Your team probably already knows the pattern. Experimental results live in shared drives, instrument outputs sit in vendor-specific formats, formulation history is buried in spreadsheets, and the only person who understands a critical legacy LIMS workflow is the scientist who built a workaround years ago. Everyone says they want AI in materials R&D, but the data foundation still looks like a patchwork of disconnected records.
That's why legacy system migration matters. Not as an IT housekeeping exercise, but as the move that turns scattered experimental history into a usable R&D asset. If your data stays fragmented, your scientists keep repeating avoidable work, your digital team keeps building fragile integrations, and your AI ambitions stay stuck at pilot stage.
The caution is real. One industry source warns that 60% of legacy migrations fail on the first attempt (Buchanan Technologies). In practice, that aligns with what many R&D leaders already suspect. Migrations fail when teams treat them as infrastructure swaps instead of operational redesign. In a materials environment, the issue isn't only whether records move. It's whether formulations, test conditions, units, lineage, and context survive the move in a way scientists can trust.
A workable migration playbook starts from a different premise. Move only what creates value, preserve continuity for active programs, and build toward an AI-ready data backbone that supports faster experiment design, stronger scale-up decisions, and better reuse of institutional knowledge.
Table of Contents
- Match strategy to scientific and business value
- Migration Strategy Comparison for R&D
- When retaining is the smart move
Your R&D Data Is Trapped What Now
In materials R&D, the biggest bottleneck often isn't lab capacity. It's fragmented knowledge. Teams may have years of tensile data, rheology runs, microscopy results, formulation tweaks, and failure notes, but none of it sits in one usable system. A scientist trying to answer a simple question, such as whether a resin family has already failed under similar humidity conditions, often has to search across spreadsheets, PDFs, inboxes, ELN exports, and file shares.
That fragmentation blocks more than reporting. It blocks learning. AI models can't do much with disconnected records, inconsistent metadata, and undocumented lineage. Scientists can't trust recommendations if the underlying data backbone is partial, duplicated, or context-free. Digital teams can't automate handoffs if every instrument and legacy application uses a different structure.
Practical rule: If your team can't reliably trace an experiment from raw input through formulation, processing conditions, and test result, you are not ready for serious AI adoption.
The mistake many organizations make is assuming the answer is a full rip-and-replace program. It usually isn't. A better starting point is to treat legacy system migration as a business-critical R&D enablement effort. The target state is not "everything in the cloud." The target state is a connected environment where experimental data is discoverable, comparable, governed, and reusable.
Three realities define the challenge:
- Scientific context matters: A migrated number without units, sample prep conditions, or material lineage is often useless.
- Operational continuity matters: You can't interrupt active development programs just to modernize architecture.
- Trust matters: If scientists doubt the migrated record, they'll fall back to offline trackers.
The hardest part of migration isn't moving data. It's preserving meaning.
That is why the migration plan has to tie directly to faster innovation. Which systems prevent cross-project learning? Which datasets could support property prediction if they were normalized? Which manual handoffs slow scale-up or technical transfer? Those are the right questions.
The organizations that get this right don't start with technology preference. They start with a disciplined sequence: assess the current estate, identify dependencies, map the data, choose the right treatment for each system, validate aggressively, and only then retire what no longer serves the business. That approach reflects the broader modern migration pattern described in this migration overview from KME Systems, where phased movement and structured preparation reduce disruption.
Phase 1 Assess and Map Your R&D Data Landscape
A migration that starts with "what platform are we moving to?" is already behind. In R&D, the first job is to understand how data moves through the organization. That means following the work from experiment planning to lab execution, analysis, review, scale-up, and reporting.
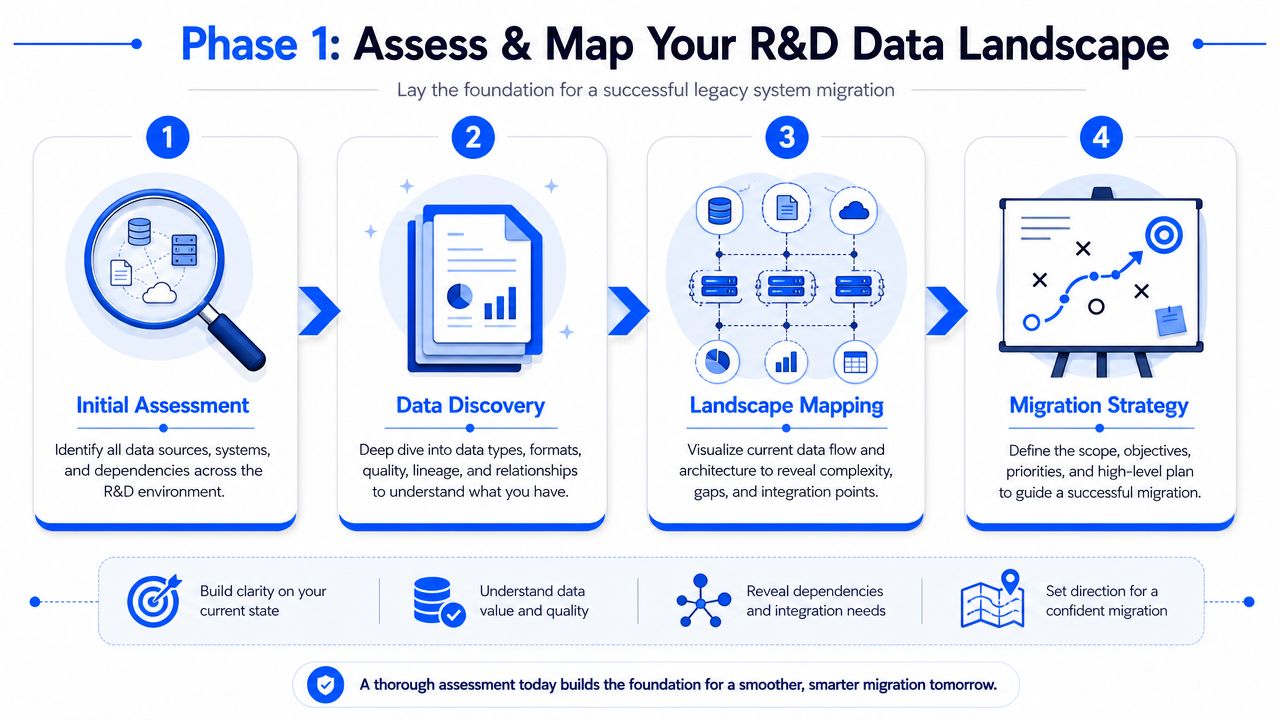
Start with workflows, not servers
A practical migration workflow begins by inventorying applications and dependencies, defining objectives and KPIs, building a field-level data dictionary, staging the move in a replica environment, and validating function plus data quality before cutover (Webflow's migration workflow guide). For materials teams, that sequence works because it forces business relevance into the technical plan.
Start by listing every place experimental or operational data lives. Include obvious systems such as LIMS, ELNs, file shares, and reporting databases. Then go after the less visible sources: instrument PCs, analyst-maintained spreadsheets, archived CSV exports, PDF reports, and custom scripts maintained by one person.
The inventory should answer five questions:
- What data is stored here
- Who uses it
- What upstream systems feed it
- What downstream reports, models, or processes depend on it
- What breaks if this source disappears for a week
That last question changes conversations. A legacy database that looks outdated may still sit in the middle of a release process or customer qualification workflow. A spreadsheet may appear informal but functions as the only master record for formulation history.
Build the mapping artifacts early
Once the inventory is real, create the artifacts that make migration controllable.
- Dependency map: Show how systems, files, instruments, and reporting flows connect.
- Business criticality ranking: Mark which assets support active programs, compliance, customer delivery, or scale-up.
- Field-level data dictionary: Define source fields, target fields, units, accepted values, and transformation rules.
- Quality log: Record duplicate issues, missing metadata, naming inconsistencies, and orphaned records.
In materials R&D, the data dictionary matters more than many teams expect. "Viscosity" isn't a single field if one system stores unit-bearing text, another stores a numeric value, and a third stores method-specific output codes. The same problem shows up with chemical naming, batch IDs, cure conditions, and test method references.
A good assessment also sets boundaries. Not every source deserves first-wave migration. Prioritize datasets that enable cross-project reuse, improve scientist searchability, or support future modeling. Leave low-value archival sources for later if they create unnecessary drag.
Audit for scientific reuse, not just technical ownership.
If you do this phase well, the migration stops being abstract. You can point to the records that matter, the bottlenecks worth fixing, and the systems that deserve either modernization, containment, or deliberate delay.
Choosing Your Migration Strategy Beyond Lift-and-Shift
Most legacy portfolios need more than one strategy. In R&D, that's even more true because systems differ sharply in scientific value, integration complexity, and operational sensitivity. One application may only need infrastructure relief. Another may need a redesign because its schema makes cross-experiment analysis almost impossible. A third may not deserve migration at all.
Match strategy to scientific and business value
The standard options are familiar: rehost, refactor, replace, and staged replacement through a strangler-style approach. The missing option in many discussions is retain. That matters because one modernization guide explicitly includes "Retain, Deliberate Deferral" as a valid option, chosen based on system condition and business outcomes (Shift Asia's modernization guide).
For materials R&D, the right choice depends on a short list of practical questions:
- Does this system contain unique experimental history that future models need?
- Does it disrupt current lab work if touched too early?
- Can its data be extracted cleanly enough to support downstream analytics?
- Is the workflow commodity or differentiating?
- Will migration reduce dependency on fragile manual workarounds?
A lift-and-shift move can make sense for a stable application that scientists rely on daily, especially if the immediate need is infrastructure modernization or access improvement. It does not solve poor data models, weak metadata, or hard-coded process logic. If the objective is AI readiness, lift-and-shift buys time. It does not create the destination.
Refactoring is the opposite. It takes longer and carries more design effort, but it gives you a chance to expose lineage, normalize metadata, improve interoperability, and remove structures that block downstream learning.
Replacement fits best when the legacy workflow is no longer strategic. If your team is keeping an old system alive mostly because "that's where we've always entered test requests," replacement may be cleaner than preserving obsolete behavior.
The strangler approach is often the most practical route in R&D. Wrap the old system, expose the data you need, move selected workflows first, and shrink the legacy footprint over time. That preserves continuity while letting the organization improve one boundary at a time.
Migration Strategy Comparison for R&D
| Strategy | Speed | Cost | Risk | AI-Readiness Impact |
|---|---|---|---|---|
| Rehost | Faster to execute | Usually lower upfront | Lower technical change risk, but legacy constraints remain | Limited unless paired with later data harmonization |
| Refactor | Slower | Higher design and implementation effort | Higher delivery risk, stronger long-term fit | Strong when data models and metadata are redesigned |
| Replace | Moderate to slow depending on workflow fit | Moderate to high | Risk shifts to process change and adoption | High if the new system supports structured, governed data |
| Strangler pattern | Moderate | Spread over phases | Lower cutover shock, more integration management | Strong because data and workflow modernization can happen incrementally |
| Retain | Fastest near term because nothing moves | Lowest immediate spend | Risk remains in the legacy estate | Low near term, but valid when the system has limited strategic value |
When retaining is the smart move
Retaining a system isn't avoidance if it's deliberate. It can be the right decision when a stable application has low innovation impact, low change tolerance, and no immediate role in your target data backbone.
Examples include:
- Archival repositories that are rarely queried and don't feed active R&D decisions
- Narrow utility tools that support one isolated device with minimal downstream dependency
- Highly customized workflows that would consume major migration effort without enabling reuse or AI
The key is to define conditions for deferral. Retained systems still need an owner, access controls, export rules, and a review date. Otherwise, "retain" becomes "ignore," and that's how technical debt steadily hardens.
What doesn't work is applying one strategy across the board because procurement or architecture wants consistency. Legacy system migration succeeds when you tailor treatment to value, risk, and scientific relevance. In materials R&D, uniformity is less important than preserving experimental continuity while building a usable data foundation.
Executing Data Migration to an AI-Ready Backbone
Migration either creates future advantage or just creates a new version of the same mess. Moving records into a modern platform isn't enough. If historical data arrives without consistent identifiers, controlled units, complete metadata, and traceable relationships, it won't support advanced analytics or machine learning in any meaningful way.
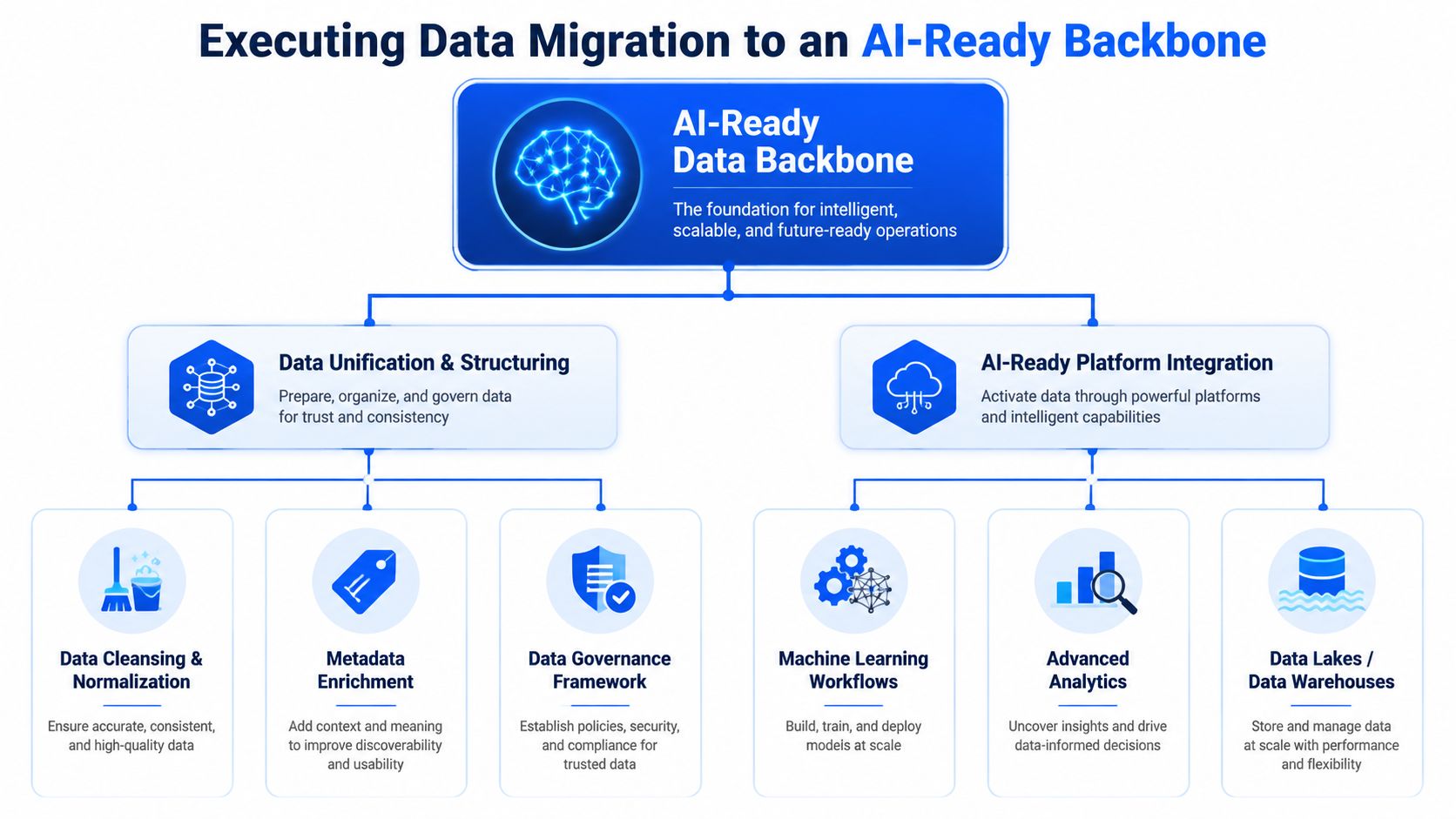
Treat extraction as a scientific data problem
Materials organizations usually have a mix of structured and unstructured sources. Structured records may come from databases, CSV exports, ERP-linked quality systems, or instrument software. Unstructured content shows up in PDFs, analyst notes, slide decks, scanned reports, and free-text observation fields.
You need an extraction approach that respects both. For teams dealing with document-heavy records, vendor reports, or text-based lab outputs, DigiParser's guide is a useful reference for thinking through data extraction workflows before loading anything into a central backbone.
The execution pattern is straightforward in principle and demanding in practice:
- Extract: Pull records from each source without losing provenance.
- Normalize: Standardize names, units, timestamps, identifiers, and material references.
- Enrich: Add missing metadata where rules or domain review can recover it.
- Link: Connect experiments to formulations, batches, methods, and outcomes.
- Load: Push into the target backbone with validation controls and auditability.
A common failure point is over-automating too early. If a source system has inconsistent naming or mixed semantics, forcing full automation before domain review often multiplies bad records at scale. Start with a controlled subset. Validate transformation rules with scientists who understand the underlying experimental logic.
A short explainer can help align technical and lab teams on the objective:
Create structure that models can actually use
AI-readiness comes from structure plus context. A model needs more than final property values. It needs enough lineage to understand what was tested, under which conditions, from which ingredients, prepared how, and compared against what baseline.
That means your target schema should preserve relationships such as:
- Material genealogy: Parent resin, additives, grades, supplier variants
- Formulation context: Composition, ratios, processing order, cure schedule
- Experiment conditions: Temperature, humidity, method, instrument, operator context where relevant
- Outcome linkage: Measured properties, pass-fail criteria, scale-up notes, deviations
If the migrated dataset can't support a scientist asking "what changed between these two runs," it isn't an AI-ready backbone yet.
For many teams, the right target isn't a single monolithic application. It's a governed backbone that can feed ELNs, analytics environments, search layers, and modeling workflows without recreating silos. That architecture matters because R&D data has to serve both daily execution and future learning.
The practical discipline here is boring but decisive. Version your mapping rules. Keep source provenance. Flag uncertain transformations instead of hiding them. Separate inferred values from observed values. Make unit conversions explicit. Preserve original raw data where feasible.
Legacy system migration becomes strategically valuable at this point. The organization is no longer just moving away from old tools. It's converting trapped experimental history into reusable intelligence.
Validating the New System and Managing the Human Element
A technically correct migration can still fail in the lab. Scientists will reject a new system if search results look incomplete, familiar workflows take longer, or instrument integrations become unreliable. Validation has to prove more than data presence. It has to prove operational trust.
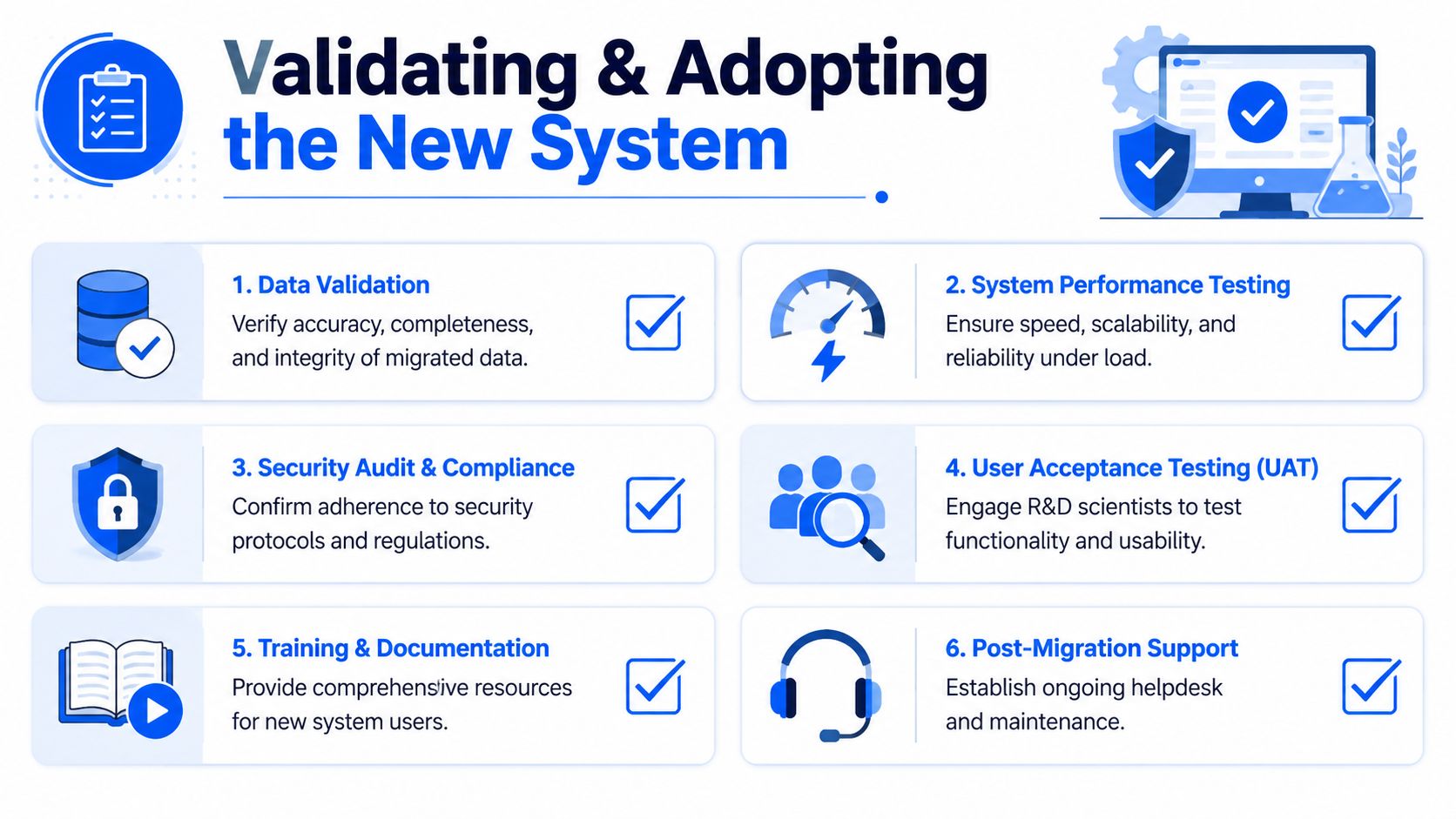
Validation has to reflect lab reality
One of the most common migration mistakes is replacing a system in one large cutover instead of using phased or parallel migration. Independent guidance recommends moving from lower-risk to higher-risk components, running old and new systems side by side where possible, and extending testing after migration because broad overhauls raise downtime and defect risk (Pacific Blue Engineering's migration guidance).
In R&D, side-by-side running isn't just a technical safety measure. It's a credibility tool. Scientists can compare outputs, verify searchability, and confirm that records behave as expected before the old environment is retired.
Use a validation checklist that reflects real work:
- Data integrity checks: Confirm that records are complete, linked correctly, and traceable back to source.
- Workflow verification: Test common lab tasks, approvals, and reporting routines with actual users.
- Integration testing: Confirm instrument feeds, analytics tools, and enterprise handoffs still work.
- Performance review: Check whether scientists can retrieve and compare data fast enough for daily use.
- Security and access controls: Validate that sensitive IP is visible only to the right users and teams.
Don't delegate user acceptance testing only to project champions. Include skeptical scientists, power users, and people who run edge-case workflows. They usually surface the defects that formal scripts miss.
Parallel run should end only when users trust the new record enough to stop checking the old one.
Adoption fails when support models lag behind
The practical risk after go-live is often an ongoing operating-model change involving new support processes, retraining, and parallel-system overhead, and recent guidance notes the use of phased migration and side-by-side operation to reduce that risk (ISOS Technology's migration article).
That matters because many migration teams underinvest in the post-launch model. They move the system, then assume adoption will follow. It won't. Scientists need clear support channels, updated SOPs, practical training, and named owners for data issues, access problems, and workflow changes.
A workable post-migration operating model usually includes:
- Tiered support ownership: Distinguish between lab operations issues, data stewardship issues, and platform issues.
- Scientist-focused training: Use task-based sessions, not generic platform demos.
- Rollback criteria: Define the conditions that trigger partial fallback before users encounter chaos.
- Issue triage cadence: Review defects and adoption friction quickly in the early stabilization period.
The human side isn't softer than the technical side. It's the part that determines whether the migrated environment becomes the system of record or just another system people work around.
Defining Success Beyond Go-Live
Go-live is an event. Success is a pattern. In materials R&D, you know the migration is working when scientists can find prior work faster, compare experiments with less manual effort, and reuse historical knowledge in current programs without rebuilding context from scratch.
Measure scientific throughput, not just system status
Traditional migration reporting focuses on completion metrics: records moved, systems retired, interfaces reconnected. Those are necessary, but they don't tell an R&D leader whether the investment is helping innovation move faster.
A better scorecard asks whether the new environment improves how research gets done. Useful measures are often qualitative at first, then become more structured over time:
- Experiment reuse: Are scientists finding and reusing historical work instead of repeating it?
- Searchability: Can teams locate prior formulations, test methods, and outcomes without manual digging?
- Handoff quality: Is knowledge moving more cleanly from discovery to scale-up, quality, and production support?
- Model readiness: Do data teams have enough structured, trustworthy history to support predictive workflows?
- Decision speed: Are technical reviews faster because evidence is easier to assemble?
These indicators matter more than abstract modernization language. They show whether legacy system migration is reducing friction in daily scientific work.
Prove that complexity is going down
A foundational shift in migration practice has been the move away from big-bang cutovers toward phased or trickle migrations, where data moves in small batches over weeks or months to lower risk and support continuous user acceptance testing (KME Systems' migration best practices). That historical change points to the right definition of success. You don't win by switching everything at once. You win by steadily reducing operational complexity while preserving continuity.
For R&D teams, that usually looks like this:
- Fewer shadow spreadsheets because the main system is trusted
- Fewer one-person dependencies because workflows are documented and governed
- Fewer disconnected records because formulation, test, and outcome data are linked
- More confidence using historical data for prioritization and AI-assisted experiment planning
If those conditions aren't improving, the migration may be technically complete but strategically unfinished.
Legacy system migration is worth doing when it creates an R&D backbone that people use. Not because the architecture diagram looks cleaner, but because scientists can move from trial-and-error toward targeted discovery with better data behind every next experiment.
If your materials R&D organization is trying to turn fragmented experimental history into a secure, AI-ready foundation, Polymerize is built for that challenge. It helps enterprises unify data across spreadsheets, ELNs, and silos, create a usable data backbone for research, and support faster discovery and scale-up with AI-native workflows.

