A chemist tries to repeat a promising formulation from six months ago. The original run lives across a paper notebook, a spreadsheet on a shared drive, and instrument files named with whatever made sense that afternoon. One page is smudged. A critical value is hard to read. The scientist who ran the work has already left.
That situation isn't unusual. It's what happens when good science depends on bad information plumbing.
In chemistry, notebooks were never casual notes. They were the permanent primary record of laboratory observations, with dated entries, numbered pages, and legible corrections because the notebook had evidentiary weight. The move to digital didn't change that responsibility. It modernized it. According to Imperial College London's guidance on electronic lab notebooks, ELNs preserve that same role while adding search, archiving, collaboration, permissions, stable identifiers, and support for attached text, images, data, and equations.
That matters for chemistry because chemistry data is messy by default. A single experiment can combine structures, stoichiometry, spectra, procedural notes, sample history, analytical files, and final interpretation. If those pieces stay disconnected, the lab keeps relearning what it already knows.
Table of Contents
- The value shows up in four operational areas
- What changes on the lab floor
- Why this matters strategically
- Structured reaction capture is non-negotiable
- Features that save time because they preserve context
- What sounds useful but often disappoints
- A practical buying filter
- What regulated environments usually need
- Compliance controls also strengthen IP
- Where companies get into trouble
- Start with deployment risk, not feature envy
- A rollout sequence that works in practice
- Why ELNs matter for AI readiness
- From ELN to connected R&D system
Introduction From Paper Chaos to Digital Clarity
Most labs don't lose knowledge in one dramatic failure. They lose it in fragments. A missing lot number. An unlinked NMR file. A reaction condition captured in shorthand that only one researcher understands. By the time a team tries to reproduce the work, the cost shows up as delay, repeated experiments, and weaker confidence in the data.
That is why electronic lab notebook chemistry should be treated as an operating model, not a software purchase. The goal isn't to type notes into a browser instead of writing them on paper. The goal is to create a controlled, searchable, durable experimental record that survives staff turnover, project handoffs, and scale-up.
Why paper habits don't translate cleanly
Paper notebooks worked when labs were smaller, datasets were lighter, and most context stayed in one person's head. Modern chemistry R&D doesn't work that way. Scientists move across sites. Analytical data comes from multiple instruments. Development teams need to compare batches, formulations, and process variants quickly.
A useful ELN keeps the discipline of the old notebook while removing its physical limits.
- Permanent record keeping: Entries remain attributable and organized.
- Searchability: Teams can find experiments by reagent, sample, structure, or project context.
- Collaboration: Process chemists, analytical scientists, and formulation teams can work from the same record.
- Archiving: Data remains available after projects pause or people leave.
Practical rule: If an experiment can't be understood without asking the original scientist, the record isn't complete.
What changes when the record becomes structured
The biggest shift is subtle. The experiment stops being a page and becomes a data object. Conditions, reagents, attachments, observations, and outputs can be linked instead of scattered. That makes the record more useful on day one, and much more valuable later when teams want to compare experiments, mine prior work, or connect lab data to downstream systems.
For chemistry organizations thinking beyond digitization, that's the inflection point. An ELN is the first layer of a modern data foundation. Without it, every later initiative, from instrument integration to AI-assisted experiment planning, starts with cleanup instead of insight.
What Exactly Is an Electronic Lab Notebook?
An electronic lab notebook, or ELN, is software used to document experiments, methods, observations, and supporting files in a controlled digital environment. In a chemistry setting, that definition needs to be tighter. A real chemistry ELN isn't just a note-taking app with folders. It's a system built to connect chemical context with experimental evidence.
A useful analogy is a CRM for science. A CRM doesn't just store text about customers. It organizes interactions, links records, standardizes fields, and gives teams a shared source of truth. A chemistry ELN does the same for experiments.
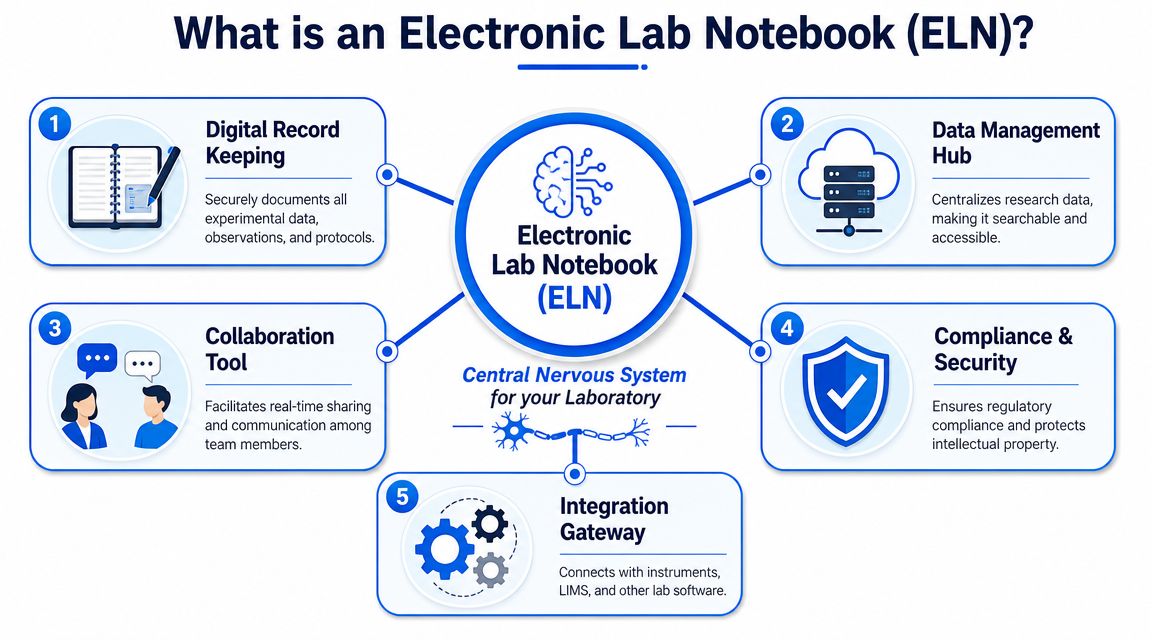
What a true chemistry ELN contains
Generic tools like OneNote can be approved for certain use cases, and some organizations do keep low-friction tools in the stack for limited workflows. But they don't usually give chemists the structure needed for reaction-centric work.
A chemistry ELN should handle records like these:
| Record type | What chemists need to capture |
|---|---|
| Reactions | Structures, reactants, stoichiometry, conditions, yields, observations |
| Analytical results | Attached spectra, chromatograms, reports, and interpretation notes |
| Samples | IDs, provenance, storage, status, links to batches or formulations |
| Procedures | Reusable protocols, deviations, safety notes, execution details |
| Project knowledge | Cross-links between experiments, decisions, failures, and follow-up work |
Why disconnected files fail in practice
The daily problem isn't storage. It's context.
A PDF in a folder doesn't tell you which batch it belongs to. A spreadsheet doesn't explain whether a reagent was fresh, substituted, or partially consumed. An instrument export doesn't reveal which exact procedure variant was used. Teams end up reconstructing the story after the fact.
That's where an ELN becomes the laboratory's control plane.
- It centralizes records. Experimental notes, supporting files, and metadata live together.
- It preserves relationships. The reaction links to the sample, the sample links to the spectrum, and the spectrum links to the conclusion.
- It supports governed access. People see what they should see, and changes are attributable.
- It improves retrieval. Scientists can search for prior work instead of relying on memory and folder archaeology.
An ELN isn't valuable because it's digital. It's valuable because it keeps experimental context attached to the data.
For teams adopting electronic lab notebook chemistry seriously, that distinction matters. If the platform only stores documents, it digitizes clutter. If it structures work around experiments, it becomes a reusable knowledge base.
Why Every Modern Chemistry Lab Needs an ELN
Labs don't adopt ELNs because they want a shinier notebook. They adopt them because paper records, spreadsheets, and shared drives stop working once projects become collaborative, regulated, or data-heavy.
The market reflects that shift. The global ELN market was estimated at USD 750.82 million in 2025, rose to USD 805.33 million in 2026, and is projected to reach USD 1,513.26 million by 2035, implying a 7.26% CAGR from 2026 to 2035. North America accounted for about 40% of the market in 2024. NFDI4Chem also highlights that ELNs centralize metadata, link test descriptions directly to collected data, and improve traceability, reusability, and secure storage for chemistry research. See the NFDI4Chem overview of ELNs and market growth.
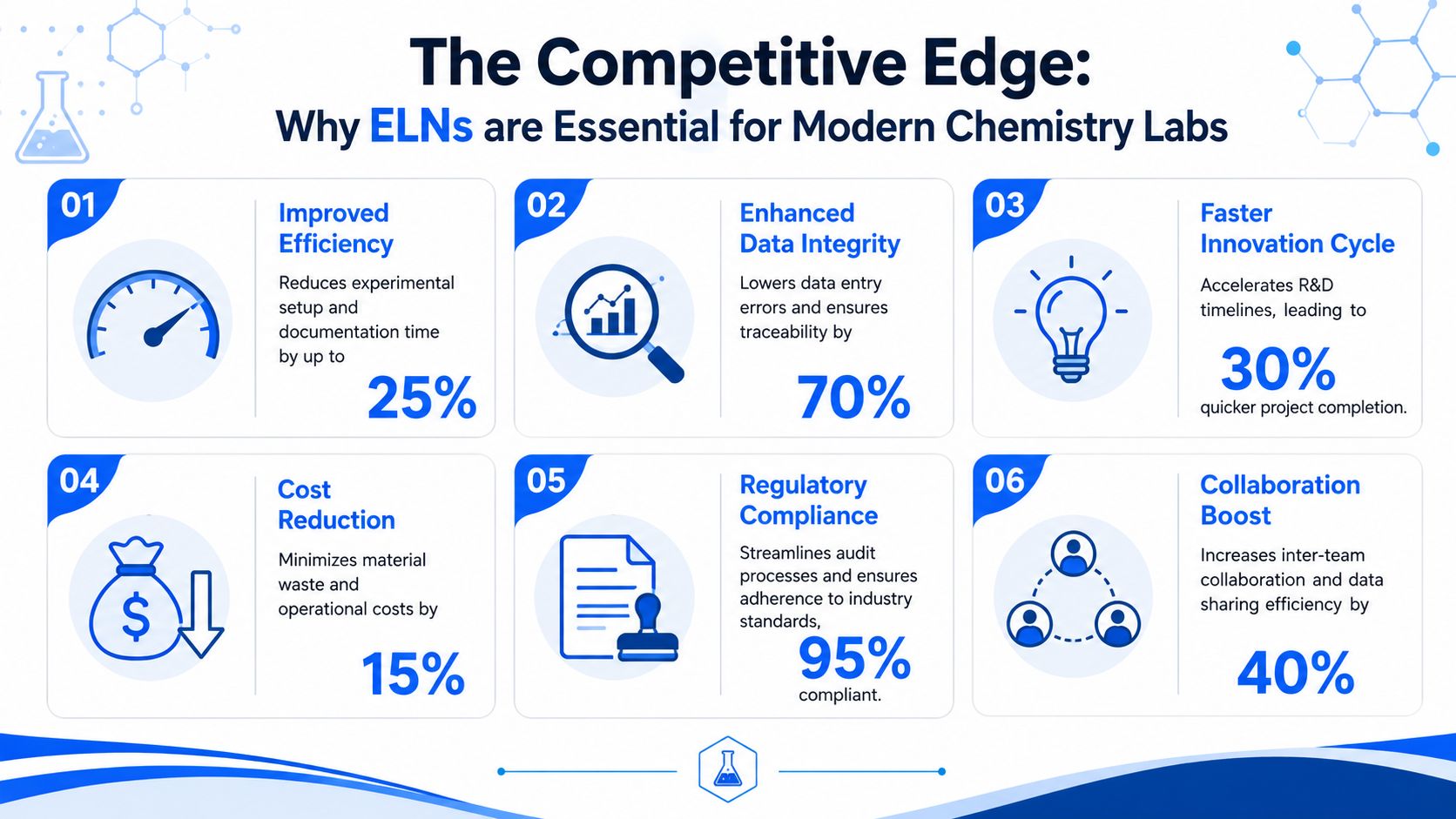
The value shows up in four operational areas
The best way to judge an ELN is to look at the friction it removes from routine work.
Data integrity comes first. Illegible notes, missing files, and untracked edits weaken the record. A controlled digital environment makes the experiment easier to review and far harder to lose.
Reproducibility is next. Chemistry teams need to know not only what was intended, but what was done. That includes materials, quantities, conditions, deviations, and attached evidence.
Collaboration improves because the record no longer depends on a single scientist's filing habits. Teams in synthesis, analytical, process, and scale-up can inspect the same experiment without rebuilding context from email threads.
IP protection gets stronger because time-stamped, attributable records are easier to organize, review, and preserve than scattered paper binders and desktop files.
What changes on the lab floor
An ELN doesn't remove scientific uncertainty. It removes avoidable administrative uncertainty.
- Fewer blind repeats: Teams can see whether an experiment already failed, and why.
- Cleaner handoffs: A new scientist can continue work without interviewing the previous owner.
- Better project review: Managers and technical leads can inspect work in context, not as disconnected attachments.
- More reusable knowledge: Negative results stay useful when they're findable and interpretable.
A quick explainer on the broader category helps if you're aligning technical and business stakeholders:
Why this matters strategically
In many organizations, the first argument for ELNs is efficiency. That's valid, but incomplete. The deeper reason is that chemistry organizations now need records that can feed downstream systems. If metadata, test descriptions, sample lineage, and outcomes aren't linked at the source, every later analytics or AI effort starts by cleaning historical messes.
That's why high-performing labs treat the ELN as infrastructure. Not glamorous infrastructure. Foundational infrastructure.
Essential Features of a Chemistry-Specific ELN
A generic ELN often demos well and fails subtly. It handles text entry, file upload, and basic search, so buyers think they are covered. Then the chemistry team tries to capture a multistep synthesis, track reagent lineage, attach analytical evidence, and search prior work by structure. That's when the mismatch appears.
Chemistry workflows need chemistry-native data capture.
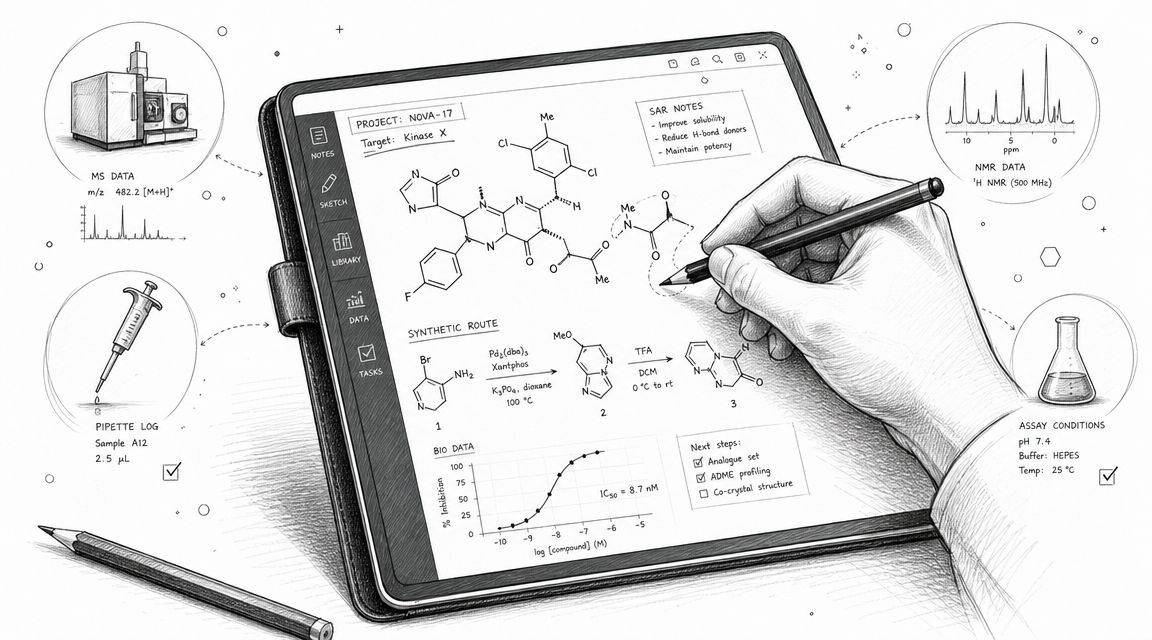
Structured reaction capture is non-negotiable
For chemistry work, an ELN should support structured reaction capture, including stoichiometry calculators, reaction schematics, and reagent or sample tracking, because those features reduce manual transcription errors and make records more searchable and reusable across projects. That's called out directly in Sapio Sciences' discussion of ELN types and chemistry workflow needs.
Without structured capture, chemists end up pasting images of reaction schemes and typing quantities into free text. That may satisfy basic documentation, but it doesn't create data you can query later.
Look for:
- Reaction schematics: Scientists should be able to represent the chemistry clearly inside the record.
- Stoichiometry support: Quantities, equivalents, and expected outcomes should calculate cleanly and remain reviewable.
- Tracked entities: Reagents, intermediates, products, and samples should remain linkable across experiments.
Features that save time because they preserve context
The best chemistry ELNs don't just collect more information. They reduce re-entry and ambiguity.
Consider the daily workflow impact of the following capabilities:
| Feature | Why it matters in chemistry |
|---|---|
| Chemical drawing integration | Lets scientists capture structures in a form they can reuse and search |
| Analytical file attachment | Keeps spectra and other outputs tied to the exact experiment |
| Sample and reagent tracking | Preserves lineage, provenance, and status |
| Template-based protocols | Standardizes recurring experiments without forcing copy-paste habits |
| Search across experiments | Helps teams find prior methods, conditions, and outcomes quickly |
If your chemists still have to maintain a separate spreadsheet to understand what's in the flask, the ELN isn't doing the job.
What sounds useful but often disappoints
Buyers get distracted by feature count. In practice, chemistry teams care less about long checklists and more about workflow fit.
What usually fails:
- Free-form note systems with chemistry add-ons: These capture narrative, but not reusable experimental structure.
- Poor attachment handling: If opening spectra or analytical files is clumsy, users stop linking evidence properly.
- Weak search: Search that only finds keywords in note text won't help medicinal chemists or formulation teams compare prior work.
- Rigid templates: Over-locked forms create workarounds. Scientists start keeping side notes outside the system.
What tends to work is a balanced design. The ELN should enforce enough structure to make records reusable, while still letting chemists record the nuance that real lab work requires. Chemistry isn't a pure form-filling exercise. Side observations matter. Deviations matter. Failed runs matter too.
A practical buying filter
When I assess ELNs with chemistry teams, I usually ask them to run one realistic scenario. Not a polished demo workflow. A real experiment with the ugly parts included.
Ask the vendor to show how the platform handles:
- A reaction with multiple reagents and equivalents.
- An amended procedure after the run starts.
- Attached analytical evidence.
- Sample tracking into downstream testing.
- Retrieval of that experiment months later by structure, sample, or project.
If that journey feels awkward, adoption will be harder than the sales process suggests.
Navigating Compliance and Intellectual Property
Compliance discussions often become abstract too quickly. In lab operations, the practical question is simpler. Can you show who recorded what, when they recorded it, what changed later, and who approved the final record?
That is why ELN compliance features matter even in teams that don't think of themselves as heavily regulated. Good controls support quality, governance, and IP protection at the same time.
What regulated environments usually need
Organizations in pharmaceuticals, specialty chemicals, food science, and adjacent sectors often care about the same controls, even when the exact regulatory framework differs.
The ELN should support:
- Audit trails: Every material change should be attributable and reviewable.
- Electronic signatures: Approval events should be formal, not improvised through email.
- Role-based permissions: Scientists, reviewers, and administrators should not all have the same access.
- Version control: Teams need a clear record of what changed and what was final.
- Retention discipline: Records should remain accessible according to internal and external requirements.
For teams working through software and validation responsibilities, this primer on understanding compliance in software development is useful because it frames compliance as a design and governance issue, not just a legal checkbox.
Compliance controls also strengthen IP
People sometimes treat compliance and innovation as opposing goals. In chemistry R&D, the opposite is often true. Stronger records make inventions easier to defend.
A witnessed paper notebook was historically valuable because it created a dated record. A well-configured ELN can preserve that evidentiary logic while improving legibility, retrieval, and control. When a team needs to reconstruct the path to an invention, the combination of timestamps, linked attachments, review history, and attributable edits is far more useful than a box of binders and a shared folder of exports.
The same controls that help during an audit also help when legal, R&D, and management need to prove how a result was developed.
Where companies get into trouble
The common failure isn't usually missing software functionality. It's weak process design.
Three recurring mistakes show up:
| Mistake | Consequence |
|---|---|
| Treating signatures as an afterthought | Approval workflows become inconsistent |
| Giving broad edit rights to everyone | Record integrity becomes harder to defend |
| Ignoring archival and retrieval early | Old data becomes technically stored but operationally unusable |
An ELN won't create compliance by itself. It has to be configured to match real responsibilities, review paths, and data retention expectations. The software can support discipline. It can't substitute for it.
Implementing Your ELN and Integrating with AI
Most ELN projects succeed or fail long before the chemistry team decides whether they like the interface. The hard parts are migration, governance, security review, validation expectations, and user adoption. That is why implementation planning matters more than vendor theatrics.
Harvard's institutional guidance on ELNs clearly indicates the risk: the issue isn't merely feature breadth, but deployment friction, security approvals, maintenance burden, and fit with organizational workflows. It also reflects a broader trend toward direct connection with instruments and other systems, while acknowledging that some organizations still keep tools like OneNote approved for narrower use cases. The Harvard guidance on evaluating and deploying electronic lab notebooks is worth reading before procurement starts.
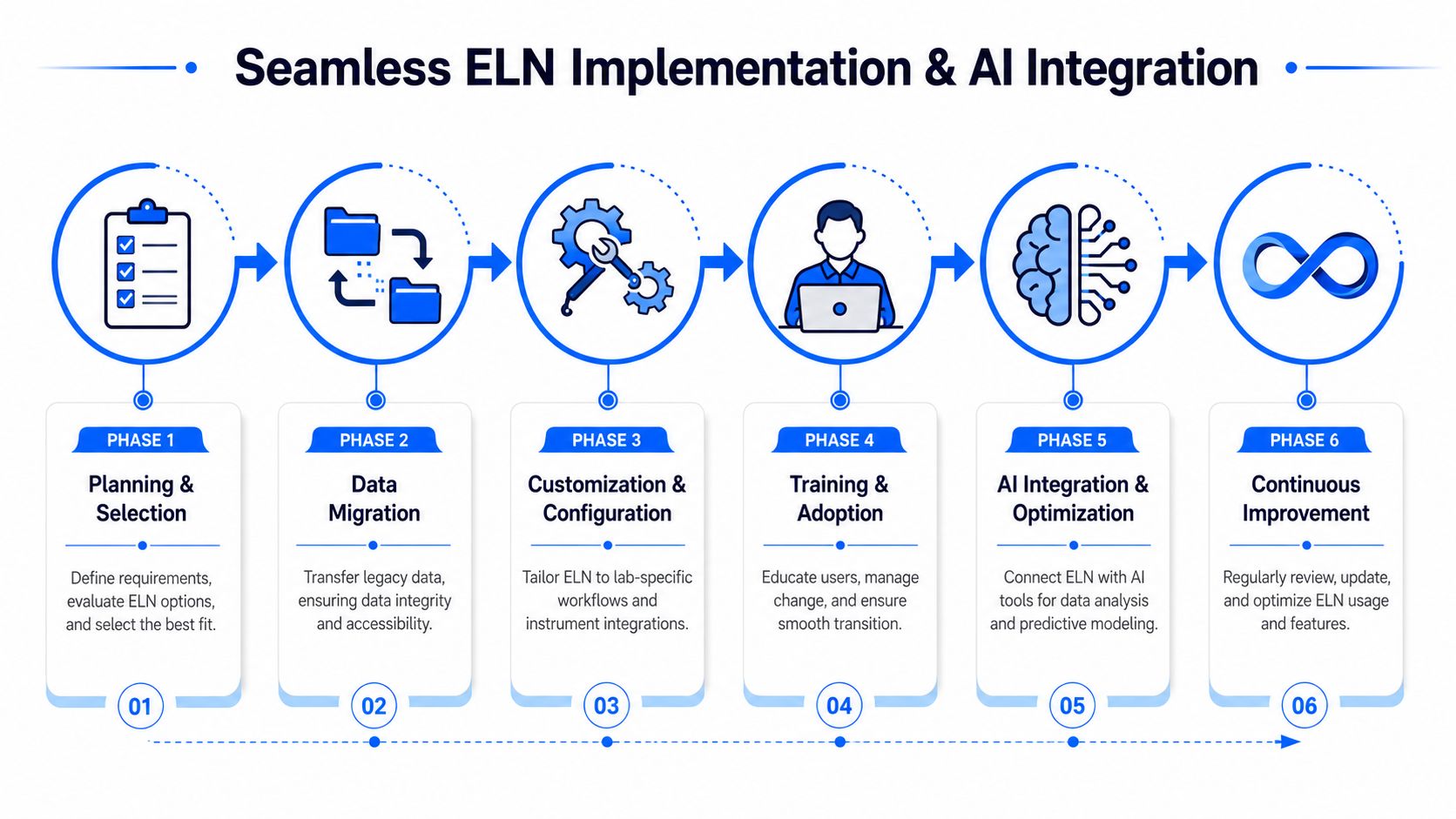
Start with deployment risk, not feature envy
Teams often ask which ELN has the most capabilities. That is rarely the right first question.
Ask instead:
- Can IT and security approve the deployment model?
- Can legacy records be migrated without destroying context?
- Can scientists use it without building shadow systems?
- Can it connect to instruments, LIMS, and enterprise data flows later?
Those questions are less exciting than a demo, but they are what determine whether the ELN becomes the system of record or just another tab nobody trusts.
A rollout sequence that works in practice
The most reliable implementations are staged. They don't try to digitize every historical record and every lab workflow at once.
A sensible sequence looks like this:
- Define priority workflows. Pick the chemistry processes that create the most value or the most pain.
- Map required metadata. Decide what must be captured consistently for experiments to remain reusable.
- Pilot with a real team. Use active projects, not synthetic test cases.
- Refine templates and permissions. Early friction usually reveals missing fields or overbuilt forms.
- Integrate selectively. Connect the systems that matter most first, especially where transcription creates risk.
- Establish governance. Ownership for templates, training, archival rules, and change control should be explicit.
Field note: The fastest way to lose adoption is to force scientists into rigid forms before you've learned how they actually work.
Why ELNs matter for AI readiness
Many organizations, in this scenario, undersell the business case. The ELN is not the finish line. It is the data foundation for everything that comes next.
AI systems in R&D depend on structured, traceable, contextualized data. If experiment records are inconsistent, attachments are orphaned, and outcomes are buried in prose, advanced models won't rescue the situation. They will inherit the chaos.
If your team is still getting familiar with AI concepts, this overview of understanding large language models helps explain one part of the broader AI stack in plain language. For chemistry and materials organizations, the operational takeaway is simple: AI becomes useful when experimental records are clean enough to support retrieval, comparison, and model input.
From ELN to connected R&D system
A mature setup links the ELN with adjacent systems rather than asking the ELN to do everything alone. Depending on the organization, that may include a LIMS, inventory platform, instrument data layer, PLM environment, or analytics stack.
For materials and formulation teams, one option in that broader architecture is Polymerize, which is positioned as an AI-native system for materials R&D that unifies fragmented experimental data across spreadsheets, ELNs, and silos into a centralized data backbone. That isn't a substitute for an ELN. It's the kind of downstream intelligence layer that becomes more useful once the ELN captures experiments in a disciplined, structured way.
The strategic payoff is not just better documentation. It is the ability to move from record keeping to decision support. When historical chemistry data is structured well enough to query and model, teams can compare similar formulations, learn from previous failures, and plan the next experiment with more confidence and less guesswork.
Conclusion From Digital Record to Innovation Engine
Chemistry organizations don't need an ELN because paper is old. They need one because modern R&D depends on records that are searchable, attributable, reusable, and durable across people, projects, and systems.
A well-implemented ELN improves daily execution first. Scientists can find past work, attach evidence properly, review experiments in context, and protect the integrity of the record. That alone is worth doing.
But the larger reason is strategic. Once experimental data is captured in a structured way, the lab stops producing isolated notes and starts building a usable knowledge asset. That is the foundation required for stronger analytics, instrument connectivity, materials informatics, and AI-guided experimentation.
The primary return isn't just cleaner documentation. It's giving the organization a data backbone that can support future discovery instead of forcing every new initiative to start with data rescue.
If your chemistry or materials R&D team is trying to move beyond fragmented records and build an AI-ready experimental data foundation, Polymerize is worth evaluating as part of the next layer of your architecture. It helps organizations unify experimental data across ELNs, spreadsheets, and silos so teams can support better modeling, formulation optimization, and faster decision-making on top of a stronger data backbone.

