked derived datasets | Overwriting “final_v2_revised” files |
| Access | Role-based permissions tied to project context | Folder permissions managed by memory |
Watch for this failure mode: teams document governance perfectly and operationalize almost none of it. If the controls aren't embedded into the workflow, they won't hold under deadline pressure.
For materials organizations, governance is not separate from speed. It's what prevents analysis pipelines, scale-up decisions, and AI models from drifting into untraceable territory.
Measuring Success and Integrating Your Ecosystem
The easiest way to undersell scientific data management is to evaluate it like an IT storage project.
If your success metrics are limited to files migrated, repositories connected, or records created, you'll miss the business case. A materials data backbone earns its keep when it shortens the path from question to decision and increases the share of historical work that can be reused with confidence.
What to measure besides storage and record counts
The most useful indicators are operational.
Track how long it takes a scientist to find comparable prior experiments for a new formulation. Track whether project teams can connect analytical results back to exact process conditions without manual investigation. Track how often historical datasets are reused in new analysis, model training, design reviews, or scale-up planning.
You can also look for directional signals such as:
- Faster time to first insight: Teams locate and trust prior work quickly enough to shape the next experiment.
- Lower rework from missing context: Analysts spend less time cleaning, reconciling, and interpreting detached files.
- Higher reuse of historical evidence: Project teams reference prior formulations, methods, and results instead of starting from scratch.
- Cleaner handoffs across functions: Formulation, characterization, process, and quality groups work from the same scientific record.
None of these needs a fabricated ROI formula to be credible. In practice, leaders see the value when researchers stop asking “where is that data?” and start asking “what does the historical pattern suggest?”
Integration is where many programs stall
One of the biggest challenges in scientific data management is finding software that effectively supports scientists' day-to-day workflows. Poor integration can block reuse and AI adoption even when data is technically stored correctly, as highlighted in this News-Medical coverage of scientific data management challenges.
That observation lines up with what usually happens on the ground. Teams buy a repository, load data into it, and then keep doing the actual work somewhere else. The backbone becomes a passive archive rather than the operational system connecting bench work, analytics, and decision-making.
For materials R&D, integration has to cover at least four directions:
- Upstream lab tools such as ELNs, instrument software, and spreadsheet-based capture that scientists already depend on.
- Operational systems including LIMS, ERP, quality, and manufacturing records when development and scale-up need continuity.
- Analytical environments such as Python, R, SQL, dashboards, and notebook workflows used by data scientists and advanced users.
- AI applications that need governed access to curated, contextualized data rather than one-off exports.
The right design test is simple. Can the backbone sit in the middle of the workflow without forcing scientists into unnatural behavior? If the answer is no, adoption will stay shallow, and the data quality problem will return in a different shape.
Your Implementation Roadmap and Change Management
A CTO usually sees the problem first when a materials team asks a simple question and nobody trusts the answer. Which formulation matched this characterization result? Which process change affected the final property? Which dataset is clean enough to train a model on without weeks of manual reconstruction? That is the point where scientific data management stops being an IT project and becomes an innovation constraint.
Most organizations should not try to rebuild the entire R&D data estate at once. Build the backbone in phases. Prove it on one workflow that matters to scientists and to the business. Then expand with discipline.
That sequence matters because adoption decides whether the architecture becomes operational infrastructure or another archive nobody wants to touch.
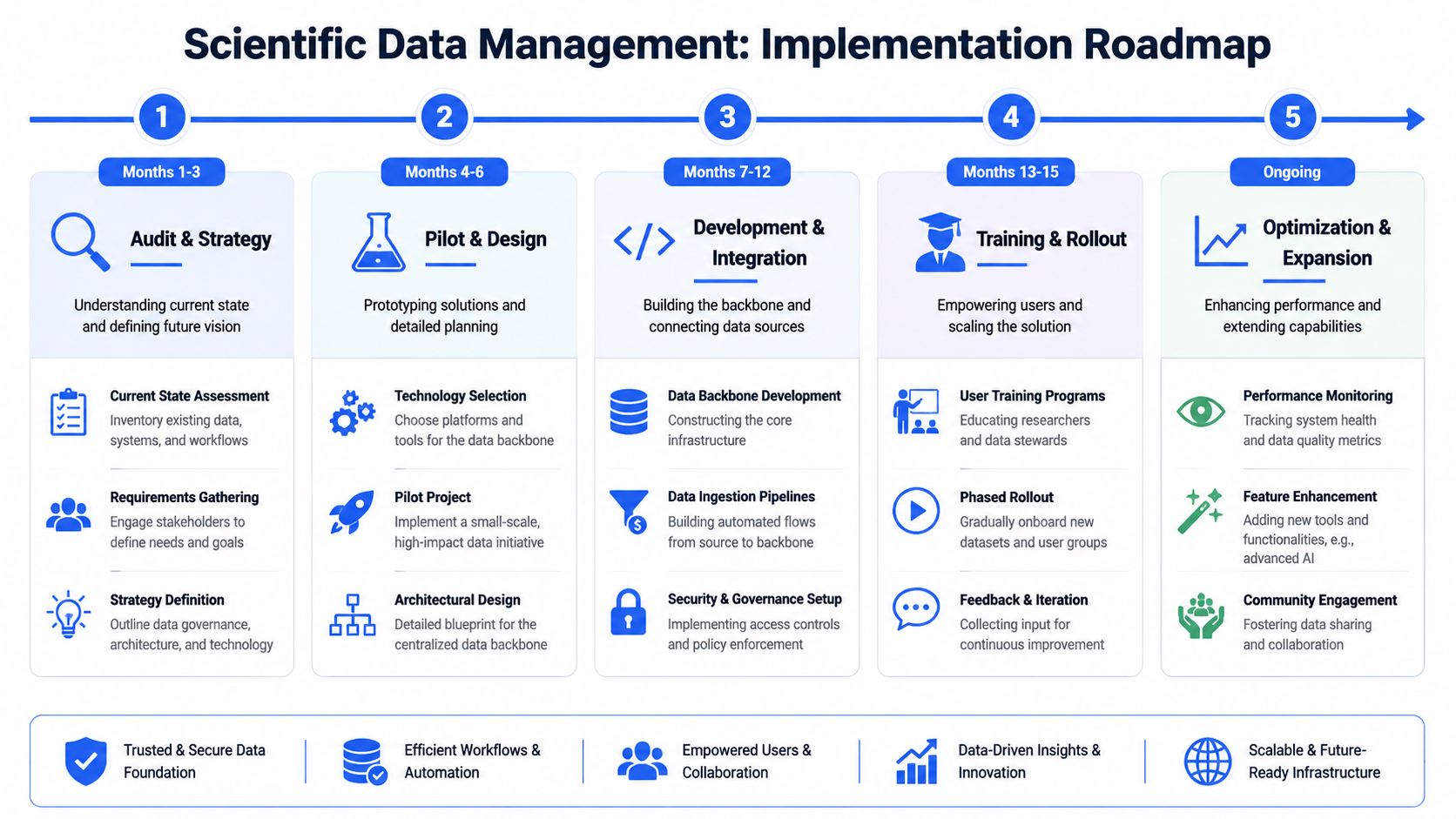
Phase 1 and 2 audit, strategy, and pilot
Start narrower than you think.
Phase 1 is audit and strategy. Inventory the data sources that change decisions, not every folder and instrument export in the company. Define the entities that need persistent identity across experiments, samples, formulations, methods, and results. Then pinpoint where the current process breaks down: repeated experiments because prior work cannot be found, analytical outputs detached from raw context, or handoffs between research and scale-up that depend on tribal knowledge. Set a governance model that is light enough to adopt and strict enough to support trust.
Phase 2 is pilot and design. Choose one workflow where better data continuity will be obvious within a quarter. In materials science, strong pilots often sit in formulation screening, characterization-intensive development, or transfer from lab to pilot scale. The pilot needs real ingestion, metadata capture, search, lineage, and reuse. A storage demo will not change behavior.
Use four criteria to choose that pilot:
- The workflow happens often: Repetition creates a clear return from standardization.
- Multiple groups rely on the output: Shared value builds support faster than a single-team use case.
- The current pain is visible: Scientists already spend time hunting, reconciling, or second-guessing the data.
- The data could support later modeling: The pilot should produce records that can feed future AI or decision-support work.
The strongest pilot is usually not the most advanced science. It is the workflow where fixing data continuity saves time immediately and improves technical decisions.
Phase 3 and 4 build, integrate, and roll out
After the pilot proves the pattern, expand carefully.
Phase 3 is development and integration. Build the core backbone and connect it to the systems people already use. Automate ingestion where repetition justifies the effort. Put access controls, auditability, and curation in place early. Keep the data model practical. In the first release, stable identifiers, a small set of required metadata fields, and reliable links across sources matter more than an elaborate ontology nobody can maintain.
Teams often overbuild. I have seen programs spend months debating naming standards while scientists keep working in spreadsheets because the new system still does not help with retrieval or comparison. A better approach is to standardize the fields that drive reuse and keep room for local variation where the science is still evolving.
Phase 4 is training and rollout. Technical success can still fail here. Training needs to match real roles. Bench scientists need clear rules for what metadata they must capture and what they get back in return. Data stewards need a process for exceptions, schema updates, and quality checks. Leaders need operating metrics that show whether the system is reducing cycle time, improving reuse, and making cross-team handoffs cleaner.
A few change-management practices consistently work:
- Show retrieval wins early: Let scientists find and compare prior experiments in minutes.
- Use lab vocabulary: Train around sample lineage, method traceability, and result interpretation.
- Keep domain experts involved: Lab leads and analytical specialists should shape schemas and vocabularies.
- Capture once where possible: Reduce duplicate entry through integrations rather than asking researchers to retype context.
Phase 5 optimize and make the system self-improving
At maturity, the backbone starts improving itself because people use it to ask better questions.
That usually means refining metadata models, improving search, expanding connectors, and closing the context gaps that still hurt downstream work. In materials R&D, those gaps are often specific: weak image metadata, inconsistent recording of process deviations, poor visibility into method versions, or property measurements that cannot be compared confidently across instruments and sites.
The target state is an operating backbone for discovery. Experimental data stays messy at the edges because science is messy at the edges. What changes is that the important context no longer disappears into spreadsheets, local drives, or disconnected ELN records. The organization can search across past work, connect results to methods and materials history, and prepare datasets that are usable for analytics and AI without starting from scratch each time.
If your materials organization is trying to move from scattered spreadsheets and siloed lab records to an AI-ready R&D backbone, Polymerize is worth evaluating as part of that stack. It is built for materials teams that need to unify experimental data, preserve scientific context, and connect that foundation to AI-driven discovery workflows without treating data management as a separate administrative layer.

