Your lab probably already has the data needed to make better formulation decisions. The problem is that it doesn't live in one place, and it doesn't follow one structure. A rheology result sits in instrument software. A formulation table lives in Excel. Thermal data is buried in PDFs. The scientist's reasoning is in a notebook or an ELN entry that nobody else can find six months later.
That's why many materials teams feel data-rich and insight-poor at the same time. They've digitized parts of the lab, but they haven't built a usable data backbone. When leaders talk about AI, predictive modeling, or faster scale-up, the conversation often stalls at the same point. The historical data isn't clean enough, connected enough, or standardized enough to trust.
A Laboratory Information Management System can fix that, but only if it's approached as more than a compliance tool. In exploratory materials R&D, the primary value of a LIMS isn't just traceability. It's turning fragmented experimental history into structured, reusable knowledge that scientists can build on.
Table of Contents
- Sample lineage matters more than sample count
- Instrument integration changes data quality
- Workflow control without slowing scientists down
The Modern R&D Lab Data Challenge
Materials R&D rarely fails because scientists lack ideas. It fails because teams can't reliably connect what they tried, what changed, and what happened next.
In a typical polymer or specialty chemicals lab, data is spread across spreadsheets, shared folders, instrument software, PDF reports, and handwritten notes. Each system captures a fragment of the experiment. None of them preserves the full chain from raw material lot to formulation variant to test condition to final property outcome. When a team wants to revisit an old program, compare sites, or train a model, they discover that the data is technically present but operationally unusable.
That fragmentation creates practical drag:
- Scientists re-run work: They can't find prior conditions with enough confidence to reuse them.
- Managers lose visibility: They see project status, but not experimental quality or comparability.
- Scale-up teams inherit ambiguity: The lab result exists, but the process context behind it doesn't.
- AI initiatives stall: Historical records aren't standardized enough to support reliable modeling.
A modern Laboratory Information Management System addresses that by creating a governed operating layer for the lab. It gives every sample, test, method, result, and approval state a durable system record. That sounds administrative, but in exploratory R&D it's strategic. Structured data is what lets a team connect composition to performance across time, instruments, and projects.
The urgency is easy to understand from the market itself. The global LIMS market is projected to grow from USD 1.8 billion in 2023 to USD 3.5 billion by 2030, at a 10.1% CAGR, reflecting broad adoption to manage complex R&D data and rising data integrity demands, according to Laboratory Information Management System market statistics.
Practical rule: If your scientists spend more time hunting for context than interpreting results, you don't have a science problem. You have a data architecture problem.
For materials leaders, the decision isn't whether to digitize. Most labs already have. The decision is whether to keep adding disconnected tools or put a system in place that makes experimental data reusable across discovery, characterization, and scale-up.
What Is a Laboratory Information Management System
A Laboratory Information Management System, or LIMS, is the operational system that manages how samples, tests, methods, results, approvals, and records move through the lab. The cleanest way to think about it is as the lab's central nervous system. It doesn't replace science. It coordinates the signals, records the actions, and preserves the context.
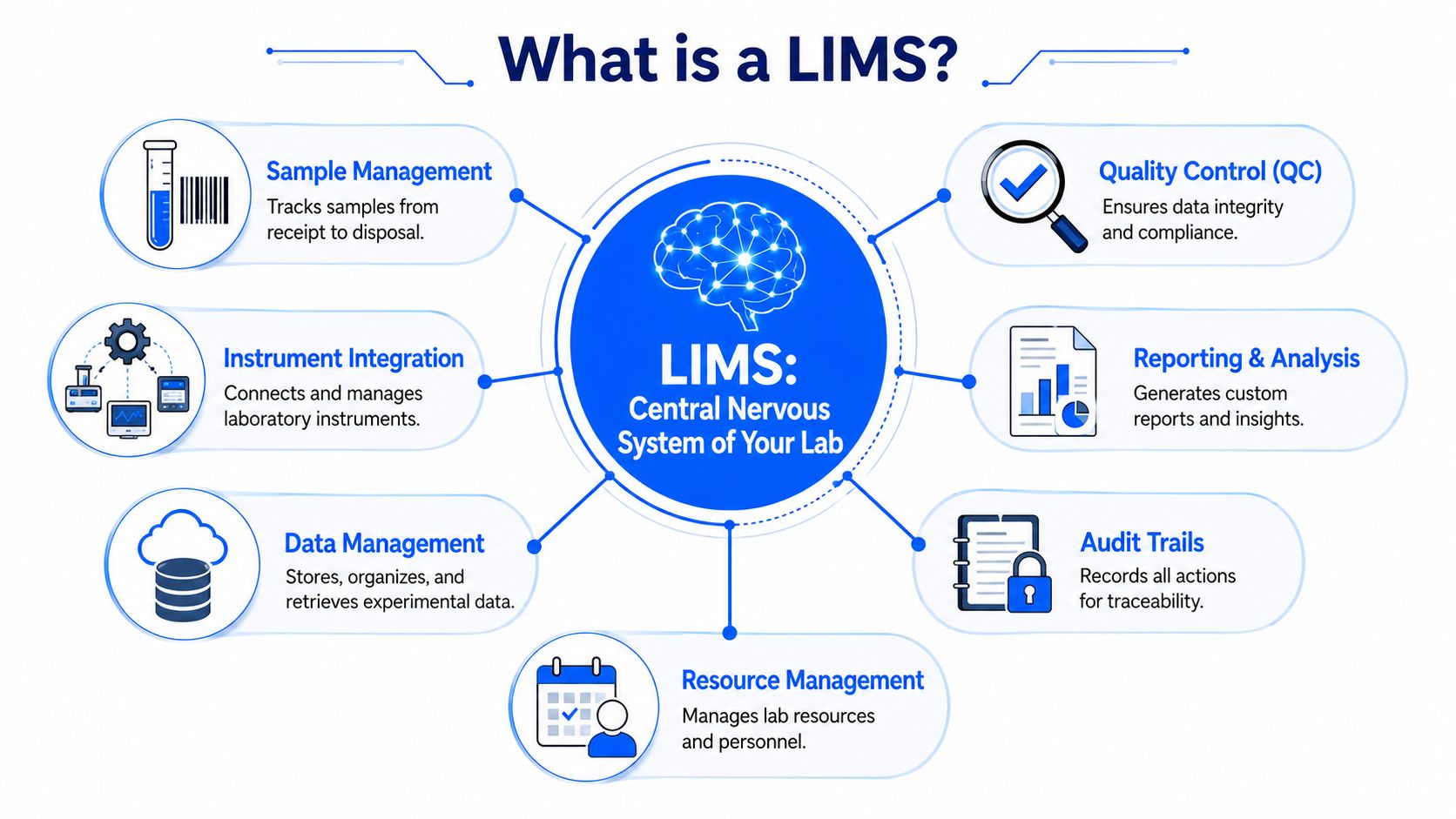
From sample tracker to lab backbone
LIMS didn't start as a broad innovation platform. It began as a way to track samples. Over time, those systems expanded into workflow, compliance, integration, and enterprise data management. The history of LIMS development traces that shift from basic sample-tracking tools in the 1980s to more extensive platforms by the 2000s, with regulations such as 21 CFR Part 11 pushing adoption of electronic records and signatures. Today, LIMS are central to full-traceability sample handling in industrial and research environments.
That history matters because many legacy deployments still reflect the old mindset. They're rigid, admin-heavy, and optimized for repetitive workflows. Materials R&D usually needs something broader. It needs traceability without forcing every experiment into a clinical-lab template.
For organizations planning wider digital modernization, it helps to see LIMS as one layer inside a broader operational stack. Teams evaluating connected platforms often compare lab workflows with larger business systems such as REDCHIP IT's enterprise system to understand where laboratory data should integrate with purchasing, quality, and enterprise reporting.
What a LIMS actually manages
A strong LIMS does more than store results. It manages the lifecycle of laboratory work in a structured way.
| Function | What it means in practice for materials labs |
|---|---|
| Sample registration | Assigning IDs to raw materials, blends, intermediates, and final specimens |
| Test orchestration | Routing samples into characterization, stability, mechanical, or analytical workflows |
| Metadata capture | Recording formulation variables, operator, instrument, method version, and batch context |
| Status control | Knowing what's queued, in progress, failed QC, approved, or archived |
| Auditability | Preserving who changed what, when, and under which method |
| Reporting | Generating internal summaries, certificates, and handoff packages |
The key distinction is that a LIMS structures operational data at the point of creation. That's why it becomes useful later for trend analysis, root-cause review, and model building. Without that structure, a lab may still be digital, but it won't be computationally ready.
A spreadsheet can hold a result. A LIMS can hold the result, the method, the sample lineage, the operator, the instrument state, and the approval history in one governed record.
Core LIMS Features and Benefits for Materials R&D
Most LIMS feature lists are too generic to help a materials organization choose well. Polymer and advanced materials teams don't just process samples. They manage formulation variants, unstable naming conventions, shared instruments, iterative test plans, and evolving methods. The useful question isn't whether a platform has sample management. It's whether it handles scientific variation without losing structure.

Sample lineage matters more than sample count
In materials R&D, one “sample” is often a chain of related entities. A resin lot becomes a pre-mix. The pre-mix becomes multiple formulation variants. Those variants become molded plaques, films, or test coupons. Each derivative can go through different conditioning and characterization paths.
A capable LIMS should model that lineage directly. If it can't, teams end up flattening rich experimental context into free text. That's where future reuse breaks down.
Look for capabilities such as:
- Parent-child sample relationships: Essential for linking raw materials, intermediates, and derived specimens.
- Formulation-aware records: The system should capture components, loadings, and process steps without forcing awkward workarounds.
- Versioned methods: Test methods change. The record should preserve which version produced which result.
When those elements are configured well, scientists can answer practical questions fast. Which additive package produced the best impact strength at a given processing window? Which lot-to-lot shifts correlate with rheology drift? Those answers depend on lineage, not just result storage.
Instrument integration changes data quality
Manual transcription is still one of the most expensive invisible problems in R&D labs. It consumes scientist time, introduces avoidable errors, and slows reporting. That's why instrument integration is usually one of the highest-value LIMS capabilities.
According to Illumina's overview of LIMS infrastructure and automation, instrument-integrated LIMS can reduce manual data transcription errors by 40 to 60 percent and cut reporting lead times by 30 to 50 percent. The same source notes that workflow automation can reduce non-productive lab time, including rework and manual coordination, by 20 to 35 percent.
For materials teams, this matters most around shared analytical assets such as DSC, GPC, rheometers, TGA systems, spectrometers, and mechanical testers. The gains don't come only from automatic file import. They come from attaching the right run to the right sample, under the right method, with the right metadata.
Field advice: Don't ask whether a LIMS “integrates with instruments.” Ask how it handles file parsing, run exceptions, method mapping, calibration status, and failed import review.
Workflow control without slowing scientists down
Workflow automation gets misunderstood. Scientists hear “workflow control” and expect bureaucracy. In a well-designed LIMS, the opposite is true. The system should remove repetitive coordination work while leaving room for exploratory judgment.
The highest-value workflow features usually include:
- Pre-analytical checklists: Useful for specimen prep, labeling, and method eligibility before instrument time is wasted.
- Conditional routing: A sample can move to additional tests only when an earlier result or QC flag requires it.
- Approval states: Teams can distinguish draft, reviewed, approved, and released results without emailing spreadsheets around.
- Exception handling: Scientists need a documented way to branch from the default path when discovery work demands it.
Reporting is the final piece. In weak implementations, reporting is an afterthought. In strong ones, reports are generated from the same structured records used to run the lab. That means internal dashboards, customer-facing summaries, and audit trails all pull from one system of record instead of competing copies.
LIMS vs ELN vs CDS vs MES Explained
Many labs buy tools in isolation and then wonder why the digital environment feels fragmented. The problem usually isn't the presence of multiple systems. It's the absence of clear system roles.
The lab informatics stack makes more sense when each application owns a specific type of work and data.
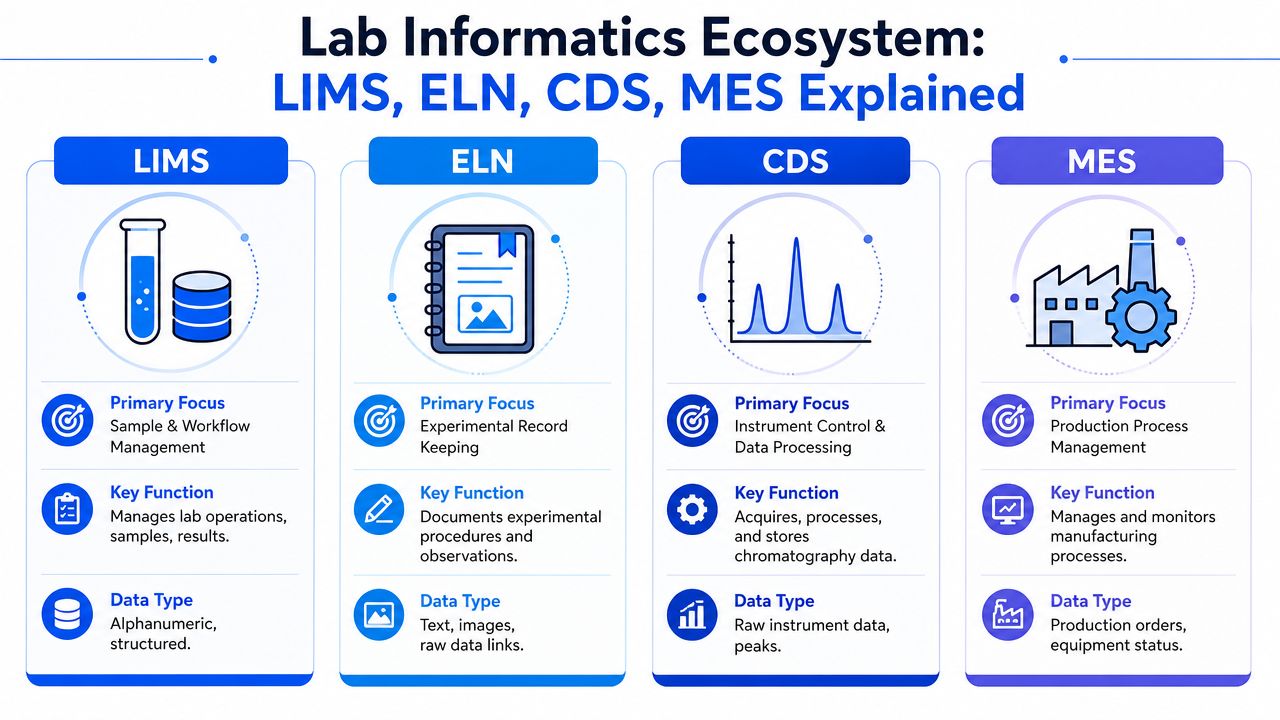
Where each system fits
| System | Primary role | Best at handling | Typical weakness if used alone |
|---|---|---|---|
| LIMS | Operational control of lab entities and workflows | Samples, tests, results, status, auditability | Doesn't capture rich scientific narrative well |
| ELN | Experimental recordkeeping | Hypotheses, procedures, observations, rationale, attachments | Often lacks structured operational control |
| CDS | Instrument-specific acquisition and processing | Chromatography runs, peaks, raw files, processing methods | Narrow scope outside its instrument domain |
| MES | Execution on the production floor | Batches, work orders, plant equipment steps, manufacturing traceability | Not designed for discovery-stage lab experimentation |
An ELN captures the “why” of the experiment. It records what the scientist intended, observed, and concluded. A LIMS captures the “what” and “how” in a controlled way. It records which sample moved through which workflow and which result is official.
A CDS is more specialized. It's the right home for instrument control and raw chromatography data processing, but it shouldn't be asked to run broader laboratory operations. MES sits further downstream. It governs production execution, not exploratory bench work.
Later in the evaluation process, many teams find it useful to hear a concise vendor-neutral explanation before comparing products. This short video does that well:
How they work together in practice
A practical materials workflow might look like this:
- The scientist plans the experiment in the ELN. Formulation intent, rationale, and observations are recorded there.
- The LIMS creates and tracks the formal entities. Raw material lots, blends, specimens, assigned tests, and release states are managed there.
- The CDS controls chromatography instruments where applicable. It captures and processes the raw run data.
- MES takes over at scale-up or manufacturing transfer. It executes the controlled production process.
The best digital labs don't force one platform to do everything. They connect systems so each one does its own job cleanly.
Where organizations struggle is integration semantics. If sample IDs don't match across platforms, or if method versions drift, the data pipeline becomes brittle. That's why system boundaries should be designed intentionally, not left to ad hoc exports.
Designing a LIMS for AI and Data-Driven Innovation
A legacy LIMS stores records. An AI-ready LIMS stores records with enough structure and context to support inference.
That distinction is where many materials data programs succeed or fail. Teams often assume that once they centralize historical results, they can start modeling. In practice, the model only sees what the data architecture preserves. If process conditions are missing, units are inconsistent, formulations are described differently by different scientists, or instrument context isn't attached, the resulting dataset looks large but behaves badly.
AI-ready means context-ready
In materials R&D, metadata is not administrative overhead. It is part of the experiment. Temperature profile, mixing order, residence time, catalyst loading, reagent lot, cure conditions, equipment identity, and operator actions can all influence downstream properties.
The consequence of weak metadata discipline is measurable. In materials R&D workflows, inconsistent or missing metadata can degrade machine learning model accuracy by 20 to 30 percent, and a well-architected LIMS that enforces validation at data entry can reduce manual data correction errors by 30 to 50 percent.
That's why the design question isn't “Can the LIMS store our data?” It's “Can the LIMS force the right context to exist when the data is created?”
For leaders thinking beyond the lab, there's a useful parallel in connected industrial systems. The same principles behind building connected product analytics apply here. Data only becomes analytically valuable when collection, structure, and context are engineered together.
What to design into the data model from day one
The best LIMS implementations for exploratory materials work usually share a few design characteristics.
- Flexible entity modeling: Formulations, blends, intermediates, and specimens should be first-class records, not hacked into generic sample fields.
- Controlled vocabularies: Teams need standard names for materials, methods, units, and outcomes. Free text should be the exception, not the default.
- Mandatory metadata at key stages: Require what the model will later need. Don't rely on scientists to remember every field after the fact.
- Validation at entry: Range checks, unit consistency, and schema constraints prevent low-quality records from entering the system.
- API accessibility: If the data can't move cleanly into analytics, modeling, and reporting environments, the LIMS becomes another silo.
A common mistake is over-designing the schema too early. Teams try to define every possible future experiment before they've stabilized current workflows. That usually leads to bloated configurations and weak adoption.
A better pattern is to standardize the repeatable backbone first. Start with the high-value experimental families that already drive portfolio decisions. Build the metadata model around those. Then extend carefully as new test types and formulation strategies emerge.
Decision test: If a scientist can't reconstruct the full experimental context from the system record alone, the LIMS isn't ready for AI no matter how modern the user interface looks.
Practical LIMS Use Cases for Polymer and Materials Teams
The strongest argument for a LIMS in materials R&D isn't theoretical. It shows up when the system supports real experimental work without forcing scientists into rigid templates.
That flexibility matters because materials teams don't operate like clinical labs. As discussed in the implementation literature on advanced materials laboratories, these groups often need more modular systems that can support non-standard and iterative workflows while still preserving traceability, as noted in this analysis of flexible LIMS needs in advanced materials settings.
Formulation screening and variant tracking
A formulation screening campaign can generate many closely related variants. The challenge isn't creating those records. It's preserving the differences that matter.
A well-configured LIMS can support this by:
- Registering each formulation as a structured object: Components, concentrations, order of addition, and processing notes stay linked.
- Creating derived test specimens automatically: Plaques, films, pellets, and conditioned samples inherit lineage from the parent formulation.
- Routing variants into planned test panels: Mechanical, thermal, barrier, optical, or rheological workflows can be attached by project or material class.
In weak systems, scientists export all of that into Excel because it's faster. In strong systems, the LIMS is just as easy to use for recurring work and much safer for long-term reuse.
Characterization and scale-up handoff
Characterization programs usually break when test data is technically complete but scientifically disconnected. A tensile result without specimen prep details is hard to interpret. A DSC curve without batch history is less useful than it looks.
A modern LIMS helps by keeping one auditable record of the sample's journey. The raw material lot, processing conditions, conditioning history, assigned methods, exceptions, and approved results remain attached to the same lineage chain. That makes cross-test interpretation much easier.
Scale-up is where this pays off most clearly. Process development teams don't just need the “best result.” They need the bounded process window that produced it. If the lab has captured those conditions in a structured way, the handoff into pilot work becomes more reliable. If not, scale-up starts with re-discovery.
Here's the trade-off leaders should acknowledge openly:
| Approach | What works | What fails |
|---|---|---|
| Rigid legacy LIMS | Strong control for repetitive QC flows | Poor fit for exploratory formulation work |
| Spreadsheet-heavy research | Fast for individual scientists in the moment | Weak reuse, weak governance, weak comparability |
| Flexible modern LIMS | Balances traceability with experimental variation | Requires thoughtful schema design and change management |
The goal isn't to make discovery feel like manufacturing. The goal is to give discovery work enough structure that the organization can learn from it repeatedly.
Implementation Checklist and Measuring ROI
Most LIMS projects don't fail because the software lacks features. They fail because the organization tries to digitize disorder without first deciding what should be standardized.
The hardest part is usually historical data. Materials labs often have years of spreadsheets, local file stores, instrument exports, and naming conventions that evolved by habit. According to Grand View Research's LIMS market analysis, migration complexity remains a major barrier in materials labs, especially when teams want to prepare legacy data for AI and predictive modeling rather than simple reporting.

A phased rollout works better than a big bang migration
The most reliable implementation pattern is phased. Don't attempt to normalize every historical record before go-live. Migrate the data that supports active decisions, and archive the rest with a clear retrieval strategy.
A practical rollout checklist looks like this:
Define the operating model
Decide what the LIMS will own. Samples, formulations, tests, approvals, and instrument result imports should have clear boundaries.Choose priority workflows
Start with a limited set of high-volume or high-value workflows such as formulation screening, incoming material characterization, or release testing.Create a data standard
Standardize names, units, material identifiers, method versions, and required metadata. The quality of future analytics hinges on this standardization.Map legacy sources
Identify which spreadsheets, instrument systems, and ELN records contain reusable data. Not every old file deserves migration.Design integrations early
Instrument imports, ELN links, reporting outputs, and enterprise connections should be planned before configuration is finalized.Train by role
Scientists, lab managers, QA, and informatics staff need different training. Generic system training usually produces weak adoption.Validate with live scenarios
Test actual workflows, exceptions, and review paths. A clean demo environment doesn't prove production readiness.
Start with the workflow that hurts the most and repeats the most. That's usually where adoption and ROI appear fastest.
How to measure value after go-live
LIMS ROI should be measured operationally, not just administratively. If the only success metric is “the system launched,” the program will underdeliver.
Good post-launch metrics usually include:
- Data quality indicators: Fewer incomplete records, fewer manual corrections, cleaner metadata.
- Lab execution indicators: Faster turnaround for common workflows, fewer handoff delays, fewer duplicate records.
- Scientific reuse indicators: More successful retrieval of prior experiments, stronger comparability across projects or sites.
- Governance indicators: Better auditability, controlled approvals, and clearer status visibility.
Security and compliance still matter, especially for enterprise R&D organizations handling sensitive formulations and partner data. Review role-based access, validation requirements, audit trails, and alignment with your organization's broader controls such as ISO 27001, SOC 2, GLP, or GMP expectations where relevant.
The best implementations don't treat LIMS as a standalone IT project. They treat it as the foundation of a long-term lab data strategy.
If your team is trying to modernize beyond static recordkeeping, Polymerize is worth evaluating as an AI-native platform for materials R&D. It helps enterprises unify fragmented experimental data across spreadsheets, ELNs, and lab silos into a centralized backbone, then apply explainable models to predict properties, optimize formulations, and guide the next experiment. For materials leaders who want cleaner data, fewer failed iterations, and faster scale-up, that's a more direct path from laboratory information management to innovation performance.

