Monday morning, a formulation scientist is looking for stability data from a study run 18 months ago. The raw files are still on an instrument PC, the summary sits in a spreadsheet with unclear version history, and the person who named the folders left the company last quarter. The data exists, but the team cannot use it with confidence or speed.
That pattern shows up across R&D. Experimental results are scattered across instrument software, spreadsheet trackers, ELNs used differently by each group, shared drives full of weak metadata, and personal folders that disappear from view as roles change. The immediate cost is wasted time. The larger cost is strategic. Teams repeat experiments, struggle to reproduce prior work, and make slower portfolio decisions because the evidence base is fragmented.
Research data management software addresses that problem by creating structure around scientific data, context, and ownership. Done well, it becomes part of the operating model for R&D, not another repository to maintain. It gives teams a controlled way to capture metadata, preserve provenance, connect records across systems, and keep data usable long after the original project team has moved on.
That long-term usability point gets missed in many buying cycles. So does storage economics. In high-volume R&D environments, software selection is not only about search, collaboration, or compliance. It is also about whether future teams can still interpret the data, and whether the storage model remains financially workable as instruments, imaging, and assay platforms keep producing larger files. Those two factors usually decide whether an RDM platform becomes durable infrastructure or an expensive archive.
Table of Contents
- It manages the full research lifecycle
- It adds structure that survives team changes
- What RDM software is
- Reproducibility and knowledge retention are business issues
- FAIR is practical, not academic
- Why this changes the pace of discovery
- Metadata makes data usable years later
- Provenance protects reproducibility and decision quality
- Integration quality matters more than integration count
- Access control has to match how R&D actually operates
- Auditability and operations decide whether the platform holds up
- Test long term usability under real conditions
- Put storage economics into vendor selection
- Pilot around a workflow with visible pain
- Measure friction where work actually slows down
- Connect RDM value to decisions, reuse, and cost control
- Use ROI to prioritize the roadmap
Your R&D Data Is Everywhere Is It Driving Innovation
Organizations often know where their newest data is. They have a much harder time finding the right historical data with enough context to trust it.
That's the familiar pattern in materials, chemicals, and formulation R&D. Raw instrument outputs sit in one environment. Experimental plans and observations sit in another. Calculations happen in Excel. Decisions get summarized in slide decks or email threads. Months later, a new team tries to reuse the work and discovers they have files, but not understanding.
Data chaos blocks more than compliance
This isn't just an admin problem. It affects cycle time, reproducibility, and handoffs between discovery, scale-up, quality, and manufacturing. If a formulation scientist can't tell which version of a dataset fed a conclusion, or if a project lead can't compare like-for-like results across programs, decision quality drops fast.
Research data management software matters because it imposes structure where labs usually accumulate exceptions. It links data to metadata, methods, ownership, and access rules. It gives teams a place where records can be found, interpreted, and governed consistently.
Practical rule: If a scientist has to ask a former colleague how to understand a dataset, your data system is storing files, not knowledge.
What good looks like in practice
A workable RDM environment does a few things at once:
- Centralizes research records: It gives teams one governed environment instead of scattered storage across drives, inboxes, and instrument PCs.
- Standardizes context: It captures metadata, methods, and version history so results remain interpretable.
- Supports collaboration: It lets chemists, engineers, analysts, and digital teams work from the same record base.
- Protects continuity: It prevents critical knowledge from leaving with one scientist or one project team.
The business case is straightforward. Faster retrieval, clearer lineage, cleaner handoffs, and fewer avoidable repeats all improve how R&D works day to day. The organizations that treat data as infrastructure, not exhaust from experimentation, tend to make better use of every experiment they already paid for.
Beyond a Digital Filing Cabinet What RDM Software Is
A scientist reruns an experiment from last year because the original files are still there, but the method settings, sample context, and processing steps are not. That is the line between file storage and research data management.
Research data management software gives R&D a structured system for preserving not just records, but meaning. It connects raw data, metadata, workflows, versions, permissions, and retention rules so another team can find the work later and trust what they found. In practice, that matters as much for future usability as it does for day-to-day efficiency.
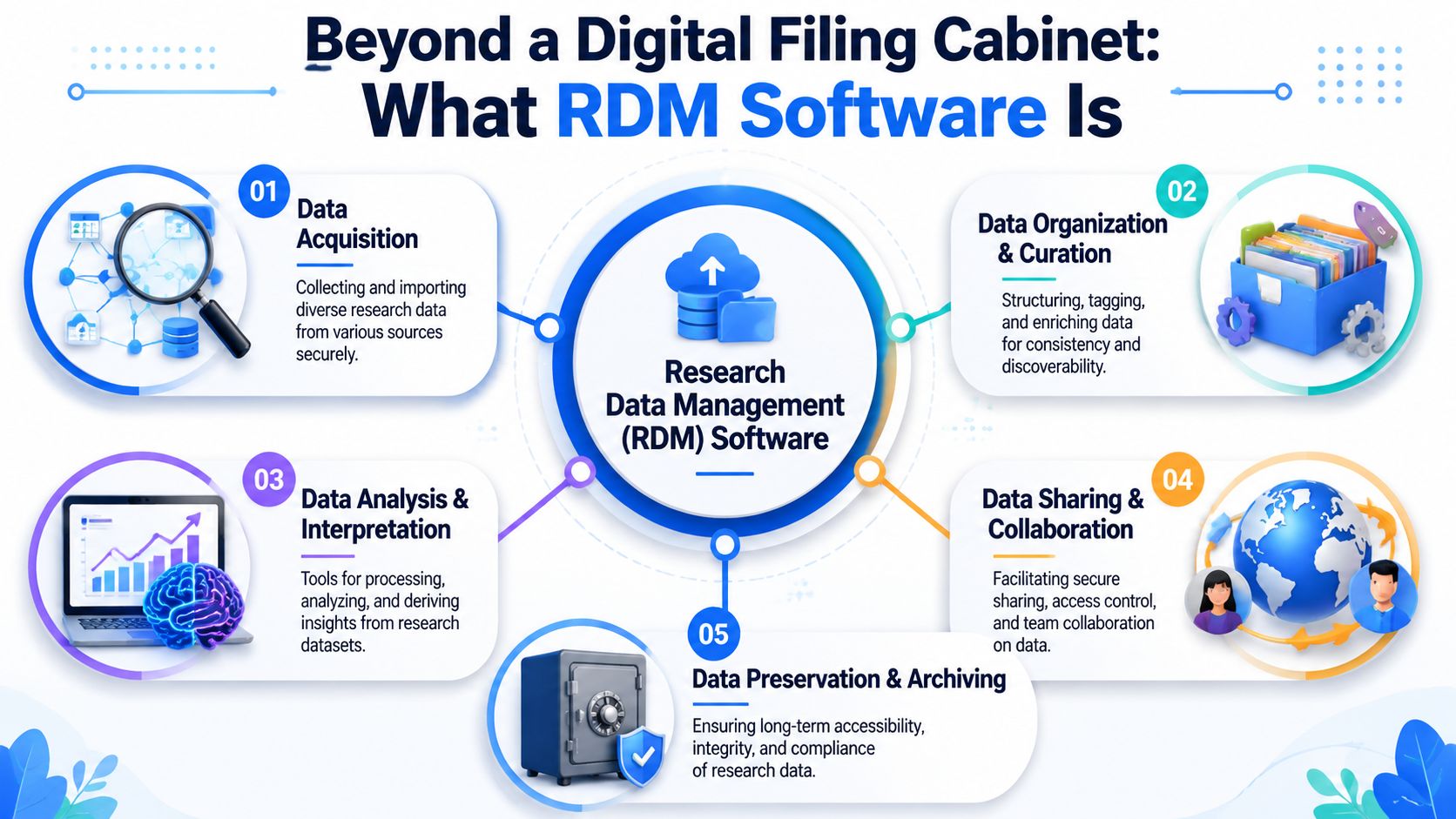
It manages the full research lifecycle
The scope is broader than storage, search, or document control. Research data management covers how data is collected, described, checked, stored, shared, retained, and reused over time. Many organizations also expect data planning to start early in the project rather than after results accumulate.
That has direct technical implications. An RDM platform needs to handle instrument output, derived data, metadata capture, review steps, access control, retention schedules, and archival policies in one governed environment. If it only stores final reports, it loses the evidence trail behind the result.
This is also where software selection often goes wrong. Teams buy for immediate retrieval and collaboration, then discover two years later that they cannot read old formats, interpret undocumented fields, or afford to keep everything in premium storage. Good RDM software has to support long-term reuse and a realistic storage model, especially in data-heavy R&D functions such as materials, biologics, imaging, and process development.
It adds structure that survives team changes
Useful RDM software captures the information another scientist or data engineer will need later, not just what the original project team already knows:
- Collection context: instrument, method, sample, batch, operator, and experimental conditions
- Data organization: agreed schemas, identifiers, naming rules, and controlled metadata
- Version and lineage: what changed, when it changed, who changed it, and what downstream work used that version
- Supporting documentation: methods, calculations, notes, and decisions tied to the record
- Retention and preservation: policies for archiving, storage tiering, and access over time
The storage tiering point gets overlooked. High-volume R&D produces expensive data footprints fast. Spectra, images, simulation outputs, sensor streams, and intermediate files all compete for budget. A credible RDM strategy separates high-value, frequently used data from material that can move to lower-cost archival storage without losing traceability or access control. Otherwise, the platform becomes costly to maintain and teams start bypassing it.
I push back when organizations say SharePoint, Box, or disciplined folders already solve data management. Those tools can store and share files. They usually do not enforce a scientific data model, capture lineage at the right level, or preserve enough context for reuse across teams and time.
Well-labeled files are still weak research memory if the links between samples, methods, transformations, and outcomes are missing.
What RDM software is
RDM software is the governed data layer across the research process. It can connect to ELNs, LIMS, instrument systems, data lakes, and cloud storage, but its job is different. It creates a consistent structure around scientific records so data remains interpretable after the project ends, after staff change, and after systems are replaced.
That is the core business case. A good platform reduces search time and improves control, but the larger payoff is continuity. It gives future teams a usable data backbone instead of a backlog of files with unclear value, unclear provenance, and unclear storage cost.
From Trial and Error to Data Driven Discovery
Materials and chemical R&D still runs on expertise, judgment, and iteration. That won't change. What should change is how much of that iteration is avoidable.
In most labs, trial and error gets more expensive as projects move forward. Early ambiguity is tolerable. Late-stage ambiguity is not. If a team can't reproduce a promising result, can't trace why one batch behaved differently, or can't retrieve failed experiments that already eliminated a path, the organization pays twice. First in wasted effort, then in delayed decisions.
Reproducibility and knowledge retention are business issues
The strongest argument for research data management software in industrial R&D isn't administrative neatness. It's operational control over scientific learning.
Structured data-management software has shown measurable gains in adjacent enterprise settings. Organizations using MDM software have reported up to a 20% increase in data accuracy and up to a 15% improvement in organizational efficiency, according to Semarchy's summary of Gartner-referenced master data management statistics. In research environments, that matters because every improvement in data quality and retrieval reduces friction in analysis, review, and reuse.
When a senior scientist leaves, unmanaged labs lose more than a person. They lose tacit knowledge encoded in naming habits, spreadsheet logic, and undocumented assumptions. RDM software can't preserve judgment by itself, but it can preserve the record structure that lets the next team understand what happened and why.
FAIR is practical, not academic
The FAIR principles get treated like policy language in some organizations. They're much more useful than that.
A dataset should be:
| FAIR principle | What it means in day-to-day R&D |
|---|---|
| Findable | Teams can search by material, formulation, method, batch, or condition and get the right record |
| Accessible | Authorized users can retrieve data without asking around for folders or exports |
| Interoperable | Data can move between systems and still keep meaning |
| Reusable | A new scientist can understand and apply it later |
That framework changes how teams think about value. A result isn't valuable because it exists. It's valuable because someone else can find it, trust it, and build on it.
Why this changes the pace of discovery
In materials programs, speed doesn't come only from running more experiments. It comes from reducing uncertainty between experiments.
A governed data backbone helps teams compare formulations across projects, revisit negative results, and connect process conditions to outcomes with less manual reconstruction. That lowers the odds of repeating work and improves the quality of handoffs from research to development and scale-up.
For CTOs and R&D leaders, the strategic point is simple. If your data remains fragmented and weakly structured, innovation depends on memory and heroics. If your data is governed and reusable, innovation becomes more repeatable.
Essential Features of Enterprise Grade RDM Platforms
Enterprise buyers often get trapped in feature comparison spreadsheets. The harder question is whether the platform will preserve scientific meaning after team turnover, method updates, instrument changes, and years of accumulated records.
That standard rules out a lot of attractive demos.
An enterprise RDM platform has to do more than store files. It needs to preserve context, control access, document changes, and support a cost model that still works when data volumes climb. Long-term usability and sustainable storage planning get less attention than search, dashboards, or user interface design, but they matter more once the system is in production.
Guidance on effective data management planning points to three capabilities that keep research records usable over time: granular authorization, metadata capture, and auditable workflows, as described in this research data management implementation guidance from PubMed Central.
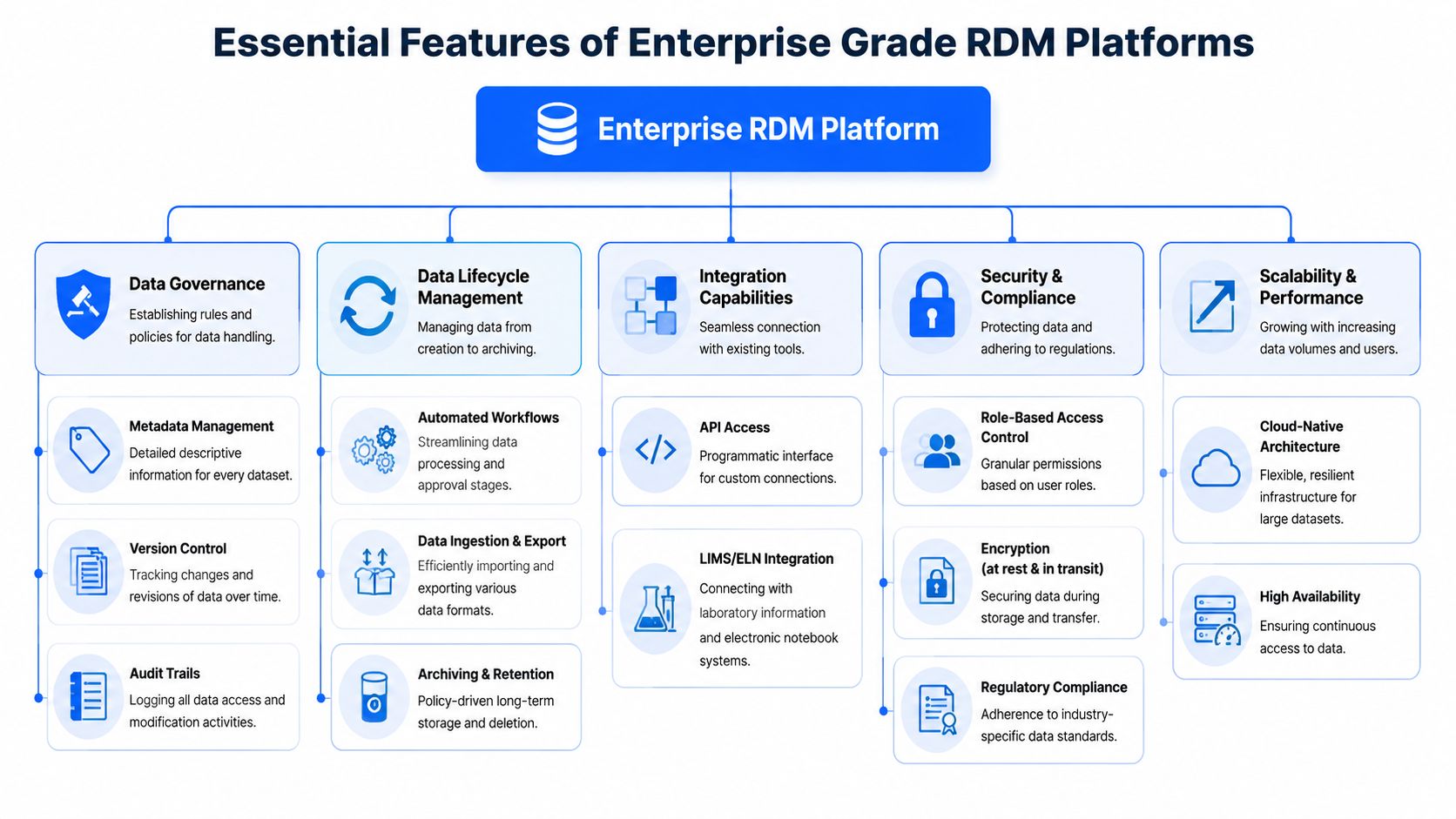
Metadata makes data usable years later
Metadata is what lets a future team understand what happened without tracking down the original scientist.
If a DSC trace, rheology result, or formulation output lands in the system with only a file name and timestamp, the data is technically preserved but practically weak. You may still have the result, but not enough context to compare it across projects, verify how it was produced, or reuse it in a later program.
Useful platforms support metadata in ways that match real lab work:
- Configurable schemas: Experiment classes, materials, and analytical methods need different structures.
- Controlled vocabularies: Sample names, units, methods, and material identifiers have to stay consistent.
- Capture at the point of work: Metadata entered later is often incomplete, inconsistent, or missing the details that matter.
I usually test this with a simple question during evaluation. Can a scientist who did not run the experiment understand the record six months later and compare it to similar work without asking for help? If the answer is no, the metadata model is too thin.
Provenance protects reproducibility and decision quality
Provenance is the recorded path from raw observation to reported conclusion.
In industrial R&D, that path matters well beyond compliance. It affects reproducibility, IP support, internal review, technical transfer, and root-cause investigation. Teams need to know which source files fed a processed dataset, which calculations or scripts transformed it, who reviewed it, and what changed after approval.
Without that record, every dispute turns into forensic work. People dig through shared drives, local notebooks, and email threads to reconstruct history after a result is already influencing project decisions.
If a team cannot trace a result back to its source conditions and transformation steps, it cannot test that result properly or defend it credibly.
Integration quality matters more than integration count
A vendor can list dozens of integrations and still leave you with manual work at the points that matter.
The practical requirement is reliable data flow between the systems your teams already use. ELNs, LIMS, instrument software, assay tools, data processing environments, and business systems all create pieces of the record. If the RDM platform depends on manual export and upload between those steps, data quality will drift and adoption will weaken.
Priority integrations usually include:
- ELN connections: To keep experimental intent, execution, and outcomes linked
- LIMS connections: To preserve sample identity, status, and workflow context
- Instrument and assay software: To reduce transcription and late-stage file handling
- Analytics environments: To maintain traceability from raw data through interpretation
The trade-off is real. Deep integrations take time and governance discipline. They also reduce re-entry, lower ambiguity, and make the system part of daily scientific work instead of a repository people update after the fact.
Access control has to match how R&D actually operates
R&D permissions rarely fit a simple open-or-closed model.
Access usually varies by program, site, function, collaborator, development stage, and IP sensitivity. A formulation scientist may need visibility into summarized partner results but not adjacent programs. A process engineer may need approved records for scale-up work without edit rights on exploratory research. External collaborators may need to contribute data inside a governed workflow without broad repository access.
Role-based access is the starting point. Fine-grained permissions are what prevent workarounds.
If the model is too coarse, teams create side channels. They export files, keep local copies, and share data outside the system. Once that starts, governance degrades quickly.
Auditability and operations decide whether the platform holds up
Audit trails should answer basic operational questions without manual reconstruction. Who created the record. Who modified it. Which version was reviewed. What was approved. What was exported, and by whom.
That record supports quality reviews, dispute resolution, deviation analysis, and confidence in cross-team decisions. It also has to sit on top of a platform that performs reliably under real load. Slow search, unstable sync jobs, and weak uptime discipline will erode trust even if the data model is sound.
Storage architecture belongs in this discussion too. High-volume R&D groups generate expensive data footprints, especially when raw instrument outputs, images, spectra, simulation files, and derived datasets are all retained. Ask vendors how they handle tiered storage, retention policies, archival access, and cost growth across multiple years. A platform that works economically at pilot scale can become difficult to justify once enterprise usage expands.
The right platform creates a structured data backbone that can survive team changes, support future reuse, and scale without turning storage cost into a budgeting problem.
Making Your R&D Data AI Ready
A data science team gets asked to predict formulation performance from five years of experiment history. They quickly find the actual problem is not model selection. The problem is that the underlying records were never captured in a way a model, or even another scientist, can reliably interpret.
That is why many AI programs in R&D slow down before any modeling work produces value. Historical results sit across spreadsheets, instrument files, ELNs, shared drives, and local folders. Teams can assemble a one-off dataset for a pilot, but that manual cleanup effort does not hold up across business units, methods, and years of accumulated work.
Why AI projects fail before modeling starts
In materials, formulation, and process development, machine learning only works when inputs, process conditions, methods, and results stay connected. If those links are inconsistent or missing, the dataset looks larger than it really is. Scientists spend more time reconstructing experiment context than testing hypotheses.
In practice, the common failure modes are predictable:
- Inconsistent naming: the same material, sample, or test appears under different labels
- Missing context: results exist without full process parameters, environmental conditions, or method details
- Broken lineage: transformed datasets lose the connection to raw files and original experiments
- Team-level silos: useful records remain inside one function and never become reusable organizational data
APIs and instrument integrations matter here, but only as part of a broader operating model. Automated ingestion reduces manual entry and cuts transcription errors. It also gives teams a way to capture data at the point of generation, before context is lost in email threads, file exports, or offline spreadsheets.
I have seen organizations buy AI tools before fixing this layer. The result is usually the same. A small pilot succeeds because a few experts hand-curate the dataset, then the broader program stalls because that effort cannot be repeated at enterprise scale.
What an AI ready data backbone looks like
AI-ready R&D data has a few clear characteristics. Metadata is structured enough to filter experiments by material class, process window, formulation variables, test conditions, and outcome type. Provenance is retained so teams can trace a prediction back to the source records and judge whether the evidence is credible. Data from current and historical work can be combined without rebuilding the experimental story by hand.
Long-term usability matters just as much as current model performance. Future teams need to understand what a dataset means, how it was generated, which assumptions shaped it, and whether it is still fit for reuse. If your platform stores files without preserving that context, you are creating technical debt that will surface later in model validation, transfer projects, and regulatory review.
Cost discipline matters too. AI-ready data strategies often fail because nobody plans for the storage economics of raw instrument outputs, images, spectra, simulation files, and derived datasets. The right RDM environment should support selective retention, lifecycle policies, and storage tiering so the business can preserve high-value context without treating every file as equal forever.
One practical example is a platform that combines a centralized R&D data layer with AI workflows. Polymerize is one option used in materials R&D, with a focus on consolidating fragmented experimental records from spreadsheets, ELNs, and other systems into a structured environment that supports downstream analysis and AI use.
AI increases the return on good data discipline. It also exposes weak discipline quickly.
Here's a useful walk-through on how teams think about the connection between data infrastructure and scientific AI in practice:
Better models start with better records. In R&D, missing context usually matters more than missing files.
If your organization is funding AI initiatives, treat research data management software as part of the same investment case. The business value comes from building a data backbone that future teams can still use, and that finance can still afford, once data volumes scale.
A Strategic Guide to Vendor Evaluation and Adoption
A vendor demo goes well. Search is fast, dashboards look clean, and the workflow builder checks the obvious boxes. Six months after launch, scientists still export data to spreadsheets to make sense of old work, and IT is fielding questions about storage growth no one priced properly. That gap between demo quality and operating reality is where many RDM selections fail.
The strongest evaluations focus on two questions early. Will future teams be able to understand and reuse today's data without relying on the original project team? And will the platform still make financial sense once instrument files, images, spectra, simulation outputs, and derived datasets start piling up?
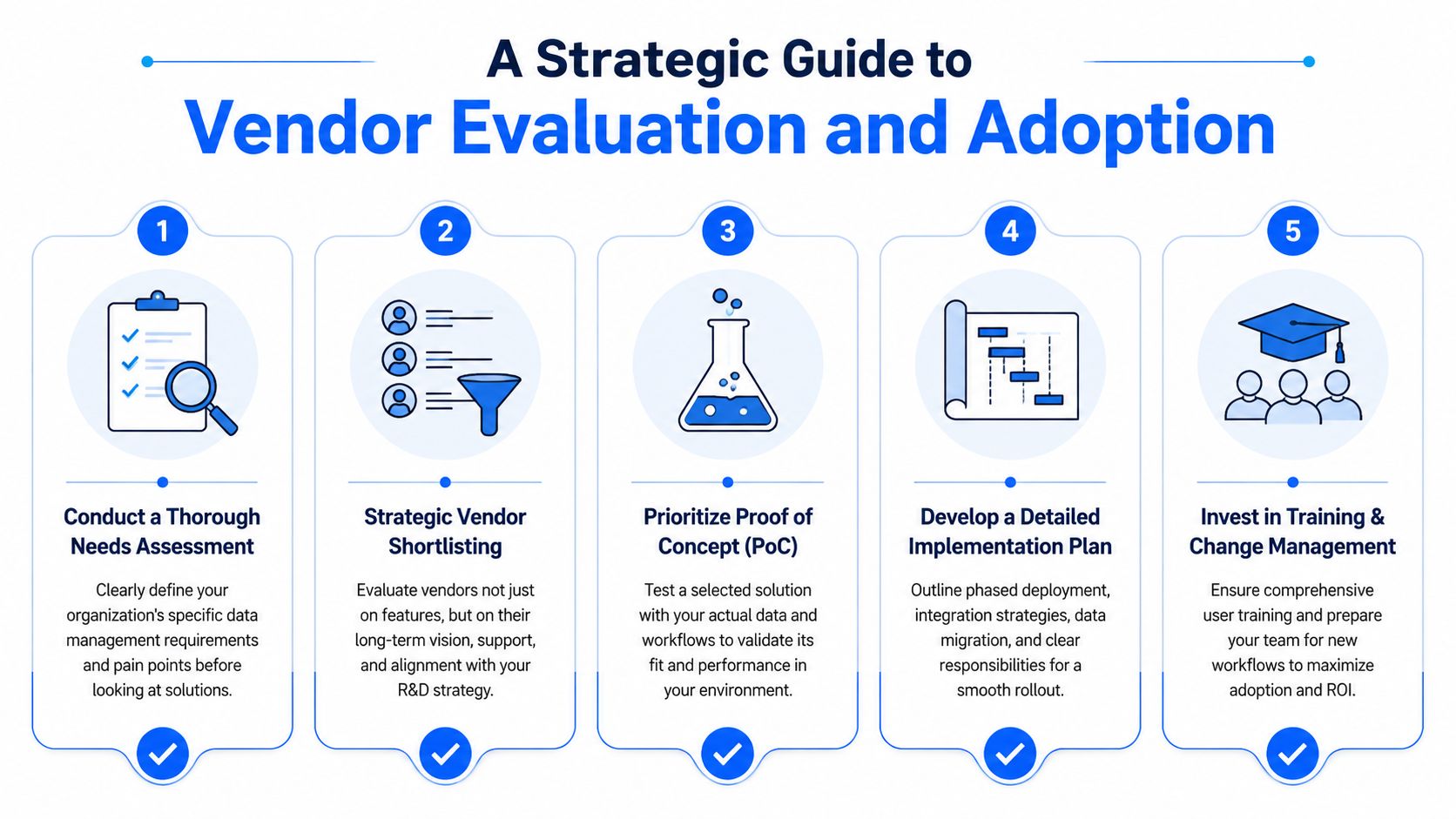
Test long term usability under real conditions
Feature comparisons often reward what is easy to show in a one-hour demo. Long-term usability is harder to fake, and it matters more. Guidance in this PubMed Central article on active data management planning and long-term reuse makes the point clearly. Reusable research data needs provenance, methods, documentation, and code or analysis context, not just stored files.
I recommend giving vendors a closed project and asking them to walk through it as if the original scientist has left the company. The test is simple. Can a capable new team member understand what was done, why it was done, what changed over time, and whether the data is safe to reuse?
Use scenario-based evaluation, not generic scoring sheets.
| Evaluation question | What you want to see |
|---|---|
| Can a new user interpret the record? | Linked methods, provenance, notes, ownership, and version history |
| Can teams preserve context over time? | README-style documentation, attachments, relationships, and update workflows |
| Can non-original users reuse data safely? | Clear metadata, controlled vocabularies, and understandable lineage |
A platform can look polished and still fail this test. I have seen systems with good search return the right file and none of the context needed to trust it. For R&D, that is a retrieval system, not a knowledge system.
Put storage economics into vendor selection
Storage strategy belongs in the evaluation phase, not in a later infrastructure workstream. If the vendor cannot explain how data moves across storage tiers, how retention rules are applied, and what retrieval or migration costs look like over time, the business case is incomplete.
This matters most in high-volume environments. Analytical instruments, microscopy, imaging, simulation, and automated experimentation can produce data faster than governance practices mature. The software decision and the storage decision are tied together, whether the buying team acknowledges it or not.
A serious vendor review should cover:
- Hot versus cold storage logic: what stays instantly accessible and what can shift to lower-cost tiers
- Retention policy controls: how records are archived, preserved, or deleted under policy
- Lifecycle cost visibility: how storage, retrieval, migration, and support costs change over time
- Operational trade-offs: how retrieval speed, governance, and cost affect each other
Cheap ingestion creates expensive sprawl when no one defines what remains active, what moves to archive, and what still needs fast access for development or regulatory work.
Pilot around a workflow with visible pain
Adoption usually fails when the rollout is broad, abstract, and disconnected from a real operating problem. A narrower pilot gives better evidence and exposes process issues early.
Pick one workflow where fragmented data already causes measurable friction. Good examples include repeated formulation work across sites, poor retrieval of historical analytical results, or weak handoff between discovery and process development. Those cases create enough pain that scientists will tell you quickly whether the platform improves the work.
A practical adoption path usually looks like this:
- Map one priority workflow. Identify where data originates, where context drops out, and who needs the record later.
- Define the minimum governed record. Specify the metadata, provenance, files, methods, and approvals that must stay connected.
- Connect a small number of systems first. Start with the systems that cause the most rework when disconnected.
- Run with real users and real data. Demo records hide the messy edge cases that break adoption.
- Measure retrieval, reuse, and handoff quality. Those signals show whether the platform is creating a usable data backbone.
This is less dramatic than a company-wide launch. It is also more reliable. Vendor evaluation should tell you whether the software can support future science, future teams, and future data volumes without creating a cost structure the business regrets.
Proving ROI and Accelerating Your Innovation Roadmap
A year after implementation, the ROI question usually lands in a simple place. Are scientists finding prior work faster, reusing more of it, and making fewer decisions with partial context?
That is the business case for research data management software. The return does not come from having one more system in the stack. It comes from reducing avoidable experimental repetition, shortening handoffs between teams, improving technical review quality, and preserving data in a form that future groups can still interpret and use.
Measure friction where work actually slows down
Start with the points where work stalls today. In many R&D organizations, that means historical results are hard to retrieve, method context is buried in attachments or notebooks, and datasets need manual cleanup before anyone can compare them across projects.
A credible baseline usually includes a small set of operational measures:
- Time required to find and validate historical experimental data
- Rate of repeated experiments caused by missing, unclear, or untrusted prior records
- Cycle time for technical review, stage-gate, or portfolio decisions
- Effort required to prepare data for modeling, reporting, or downstream analysis
- Number of handoffs that still rely on manual exports, email, or spreadsheet consolidation
- Share of project records that include usable metadata, provenance, methods, and approvals
Perfection is not the goal here. Consistency is. If the same measures are tracked before and after rollout, teams can show whether the platform is removing real operating friction or just shifting it.
Connect RDM value to decisions, reuse, and cost control
Executives rarely approve an RDM program because the data layer looks cleaner. They approve it when cleaner, better-structured data changes the speed and quality of R&D decisions.
In practice, that shows up in a few concrete ways. Teams can reuse prior experiments instead of rerunning them. Process development can trace why a formulation or parameter set succeeded. New staff can pick up older programs without spending weeks reconstructing history. Data science groups can work with less wrangling because the records already carry enough context to be useful.
Long-term usability matters as much as short-term efficiency. If records are stored without consistent metadata, provenance, and method context, the organization keeps paying to rediscover what it already learned. The problem gets more expensive over time, especially after team changes, site expansions, or platform migrations.
Cost also needs its own scrutiny. High-volume R&D data can become expensive fast if every file is kept on premium storage, retention rules are vague, and ingestion is uncontrolled. A serious ROI model should include storage tiering, archival policies, expected data growth, retrieval patterns, and the labor needed to curate high-value records. Otherwise, the software looks affordable in year one and difficult to justify later.
A strong business case usually rests on three claims:
- The current operating model already carries hidden cost in labor, delay, duplicate work, and weak knowledge transfer
- Structured, governed data gains value over time because future teams can find it, trust it, and reuse it
- Storage and lifecycle policy determine whether the economics hold up as instrument output and project volume increase
Use ROI to prioritize the roadmap
The best ROI cases do more than justify purchase approval. They help sequence the transformation.
If one workflow loses weeks each quarter to poor retrieval and duplicate analysis, fix that first. If another generates large instrument files with low reuse value, design the storage policy before scaling ingestion. If a business unit expects to apply machine learning within the next year, prioritize the records and metadata standards that make those datasets usable later.
This is how RDM supports the innovation roadmap. It creates a structured data backbone that improves current execution and preserves scientific value for the teams that come next.
If your organization is trying to unify fragmented materials R&D data and create an AI-ready foundation, Polymerize is worth evaluating as part of that process. It's built for materials research workflows, with a centralized data backbone designed to bring together experiments from spreadsheets, ELNs, and disconnected systems so teams can manage data more consistently and support downstream analysis.

