You already know the feeling. A property trend looks promising, the formulation team wants to move, and then the repeat data comes back just far enough apart to trigger an argument. One chemist says the difference is real. Another says it's noise. A third asks whether the instrument was even stable that day.
That argument is usually framed as a data problem. It's really a measurement uncertainty problem.
In materials R&D, uncertainty decides whether you trust a screening result, whether a process window is real, whether a supplier difference matters, and whether an AI model is learning chemistry or just learning your lab's inconsistencies. If your team treats uncertainty as a paperwork exercise done after the experiment, you'll keep paying for it upstream in bad experimental choices and downstream in weak decisions.
Table of Contents
- Error and uncertainty are not the same thing
- Type A and Type B give a usable framework
- GUM is a modeling discipline
- Control the uncertainty sources that sit outside the instrument spec
- Build uncertainty control into daily lab work
- Bad uncertainty data poisons good models
- AI systems need uncertainty-aware inputs and uncertainty-aware outputs
Why Every Measurement Has a Margin of Doubt
Two labs can test the same material and produce slightly different values without either lab doing anything obviously wrong. That doesn't mean one team is careless. It means every reported result is an estimate, shaped by instrument behavior, sample handling, environment, operator choices, and the way the result is calculated.
That margin of doubt matters far beyond metrology audits. In a materials program, it changes how you interpret a formulation ranking, how you set pass-fail criteria, and how you decide whether a pilot result is worth scaling. If the uncertainty is large relative to the effect you're chasing, your program can look data-driven while still making weak decisions.
Why this hits R&D harder than routine QC
Routine QC often asks a narrower question. Is the batch inside a known specification? R&D asks messier ones. Did the additive improve stability? Is the viscosity shift real across composition space? Did a processing tweak create a better morphology, or did the prep method shift the readout?
Those are model-heavy questions, not just reading-heavy questions. The more transformations sit between raw observation and final claim, the more room uncertainty has to accumulate and hide.
Practical rule: If a result will change what experiment you run next, the uncertainty around that result is part of the result.
A lot of teams still treat uncertainty as a plus-minus number added at the end. That's too late. You need it early, when choosing methods, setting replication plans, deciding what metadata to capture, and determining whether a measured difference is decision-grade or just numerically different.
What good teams do differently
The strongest labs don't chase impossible certainty. They build enough quantified confidence to act well. In practice, that means they ask three hard questions before they trust a number:
- What exactly was measured: The property name isn't enough. The measurand depends on method, conditioning, sample state, and calculation.
- Where doubt enters: Not just the instrument, but preparation, correction factors, assumptions, and environmental conditions.
- Whether the result is fit for purpose: A value can be acceptable for screening and still be inadequate for release, scale-up, or model training.
That shift, from “What number did we get?” to “How much confidence do we have in this number for this decision?”, is where reliable science starts.
The Language of Uncertainty GUM Principles
GUM gives labs a shared operating language for measurement uncertainty. That matters any time a result needs to survive handoff between scientists, instruments, sites, or software systems without changing meaning.
At its core, GUM forces one discipline that many teams skip under schedule pressure. Define the measurand clearly, write the measurement model, identify the input quantities, assign uncertainty to each input, and combine them in a way another competent lab could follow. In practice, this exercise does more than support reporting. It exposes where the method depends on assumptions, hidden corrections, or environmental conditions that no one documented because the procedure felt routine.

Error and uncertainty are not the same thing
Chemists often use error, bias, precision, and uncertainty as if they were interchangeable. They are not.
Error is the difference between a measured value and a reference or true value, if that reference is known. Bias is the systematic component that pushes results in one direction. Precision describes scatter under stated conditions. Uncertainty is the quantified doubt attached to the reported result after considering the whole measurement process.
That distinction changes what you do in the lab. Repeats can characterize random variation. Repeats alone will not fix a drifted calibration, an incorrect blank correction, a sample conditioning problem, or a measurement model that leaves out a real effect.
A method can be highly repeatable and still mislead the team.
Type A and Type B give a usable framework
GUM separates uncertainty evaluation into two broad classes because labs need both observed variation and prior knowledge.
| Aspect | Type A Evaluation | Type B Evaluation |
|---|---|---|
| Basis | Statistical analysis of repeated observations | All other available information |
| Typical source | Replicate measurements | Calibration data, specifications, prior knowledge, reference information |
| Strength | Captures observed variability in your actual run conditions | Captures uncertainty not visible from repeats alone |
| Common misuse | Assuming repeats capture everything | Treating handbook values as if they exactly match your setup |
| Best use | Estimating random components tied to execution | Accounting for systematic and contextual contributors |
Type A is familiar ground. You run replicates, estimate the spread, and quantify the uncertainty contribution from observed variability under your conditions.
Type B is where experienced teams usually gain accuracy in the final statement. Calibration certificates, instrument resolution, reference material uncertainty, environmental sensitivity, correction factors, and justified scientific judgment all belong here. Ignore those inputs and the uncertainty estimate often looks cleaner than the method is.
That is not a paperwork problem. It is a decision problem. If a screening result feeds a go or no-go call, or if a property value becomes a feature in a machine learning model, understated uncertainty gives the model and the team too much confidence in weak data.
GUM is a modeling discipline
The practical value of GUM is not the final plus-minus line. It is the requirement to state how the reported value is produced.
Once the method is written as a model, weak spots become visible. Which correction is assumed constant? Which input was treated as exact because the software defaulted that way? Which environmental effect was considered negligible without evidence? Those questions matter in classical metrology, and they matter even more in modern R&D workflows where derived properties feed optimization algorithms, active learning loops, and cross-site datasets.
For data-rich R&D, that's the critical warning. If the measurement model leaves out a material effect, the problem is larger than narrow error bars. You can report the wrong measurand, train AI on mislabeled targets, and steer the next round of experiments in the wrong direction with high apparent confidence.
Good uncertainty work starts at method design, where teams decide what is being measured, what assumptions are acceptable, and what level of confidence the downstream use requires.
How Uncertainty Propagates Through Your Workflow
Most lab errors don't arrive as a single dramatic event. They accumulate in small, ordinary steps. A balance reading looks fine. A volumetric transfer looks routine. A temperature correction feels negligible. Then the final derived value carries more uncertainty than anyone expected.
That's why treating measurement uncertainty at the instrument level alone misses the actual workflow.
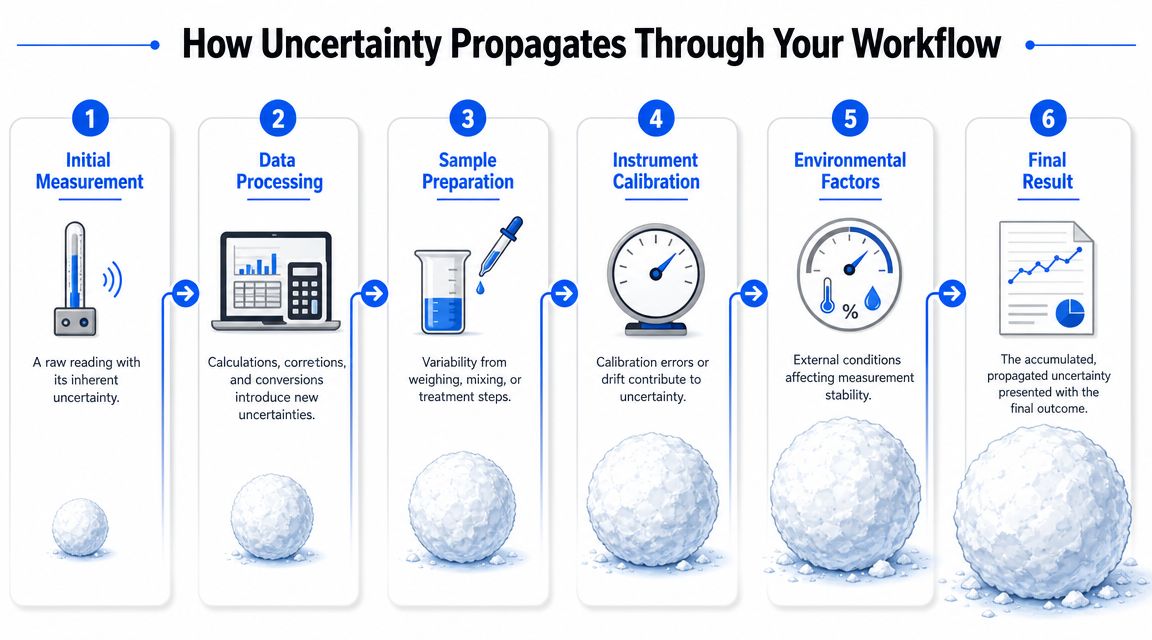
A simple solution prep shows the problem
Take a basic preparation task. You weigh a powder, transfer it into a flask, fill to volume, mix, and use that solution downstream for an analytical or formulation step. No single action looks risky. The chain is the risk.
The weighed mass has uncertainty. The flask volume has uncertainty. The meniscus reading has operator dependence. Solvent behavior changes with temperature. Transfer losses may be small but not zero. If the concentration becomes an input to another measurement, all of those components travel with it.
Here's the practical point chemists often underestimate. The final uncertainty doesn't care which step felt important to the operator. It depends on which inputs materially influence the result.
- Upstream mass matters when concentration is derived from a small weighed quantity.
- Volume handling matters when dilution accuracy drives the property calculation.
- Temperature matters when density, viscosity, or response factors shift with conditions.
- Correction choices matter when software applies them automatically and no one audits the assumptions.
A clean way to think about propagation is conceptual “sum in quadrature” for independent components. You don't add every absolute contribution line by line. You combine them according to how they affect the output quantity. The bigger lesson is not the formula. It's that weak control in early steps doesn't stay local.
To see the visual logic, this short walkthrough is useful:
The model matters as much as the math
A lot of teams build propagation worksheets that are mathematically tidy and scientifically incomplete. They include readable sources like repeatability and instrument resolution, but ignore less tidy effects such as sample inhomogeneity, equilibration time, conditioning history, or data transformations inside vendor software.
That's exactly where model-driven workflows get into trouble. The uncertainty propagation can look rigorous while the underlying measurement model is too thin to support the claim. You can't rescue a missing effect with a better calculator.
If your workflow includes corrections, transformations, or inferred properties, document the chain before you calculate the uncertainty.
For materials R&D, this matters because so many reported values are derived rather than directly observed. Conversion, normalization, baseline correction, smoothing, fit parameters, and feature extraction all change what uncertainty means. Once you start feeding those values into screening decisions or predictive models, propagation becomes a program-level issue, not just a metrology one.
Practical Calculations and Reporting in Materials R&D
Most uncertainty work fails for a simple reason. The calculation is built as a compliance artifact instead of a decision tool. A useful uncertainty budget helps a chemist decide whether a method is good enough, which source deserves cleanup first, and how to report a result so another team can use it correctly.
Build a usable uncertainty budget
Take a common property measurement such as viscosity. You don't need a heroic statistical treatment to start. You need a structured list of contributors that matches how the result is produced.
A practical uncertainty budget usually includes:
- Replicate variation from repeated readings on the same material under controlled conditions. This is the obvious Type A input.
- Calibration-related contributions tied to the instrument and any certified references used to verify it.
- Temperature sensitivity if the material's response changes meaningfully with thermal conditions.
- Sample preparation effects such as mixing consistency, conditioning time, entrained bubbles, or solids settling.
- Method choices including spindle selection, shear history, dwell time, data window, or software averaging settings.
The point isn't to make the longest list. The point is to include the contributors that can plausibly move the result. Labs often waste time refining tiny components while ignoring one poorly controlled preparation step that dominates the budget.
Report for decisions, not for decoration
After identifying the components, estimate each contributor in consistent units, convert them where needed, and combine them into a combined standard uncertainty. Then decide how the result should be expressed for the intended use.
Recent reporting guidance has moved away from a generic plus-minus habit and toward fit-for-purpose confidence statements. The UKAS guidance on expressing uncertainty and confidence in measurement reinforces laboratory reporting practice, and the EPA MARLAP manual it discusses states that results should be reported with expanded uncertainty and a stated coverage factor or with combined standard uncertainty.
That sounds subtle, but operationally it changes everything. “510 cP” is a number. “510 cP with expanded uncertainty and stated coverage factor” is a result another team can evaluate against a specification, compare across sites, or feed into a model with appropriate trust.
A good report should answer these questions without forcing a reader to hunt:
- What was measured: Include the property, method conditions, and sample state.
- How uncertainty is expressed: Combined standard uncertainty or expanded uncertainty.
- What confidence framing applies: State the coverage factor when using expanded uncertainty.
- Whether the result is fit for purpose: Screening, development, transfer, release, or investigation.
Decision test: If another lab can't tell how much confidence to place in your value, you haven't finished the measurement.
One more practical point. Don't copy a coverage convention from another method just because the template expects it. The reporting format has to serve the decision. In development work, the right question often isn't “how do we calculate uncertainty?” It's “what uncertainty must we report, and at what confidence, to support this call?”
Lab Best Practices for Managing Uncertainty
A method can look stable for months, then fail the first time a second site tries to reproduce it. In my experience, that usually traces back to a source of uncertainty the team treated as background noise. The instrument was calibrated. The measurement still was not under control.

High-performing labs treat uncertainty as an operating variable, not a paperwork exercise. That matters in bench science, and it matters even more once results feed screening models, optimization loops, or AI systems that rank the next experiment. If hidden variation enters the dataset at the bench, the model inherits it and turns it into false confidence.
Control the uncertainty sources that sit outside the instrument spec
Calibration matters. It does not tell the whole story. In precision measurement, geometry, fixturing, and the object itself can dominate the result. In this angular metrology study, apparent tilt changed by as much as 0.02 arcseconds depending on mask placement, and the same study estimated about 0.01 arcseconds uncertainty for a 45° angle block.
Materials labs see the same pattern in different forms. Surface finish changes a contact measurement. Fill level changes a rheology result. Probe position changes a thermal or electrochemical reading. The instrument may be performing exactly as specified while the method is still producing unstable data.
The practical question is simple: what in the setup can change the number, even when the instrument passes its checks?
Here are the failure points that deserve routine attention:
- Sample state drift: Moisture uptake, sedimentation, phase separation, cure progression, oxidation, and thermal history can shift the measurand before the run even starts.
- Setup dependence: Holder force, orientation, path length, probe depth, contact area, and fixture geometry often contribute more variation than teams expect.
- Operator intervention: Analysts compensate for awkward steps unless the SOP defines what to do when the sample behaves badly.
- Software and data handling: Baseline correction, smoothing, peak selection, averaging rules, and outlier treatment can change the reported value as much as a hardware adjustment.
A useful companion to this mindset is a closer look at research integrity standards in material and chemical workflows. Purity, identity, labeling, and handling discipline directly affect uncertainty because they determine whether the sample being measured is the sample you think it is.
Build uncertainty control into daily lab work
The labs that manage uncertainty well do a few things with discipline.
- Calibrate against traceable references. Traceability lets teams compare results across time, sites, and instruments without guessing whether the numbers belong on the same scale.
- Write SOPs around known variation points. Good procedures define sample conditioning, setup tolerances, acceptance checks, and the exact response to common deviations.
- Verify method behavior during routine use. Check standards, duplicates, and control charts catch drift before it contaminates a month of development data.
- Train analysts to recognize decision-relevant deviations. The job is not just running the instrument. It is knowing when a result is questionable and should be repeated, flagged, or stopped.
- Update uncertainty budgets when the method changes. New sample matrices, new fixtures, software updates, and automation steps can all shift the uncertainty structure.
- Store uncertainty with the result, not in a separate file. If the value enters a data platform without its confidence context, downstream models will treat weak and strong measurements as equals.
The most expensive uncertainty source is the one nobody recorded, because it gets baked into decisions, models, and transfer packages.
What fails in practice is the annual uncertainty worksheet that only appears during audits. By then, hidden variation has already been normalized into the method, the database, and the experimental conclusions. The teams that get reliable scale-up and useful AI support are the ones that handle uncertainty at the point of measurement, where it can still change what they do next.
The Next Frontier AI for Uncertainty Quantification
A team runs a high-throughput screening campaign, feeds the results into a model, and gets a clean ranking of the next formulations to make. Two weeks later, the winners fail on repeat. The chemistry was not the only problem. The training data mixed measurements with very different confidence, and the model had no way to tell which numbers were stable and which were barely controlled.
AI changes the speed of materials R&D. It also raises the penalty for weak measurement practice. A scientist can often spot a questionable result during review. A model will usually treat it as another valid row unless the uncertainty, method context, and measurement conditions are stored with the result.
Bad uncertainty data poisons good models
For AI-driven experimentation, a number without context is incomplete. The record needs the method version, sample history, preparation details, operating window, and a usable representation of uncertainty. Otherwise, the model gives the same weight to a tightly controlled measurement and a result taken near the edge of method capability.
The consequences show up fast in practice. Bayesian optimization starts chasing noise. Classification boundaries look cleaner than the lab can reproduce. A property model appears accurate in cross-validation because it learned method artifacts tied to one instrument, one operator pattern, or one sample prep route.
I have seen this happen in formulation work where viscosity data from two nominally similar methods were pooled into one training set. The model found a trend. The lab could not reproduce the recommendation because the trend was partly a measurement-system difference, not chemistry.
For teams setting AI governance for scientific work, broader leading AI safety solutions are useful reference points. In an R&D environment, safety starts earlier than deployment review. It starts with whether the evidence entering the model is fit for a technical decision.
AI systems need uncertainty-aware inputs and uncertainty-aware outputs
Classic metrology already established the hard part. Every reported value depends on a measurement model, and missing effects can bias the result or make the stated uncertainty look smaller than it is. In AI workflows, that mistake spreads further. It enters the training set, shapes the surrogate model, and then influences which experiment gets run next.
That changes how uncertainty should be used. It is not just a reporting field for the final slide. It belongs in feature engineering, record weighting, outlier review, active learning, and stopping criteria. If one assay has wider uncertainty in a certain composition range, the model should know that. If a property estimate is based on sparse data far from the center of the design space, the planning system should surface that before the team spends a week synthesizing around a weak prediction.
The better systems do more than rank candidates. They show where confidence is thin, where method variation is entangled with formulation effects, and where the recommendation is really an extrapolation.
A prediction without confidence context is only half a scientific output.
That is the practical frontier. GUM-style discipline defines what the measurement means. AI uses that uncertainty to decide what to trust, what to test next, and where another replicate is worth more than another model iteration.
From Uncertainty to Confident Innovation
Measurement uncertainty isn't a tax on progress. It's the mechanism that makes progress trustworthy.
When teams treat uncertainty as part of the experimental design, they make better choices about methods, replication, reporting, and scale-up. They stop overreacting to weak differences and stop missing strong signals hidden inside noisy workflows. They also give their AI systems something far more valuable than a large dataset. They give them a dataset with context.
The labs that move fastest over time usually aren't the ones pretending every number is crisp. They're the ones that know where doubt enters, how large it is, and whether it matters for the decision in front of them. That discipline pays off in screening, transfer, qualification, and model-guided development.
In modern materials R&D, confidence is built, not assumed. Measurement uncertainty is how you build it.
If your team wants to make uncertainty visible across experiments, methods, and AI-guided decisions, Polymerize is built for that kind of R&D reality. It helps materials organizations unify fragmented experimental data, preserve the context around each result, and use AI to plan better next experiments with confidence-aware insight rather than guesswork.

