A lot of teams think they have material traceability because they can answer one narrow question under pressure: which supplier shipped this drum, this resin, or this additive? That isn't enough when a formulation drifts in pilot, a customer questions a certificate, or a quality event forces you to determine exactly which downstream batches consumed a suspect lot.
In polymers and chemicals, the core challenge isn't finding a document. It's reconstructing a material's full history across sourcing, lab work, scale-up, production, release, and shipment, then using that history to make better decisions faster. Leadership teams usually feel this gap at the worst moment, when operations, quality, regulatory, and R&D all need the same answer and each function is working from a different system.
A modern material traceability program solves that problem. It reduces exposure during recalls and audits, but its strategic value is larger than compliance. When traceability data is structured well, it becomes the backbone for faster root-cause analysis, better scale-up decisions, and AI-ready materials development.
Table of Contents
- The High Cost of Untraced Materials
- A biography for every batch
- What complete chain of custody actually captures
- Small input changes create large downstream consequences
- Composition claims only hold if identity survives processing
- Why paper records break under real operating conditions
- How the core systems work together
- Traceability system roles
- Start with the data model, not the software demo
- Build lot genealogy into daily work
- Use implementation stages that match risk and value
The High Cost of Untraced Materials
A customer reports a field failure on a Friday afternoon. Quality asks which finished lots used the suspect resin. Manufacturing can only narrow it to three production days. R&D has test results, but they sit in a separate system from batch records and formulation history. The immediate decision is predictable. Hold everything that might be affected, stop shipments, and start reconstructing the past by hand.
That is the cost of poor material traceability. The first loss is precision.
In polymers and chemicals, small material differences can spread quickly across multiple batches, product families, and customer orders. If teams cannot tie incoming lots to formulations, process conditions, test results, and shipment records, they widen the containment area to stay safe. That protects the business in the short term, but it also freezes good inventory, consumes engineering time, and delays customer communication.
The financial hit rarely shows up in one line item. It appears as excess quarantine stock, extra changeovers, rush testing, supplier disputes, scrap that might have been avoided, and long root-cause meetings built around partial records. Leadership teams often treat these as separate problems. In practice, they come from the same failure. The business cannot identify what happened, where it happened, and what was exposed.
The operational burden is just as serious:
- Containment gets too broad: teams block more raw material, WIP, and finished goods than the event requires.
- Investigations slow down: engineers reconcile ERP transactions, lab data, batch sheets, and email attachments instead of testing hypotheses.
- Release decisions get weaker: quality relies on judgment calls because the material history is incomplete.
- R&D learning stalls: formulation teams cannot reliably connect performance shifts to supplier changes, storage conditions, or process drift.
- Customer response loses credibility: commercial teams speak in probabilities when customers need specifics.
I have seen this pattern repeatedly. A traceability gap that starts as a compliance weakness becomes an R&D handicap. If material history is fragmented, teams cannot separate signal from noise. That matters far beyond recalls. It limits how fast a company can qualify new suppliers, compare formulation variants, or train AI models on past experiments. Platforms such as Polymerize only create real value when the underlying batch, test, and process records preserve material identity well enough to support model-ready analysis.
Inventory control is part of the same problem, not a separate one. This guide to automated inventory control savings is a useful reference for understanding how better material identification, location accuracy, and transaction discipline reduce daily operating losses.
If a team cannot trace material quickly and confidently, it does not just have a documentation issue. It has a slower factory, weaker investigations, and a thinner foundation for AI-driven materials development.
Understanding Material Traceability from End to End
Material traceability is the complete, auditable biography of a material lot. It starts when raw material enters the business and continues through every transformation, transfer, test, blend, hold, release, and shipment. Good programs don't just record that material existed. They preserve identity as the material changes form and moves across functions.
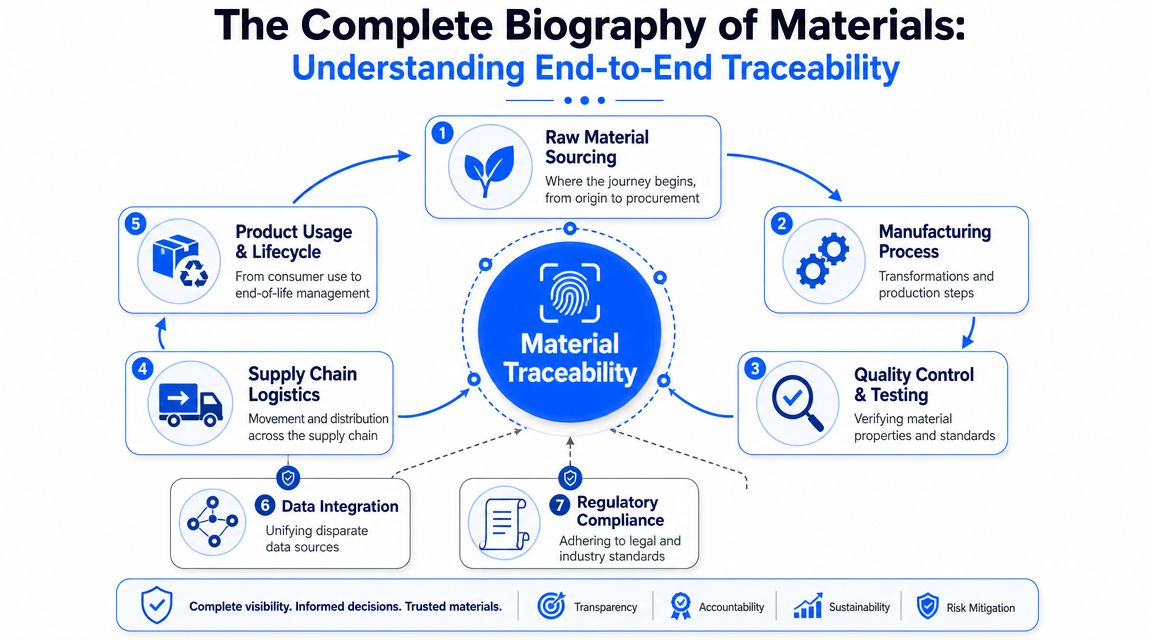
A biography for every batch
Most companies begin with lot tracking. That's useful, but it isn't the same as end-to-end traceability. Lot tracking tells you what came in and what went out. End-to-end traceability tells you what happened in between.
For a polymer resin, that biography should include supplier identity, certificate references, receiving status, storage conditions where relevant, sampling and test results, dispensing records, formulation use, process parameters tied to the batch, nonconformance events, rework if any, release decision, and final customer allocation. For a chemical intermediate, it should also preserve how it was transformed into the next material state.
A major historical driver here is the expansion of chain-of-custody requirements in sustainability and regulatory regimes, especially in Europe. Guidance now points to digital product passports becoming mandatory for many products sold in European markets, marking a move from simple lot tracking to evidence-based material provenance where every handler records critical details as the material moves up the value chain, as outlined in Technomark's guidance on traceability requirements and digital product passports.
What complete chain of custody actually captures
In practice, a usable chain of custody has to answer three kinds of questions.
Where did this material come from?
Supplier, source documents, lot number, certificates, declarations, and receiving event.What happened to it here?
Storage, sampling, testing, weighing, blending, reactions, transfers, packaging, holds, deviations, and operator or equipment context.Where did it go next?
Which pilot lots, production batches, retained samples, customer shipments, and waste streams consumed it.
Practical rule: If your team can trace backward to origin but can't trace forward to every downstream use, the chain is incomplete.
That standard matters because weak handoffs are where traceability usually breaks. Material gets relabeled. Partial quantities are moved without updating remaining balance. Lab samples become disconnected from the parent lot. Pilot trials create data that never flows back into manufacturing knowledge.
The strongest programs treat each handoff as a controlled event. They don't rely on memory or post hoc spreadsheet cleanup. They assign identity at the carrier level, then preserve that identity through every material movement and transformation.
Why Traceability Is Non-Negotiable for Polymers and Chemicals
Polymers and chemicals punish weak traceability faster than many other manufacturing environments. Small differences in raw materials, handling, or processing can change viscosity, cure behavior, dispersion quality, stability, or final performance in ways that aren't obvious at receiving.
Small input changes create large downstream consequences
This is especially true in multi-component systems. A formulation may depend on tight interactions between base polymer, filler, additive package, catalyst, solvent, or stabilizer. If one input shifts, the problem may surface much later, during extrusion, coating, molding, aging, or customer use.
That creates a practical leadership issue. Without disciplined material traceability, teams often blame the most visible variable instead of the actual one. They adjust process settings, rewrite work instructions, or question operator execution when the root cause sits upstream in material provenance or lot-specific variation.
Common high-risk situations include:
- Scale-up transitions: Lab-grade success can fail in pilot or manufacturing if the consumed lots differ in ways the records don't capture.
- Regulated applications: Aerospace, electronics, medical, and specialty industrial customers expect defensible genealogy, not just a batch traveler.
- High-value formulations: When intellectual property is embedded in composition and process know-how, weak traceability makes both protection and troubleshooting harder.
Composition claims only hold if identity survives processing
For plastics and composites, the technical standard is even stricter. Material traceability depends on preserving an unbroken chain of custody from raw material to finished part, including manufacturer certificates of conformance and lot numbers. That matters because weight-based composition claims and bill-of-material verification are only defensible when each lot's identity survives every processing step, as explained in TrusTrace's discussion of material traceability for plastics and composites.
That point has direct implications for polymers and chemicals beyond sustainability claims. It affects recycled-content declarations, customer-specific composition requirements, supplier substitution controls, and any situation where you must prove the ordered input matches what was consumed.
If identity breaks at repacking, pre-blending, or internal transfer, the downstream certificate may look complete while the technical evidence is weak.
This is why mature organizations stop treating traceability as an EHS or QA side project. In advanced materials, it belongs in the operating model for R&D, process engineering, manufacturing, quality, and regulatory affairs.
The Digital Toolkit for Modern Traceability
A traceability program usually gets stress-tested at the worst possible moment. A customer reports an off-spec batch. Quality needs affected lots within the hour. R&D wants to know whether the root cause sits in a resin grade change, a drying condition, or a reformulation trial that crossed into pilot production. If the record lives across paper logbooks, spreadsheets, email attachments, and disconnected batch files, the team spends its first day reconstructing history instead of containing risk.
That is the practical reason digital traceability matters. It turns material history into an operating system for decisions, not just an archive for audits. In polymers and chemicals, that same system also becomes the data backbone for faster formulation learning, scale-up discipline, and later-stage AI work.
Why paper records break under real operating conditions
Paper can capture facts. It cannot maintain synchronized identity, status, and genealogy across receiving, lab work, production, and quality review.
A handwritten receiving log does not update inventory state. A spreadsheet used by formulation scientists rarely carries forward cleanly into pilot or plant execution. A certificate PDF stored in email is weak evidence if nobody linked it to the exact internal lot, container, and consumed batch. Under normal workload, those gaps stay hidden. Under deviation, complaint, or recall pressure, they become the investigation.
The fix is not one giant application. It is a connected digital stack that records physical events where work happens and passes clean identifiers between systems.
How the core systems work together
The physical-to-digital bridge starts with barcodes, QR codes, or RFID attached to lots, containers, and internal transfers. Once every material carrier has a machine-readable identity, the rest of the stack can maintain custody, status, and genealogy with much less manual reconciliation.
- ELN: Captures formulation intent, experimental execution, observations, and the exact material lots used in R&D.
- LIMS: Manages samples, test methods, specifications, results, and release evidence.
- ERP: Holds purchasing, receipts, inventory transactions, batch status, and shipment records.
- MES or shop-floor applications: Record material consumption, work-order execution, operator actions, and equipment context during production.
- QMS: Controls deviations, holds, CAPAs, change control, and disposition decisions.
Used well, these systems do more than support compliance. They let teams connect development history to manufacturing outcomes. That matters when leadership wants to know which raw material shift changed viscosity drift, which compounding line produced the defect pattern, or which trial conditions should feed the next model for formulation prediction. Platforms such as Polymerize fit into this direction by helping companies unify experimental, process, and materials data so traceability supports both control and learning.
For some organizations, immutable event trails also matter. If you are evaluating distributed proofs of custody or ownership models for high-value or highly scrutinized assets, it is worth understanding adjacent approaches such as RWA tokenization solutions. Not every materials company needs that architecture, but the design logic is useful when tamper resistance and auditable transfer history become explicit requirements.
Traceability system roles
| System | Primary Role in Traceability | Typical Data Captured |
|---|---|---|
| ELN | Preserves R&D execution context | Formulations, experimental steps, observations, linked material lots |
| LIMS | Controls analytical and QC evidence | Sample IDs, test methods, results, specifications, release data |
| ERP | Maintains transactional batch record | Purchase orders, receipts, inventory balances, lot status, shipments |
| MES or shop-floor app | Connects physical production to digital history | Work orders, material consumption, operator actions, equipment context |
| QMS | Governs exception handling and evidence | Deviations, holds, CAPAs, quarantine, approvals |
A traceability stack fails when each application is clean on its own but disconnected from the others.
The practical target is shared identity and reliable genealogy across systems, with clear ownership for each data domain. ERP should not be forced to behave like an ELN. An ELN should not become the plant inventory master. The right design assigns each system a defined role, then synchronizes the fields that matter most: material ID, supplier lot, internal lot, container ID, status, quantity, location, and parent-child relationships created by blending, repacking, sampling, and consumption.
That architecture improves audit response. It gives R&D, manufacturing, and quality one evidence base for troubleshooting today's failures and training tomorrow's models.
Implementing a Robust Traceability Program
A traceability program usually fails on the plant floor long before it fails in an audit. A pallet arrives with a supplier label that does not match the internal item code. A sample reaches the lab without a clear parent lot. Production consumes a partial container, then someone records the balance at shift end from memory. At that point, the software choice is no longer the main problem. The operating rules are.
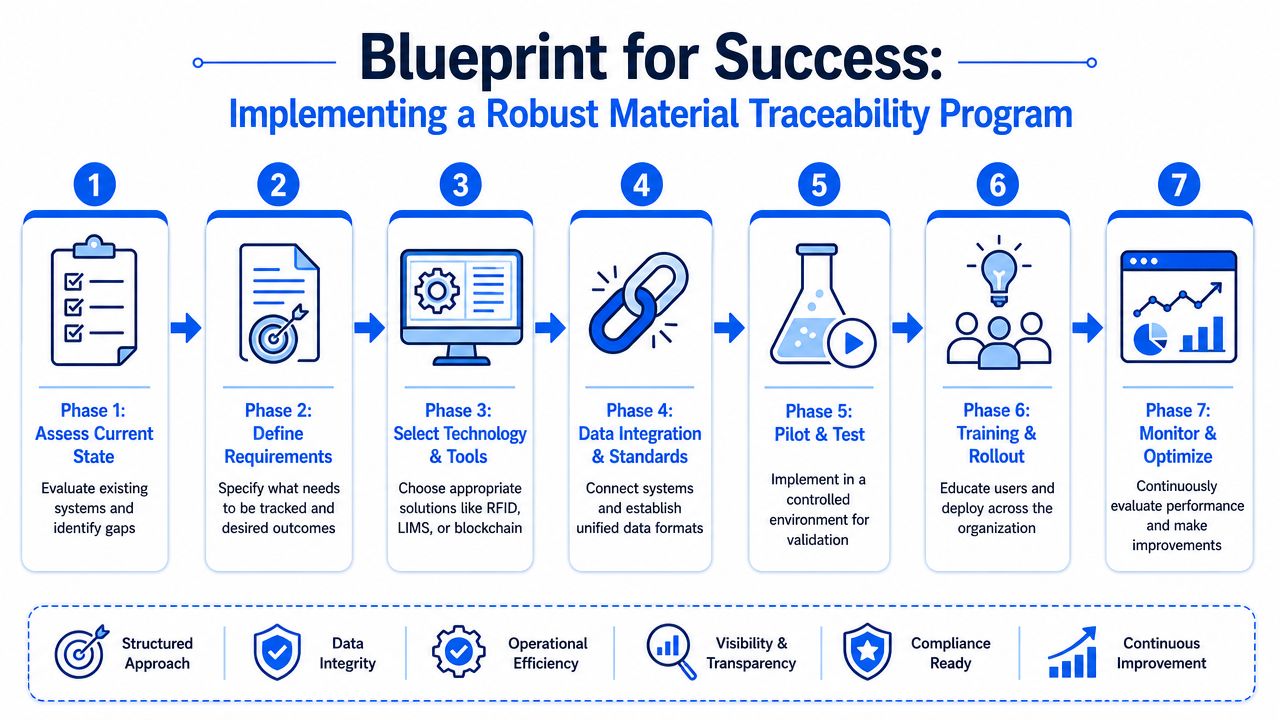
Start with the data model, not the software demo
An effective program defines the minimum record that must exist every time material changes hands, changes state, or enters a decision point. For polymers and chemicals, that means tracing more than a batch number. Teams need a carrier-level record that captures what arrived, how it was identified, where it went, what happened to it, and what evidence supports release or rejection.
At a minimum, each material carrier should link to a unique ID plus its origin, supplier lot, receiving package, current location, remaining quantity, movement history, consumption, and loss. A closed-loop model like this narrows the affected scope during an investigation and supports faster quarantine decisions, as described by AISC in its overview of Factory 4.0 traceability.
The data model should define:
- Identity fields: Material code, supplier lot, internal lot, package or container ID
- State fields: Quality status, quantity balance, location, custody owner
- Transformation fields: Parent-child relationships for splits, blends, reactions, repacks, and rework
- Evidence fields: Certificates, declarations, test results, deviations, approvals
Many leadership teams make the wrong trade-off, accepting a thinner data model to speed deployment, then discovering six months later that the system can support inventory control but not root-cause analysis, supplier comparison, or model-ready R&D history. Retrofitting lineage after go-live is expensive.
Build lot genealogy into daily work
Genealogy has to be created during execution. It cannot be reconstructed reliably from reports after the fact.
If operators can consume material without scanning it, if lab staff can create samples without inheriting the parent lot, or if transfers happen outside the system, gaps will appear immediately. Those gaps matter in compliance. They matter even more in development, where one missing lot link can invalidate a trial comparison or hide the reason a formulation suddenly drifted.
Use a small number of control points that are difficult to bypass:
Receive with identity first
No unlabeled or unverified container enters controlled inventory.Sample from the lot record
Lab samples should inherit parent identity automatically, not through manual relabeling.Consume by scan or verified selection
Free-text entry creates duplicate names, lot ambiguity, and reconciliation work.Record splits, blends, and repacks as lineage events
These are the moments when material history is most often lost.Control quarantine through system status
Holds need to block movement and use in the execution system, not sit in email threads.
Operational discipline is the program.
Use implementation stages that match risk and value
A company does not need enterprise-wide perfection on day one. It does need a rollout sequence that reflects where traceability failures are most expensive. In practice, that usually means starting where customer risk, process complexity, and learning value overlap.
A staged rollout often works best:
- Start with high-risk materials: Focus on inputs tied to safety, regulated declarations, narrow process windows, or recurring investigations
- Pilot one value stream: Choose a line, plant, or product family with clear ownership and manageable handoffs
- Map break points explicitly: Repacking, partial consumption, retained samples, toll manufacturing, and external testing need defined rules
- Train by role: Warehouse, lab, production, procurement, and quality do not need the same instructions
- Measure exception rates early: Track scan bypasses, unlabeled containers, quantity mismatches, and unresolved lot links before expanding scope
The key trade-off is speed versus behavior change. Teams can install software quickly. They cannot standardize receiving, sampling, production logging, and release practices at the same pace unless leadership treats those workflows as part of the implementation, not as local details to clean up later.
That discipline pays twice. It improves audit readiness now, and it creates the structured history that advanced analytics and AI systems need later. For organizations investing in faster formulation cycles, supplier optimization, or platforms such as Polymerize, implementation is not just a compliance exercise. It is the groundwork for a usable materials data backbone.
Accelerating R&D with AI and Unified Data
A familiar failure pattern shows up in materials organizations: a development team sees promising lab results, scale-up starts, and performance suddenly drifts. The formulation did not change on paper. The actual input history did. A different supplier lot, a handling deviation, or an undocumented substitution entered the process, and no one can connect the result back to the full material record fast enough to learn from it.
Why R&D needs traceability-grade data
That is where traceability becomes strategically valuable for R&D. Compliance is still part of the job, but the larger payoff is decision quality. When teams can connect provenance, formulation, processing conditions, test outputs, and scale-up outcomes in one usable record, they stop repeating experiments for avoidable reasons.
Many companies already hold the raw ingredients for this. Years of formulation work sit in spreadsheets and ELNs. Test results sit in LIMS. Supplier declarations sit in quality systems or shared drives. Batch history sits in ERP or production logs. The problem is not data scarcity. The problem is weak identity across systems.
AI models are particularly sensitive to that weakness. If the property result is linked to the wrong lot, if a pilot batch used a substitute raw material that never made it into the record, or if the process window is missing, the model learns from noise. That slows R&D rather than speeding it up.
Teams with connected traceability data can answer more useful questions:
- Which supplier-lot attributes track with property variation?
- Which process settings hold up across normal raw-material variability?
- Which formulation changes improved performance, and which only masked inconsistency in the input stream?
- Which failed trials should be excluded from model training because the material history is incomplete or suspect?
Polymerize fits this layer as a system for bringing fragmented experimental and materials records into a structured environment that R&D teams can effectively use. The practical value is not just storing more data. It is preserving context well enough to support formulation design, scale-up decisions, and explainable AI workflows.
Where AI changes the value of traceability
Once data is unified, traceability stops being a retrieval tool and becomes a learning system.
That shift matters because document-based traceability has limits. A certificate of analysis may confirm what a material was declared to be. It does not always capture what the material did in the process, how it was handled between receipt and use, or whether an undeclared change affected downstream performance. For high-risk materials, premium claims, or chronic variability problems, teams often need both documentary traceability and selective scientific verification. Oritain outlines that broader approach in its discussion of product and material traceability.
For R&D, the trade-off is straightforward. Full verification on every lot is expensive and slow. Pure document trust is faster, but it can contaminate development data with hidden errors. The right operating model uses routine digital traceability across all material flows, then applies deeper checks where the technical or commercial risk justifies the cost.
The AI layer benefits directly from that discipline:
- Unify historical records: Connect formulations, lot genealogy, process conditions, test results, and deviations
- Screen for anomalies: Flag impossible mass balances, inconsistent specifications, and performance shifts that do not match the recorded inputs
- Model with process context: Train on source, handling, and transformation history, not just nominal composition
- Prioritize verification: Focus lab checks on lots, suppliers, or experiments that create the most uncertainty in the dataset
The central point is simple. In materials development, model quality depends on material history quality. Better algorithms do not fix weak lineage.
A short product walkthrough makes the operating model easier to picture:
When organizations get this right, traceability supports two outcomes at once. Quality and regulatory teams gain cleaner evidence. R&D teams gain a reliable memory of what was tried, what entered the process, and why a result should be trusted. That is the data backbone AI needs if it is going to improve materials development instead of adding another layer of noise.
Measuring Success and Avoiding Common Pitfalls
If leadership can't tell whether the traceability program is improving operations, the initiative will eventually get reduced to a compliance checkbox. The right measures are operational, not cosmetic.
What to measure
Track outcomes that reflect decision speed, scope control, and data usability:
- Time to root cause: How quickly can the team move from issue detection to a defensible cause hypothesis?
- Recall or quarantine scope: When something goes wrong, can you isolate affected material precisely instead of freezing a broad population?
- Audit readiness: Can quality and regulatory teams retrieve genealogy and evidence without manual reconstruction?
- Data completeness at handoff points: Are receiving, sampling, transfer, consumption, and release events consistently captured?
- R&D reuse of traceability data: Can scientists connect historical lots and process context to performance outcomes in a practical way?
These metrics tend to reveal whether traceability is real or performative. A system may have high data volume and still be weak if investigators can't trust relationships between records.
What usually goes wrong
Three failure patterns show up repeatedly.
First, companies treat traceability as a one-time IT deployment. It isn't. It is an operating discipline that needs governance, ownership, and periodic redesign as products, regulations, and plants change.
Second, teams ignore master data. If material names, supplier identities, lot formats, and status codes aren't governed, even good software will produce messy genealogy.
Third, organizations leave critical data in silos. Quality has one truth, R&D another, and manufacturing a third. That blocks both containment and learning.
The easiest way to spot a weak program is this: every investigation begins with data cleanup.
The most resilient teams keep the standard simple. One identity model. Clear handoff rules. Tight parent-child genealogy. Evidence attached at source. Then they keep improving it as new requirements emerge.
If you're building that kind of traceability backbone and want it to support both compliance and faster materials development, Polymerize is worth evaluating as part of the stack. It gives R&D teams a way to unify fragmented experimental and material records into structured, AI-ready data so traceability can serve discovery, optimization, and scale-up instead of sitting idle in disconnected systems.

