A lot of innovation teams are in the same bind right now. They have a promising formulation in development, the market need is real, and the science is sound enough to justify more work. But the project keeps stretching. Data sits in spreadsheets. Instrument outputs live in separate folders. Scientists still rely on memory and side conversations to decide the next run. By the time the material is ready, the commercial brief has shifted, a competitor has moved first, or the original target spec no longer matters.
That's why the mandate to reduce R&D cycle time has changed. This isn't just about asking scientists to work faster or cutting a few days from lab scheduling. It's about building an end-to-end system that connects experiments, data, models, and lab execution so decisions happen sooner and bad paths get killed earlier. For a new VP of Innovation, that shift is usually the difference between incremental improvement and a pipeline that can keep pace with demand.
Table of Contents
- Start with a measurable cycle definition
- Separate planned loss from actual failure
- Use Pareto logic, not equal-opportunity problem solving
- Stop optimizing for activity
- Design for information density
- Build experiments that AI can actually use
- What the model should actually deliver
- Suggestion beats prediction alone
- Where leaders should be skeptical
- Start with a pilot that has operational pain
- Governance keeps gains from fading
- What the VP of Innovation should protect
The New Pace of Materials Innovation
The old materials R&D model had one brutal weakness. It assumed the market would wait.
In practice, long development cycles create strategic waste. Teams spend years refining a candidate, only to find that customer requirements have moved, feedstock assumptions changed, or internal priorities shifted to a different application. In chemicals and specialty materials, that problem used to be baked into the process because R&D cycles historically ran five to six years, while recent AI-driven prediction and focused formulation development have reduced that timeline to approximately two years, a 60% reduction in cycle time according to DKSH Discover's materials innovation discussion.
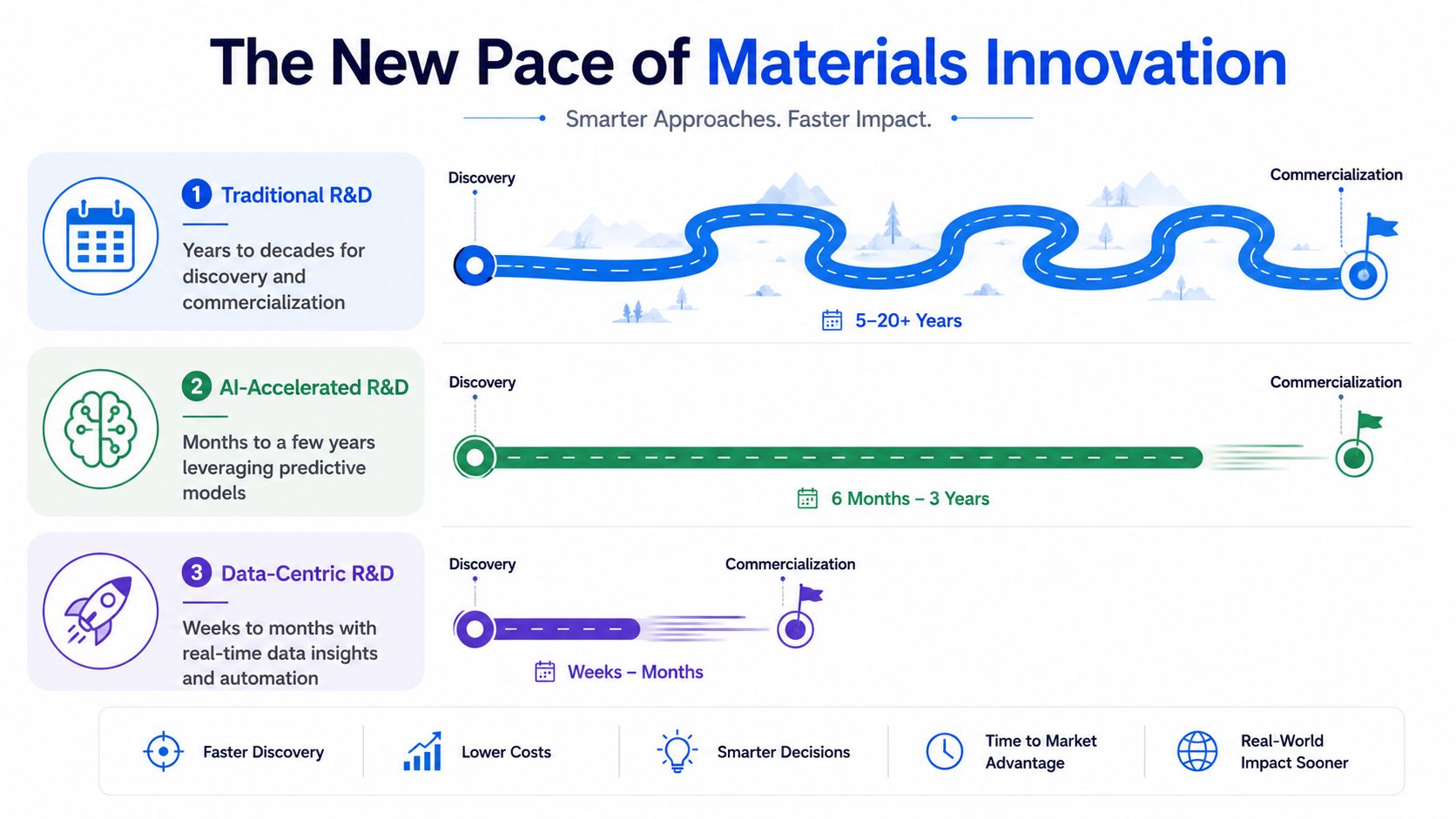
That gap matters because the modern race isn't only about inventing something novel. It's about validating faster, learning faster, and deciding faster. Teams that shorten the distance between hypothesis and evidence don't just launch earlier. They preserve optionality. They can pivot formulation strategy, swap target segments, or abandon a weak path before it consumes another quarter.
Why isolated fixes don't hold
Most organizations start with local fixes. They buy a new ELN, automate one instrument, or hire a data scientist to build a model on historical experiments. Those moves can help, but they rarely change total cycle time because the delays usually sit in the handoffs between steps.
A scientist finishes an experiment, but the result isn't structured for modeling. A model produces a recommendation, but no one trusts the input quality. A promising candidate is identified, but sample prep and testing still move through manual queues. The system stays slow because the workflow stays fragmented.
Reduce R&D cycle time by treating the workflow as one operating system, not a collection of disconnected tools.
What a faster operating model looks like
The practical shift is straightforward, even if the execution takes discipline:
- Measure the cycle correctly: Know where time is going, not where people assume it's going.
- Redesign experiments: Generate denser, more useful information per run.
- Build a usable data backbone: Bring scattered records into a structured environment.
- Apply predictive models: Use AI to narrow the search space and suggest the next move.
- Connect models to lab execution: Turn recommendations into action without manual friction.
- Govern the system: Make adoption durable so gains don't disappear after the pilot.
That's the true change in pace. Faster materials innovation doesn't come from one heroic team. It comes from a better architecture for decision-making.
Establish Your Baseline to Measure What Matters
Organizations often can't improve cycle time because they haven't defined it in operational terms. They know projects feel slow. They can point to too many meetings, too much waiting, or too many formulation rounds. But they don't yet have a baseline that separates normal process time from avoidable delay.
That distinction matters more than most leaders think. If you lump instrument maintenance, planned changeovers, and resource scheduling together with true breakdowns and rework, you get a distorted view of the problem.
Start with a measurable cycle definition
For materials R&D, cycle time should map to a decision-bearing unit of work. That could be:
| Cycle definition | Start point | End point |
|---|---|---|
| Formulation iteration | Approved test request | Decision to advance, revise, or stop |
| Screening campaign | First experiment queued | Candidate shortlist confirmed |
| Scale-up learning loop | Pilot run designed | Process window updated and accepted |
Pick one definition per workflow. Don't mix exploratory chemistry, application testing, and scale-up work into one average. That creates noise and weakens action.
Then instrument the workflow. According to Caddis Systems' cycle time guidance, organizations should collect 100+ automated cycle samples to establish a quantitative baseline and distinguish planned activities from unplanned downtime. The same guidance notes that a Pareto analysis typically shows most losses coming from a small number of causes such as unplanned downtime and changeover inefficiency.
Separate planned loss from actual failure
Many dashboards fail because they report one cycle number but hide the mechanics underneath.
Use a simple structure:
- Planned time: Scheduled setup, calibration, preventive maintenance, standard review windows.
- Execution time: The actual experiment or analytical work.
- Unplanned loss: Instrument faults, missing materials, queue interruptions, failed handoffs, repeat work due to poor data capture.
When teams make that split visible, the conversation changes. Instead of blaming "slow science," they can see whether the problem is queue design, equipment reliability, decision latency, or poor experiment packaging.
Practical rule: If your data can't tell you whether delay came from a planned constraint or an avoidable disruption, your baseline isn't ready for improvement work.
Use Pareto logic, not equal-opportunity problem solving
A new VP of Innovation will hear dozens of reasons that projects move slowly. Most are real. Only a few are decisive.
Run a Pareto review on the losses in your sampled cycles. In many organizations, one bottleneck station, one review gate, or one recurring handoff problem explains a disproportionate share of delay. That's where cycle-time work should start.
A useful diagnostic set includes:
- Time to first decision after experiment completion.
- Repeat-run frequency caused by ambiguous or incomplete outputs.
- Queue delay before critical instruments or approval steps.
- Changeover drag between formulations, methods, or test conditions.
Once the baseline is visible, you stop chasing symptoms. You can target the actual friction in the system.
Redesign Experiments for Speed and Insight
Running the same experiment faster is rarely enough. If the design is weak, you just produce bad learning at higher speed.
That's why teams that effectively reduce R&D cycle time rethink the experiment strategy itself. They stop treating each run as an isolated test and start treating each run as a data asset that should sharpen the next decision. In high-stakes R&D, that discipline matters because later-stage failure is expensive and slow to recover from. In clinical R&D, Phase II success rates are often below 50% and estimated as low as 30.7% in some studies, with efficacy responsible for 52 to 56% of failures, according to Knowledge Portalia's review of R&D time and success rates. The lesson transfers well to materials development: weak early evidence creates long, costly dead ends.
Stop optimizing for activity
A busy lab can still be a slow lab.
Teams lose months when they run one-factor-at-a-time studies that generate narrow conclusions, or when they test broad formulation spaces without a clear logic for exclusion. Scientists feel productive because benches are full and samples are moving, but the decision quality is poor. The project advances through motion, not evidence.
A better pattern uses three levers together.
Design for information density
First, use Design of Experiments where the question supports it. DOE doesn't remove domain expertise. It forces the team to encode it. Instead of changing one variable and hoping for a trend, scientists can test interactions, isolate sensitivity, and identify where the formulation is stable versus fragile.
Second, miniaturize where the chemistry and analytics allow it. Smaller-scale runs reduce material use, shorten preparation time, and let teams learn earlier without committing scarce inputs to every hypothesis.
Third, parallelize the work. That doesn't mean launching random runs in bulk. It means structuring campaigns so that multiple useful comparisons can be generated in the same lab window, with harmonized conditions and consistent capture.
The fastest experiment isn't the one that finishes first. It's the one that removes the most uncertainty.
Build experiments that AI can actually use
This is the part many organizations miss. AI-ready experimentation doesn't begin with model selection. It begins with structured experimental design.
For each run, teams should capture:
- Formulation context: exact ingredients, grade, source, and ratio.
- Process conditions: mixing sequence, temperature profile, dwell time, shear conditions.
- Response variables: not just pass/fail, but the measured outputs that shaped the decision.
- Exceptions: anomalies, operator notes, and deviations that explain outliers.
Sparse, inconsistent runs limit both scientific learning and model performance. Rich, structured campaigns do the opposite. They reduce ambiguity today and create reusable knowledge tomorrow.
A practical test helps here. After a campaign ends, ask whether another scientist could understand why the next experiment was chosen and whether a model could infer a pattern from the recorded data. If the answer is no, the campaign probably generated motion more than insight.
Build Your AI-Ready Data Backbone
Most materials organizations don't have a modeling problem first. They have a data architecture problem.
The signs are familiar. Formulation history lives in spreadsheets on shared drives. Analytical outputs sit in instrument folders with naming conventions only one person understands. ELN entries capture intent but not enough context. LIMS records are clean but narrow. When leadership asks for a portfolio view, teams spend days reconciling versions instead of learning from the data.
That setup blocks AI before the first model is even built.
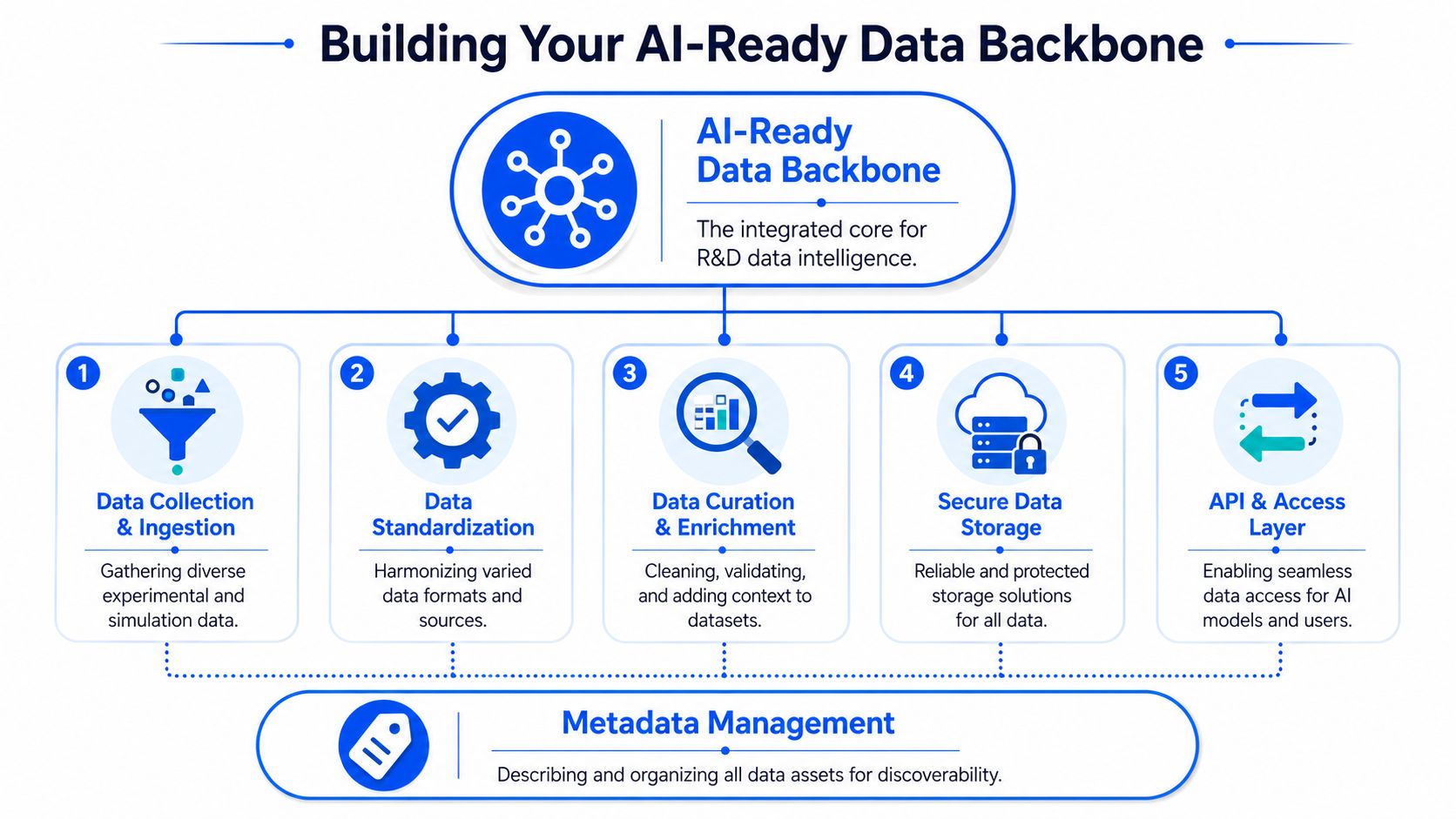
What the backbone must do
An AI-ready data backbone is a working system that makes experimental knowledge findable, structured, contextualized, and accessible to the right users and applications. It doesn't need to replace every legacy platform on day one. It does need to unify the records that drive formulation decisions.
In practice, that means connecting data from:
- Spreadsheets used for recipe tracking and ad hoc analysis
- ELNs that contain protocols, observations, and rationale
- LIMS and instrument software that hold test results and raw files
- Simulation outputs that may inform candidate selection
- Project systems where approval gates and decisions are recorded
The build sequence that works
Leaders often make this harder than necessary by aiming for a perfect enterprise ontology before any operational use. That usually stalls progress.
A more durable sequence looks like this:
Normalize identifiers early
Define consistent identifiers for materials, formulations, batches, experiments, and test methods. If one polymer grade appears under multiple names, the system will keep producing duplicate or conflicting histories.
Capture metadata as part of the workflow
Don't treat metadata as a cleanup task. Scientists won't backfill context reliably at scale. Build capture into the experiment process itself so key fields such as process settings, instrument configuration, operator, and intended objective are attached while the work is happening.
Curate for decisions, not for archives
Many repositories become digital warehouses. They store everything and support little. Curate records around decision use cases. A scientist asking for the next best formulation needs different structure than a quality team reviewing a test trail.
A data backbone earns trust when scientists can retrieve the history behind a decision without opening five systems and asking three people.
Secure access without killing usability
IP protection matters, especially in enterprise materials programs. But security models that make retrieval painful push people back to side spreadsheets. Use role-based access and clear permissioning so teams can share what they need without exposing what they shouldn't.
What good looks like
When the backbone is working, a scientist can pull up a candidate formulation and see prior experiments, conditions, measured properties, related failures, and the rationale for past decisions in one place. A model can consume the same structured history. Lab operations can reference it without rekeying information.
That is the foundation of an AI-native R&D system. Without it, every improvement stays local.
Leverage AI Models for Prediction and Suggestion
Once the data backbone is stable, AI stops being a slideware topic and becomes an operating tool.
The practical use case isn't "replace the scientist." It's narrower and much more valuable. The model helps the team predict likely outcomes, narrow the candidate space, and recommend what to test next. That changes the rhythm of formulation work because scientists spend less time screening obvious dead ends and more time evaluating promising regions of the design space.
A dashboard matters here because adoption depends on usability, not just model quality.
What the model should actually deliver
For materials R&D, useful models generally do one or more of these jobs:
- Property prediction: Estimate likely performance from formulation and process inputs.
- Formulation ranking: Prioritize candidates before the lab commits time and material.
- Next experiment suggestion: Recommend the run most likely to reduce uncertainty or improve a target property.
- Causal clueing: Surface which variables appear to influence outcomes most strongly.
Domain specificity matters. A generic ML workflow can fit a curve. It often can't help a formulation chemist decide whether to adjust a dispersant level, alter sequence, or revisit an incompatible ingredient class.
According to Deloitte's 2026 Chemical Industry Outlook, chemical companies using intelligent applications report faster turnaround from concept to validated material, with some organizations achieving up to a 50% reduction in failed experiments within just three months of implementation. That's a strong signal that AI creates value when it is embedded into decisions, not parked in a separate analytics team.
Suggestion beats prediction alone
Many first-generation AI programs stall because they stop at prediction. A dashboard says a candidate is likely to fail or likely to meet a property threshold. Useful, but incomplete.
Scientists still need the next move. Should they explore nearby compositions, change the process window, or switch to a different chemistry family? The most effective systems convert model output into recommendation logic that reflects scientific priorities, uncertainty, and operational constraints.
One practical benchmark for evaluating platforms is whether they help your team plan action, not just view data. If you're comparing tools more broadly, Iwo Szapar's AI tool recommendations are useful for thinking through how teams evaluate AI products by use case instead of hype.
For materials-specific work, Polymerize is one example of a platform that combines a centralized data layer with domain-specific models for formulation and property prediction, which is the kind of architecture needed when the goal is to reduce cycle time rather than add another analytics surface.
Later in the workflow, seeing the interaction between recommendations and lab planning becomes critical.
Where leaders should be skeptical
Be careful with systems that require extensive manual export, custom scripting for every use case, or opaque outputs that scientists can't interrogate. In materials R&D, trust is earned when the model can show historical precedents, confidence context, and the assumptions behind a suggestion.
If the scientist can't challenge the model, they won't use it when decisions become consequential. And if they won't use it, cycle time won't move.
Automate Workflows and Integrate Lab Operations
The digital loop only creates value when it reaches the bench.
A common failure pattern looks like this: the team builds a decent model, identifies a strong candidate, and then falls back into email, manual worksheets, disconnected instrument booking, and hand-entered sample metadata. The recommendation is good, but execution slows it down.
How the integrated workflow should run
A better workflow is more connected and much less dramatic than people expect.
A formulation scientist reviews model suggestions in the morning and selects a short list of candidates. The system pushes the selected recipes into the execution layer. Sample instructions are generated in a standard format. The dispensing workflow is queued. Analytical methods are preassigned based on the campaign objective. Results flow back into the record without someone spending the afternoon renaming files and copying values between systems.
That's how cycle time drops in practice. Not through a futuristic lights-out lab, but through reliable handoffs between software, instruments, and human review.
What to automate first
Don't start with the most technically impressive task. Start with the repetitive points where delay and error already show up.
- Request translation: Convert approved digital experiment plans into structured lab instructions.
- Sample and test orchestration: Route materials, methods, and instrument queues without manual chasing.
- Result capture: Pull outputs directly into the experimental record with traceable metadata.
- Exception handling: Flag missing data, failed runs, and method deviations so they don't disappear into side notes.
Automation should remove clerical friction first. Scientists need more time for interpretation, not more dashboards to maintain.
Many innovation leaders also need a process lens beyond the lab stack itself. For that, this practical playbook for workflows is a helpful reference because it frames workflow improvement as operational design, not just software purchase.
The trade-off leaders need to manage
Too much automation too early can backfire. If the scientific process is still unstable, hardwiring it into software and robotics can lock in bad habits. But waiting for a perfect process usually means staying manual for years.
The right balance is selective integration. Automate mature, repetitive steps. Keep judgment-heavy decisions with scientists. Tighten the loop one handoff at a time.
Pilot, Scale, and Sustain Your Gains Through Governance
The riskiest way to modernize materials R&D is the way many companies still propose it. A broad transformation program, a long requirements document, and a promise that everything will change at once.
That approach usually creates more theater than progress.
Start with a pilot that has operational pain
The strongest pilot isn't the most glamorous use case. It's the one where delay is visible, data already exists in fragmented form, and the team is motivated to work differently.
Good pilot candidates often share three traits:
| Pilot trait | Why it matters |
|---|---|
| Clear bottleneck | The team can see where time is being lost |
| Repeated workflow | The process happens often enough to learn quickly |
| Decision ownership | A real leader can change behavior based on results |
Pick a workflow where formulation iteration, testing, and decision-making recur often. Then define success in operational terms. Fewer repeat loops. Faster time from result to decision. Better handoff quality. Stronger confidence in what to test next.
Governance keeps gains from fading
A pilot can prove the concept. It can't sustain the operating model by itself.
Sustained improvement needs governance across four areas:
- Data ownership: Someone must own definitions, access rules, and record quality.
- Model oversight: Teams need a clear process for retraining, validation, and retirement.
- Role design: Scientists, data teams, and lab operations need explicit responsibilities.
- Adoption habits: Leaders must reinforce that decisions should flow through the new system, not around it.
Many programs slow down because they treat governance as a compliance layer added after implementation. In reality, governance is what lets the system scale without becoming chaotic.
If every team invents its own data labels, model rules, and experiment templates, cycle time creeps back in through inconsistency.
What the VP of Innovation should protect
Protect the pilot team from overreporting and under-supporting. They need enough visibility to build momentum, but not so much executive theater that they spend more time presenting than improving.
Protect scientific credibility too. Teams don't adopt an AI-native workflow because they were told to. They adopt it when the system helps them make better calls under real project pressure.
When that happens, cycle-time reduction stops being a special initiative. It becomes how the organization works.
If you're building an AI-native operating model for materials innovation, Polymerize is worth evaluating as a system that connects fragmented experimental data, domain-specific models, and lab-facing workflows in one environment. For teams trying to reduce R&D cycle time without stitching together separate tools, that kind of integrated setup can make the difference between a successful pilot and another isolated digital project.

