Your team probably already feels the pain that pushes companies toward a materials informatics platform. A formulation scientist has legacy results in spreadsheets. Process data sits in one system, characterization data in another, and half the useful experimental context lives in slide decks, ELNs, or someone's memory. Projects move forward, but too often by repeating old work, chasing weak hypotheses, and running more physical experiments than the team can afford.
That old model still works, technically. It just doesn't scale well when portfolios expand, expertise gets fragmented, and leadership wants faster decisions with fewer dead ends. What changes the game isn't AI in the abstract. It's having a structured system that makes past experimental knowledge searchable, reusable, and operational inside day-to-day R&D.
Table of Contents
- Data ingestion and curation
- Experimental workflow integration
- Predictive modeling and experiment guidance
- Explainability and confidence scoring
- Enterprise security and governance
- Start with your ugliest data, not the vendor demo
- Questions that reveal platform fit
- Materials Informatics Platform Evaluation Checklist
- Polymers and formulations
- Specialty chemicals and process-sensitive products
- Advanced materials and engineering handoff
The End of Trial-and-Error in Materials R&D
Materials R&D has always involved uncertainty. The problem is that many teams still manage uncertainty with a process built for a smaller, slower world. Scientists test a formulation, log results inconsistently, make a judgment call, then repeat. Over time, the organization builds a lot of data but very little reusable intelligence.
That's why a materials informatics platform matters. It changes the unit of progress from isolated experiments to cumulative learning. Instead of asking, “What should we test next based on intuition alone?” teams can ask, “What does the existing evidence suggest is worth testing next?”
The shift is no longer niche. The global material informatics market is projected to grow from USD 170.4 million in 2025 to USD 410.4 million by 2030, reflecting a 19.2% CAGR, according to MarketsandMarkets' material informatics market outlook. That matters less as a market statistic and more as a signal. Buyers are no longer evaluating these platforms as experimental software. They're treating them as part of the core R&D stack.
Why the old process breaks down
A trial-and-error workflow usually fails in predictable ways:
- Data gets trapped: Critical observations remain buried in spreadsheets, PDFs, slide decks, or handwritten notes.
- Knowledge leaves with people: When a senior chemist changes roles, the reasoning behind past experiments often disappears with them.
- Programs duplicate work: Teams rerun experiments because they can't reliably find prior results or compare them across projects.
- Scale-up gets disconnected: Lab decisions don't always carry enough context for process, quality, or manufacturing teams.
Practical rule: If your scientists spend more time hunting for usable data than debating hypotheses, you don't have an AI problem. You have an R&D operating model problem.
A good platform doesn't eliminate experimentation. It makes experimentation more selective. That's the difference. The primary win isn't replacing the lab. It's stopping the lab from acting as the first place where knowledge gets organized.
What Is a Materials Informatics Platform?
The simplest way to think about a materials informatics platform is this. It's a system of intelligence for materials R&D. Not just a database. Not just a modeling workbench. Not just another dashboard.
A database stores results. A standalone model predicts an outcome. A true platform connects data, context, and decision-making so scientists can move from fragmented records to better next-step choices.
More like a GPS than a spreadsheet
A useful analogy is a GPS for materials discovery. A GPS doesn't move the car for you. It tells you where you are, what routes are available, which path is blocked, and what the fastest reasonable option looks like given current conditions. A materials informatics platform does something similar for formulation and materials development. It helps teams find their way toward a target property profile using the evidence they already have, not just instinct and repetition.
That means the platform has to unify multiple kinds of information:
- Experimental results from spreadsheets, ELNs, LIMS, and reports
- Metadata such as processing conditions, raw materials, equipment, and operator context
- Analytical outputs from characterization and simulation tools
- Decision history that explains why a team changed composition, process, or test method
If you work with business systems outside the lab, the concept is similar to how analytics teams distinguish reporting tools from true decision systems. Querio's guide to BI platforms is useful here because it draws that line clearly. The same distinction applies in materials R&D. A platform should help users act on data, not just view it.
What a platform is not
A lot of software gets labeled as materials informatics, even when it covers only one layer of the problem. In practice, these are the common mismatches:
| Tool type | What it does well | Where it falls short |
|---|---|---|
| Standalone modeling tool | Builds predictions from prepared datasets | Doesn't solve fragmented data capture and governance |
| Basic materials database | Stores property records | Often lacks workflow context and experiment guidance |
| Generic BI dashboard | Summarizes trends | Rarely handles materials-specific structure, provenance, or scientific reasoning |
The practical definition is stricter. A materials informatics platform should give your scientists one place to find prior work, structure messy data, compare hypotheses, and generate a defensible next experiment.
Most failed evaluations happen because teams buy for the AI demo and discover later that the hard part was assembling trustworthy data in the first place.
That's why the strongest platforms behave less like analytics add-ons and more like an operational layer for R&D. They make scientific data usable across projects, teams, and handoffs.
The Core Components of a Modern MI Platform
Most buying teams focus too much on the modeling interface and not enough on the plumbing underneath. That's backwards. The U.S. National Institute of Standards and Technology frames materials informatics around data curation, data infrastructure, and data access, with the goal of deploying advanced materials at least twice as fast as traditional methods in its materials informatics initiative. That framing is practical because it starts where implementation succeeds or fails.
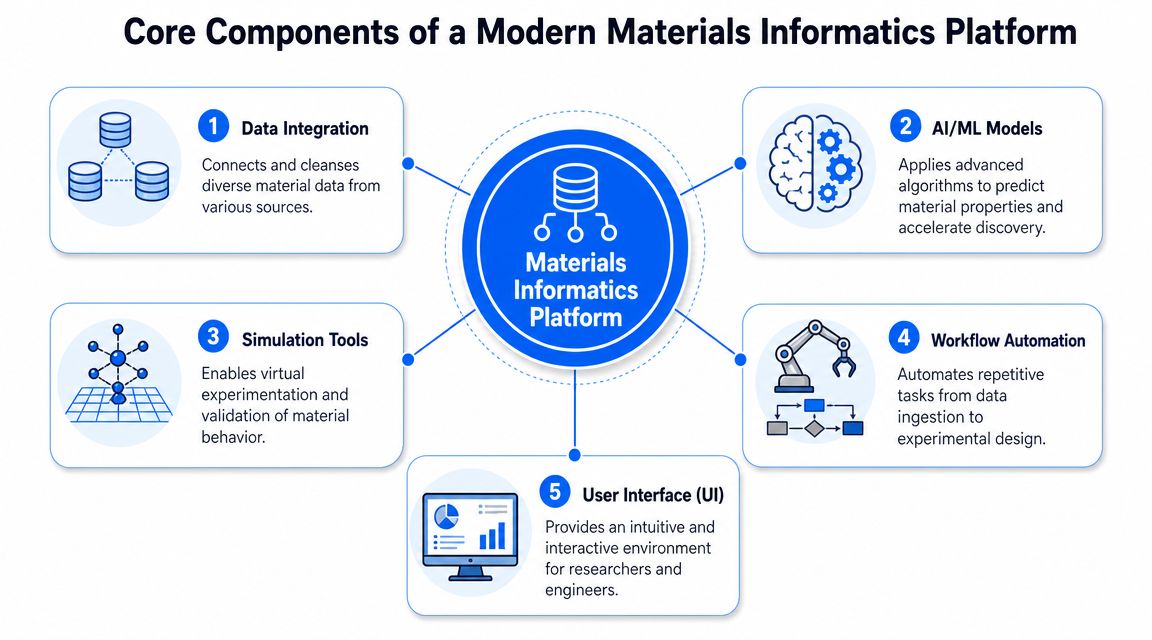
Data ingestion and curation
This is the essential layer. If a platform can't absorb scattered historical data and turn it into structured, searchable records, the rest won't matter. Most organizations start with mixed units, duplicate materials names, missing process variables, and inconsistent test descriptions. The platform has to normalize that mess without stripping out scientific nuance.
Look closely at ontology support, metadata design, lineage tracking, and how the system handles partial records. Teams that already think carefully about master data usually move faster here. A practical reference is how to select an MDM solution, because many of the same data governance questions apply when you're trying to make materials records reusable across an enterprise.
Experimental workflow integration
A materials informatics platform can't live off to the side as an “analysis environment” that scientists visit once a month. It has to connect to the systems where work happens. That usually means some combination of ELN, LIMS, characterization exports, simulation outputs, and process or quality systems.
The point isn't integration for its own sake. It's continuity. If scientists log one version of the truth in the lab and engineers rely on another version later, the platform becomes a reporting layer, not a decision layer.
Predictive modeling and experiment guidance
This is the part vendors lead with, but it only works if the first two layers are solid. Strong platforms help teams predict properties, rank candidates, identify variable interactions, and recommend the next best experiment. In real environments, the value often comes from narrowing the search space rather than claiming perfect prediction.
Some teams also want support for active learning or inverse design. Others care more about ranking known formulation directions. The right balance depends on your program maturity and the kind of data you own.
Explainability and confidence scoring
Scientists won't trust a recommendation engine that acts like a black box. They need to know why the model favors one formulation over another, how much evidence supports it, and when the system is extrapolating beyond familiar territory.
Useful explainability features include:
- Confidence indicators: Show whether the prediction sits inside or outside the model's comfort zone.
- Feature contribution views: Reveal which variables are influencing a result.
- Historical precedents: Link predictions back to related experiments or formulations.
- Uncertainty-aware ranking: Help teams decide what to validate first.
If a platform can recommend an experiment but can't explain why, your best scientists will ignore it the moment a result looks counterintuitive.
Enterprise security and governance
For many materials organizations, especially in polymers, chemicals, and regulated manufacturing, data risk is not theoretical. Formulations, processing know-how, customer-specific specifications, and quality records are all sensitive. Security reviews can delay a deployment longer than technical integration.
A platform should support role-based access, auditability, and governance rules that reflect how your teams really work. This is also where product fit diverges sharply. Some tools are designed for exploratory research. Others are built for enterprise controls and cross-functional deployment.
One example is Polymerize, which offers a cloud-based materials informatics environment centered on a unified R&D data backbone and domain-specific models for materials development. That kind of architecture is often more relevant for enterprise buyers than a pure modeling tool, because it ties prediction to data structure, provenance, and operational access.
Driving Business Value and ROI with Materials Informatics
The business case for a materials informatics platform usually isn't one dramatic breakthrough. It's the accumulation of smaller operational gains that compound across a portfolio. Fewer redundant experiments. Faster triage of weak ideas. Better continuity from lab work into engineering and manufacturing. Less time wasted searching for prior results that should already be easy to find.
That's why the strongest ROI cases usually come from organizations that treat the platform as infrastructure, not as an isolated AI purchase.
Where the economic value actually shows up
According to Ansys, one of the core functions of materials informatics is making materials data transferable into native engineering tools such as CAD and simulation, which helps engineers evaluate material choices and performance without extensive physical testing in its overview of what materials informatics is. That point deserves more attention than it usually gets.
When data moves cleanly from R&D into engineering workflows, teams can screen options in silico before committing scarce lab or prototyping capacity. That doesn't remove experimental work. It changes where physical effort is spent.
In practice, business value tends to appear in five places:
- Experiment prioritization: Scientists stop spending equal effort on low-probability ideas.
- Knowledge retention: The company keeps learning even when personnel, suppliers, or project teams change.
- Scale-up alignment: Process and engineering teams inherit structured information instead of disconnected reports.
- IP protection: Sensitive formulation knowledge lives in governed systems rather than private files and inboxes.
- Cross-team reuse: A lesson from one product line becomes searchable and usable in another.
What ROI looks like in practice
A lot of buyers make the mistake of demanding a single universal ROI metric before they've defined the operating problem. That's rarely useful. Start with cost centers your team already feels.
Ask where the current process burns time or budget:
| Friction point | What a platform can change |
|---|---|
| Repeated dead-end testing | Rank experiments before the lab runs them |
| Slow handoff to engineering | Package data in a format downstream teams can use |
| Scattered historical data | Centralize and standardize prior work |
| Scientist dependence on tribal knowledge | Convert undocumented know-how into reusable records |
A materials informatics platform earns its keep when it helps scientists say “no” to weak experiments earlier, not when it produces prettier charts after the fact.
The financial case gets stronger when the platform supports more than one team. A narrowly scoped modeling tool can help a single group. A well-implemented platform improves portfolio-level decision quality.
How to Evaluate and Select the Right Platform
Most vendor evaluations go wrong for a simple reason. The buyer watches a polished demo built on clean sample data, then assumes the platform will perform the same way on years of inconsistent in-house records. It usually won't. That doesn't mean the platform is weak. It means the evaluation was unrealistic.
Independent industry coverage points out that materials informatics often relies on sparse, high-dimensional, biased, and noisy data, and that a platform's real value often lies in how well it curates, governs, and extracts insight from imperfect historical records, as discussed in this IDTechEx analysis of materials informatics. For most enterprise teams, that is the buying issue.
Start with your ugliest data, not the vendor demo
If you're choosing your first materials informatics platform, don't begin with a greenfield use case. Begin with a dataset that reflects reality. Pull records from spreadsheets, ELN exports, and whatever incomplete historical files scientists still rely on. If the platform can't create order from that environment, its modeling layer won't save the project.
Good evaluation data should include:
- Missing fields: So you can see how the system handles partial records.
- Naming inconsistency: Different labels for the same material, additive, or test.
- Mixed structure: Tabular data, notes, attachments, and process context.
- Known edge cases: Outliers, failed runs, and contradictory historical entries.
This isn't about making vendors uncomfortable. It's about buying against the conditions your scientists face.
Questions that reveal platform fit
The best evaluation questions are operational, not theatrical. Don't ask whether the platform uses AI. Ask what happens when the data is messy, incomplete, or politically sensitive.
A practical shortlist looks like this:
- How does the platform ingest historical experimental data from spreadsheets, ELNs, and other lab systems?
- What curation work is automated, and what still requires scientist review?
- How does the platform represent provenance, uncertainty, and version history?
- Can users understand why a recommendation was made, or only see the output?
- How easily does data move into adjacent systems used by engineering, manufacturing, quality, or supply chain?
- What controls exist for role-based access, auditability, and IP-sensitive workflows?
- Does the vendor have real domain understanding in your materials class, whether polymers, chemicals, coatings, or advanced materials?
Don't ask a vendor whether their model is accurate in general. Ask how they prevent scientists from trusting predictions that sit outside the model's valid range.
You should also test the user experience with actual bench scientists, not just innovation managers or IT stakeholders. If a platform requires a data science intermediary for routine use, adoption will stall.
Materials Informatics Platform Evaluation Checklist
| Criterion | What to Ask | Why It Matters |
|---|---|---|
| Data readiness support | How do you clean, map, and normalize messy historical records? | Most value depends on usable data, not just algorithms |
| Integration depth | Which systems do you connect to, and how is data synchronized? | The platform has to fit existing workflows |
| Scientific usability | Can bench scientists use it directly for day-to-day decisions? | Low usability turns the platform into a niche tool |
| Explainability | How do users see model rationale, confidence, and precedent? | Trust determines adoption |
| Domain fit | What materials classes and workflows do you handle well? | General tools often miss field-specific nuance |
| Governance and security | How do you manage access, audit trails, and sensitive IP? | Enterprise deployment depends on it |
| Implementation model | What does onboarding require from our team? | Hidden services effort can derail timelines |
| Scale beyond the pilot | How does the system support multiple teams and sites? | A pilot that can't scale becomes shelfware |
Selection gets easier when you stop looking for the smartest model and start looking for the strongest operating fit. In most companies, that's what separates a successful materials informatics platform from an expensive experiment.
Real-World Use Cases in Key Industries
Use cases become more convincing when they sound like the work your teams already do. The point isn't fantasy success stories. It's understanding where a materials informatics platform changes decisions on the ground.
Polymers and formulations
A polymer team often faces a familiar problem. They need to hit a difficult balance of performance targets, but the historical formulation record is inconsistent. Resin grades were renamed over time. Additive loading is documented in different units. Processing notes are buried in free text.
In that setting, a platform helps by connecting formulation composition, process conditions, and resulting properties into one searchable system. Scientists can compare similar historical trials, identify variable ranges worth revisiting, and narrow the candidate space before compounding new batches.
The practical payoff is usually better experiment discipline. Teams stop chasing combinations that look novel only because prior failures were never easy to find.
Specialty chemicals and process-sensitive products
In chemicals, product performance often depends on both formulation and process. That means a simple property database isn't enough. You need to know what was mixed, how it was processed, which raw material version was used, and what happened during scale-up or quality review.
A good platform makes those relationships visible. It can connect formulation records with processing conditions and downstream quality outcomes so the team can spot patterns that weren't obvious when data was reviewed system by system.
One of the biggest benefits here is reducing false conclusions. Scientists can separate chemistry problems from process problems instead of changing both at once and learning nothing.
Advanced materials and engineering handoff
Advanced materials programs often break down at the handoff between discovery and engineering. The research team may identify a promising candidate, but engineering still needs structured property records, simulation-ready inputs, and traceable evidence for why that candidate deserves further evaluation.
That's where platform architecture matters. When candidate materials, test data, and contextual metadata are already structured, engineers can move faster into simulation, design review, or manufacturing feasibility analysis.
The strongest use case is rarely “AI found a miracle material.” It's “the team could finally connect discovery, validation, and downstream decision-making without rebuilding the dataset every time.”
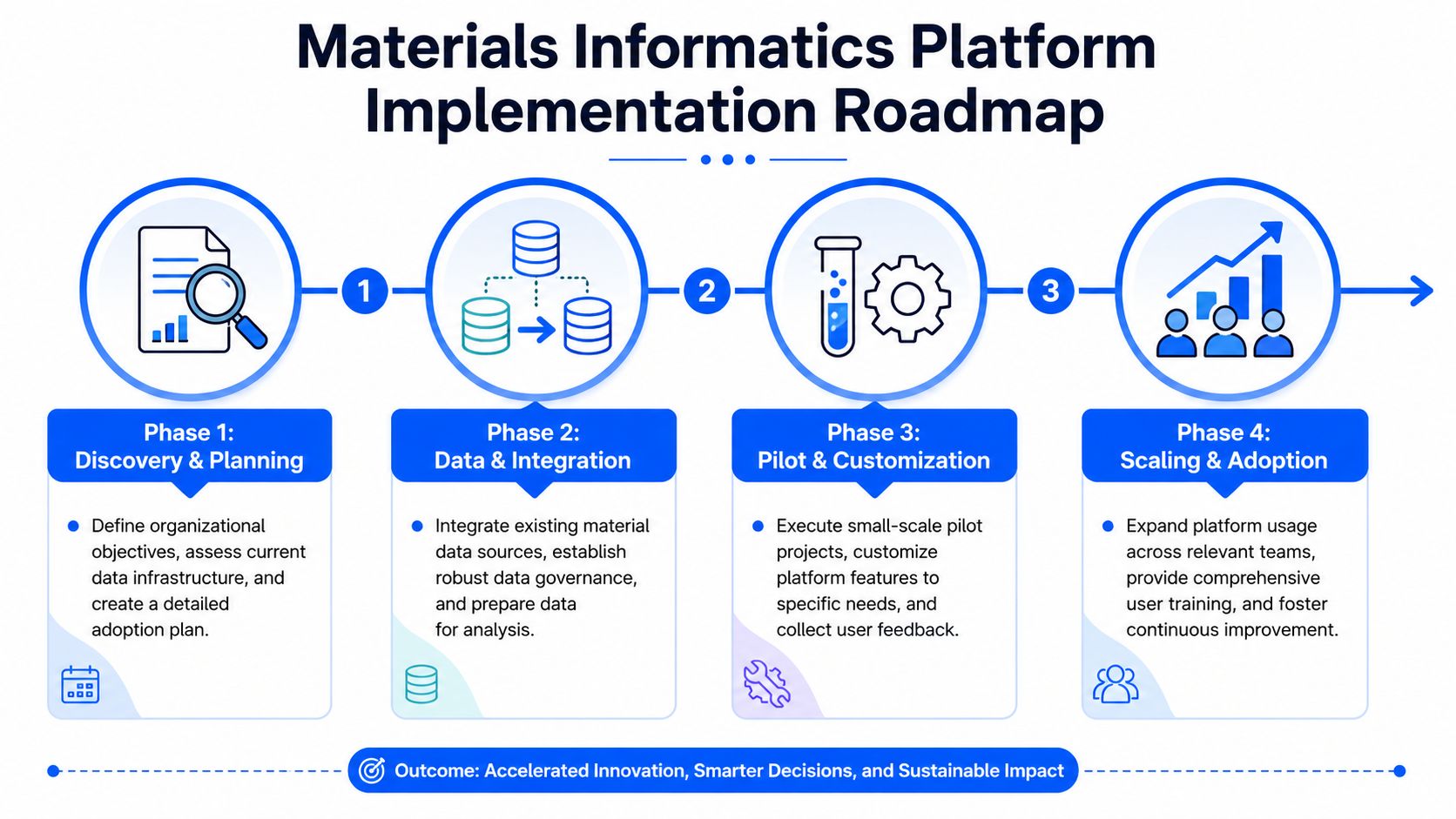
Your Implementation Roadmap and Managing Change
The first rollout should be boring in the best possible way. Clear scope. One real business problem. One dataset that matters. One science team willing to engage. Companies get into trouble when they launch a broad transformation program before they've proved that the platform fits actual R&D work.
Phase the rollout so the science team trusts it
Start with a focused pilot tied to a painful workflow. Good candidates include formulation optimization, historical experiment recovery, or a recurring scale-up bottleneck. Choose a problem where better data structure and recommendation support could visibly improve daily work.
Then build outward in phases:
- Phase 1: Audit data sources, select a pilot use case, and define what good adoption looks like.
- Phase 2: Integrate the core systems needed for that use case and clean the first meaningful dataset.
- Phase 3: Train a small group of scientists and technical champions who can pressure-test outputs.
- Phase 4: Expand to adjacent teams only after the first users can point to concrete workflow improvements.
Treat adoption as a workflow change
A materials informatics platform doesn't fail because scientists dislike technology. It fails when the software adds steps without removing friction. If users still have to enter data twice, explain context in side emails, or validate model outputs with no visibility into reasoning, they'll fall back to old habits.
The implementation team should watch for behavior, not just logins. Are scientists using the platform to decide what to test next? Are engineers pulling from it during handoff? Are managers using it to review portfolio learning instead of asking each team for custom spreadsheets?
Success comes from making the platform part of how R&D work gets done, not from announcing that AI has arrived.
If your organization is deciding whether to move beyond manual trial-and-error, Polymerize is one option worth evaluating for polymer, chemical, and advanced materials teams that need a centralized R&D data backbone, explainable model support, and enterprise controls in the same environment. The right next step isn't a broad software rollout. It's a focused pilot on a real dataset, with a problem your scientists already want solved.

