A batch clears mixing, looks stable in the lab, and then fails at final quality release. The viscosity has drifted outside spec. Color is off. Adhesion drops after cure. Production wants an answer before the next run, procurement is asking about raw material changes, and the development team is already pulling notebooks, spreadsheets, and memory into one hurried conversation.
That scene is common in polymer and formulation R&D because many teams still handle failure as an event to investigate rather than a system to manage. They run a root cause exercise after the damage is done, patch the obvious issue, and move on. Then a closely related problem shows up in scale-up, in storage, or in customer qualification.
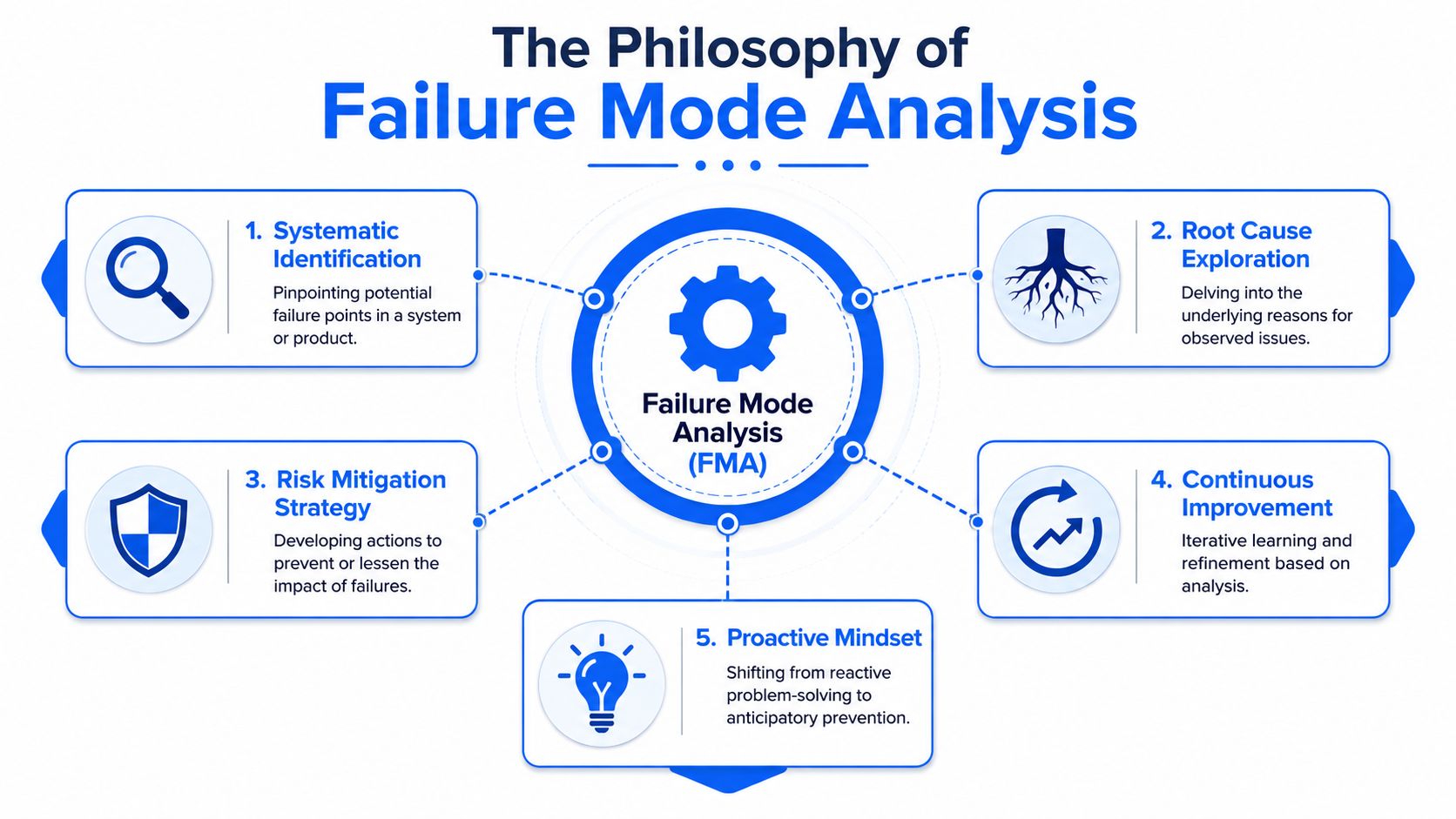
Failure mode analysis is the discipline that breaks that cycle. It gives teams a structured way to ask not only what failed, but what could fail, why it would fail, how severe the consequence would be, and whether current controls would catch it in time. In practice, that shift matters more than the terminology. Teams stop acting like emergency responders and start acting like reliability engineers.
For materials organizations, that means fewer surprises during transfer from bench to pilot, better use of scarce experiment capacity, and a stronger technical basis for deciding which risks deserve immediate attention. Methods such as FMEA and RCA both have value, but they serve different moments in the life of a formulation. Used well, they turn scattered troubleshooting into an operating habit.
Table of Contents
- Introduction When Good Formulations Go Bad
- A pre-mortem for formulations
- What the method changes in daily work
- Start with the formulation as a system
- Score risk in a way the team can defend
- Turn the worksheet into action
- From fragmented records to a working knowledge system
- Where AI helps and where scientists still decide
Introduction When Good Formulations Go Bad
A new adhesive looks promising through early screening. Initial tack is strong, cure profile is acceptable, and the bench team can reproduce the blend. Then the first larger batch starts to drift. One vessel gives a different viscosity window. Another batch yellows after UV exposure. A third passes internal checks but shows weak substrate bonding during downstream testing.
At that point, organizations typically go reactive. They review the failed lot, compare operator notes, ask whether the curing agent ratio was off, and check whether a supplier lot changed. That work is necessary, but it's also expensive because it starts after material, time, and confidence have already been lost.
In polymer development, failures rarely come from a single dramatic mistake. They usually come from interactions that looked harmless in isolation. A slight variation in raw material moisture, a mixing sequence that changes local concentration, a hold time that affects pre-reaction, or a test method that doesn't surface instability until late in the workflow can all produce the same visible symptom.
The strongest development teams don't just solve failures faster. They design their process so fewer failures reach the end of the line.
That's where failure mode analysis earns its place. It isn't paperwork for quality audits. It's a practical way to map the weak points in a formulation, process, and test system before they become release failures. For R&D leaders, it also changes team behavior. Scientists stop asking only, “Why did this batch fail?” and start asking, “Where is this program most likely to fail next if we don't change the system?”
Understanding Failure Mode Analysis at Its Core
Failure mode analysis works best when you treat it as a pre-mortem for technical work. The team assumes the formulation, process, or scale-up effort has gone wrong, then works backward to identify the plausible paths that got it there. That simple shift changes the quality of discussion. People stop defending current practice and start examining where it breaks.
A pre-mortem for formulations
For a polymer scientist, the word “failure” needs a broad definition. It includes obvious outcomes such as cracking, haze, poor adhesion, gelation, phase separation, discoloration, or viscosity drift. It also includes failures of manufacturability, storage stability, testability, and transferability from one site or scale to another.
A useful analysis asks several questions in sequence:
- What can fail: A property, unit operation, raw material interaction, packaging condition, or analytical method.
- What happens if it fails: Customer rejection, missed spec, poor application performance, rework, scrap, or delayed release.
- Why it might fail: Formulation chemistry, processing conditions, environment, operator practice, or weak controls.
- How likely and detectable it is: Whether the issue occurs often enough to matter and whether current checks would catch it before impact.
Traditional note-taking often weakens this exercise because teams reconstruct too much from memory. In labs that are trying to tighten observation capture, a private Voice-to-ELN app can help preserve process context that usually disappears between the hood, the mixer, and the meeting room.
What the method changes in daily work
The mature form of failure mode analysis in industry is Failure Mode and Effects Analysis, or FMEA. It emerged in the late 1950s as one of the first highly structured methods for failure analysis, and its scoring framework commonly uses severity, occurrence, and detection on a 1-to-10 scale, multiplied into the Risk Priority Number, or RPN = S × O × D to rank failure modes, as described in the FMEA reference overview.
That matters because it gives a lab a semi-quantitative way to compare very different risks without relying only on narrative judgment. One team may be worried about yellowing under UV, another about viscosity instability after storage, and a third about poor cure in humid conditions. A structured method forces those concerns onto the same decision frame.
Practical rule: If the discussion ends with “we should keep an eye on that,” the team hasn't done failure mode analysis yet. It has only listed concerns.
Comparing Key Failure Analysis Methods FMEA vs FMECA vs RCA
Teams often use the names interchangeably, and that creates confusion. In practice, these methods answer different questions, at different times, for different decisions. Choosing the wrong one usually means one of two failures. Either the team performs a post-failure investigation when it should be preventing failure, or it creates a forward-looking worksheet when the immediate need is to identify what already broke.
The simplest way to separate the methods
Root Cause Analysis, or RCA, is reactive. A batch failed, a coating blistered, a sealant lost bond strength, or a process excursion occurred. The team investigates the actual event and traces it back to the most credible underlying cause or cause set. RCA is narrow by design. It asks what happened in this case.
FMEA is proactive. Before a failure reaches the customer, pilot line, or final release gate, the team maps possible failure modes, their effects, their causes, existing controls, and the relative priority for action. In high-stakes industries, teams assign severity, occurrence, and detection ratings, calculate RPN, and then recalculate after corrective actions to confirm improvement, as outlined in the AHRQ FMEA analysis guidance.
FMECA extends the same logic by adding a stronger criticality lens. In real engineering settings, that usually means the team needs a more explicit way to distinguish not just whether something can fail, but which failures are unacceptable because of safety, mission, compliance, or reliability consequences. Materials teams encounter this when products move into demanding applications where some failure modes cannot be treated as routine quality variation.
Comparison of failure analysis methods
| Attribute | Root Cause Analysis (RCA) | Failure Mode & Effects Analysis (FMEA) | Failure Mode, Effects & Criticality Analysis (FMECA) |
|---|---|---|---|
| Primary timing | After a failure or deviation occurs | Before failure, during design, development, transfer, or process review | Before failure, usually where consequences require more formal prioritization |
| Main question | What caused this event? | How could this system fail? | Which possible failures are most critical? |
| Scope | Usually one event, one symptom, or one deviation trail | Broad review of product, process, assembly, or service risks | Similar to FMEA, but with added criticality focus |
| Typical output | Confirmed or likely root cause, corrective action, containment | Ranked list of failure modes with mitigation actions | Ranked list with stronger focus on critical consequences |
| Best use in polymer R&D | Investigating an off-spec batch, unstable lot, or failed qualification test | Designing robust formulations, scale-up plans, control strategies, and release checks | Screening high-consequence formulations or process steps where some failures are unacceptable |
| Team behavior it encourages | Deep investigation after the fact | Cross-functional anticipation of failure paths | Formal escalation of the most consequential risks |
A practical rule is simple. Use RCA when the batch is already in trouble and you need to know why. Use FMEA when the formulation is still under active design or transfer and you need to prevent trouble. Use FMECA when ordinary prioritization isn't enough because the consequence profile demands stricter ranking.
For most formulation organizations, FMEA is the daily workhorse. RCA remains indispensable, but it shouldn't be the only analytical muscle the group develops.
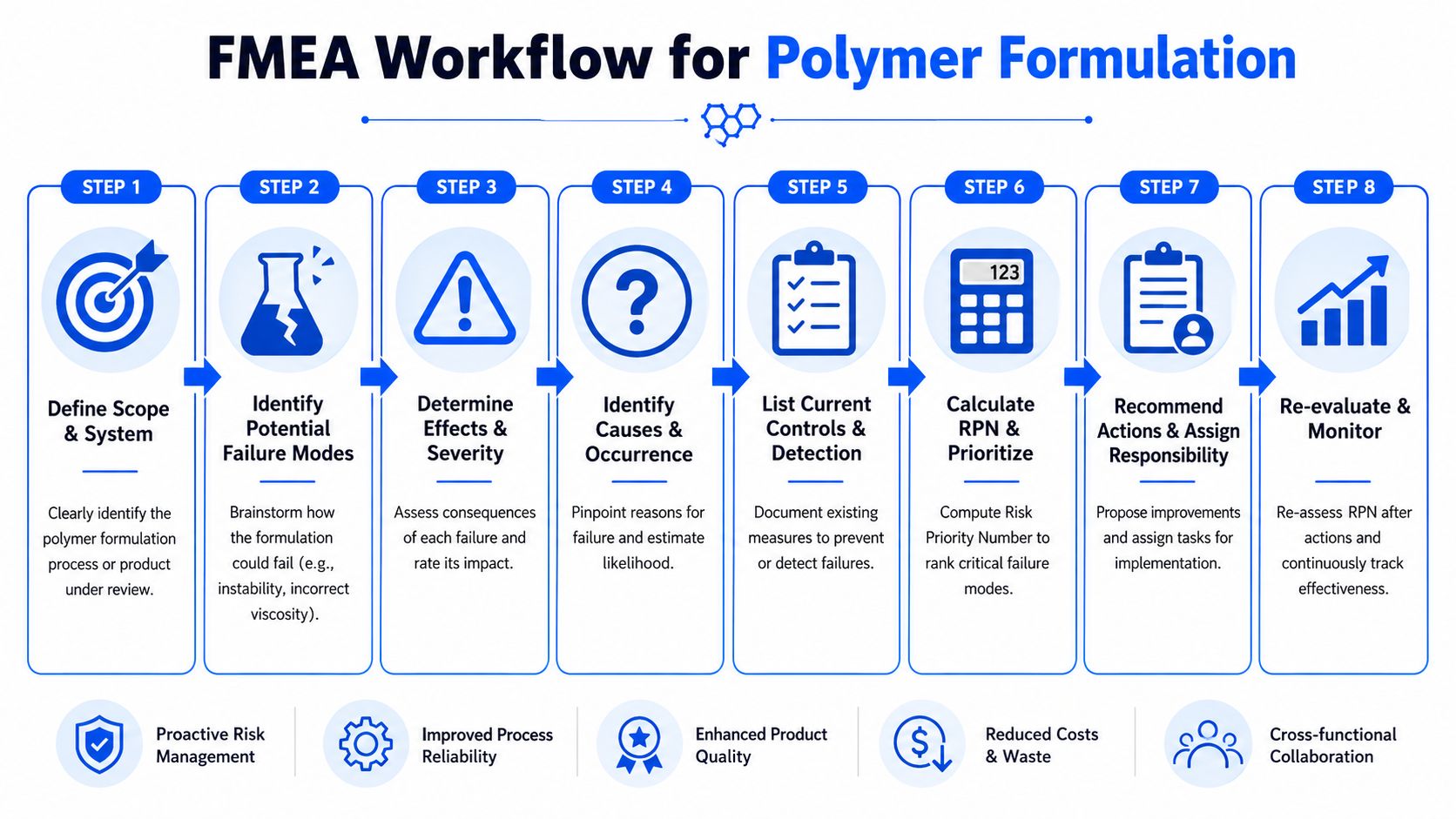
A Practical FMEA Framework for Polymer Formulation R&D
A good FMEA in formulation work has to follow the chemistry, the process, and the way the material is used. If it stays too generic, it becomes a checklist nobody trusts. If it becomes too detailed, the team drowns in low-value entries and misses the few risks that govern scale-up success.
Start with the formulation as a system
Take a simple example: a new adhesive intended for reliable bonding, workable application viscosity, stable storage, and acceptable color after cure. The first job is to define scope. Are you analyzing the bench formulation, the compounding process, the packaged product, or the end-use bond? Those are related systems, but they don't fail in the same way.
Then build the chain:
Define the required functions
List what the formulation must do. Bond strength, viscosity window, cure behavior, appearance, storage stability, and compatibility with the intended substrate usually belong here.List potential failure modes
In polymer work, this should be concrete. Poor adhesion, insufficient tack, viscosity drift, discoloration under UV, sedimentation, incomplete cure, foaming, gel formation, or phase separation are all better than vague labels such as “performance issue.”Describe the effect of each failure
Ask what the user, plant, or downstream process experiences. The effect might be scrap, line stoppage, customer complaint, inconsistent coating weight, failed qualification, or inability to dispense.Identify credible causes
Typical causes include wrong resin-to-hardener ratio, raw material impurity, unrecognized inhibitor carryover, moisture uptake, incorrect order of addition, insufficient mixing energy, excessive hold time, or poor temperature control.
Score risk in a way the team can defend
In a rigorous FMEA workflow, each potential failure mode is evaluated through a cause-effect chain and then scored on severity, occurrence or probability, and often detection. The composite score, commonly called RPN, is used to prioritize mitigation work, as outlined in Juran's guide to FMEA.
Two details matter in practice.
First, severity should be anchored to the worst credible effect, not the average case. If one failure mode can lead to several outcomes, teams should retain the highest severity rating for prioritization, consistent with ASQ guidance on FMEA severity.
Second, occurrence and detection shouldn't be guessed casually. A formulation scientist may feel that discoloration is rare, while a production chemist may have seen it repeatedly under certain storage conditions. Unless those views are tied back to data, the score becomes a negotiation rather than an assessment.
If the team argues more about the number than about the mechanism, the scoring system is carrying too much uncertainty.
A practical scoring discussion might look like this:
- High severity candidate: Loss of bond integrity after cure, because the product no longer performs its intended function.
- Moderate occurrence candidate: Viscosity drift linked to raw material variability that appears under some lots but not all.
- Weak detection candidate: A latent storage instability that doesn't appear in the release panel and only emerges later.
Turn the worksheet into action
The worksheet only becomes useful when the top-ranked items drive changes in formulation or control strategy.
That usually means actions such as:
- Tighten material inputs: Add supplier qualification checks, incoming identity tests, or moisture controls for sensitive ingredients.
- Redesign the process window: Change mixing order, reduce hold time, or narrow temperature limits where pre-reaction is likely.
- Improve detection: Add an earlier screen for cure behavior, phase stability, color shift, or rheology drift.
- Reduce formulation sensitivity: Reformulate around a more effective stabilizer package, dispersant, or curing chemistry.
After controls are added, the team should re-score the failure mode. That final step is often skipped, but it's what separates a live risk process from a historical document. In polymer R&D, the best FMEAs are revised after every meaningful learning cycle, especially after scale-up runs and failed qualifications.
The Hidden Costs of Traditional Failure Analysis
Teams often don't struggle because failure mode analysis is conceptually difficult. They struggle because the operating environment around it is weak. The chemistry is complex, the process knowledge is fragmented, and the documentation format can't hold the full decision context.
Why the spreadsheet usually disappoints
The standard spreadsheet FMEA has a predictable lifecycle. A team fills it out during a project review, stores it in a shared folder, and barely touches it again unless an audit or transfer meeting forces it back into view. By then, the actual knowledge has moved elsewhere. Some of it sits in instrument files, some in email threads, some in operator memory, and some in the notebook margin where the scientist wrote that the batch “looked wrong” before any measured value failed.
That fragmentation creates several practical problems:
- Data lives in silos: Experimental conditions, raw material records, QC results, and failure reviews aren't connected well enough to support fast reasoning.
- Scoring becomes subjective: Severity may be straightforward, but occurrence and detection often reflect confidence, seniority, or recent experience more than evidence.
- Documents go static: The FMEA captures a moment in time, while the formulation keeps evolving.
- Interactions stay hidden: Ingredient combinations and process conditions often matter more than any single factor, and simple worksheets don't surface that well.
What gets missed in formulation work
Formulation failures are rarely linear. A resin that performs well with one additive package may become unstable when a different defoamer, pigment, inhibitor, or supplier lot enters the system. A process that works at bench scale may fail once thermal history, shear profile, and hold time shift in a larger vessel.
Traditional failure analysis struggles with these coupled effects because it treats entries as isolated rows. One row for viscosity drift. Another for cure inconsistency. Another for color shift. In reality, those symptoms may share common causes or amplify one another.
A failure table is useful only if the team can trace it back to the real material system. Otherwise it becomes a tidy summary of confusion.
That's why many organizations feel that they “do FMEA” but don't get much value from it. They complete the form, yet still rely on experienced individuals to remember what happened last time. That isn't a strong risk culture. It's institutional memory held together by the people who haven't left yet.
Supercharging Failure Analysis with Polymerize AI
The main limitation of traditional failure analysis isn't the method itself. It's the lack of a connected, learning system around the method. When formulation records, test outputs, raw material history, and process conditions are unified, the team can treat FMEA and related reviews as living analyses instead of frozen files.
From fragmented records to a working knowledge system
An AI-native materials platform changes the mechanics of failure mode analysis in several ways.
First, it creates a single technical context for decisions. Instead of jumping between spreadsheets, ELNs, supplier files, and test reports, scientists can review formulations, process settings, historical runs, and measured outcomes together. That matters because failure mechanisms in polymer systems often become visible only when the formulation and the process are viewed side by side.
Second, it makes risk scoring less dependent on intuition alone. A team still needs expert judgment, but historical records can inform whether a failure mode is recurrent, under what conditions it appears, and whether current controls detect it early. That gives occurrence and detection ratings a better basis than memory or opinion.
Third, explainable AI can support root cause discovery across many experiments at once. In practice, that means the system can surface patterns a scientist might not catch manually, such as certain batch outcomes clustering around a supplier change, a humidity range, a particular order of addition, or a concentration threshold for a stabilizer.
A platform can also make the review cycle faster. When a new failed run appears, the team doesn't need to start from a blank worksheet. It can compare the event against known failure patterns, similar formulations, and prior mitigations already captured in the organization's data.
Where AI helps and where scientists still decide
The most useful role for AI in this setting is not automatic decision-making. It's decision support with traceable reasoning.
That means AI can help teams:
- Find precedent: Show where similar formulations or process windows produced related failures.
- Highlight likely drivers: Surface variables that correlate with instability, low adhesion, poor cure, or inconsistent rheology.
- Suggest next experiments: Point toward design changes or confirmation runs that reduce uncertainty around the highest-risk modes.
- Keep the analysis current: Update the knowledge base as new batches, tests, and observations enter the system.
The scientist still decides whether a pattern is chemically credible, whether a mitigation is practical, and whether a model is over-reading noise. That human filter matters because formulation work includes hidden variables, incomplete records, and mechanism questions that need domain judgment.
A short product walkthrough helps make that more tangible:
The shift is cultural. Once teams can reuse prior failure knowledge, compare across programs, and evaluate proposed actions against a broader data foundation, failure mode analysis stops being a compliance artifact. It becomes part of how the lab plans work, gates scale-up, and learns from every unsuccessful run.
Conclusion Building a Resilient R&D Process
Resilient materials development doesn't come from reacting faster to the next bad batch. It comes from building a system that identifies weak points early, ranks them clearly, and updates its understanding as evidence accumulates. That's what failure mode analysis does when teams treat it as an operating discipline rather than a meeting template.
For polymer and formulation R&D, the practical lesson is straightforward. Use RCA when something has already gone wrong and the immediate cause matters. Use FMEA when you still have room to shape the outcome. Build the analysis around real formulation functions, concrete failure modes, credible causes, and controls that can effectively prevent or detect trouble in time.
The strongest organizations also accept that spreadsheets won't carry this burden well enough forever. Modern labs generate too much interconnected information, and too much of the important context is lost when data, observations, and historical outcomes remain scattered. A connected, data-driven workflow gives teams a better foundation for judging occurrence, improving detection, and learning from repeated patterns across projects.
Leaders who want to strengthen this capability should review how their teams capture process observations, how often FMEAs are refreshed after learning, and whether development decisions are based on accessible historical evidence or on whoever remembers the last incident best. For a broader perspective on how technical organizations mature these practices, it's worth taking time to explore engineering research and development through the lens of systems, process, and knowledge reuse.
A strong failure analysis culture doesn't slow innovation. It protects it. Teams spend less time rediscovering the same problems and more time designing materials that survive real-world variation from the start.
If your team wants to move beyond static FMEAs and fragmented formulation records, Polymerize offers an AI-native system built for materials R&D. It helps unify experimental data, surface failure drivers, and guide the next best experiment so scientists can reduce avoidable risk while accelerating development.

