Your team just hit on a promising formulation. The tensile data looks real. The processing window is better than the last three candidates. Someone has already asked whether this is patentable.
Then the questions get uncomfortable.
The raw data lives in instrument exports, three spreadsheet versions, and one scientist's local folder. The formulation history sits partly in an ELN, partly in email, and partly inside an AI discovery workspace where prompts and generated suggestions aren't being archived in a defensible way. A contractor in another country contributed to the optimization run. Nobody has aligned on whether the resulting process conditions belong in a patent filing, a trade secret program, or both.
That is where many materials companies are right now. The technical breakthrough happens first. The ownership trail, filing strategy, and security controls lag behind. If you want a practical answer to how to protect intellectual property in modern R&D, you need more than legal definitions. You need a working system that survives real lab conditions, fast iteration, shared datasets, external partners, and AI-assisted discovery.
Table of Contents
- Where materials teams get exposed
- Why the old model breaks in modern R&D
- What a strong program does differently
- Centralize the record, then restrict the path
- The minimum control stack for R&D IP
- AI discovery workflows need their own guardrails
- Build controls that match the pace of research
- Ownership language has to exist before the dispute
- Policies matter when AI vendors and contractors touch your work
- Build the chain of custody while science is happening
- What a workable invention workflow looks like
- Where programs usually break
- Make the workflow support the scientist
The Modern R&D Intellectual Property Risk
A polymer team hits a promising result on Tuesday. By Friday, the key evidence sits in five places: instrument data on a local PC, formulation notes in an ELN, a supplier email with processing guidance, a model output from an AI screening tool, and a spreadsheet a scientist saved to a personal drive before boarding a flight. The science may be sound. The IP position is already unstable.
That instability usually starts with ordinary R&D behavior, not misconduct. Scientists work fast, tools do not share context well, and global teams pass data across legal entities, vendors, and time zones. In materials companies, the highest-value know-how often lives in the gaps between formal records: the rejected batch that defined the process window, the mixing order that fixed dispersion, the prompt sequence that narrowed a candidate set, or the scale-up adjustment that made the formulation manufacturable.
The risk shows up long before anyone files a patent or threatens litigation. If the company cannot reconstruct who contributed what, when they contributed it, where the supporting evidence lives, and what contractual terms governed the work, leadership cannot make sound decisions about filing, secrecy, publication, partnering, or product launch.
For a CTO, this is not a narrow legal issue. It is an R&D operating issue with direct effects on valuation, deal terms, and speed to market.
Where materials teams get exposed
Materials R&D carries a specific set of exposure points because the protected asset is rarely a single, clean invention. Value may sit in the composition, the process conditions, the precursor purity, the testing protocol, the model training data, or the judgment used to select one route over ten plausible alternatives.
Common failure points include:
- Fragmented invention records. Experimental history gets split across notebooks, ELNs, LIMS, shared drives, instrument software, email, and AI platforms.
- Unclear contribution boundaries. Scientists, data teams, process engineers, external labs, and suppliers all shape the outcome, which makes inventorship and ownership harder to sort out later.
- Premature disclosure. Conference abstracts, customer samples, joint development updates, and vendor troubleshooting can expose technical details before legal review happens.
- Trade secret erosion. Teams often protect the headline formula but leave manufacturing tolerances, parameter ranges, and scale-up heuristics exposed to broader audiences than necessary.
- AI workflow opacity. If model inputs, outputs, ranking logic, and human decision points are not captured, the company may struggle to prove the origin and significance of the inventive step.
- Cross-border collaboration drift. Data moves faster than approvals, while local employment rules, invention assignment rules, and export restrictions still apply.
One rule has held up well in practice. If the team cannot rebuild the timeline of a material innovation within a day, the IP program has a documentation problem that will surface at the worst possible time.
Why the old model breaks in modern R&D
Many companies still treat IP protection as a late-stage legal event. That model was always imperfect. It breaks faster in digital materials R&D.
AI discovery platforms generate candidate spaces quickly, but speed creates a recordkeeping burden. Global project teams improve technical depth, but they also increase the number of people, systems, and jurisdictions touching the work. External computation vendors, pilot plants, and specialist labs extend capability, yet each handoff creates another ownership and confidentiality checkpoint.
The trade-off is real. Tight controls that interrupt bench work will get bypassed. Loose controls that rely on personal discipline will fail. The right design principle is simple: build protection into the systems scientists already use, so evidence, access control, and approval points happen inside the workflow rather than after the fact.
What a strong program does differently
The companies that handle this well do three things consistently.
First, they define the asset before they argue about the legal label. In materials science, that prevents teams from over-focusing on the obvious invention and missing the surrounding know-how that may be better held confidential.
Second, they treat digital traceability as part of IP protection. Access logs, version history, instrument metadata, prompt records, and approval trails matter because they help establish authorship, inventorship, chain of custody, and scope of disclosure.
Third, they make IP decisions at the pace of R&D. That means legal, technical, and operational controls are set up to support fast experiments, external collaboration, and AI-assisted discovery without losing ownership or evidentiary quality.
That is the standard to aim for.
Mapping IP Types to Your R&D Assets
A materials R&D portfolio rarely fits into one legal box. The same program can produce a patentable composition, copyrightable simulation code, trade secret process windows, and a future product name in a single quarter. Teams lose protection when they label everything as “the invention” and move on.
Start by mapping what the lab, pilot line, and data stack are generating.
Start with asset classes, not legal labels
The four core categories are familiar. Patents cover inventions, trademarks cover source identifiers, copyrights cover original expression, and trade secrets cover confidential know-how. The mistake is assuming those categories apply cleanly at the project level. In materials science, they usually apply at the asset level.
Here is the working map I use with technical teams:
| IP Type | What It Protects | Example in Polymer R&D | Key Consideration |
|---|---|---|---|
| Patent | New inventions | Novel polymer composition, catalyst system, curing method, barrier coating process | You must disclose enough to support the claim, and public disclosure before filing can create risk |
| Trade secret | Confidential know-how | Unpatented formulation ranges, mixing sequence, process settings, scale-up heuristics, source code | Protection depends on maintaining secrecy through documented controls |
| Copyright | Original fixed expression | Technical manuals, reports, software code, training materials, product documentation | It protects expression, not the underlying scientific fact or raw data itself |
| Trademark | Source identifiers | Product family names, platform names, logos, branded material lines | It helps protect market identity, not the formulation science |
The table is simple. The decisions are not.
A new membrane material, for example, may justify a patent filing on structure or use. The process recipe that keeps defect rates low at scale may be better held as a trade secret. The machine-learning workflow used to screen candidates may include copyrightable code, confidential training choices, and invention disclosures tied to specific outputs. If your AI platform, ELN, and modeling environment do not separate those assets clearly, ownership and protection choices get blurred fast.
Choose based on disclosure, lifespan, and detectability
I advise CTOs to test each asset against three practical questions.
First, can a competitor figure it out from the commercial product, a conference slide, a regulatory submission, shared model output, or routine analytical work? If the answer is yes, secrecy may not hold for long. Patent review should happen early.
Second, what happens when you disclose it? Patent rights require disclosure. Trade secret rights depend on confidentiality. In materials businesses, that trade-off often turns on where the value sits. A formulation that can be reverse-engineered from the finished product points one way. A process adjustment that only lives inside your manufacturing line points another.
Third, will your operating model support enforcement? A patent is harder to defend if inventorship records are weak, contributors across sites are poorly documented, or AI-assisted ideation is not traceable. A trade secret is harder to defend if the same file sits in shared folders, vendor email threads, and external model workspaces.
Axiom's guidance is useful on the trade secret side. Owners need to take reasonable steps to preserve confidentiality, including controls such as password protection, access monitoring, and employee training. See the Axiom overview of intellectual property law and trade secret protection.
A trade secret is only a trade secret if you can show the company treated it like one.
That standard matters in materials R&D because the highest-value know-how is often procedural and cumulative. It lives in parameter ranges, purification decisions, supplier adjustments, failed-trial interpretations, prompt libraries for discovery models, and scale-up judgment that never appears in a patent claim. If those assets are going to stay confidential, teams need proof that access was limited, sharing was intentional, and records were controlled across geographies and systems.
A defensible classification model usually works best at the project level, with asset-specific decisions underneath it:
- Patent track for inventions that need filing review before papers, customer samples, conference abstracts, or vendor discussions.
- Trade secret track for know-how that stays internal and receives restricted access, confidentiality markings, and approval rules for any external transfer.
- Copyright track for code, manuals, protocols, reports, model documentation, and training content where authorship and reuse rights must be clear.
- Trademark track for product names, platform branding, and market-facing identifiers coordinated with commercial teams.
For a materials company using AI discovery tools and global collaborators, this mapping exercise is not clerical work. It determines which assets enter disclosure review, which stay compartmentalized, which need assignment language from external contributors, and which require digital evidence trails from day one.
If you want to protect intellectual property effectively, start by naming the asset with precision, then assign the legal tool that fits how that asset is created, shared, and defended.
Building Your Digital Fortress with Technical Controls
A formulation scientist in Germany exports a dataset to compare model outputs at home. A U.S. colleague drops screening results into a shared drive so an external partner can comment before the next call. An AI tool keeps the prompt history, including the exact property targets and surrogate variables your team considers commercially valuable. No one intended to leak IP. The systems allowed it.
That is the core technical problem in materials R&D. Valuable know-how moves faster than legal review, and modern discovery work spreads it across ELNs, cloud storage, instrument software, modeling environments, chat tools, and AI platforms. If those systems are loosely connected, your IP program becomes an after-the-fact reconstruction exercise.
Centralize the record, then restrict the path
For most companies, the first gain comes from reducing fragmentation. Experimental history, raw data, analysis scripts, model outputs, and decision records should sit inside a governed environment with stable identity, version control, and audit history. I would not aim for one monolithic system at all costs. That can slow teams down and drive them back to side channels. The better target is a controlled system of record with clear integrations to the tools scientists already use.
The screenshot above shows the kind of setup that helps. Experimental context, data lineage, contributor history, and access boundaries exist inside the workspace instead of being rebuilt from emails and local files during a dispute.
A good technical environment does two things at once. It makes legitimate research work easier, and it makes uncontrolled copying, exporting, and resharing harder.
The minimum control stack for R&D IP
The control stack does not need to be exotic. It needs to be enforced consistently across lab, data, and AI workflows.
- Role-based access. Set permissions by program, function, geography, partner status, and sensitivity. A battery team does not need open access to every catalyst dataset, and a regional commercial lead does not need raw experiment files.
- Least-privilege permissions. Separate view, edit, export, and admin rights. Export rights deserve special scrutiny because many trade secret losses happen through ordinary file movement, not intrusion.
- Encryption in transit and at rest. Protect data moving from instruments to storage, from storage to analysis tools, and from internal systems to approved external collaborators.
- Multi-factor authentication. Password-only access is weak protection for proprietary formulations, model training data, and scale-up records.
- Audit logs with timestamps and user identity. Logs should show who accessed what, what changed, what was downloaded, and what was shared externally.
- Fast deprovisioning. Remove access immediately when employees, interns, contractors, or vendors leave a project or the company.
- Controlled external sharing. Use expiring links, watermarking, download restrictions, and recipient authentication for data sent outside the company.
- Device and endpoint controls. Local sync folders, unmanaged laptops, and personal USB devices create avoidable exposure if your scientists handle sensitive process data.
Teams often underinvest in the last two controls because they feel operational rather than strategic. In practice, they decide whether a trade secret program holds up under pressure.
AI discovery workflows need their own guardrails
Materials teams using AI platforms face a different exposure pattern than teams working only in a traditional ELN. The sensitive asset is often not just the final model output. It is the problem framing, the prompt sequence, the feature selection logic, the negative results, and the private datasets used to steer the model toward a viable formulation or process window.
That changes the control design.
Use approved AI environments for confidential work. Log prompts, inputs, outputs, user identity, and retention status. Set rules for which datasets can be uploaded, whether model providers may retain inputs, and whether generated content can be reused in publications, customer decks, or partner updates without review. For cross-border teams, check where prompt logs and uploaded files are stored. A platform that is acceptable for generic productivity use may be a poor fit for proprietary research if data residency and retention terms are vague.
I have seen CTOs focus on model accuracy first and governance later. In IP terms, that sequence is backwards. If your team cannot show where an AI-assisted insight came from, who had access to the inputs, and whether the provider retained the material, ownership and secrecy become harder to defend.
Build controls that match the pace of research
Security fails in R&D when controls are technically correct but operationally clumsy. Scientists will work around systems that add delay to instrument uploads, block legitimate collaboration, or require manual approvals for routine internal tasks. The answer is not weaker protection. It is better workflow design.
Use default project templates with pre-set access groups. Tie classification labels to folders, experiments, and reports automatically. Route external sharing through approved channels. Pair that with simple researcher guidance, including an NDA explained without legal jargon resource for staff who need to know when confidentiality terms matter before data leaves the company.
Technical controls protect IP best when they are embedded in the research process itself. In a materials company running AI-assisted discovery across global teams, the goal is clear. Keep the full chain of custody for ideas, data, model interaction, and external transfer, without slowing the science to a crawl.
Securing The Human Element with Contracts and Policies
Some of the worst IP failures happen in companies with decent security and strong science. The missing piece is paperwork. A contractor helps optimize a resin system. A postdoc from a university partner contributes a key idea during a joint call. An employee builds a useful script at home and later claims it wasn't part of assigned work. Suddenly the question isn't whether the innovation is valuable. It's whether your company owns it.
Ownership language has to exist before the dispute
Practitioner guidance from Yousign notes that a large share of IP disputes are caused by missing or weak ownership paperwork, not weak underlying rights, and highlights clear employee and contractor invention-assignment agreements as a high-yield way to reduce risk. That point is captured well in this practical guide to protecting intellectual property and enforcing rights.
For R&D leaders, the lesson is direct. Don't treat invention assignment as HR boilerplate. It is core infrastructure.
A workable employee agreement should clearly address:
- What is assigned. Inventions, improvements, code, documentation, data compilations, and related work product created within the scope of employment.
- When assignment applies. During employment, using company resources, within defined research areas, or connected to assigned responsibilities.
- Disclosure obligation. Employees should be required to disclose potentially protectable inventions promptly.
- Confidentiality duties. The agreement should survive departure where legally appropriate.
- Record return and access termination. Notes, samples, files, and credentials shouldn't drift into personal possession.
If your team struggles to explain NDAs to scientists, procurement, or external collaborators, this plain-English guide on NDA explained without legal jargon is a useful resource to circulate internally before projects start.
Policies matter when AI vendors and contractors touch your work
The contractor version of this problem is usually worse because assumptions vary. Teams often believe the purchase order or statement of work already covers IP ownership. Sometimes it does. Sometimes it only covers deliverables. Sometimes it says nothing useful about background tools, reusable methods, model outputs, or derivative know-how.
That gap matters in materials R&D because collaborators often bring pre-existing methods and data into the project.
Use separate clauses for:
- Background IP. What each party owned before the engagement.
- Foreground IP. What is created during the work.
- Future inventions and improvements. What happens if the work leads to follow-on innovations after the project ends.
- Use of third-party AI and cloud tools. Whether project data may be uploaded, processed, retained, or used to improve external systems.
- Publication and disclosure controls. Who approves papers, conference talks, customer presentations, and shared technical summaries.
A short cautionary pattern appears again and again. The team assumes technical controls will protect them. They forget that a collaborator with unclear assignment language can become the cleanest route for ownership disputes.
If an outside party can touch your data, code, formulations, or model outputs, the contract needs to say who owns the result before the work begins.
Training matters too. Scientists don't need a law lecture. They need practical triggers: when to stop sharing, when to escalate a disclosure, what can't go into public slides, and which tools are approved for sensitive work.
Operationalizing IP Protection in Daily R&D Workflows
Monday morning, a formulation scientist in Boston adjusts a polymer blend based on an AI-generated recommendation. By afternoon, a process engineer in Singapore has reused the result in a scale-up trial, and a business development lead has asked for slides for a partner call. If the team cannot show who created what, which system generated which output, what remained confidential, and when review was triggered, the IP problem started before anyone noticed it.
Daily workflow is where IP protection either holds or fails. For a materials company, that means building evidence at the same speed as experimentation, model iteration, and cross-site collaboration.
Build the chain of custody while science is happening
Start with the operating principle. Every formulation change, model-assisted hypothesis, test result, exception, and decision needs a traceable record in the systems scientists already use. The goal is not more paperwork. The goal is admissible history.
For CTOs, the practical question is simple. Can you reconstruct an invention story from raw idea through validation without relying on memory, inbox searches, or local files? If the answer is no, ownership and inventorship become harder to defend, especially when AI platforms, external labs, and regional teams all touch the same program.
The lab-level requirement is clear. Each record should tie together the contributor, date, project, confidentiality status, related datasets, and any machine-generated input that influenced the work.
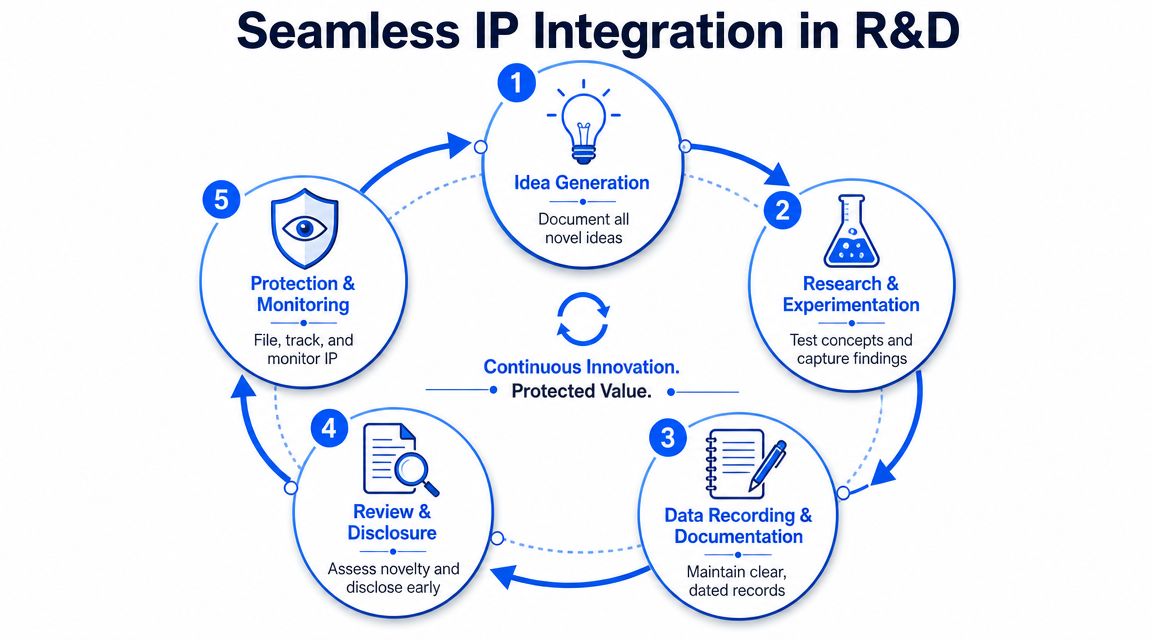
That creates chain of custody in a form legal can use and R&D can live with. It also reduces a common failure in materials programs. Discovery records sit in one platform, pilot data in another, and AI outputs in a third, with no clean thread connecting them.
What a workable invention workflow looks like
A workable invention workflow should be fast enough for bench scientists and specific enough for counsel. In practice, I want five actions built into the normal research cycle.
Capture work at creation
Record formulation details, precursor sources, process parameters, instrument files, observations, and attachments in a governed system. Free-text notes still have value, but they should sit beside structured metadata that can be searched and audited.Label sensitivity at the record level
Mark records as public, internal, confidential, or legal review required. In global teams, this matters because the same dataset may be acceptable for internal model training but not for a customer update, conference abstract, or external cloud workspace.Preserve version history across experiments and models
Materials development is iterative. Compositions drift, process windows tighten, and model recommendations change after each new result. Your system needs to show what changed, who changed it, and which prior version informed the next experiment.Trigger disclosure review based on defined thresholds
Set concrete triggers such as a new performance threshold, a novel synthesis route, a manufacturability breakthrough, or a result that is likely to appear in an external presentation. Scientists should not have to guess when something becomes review-worthy.Hold confidentiality until a filing decision is made
The highest-risk period is often the few weeks after a promising result appears. Teams want feedback, partner input, and management visibility. Without controlled sharing, they also create unnecessary disclosure risk.
Where programs usually break
The failure points are operational, not theoretical.
Scientists keep shadow spreadsheets because the official ELN takes too many clicks. A principal investigator stores screenshots of AI outputs without the prompt history or model version. A scale-up team copies a process setting into a manufacturing memo with no link back to the original discovery record. A regional team presents data externally because the deck looked internal.
Those are ordinary workflow problems. They become IP problems when the company later needs to prove inventorship, priority, confidentiality handling, or the human contribution behind an AI-assisted result.
Materials companies face an added complication. Valuable know-how often lives in process tuning, failed runs, purification choices, and stability observations that never make it into a patent draft. If daily workflow does not preserve that operational knowledge with access controls and authorship records, the company loses trade secret value even while believing the science is documented.
Make the workflow support the scientist
Adoption depends on friction. If the protected path is slower than the unofficial one, researchers will route around it.
Use design choices that fit real lab behavior:
- Invention capture templates with fields for composition, processing steps, supporting data, and commercial relevance
- Automatic timestamps, audit logs, and versioning instead of manual file naming conventions
- Linked records across experiments, datasets, model runs, and scale-up batches
- Prompt and output retention for approved AI tools so teams can show the human role in evaluation and refinement
- Review triggers built into project systems rather than relying on email reminders
- Access controls tied to project role and geography so collaboration can continue without exposing everything to everyone
The standard is straightforward. Good IP workflow should feel like good R&D operations. Clean records improve reproducibility. Controlled access reduces accidental disclosure. Clear escalation paths let legal review the right work at the right time, without slowing every experiment.
Navigating Modern IP Frontiers in AI and Global R&D
A materials program can lose control of its IP long before anyone files a patent. A model trained in one jurisdiction proposes a promising composition. A team in another country refines the process window. A pilot partner generates scale-up data under its own template and storage rules. Six months later, the science looks strong, but ownership, inventorship, and disclosure history are blurred.
That is the modern IP problem for R&D leaders. The hard part is no longer just filing strategy. It is proving what entered the collaboration, what was created inside it, who contributed to each step, and whether sensitive know-how stayed protected while the work moved across tools, borders, and organizations.
A useful visual for the problem space:
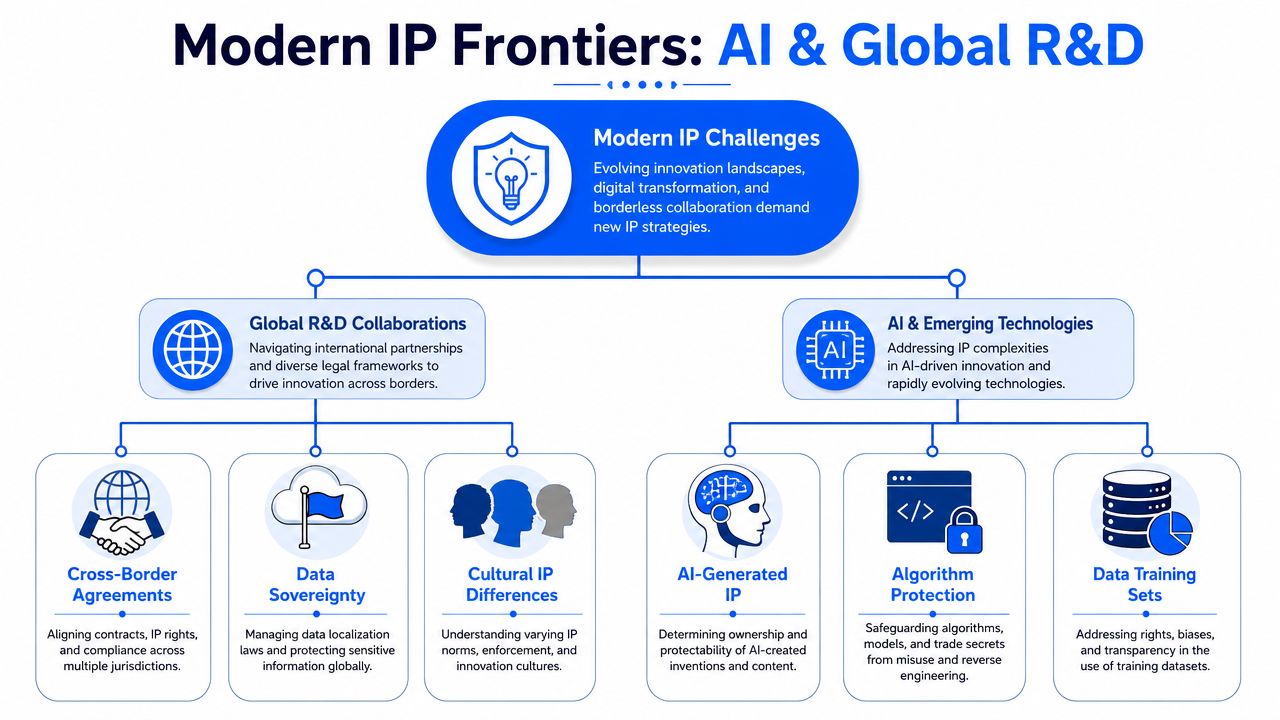
Cross-border collaboration changes ownership risk
Collaborative materials R&D creates value at the interfaces. It also creates avoidable ownership disputes if the parties do not define those interfaces with precision. NIH guidance on collaborative research highlights the need to sort out background IP, foreground IP, and future inventions at the start, and it explains why joint ownership can become difficult across jurisdictions. That practical issue is outlined in this NIH article on intellectual property and collaborative research.
For a materials company, these categories need operational definitions, not just legal labels.
- Background IP includes the assets each party brings in. Pre-existing formulations, precursor selection logic, process recipes, simulation methods, training datasets, and test protocols belong here.
- Foreground IP covers what the collaboration produces during the stated scope of work.
- Future inventions covers what emerges later from the same technical line, which is often where the highest-margin process refinements and manufacturing know-how appear.
I have seen teams negotiate ownership language carefully and still lose position because the evidence trail failed. Raw data sat in one system, model outputs in another, and key decisions lived in chat threads or slide decks. When a program succeeds, everyone remembers contributing. When a dispute starts, memory is useless.
Set rules that can survive diligence, litigation, and partner turnover:
- Define background, foreground, and improvement rights in the agreement
- Tag experiments and datasets by legal entity, site, and governing project
- Record named contributors for data generation, interpretation, and technical decisions
- Restrict cross-border copying of controlled files and model assets
- Set publication review rights before work starts with universities, consortia, or pilot partners
- Audit where collaborative records are stored, not just what the contract says
This short video is a useful complement if your team needs a quick overview mindset before diving into policy language.
AI-assisted invention needs a new evidence model
AI discovery tools change the IP record, not just the pace of discovery. In materials R&D, a model may rank candidates, suggest structures, optimize processing windows, or surface correlations a scientist would not test first. That creates a legal and operational question. What part of the eventual invention came from human conception, and what part was machine-generated analysis inside a tool with its own terms, retention rules, and confidentiality risk?
A CTO needs a defensible answer before the first breakthrough, not after it.
The strongest programs treat AI systems as part of the invention chain and part of the exposure surface. That means documenting who framed the problem, selected constraints, curated inputs, rejected weak outputs, designed validation experiments, and interpreted the results in a way that produced a patentable or protectable advance. It also means deciding which tools may receive proprietary formulations, process variables, microscopy data, or customer-linked requirements.
The practical review questions are straightforward:
- Who defined the research objective and success criteria?
- Who selected or approved the training data, candidate space, or search constraints?
- Who evaluated model outputs and chose which paths to test?
- Who designed the confirming experiments and interpreted conflicting data?
- Which records distinguish model suggestions from validated technical insight?
- Did prompts, uploads, or outputs expose confidential know-how to a vendor environment or a shared model?
The invention record has to show more than what the model suggested. It has to show what the human team invented.
That is why AI governance belongs inside your online IP protection program, not in a separate IT policy. If legal, R&D, and data teams do not agree on approved tools, retention rules, access boundaries, and auditability, the company can lose trade secret protection while believing it is accelerating innovation.
Use a record structure built for AI-assisted science:
- Separate model-generated hypotheses from experimentally validated inventions
- Preserve prompt, input, output, and version history for high-value programs
- Document human judgment in candidate selection, constraint setting, and interpretation
- Review vendor terms for ownership, training use, retention, and confidentiality
- Limit filing-sensitive work to approved environments with auditable controls
- Escalate unusual inventorship questions early, especially when AI outputs materially shape the research path
Global teams and AI platforms can produce excellent science. They also raise the standard for proof. Every material transfer, dataset handoff, model run, and partner contribution should map to an owner, a permission boundary, and a reliable record.
Your IP Protection Implementation Checklist
A materials R&D company usually does not lose IP in one dramatic event. It loses it in ordinary work. A formulation deck gets shared before legal review. A contractor uploads test data into the wrong workspace. A promising AI-assisted result never gets documented well enough to support inventorship, ownership, or trade secret status later.
That is why the checklist has to be operational. It should tell a CTO, an R&D leader, and IP counsel what controls to put in place now, what to formalize next, and what to integrate into the digital research stack over time.
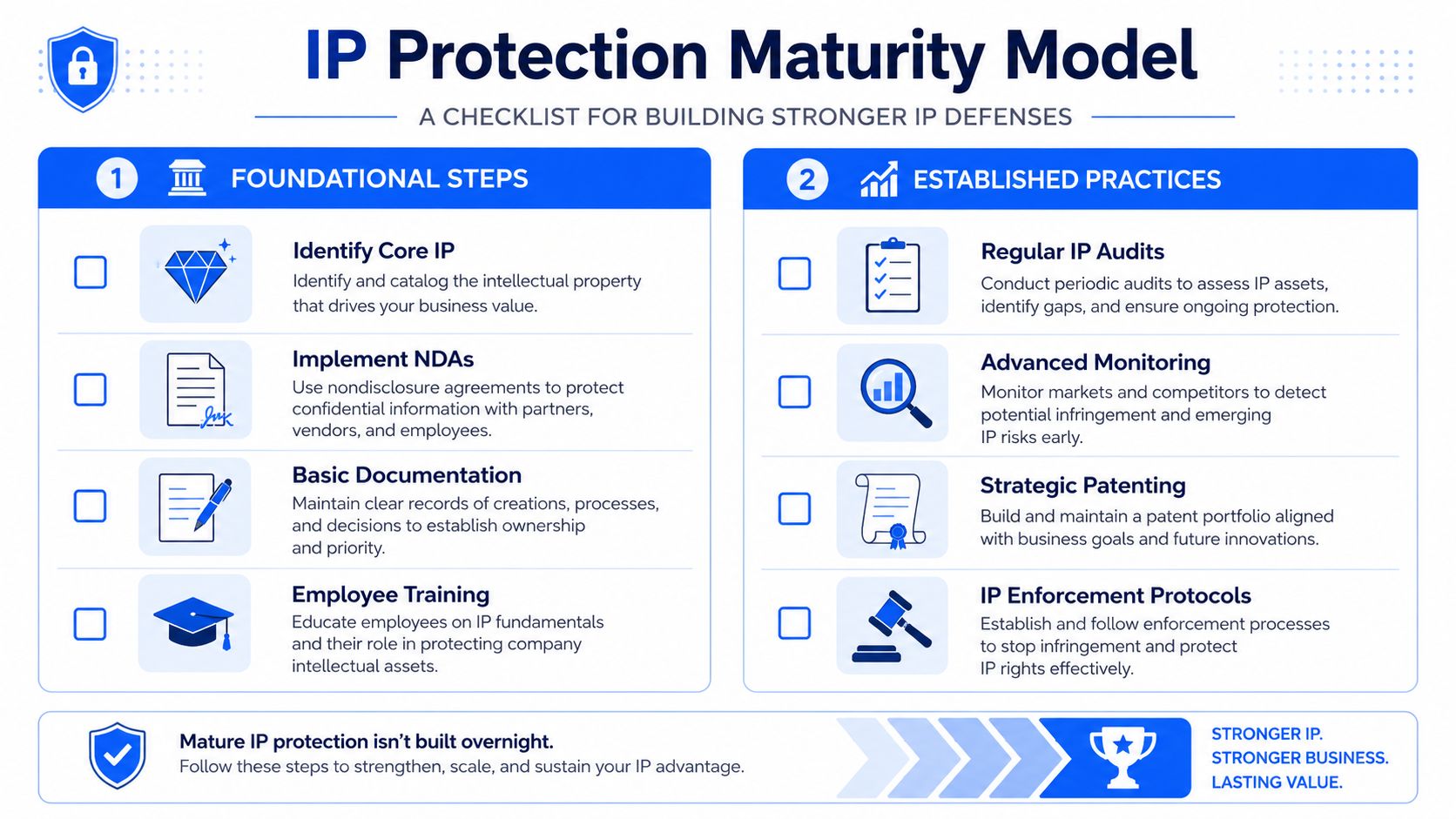
Foundational
At this stage, the goal is control over the obvious failure points. Teams need basic discipline around what counts as protectable IP, who can access it, and when a result must be reviewed before it leaves the company.
- Identify core IP assets across formulations, process parameters, lab methods, simulation code, technical reports, brand assets, and confidential know-how.
- Use NDAs consistently with employees, contractors, pilot partners, suppliers, and external evaluators.
- Set baseline access controls with strong passwords, MFA, role-based permissions, and shared-drive cleanup.
- Train scientists on disclosure triggers so conference abstracts, customer updates, preprints, and partner discussions do not create avoidable loss of rights.
- Define approved AI use for sensitive R&D work, including which tools are permitted and what data cannot be entered.
Established
Here, the company starts treating IP protection as a repeatable system instead of a set of legal documents. The priority is traceability. If a valuable invention emerges from a multi-site project, the team should be able to show who contributed, what changed, when decisions were made, and what was kept confidential.
- Run formal IP audits and classify assets by patent, trade secret, copyright, or trademark path.
- Centralize records so experiments, data files, versions, contributors, approvals, and supporting attachments are traceable.
- Use invention-assignment agreements across employees and contractors.
- Create an internal disclosure workflow with technical review, legal review, and filing or secrecy decisions tied to project milestones.
- Monitor online and market misuse with a documented escalation path. If your team also handles public-facing misuse, this guide to online IP protection is a practical reference for response options.
Optimized
An optimized program is built into the way R&D runs. Security controls, lab records, AI workflows, and collaboration systems support the IP strategy instead of forcing scientists to maintain parallel processes.
- Integrate security and R&D systems so access logs, project permissions, document history, and experiment records support one defensible record.
- Track AI contribution boundaries by preserving prompts, outputs, model versions, and human validation steps for high-value programs.
- Define cross-border ownership models before joint work begins, especially for shared datasets, co-development work, and inventor contributions across jurisdictions.
- Preserve evidence continuously through metadata, version histories, screenshots, signed assignments, and retention rules aligned to filing and enforcement needs.
- Review the program regularly because new tools, vendors, data flows, and collaboration models create fresh IP exposure.
One pattern shows up repeatedly in materials science. The strongest IP programs are not always the most restrictive. They are the ones that let teams move fast inside clear boundaries. Scientists know which systems to use, legal gets usable records instead of reconstruction projects, and leadership can decide early whether a result belongs in a patent filing, a trade secret file, or a partner negotiation.
If you are building for AI-enabled discovery and global collaboration, use this checklist as a workflow design tool, not just a compliance list. The true test is simple. Can your company prove ownership, protect secrecy, and reconstruct invention history without slowing down the next experiment?
If you're building a serious IP protection program for materials R&D, the biggest win often comes from fixing the underlying data and workflow problem. Polymerize gives teams a secure, AI-native system for unifying fragmented experimental data, controlling access, and creating the documentation backbone needed to protect high-value formulations, processes, and discoveries without slowing research down.

