Your lab probably already has the symptoms.
Formulation data lives in spreadsheets. Processing conditions sit in instrument software that only one engineer knows how to export. Mechanical test results are saved to shared drives with naming conventions nobody follows consistently. The actual experimental rationale is still handwritten in notebooks, or worse, remembered by the scientist who ran it. When a CTO asks a simple question like “what changed between the failed batch and the stable one,” the team spends days reconstructing context.
That's the moment when an electronic lab notebook stops being an IT project and becomes an R&D infrastructure decision.
In materials R&D, the core value of an ELN isn't that it replaces paper with screens. It's that it creates the first trustworthy, connected record of experiments, formulations, conditions, results, and decisions. Without that foundation, AI initiatives stall before they start. Models can't learn from fragmented, inconsistent, low-context data. Scientists can't reuse what they can't find. Leaders can't protect IP they can't trace.
Table of Contents
- Structured entry instead of free-form ambiguity
- Version control and audit trails instead of file chaos
- Search, retrieval, and collaboration
- Integration is what separates useful from transformative
- Reproducibility improves when records become structured
- IP protection gets stronger when provenance is built in
- Scale-up gets faster when teams can trace failure correctly
- Compliance becomes operational instead of reactive
- Start with a bounded pilot
- Design the data model before moving data
- Build integrations in order of scientific value
- Treat training as workflow adoption
- What AI-ready ELN data looks like
- Why explainability matters in the lab
- The progression most organizations should expect
What Is an Electronic Lab Notebook
An electronic lab notebook is the digital system where scientists document experiments, attach data, capture context, and preserve an auditable research record. In a modern materials organization, it should do far more than mimic a bound notebook. It should act as the operational layer that connects what was planned, what was run, what changed, and what was learned.
That distinction matters. A scanned PDF of handwritten notes is digital storage, not digital research infrastructure. A folder full of spreadsheets is better than paper in some ways, but it still leaves data fragmented across files, owners, and formats. A real ELN creates a structured system of record.
What it replaces in practice
Most first-time adopters think they're replacing paper. In reality, they're usually replacing a patchwork of:
- Paper notebooks that capture intent but not searchable metadata
- Spreadsheets that hold results but lose provenance
- Instrument exports that preserve raw output but not experimental context
- Email and chat threads where decisions get made and then disappear
- Shared drives that turn historical work into an archaeology exercise
An ELN pulls these fragments into a common workflow. Scientists enter experiment plans in a repeatable format, attach relevant files, record deviations, and preserve links between protocols, samples, and outcomes.
Practical rule: If your team still needs to ask “whose notebook has the full story,” you don't have a usable research record.
Why this is becoming standard infrastructure
The category is no longer niche. The global ELN market was valued at USD 613.5 million in 2023 and is projected to reach USD 1,276.3 million by 2033, with a 7.6% CAGR from 2024 to 2033, according to Market.us coverage of the Electronic Lab Notebook market.
That growth reflects something deeper than software procurement. Labs are shifting from static documentation to searchable, collaborative, audit-ready data systems. In materials R&D, that's especially important because a single development program depends on linking formulation chemistry, process conditions, analytical results, and performance testing across time.
What an ELN should become
A good ELN becomes the backbone for three outcomes that matter to a CTO:
| Need | What the ELN provides |
|---|---|
| Operational efficiency | Searchable records, reusable templates, cleaner handoffs |
| IP and compliance | Timestamps, traceability, controlled access, defensible records |
| AI readiness | Structured, contextualized data that models can actually use |
That's why the first ELN decision shouldn't be framed as “paper versus digital.” It should be framed as “fragmented memory versus connected intelligence.”
Core Features That Replace Paper and Spreadsheets
The best way to evaluate an ELN is to stop asking what features it has and start asking what failure modes it removes. Paper notebooks and spreadsheets fail in predictable ways. Entries are inconsistent. Files get copied instead of versioned. Search is manual. Auditability depends on personal discipline. Instrument data sits outside the record.
A capable ELN addresses those problems by design.
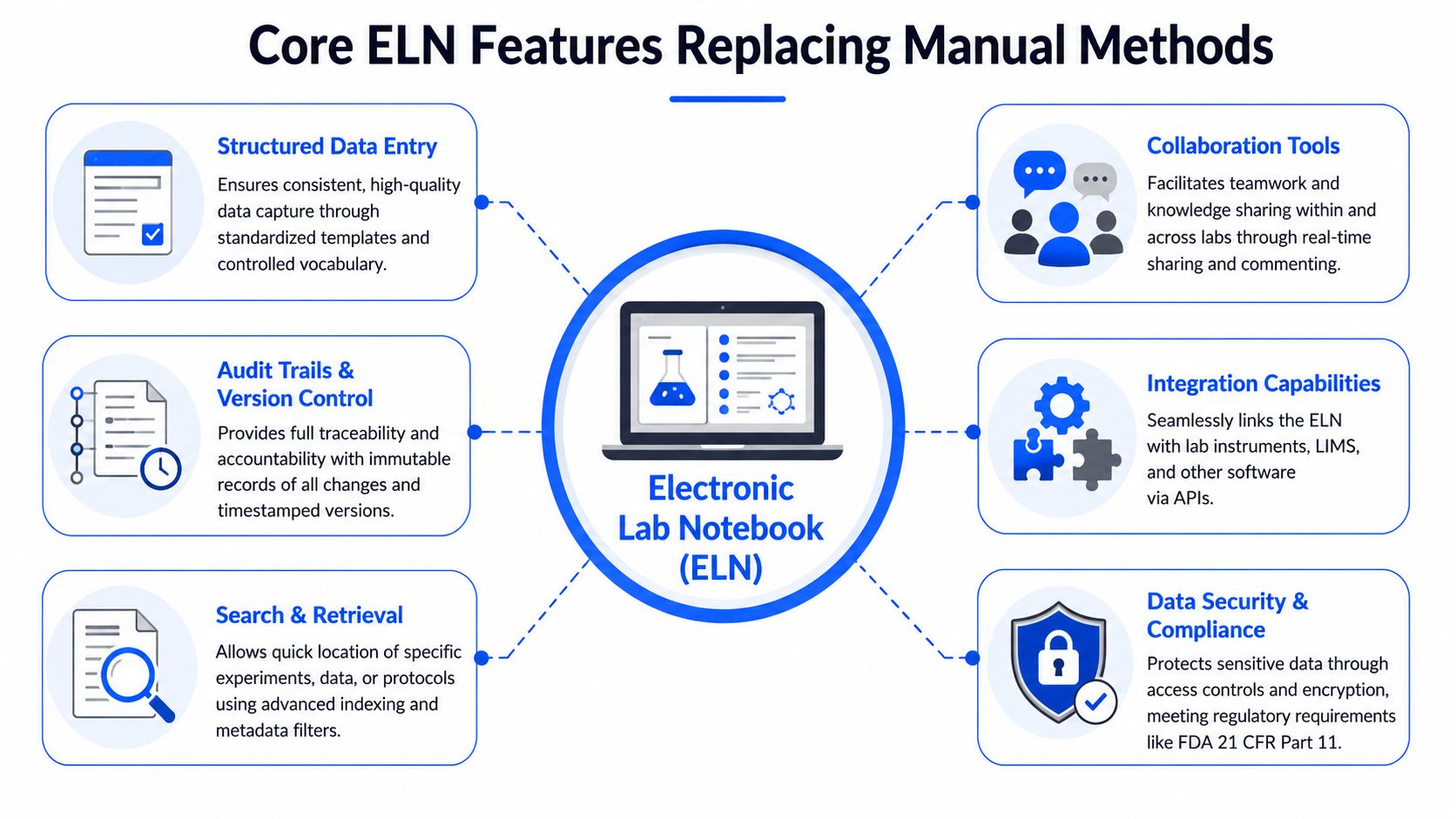
Structured entry instead of free-form ambiguity
Paper gives scientists freedom. It also creates inconsistency. Two chemists can document the same synthesis in completely different ways, which makes later comparison difficult and downstream analysis unreliable.
Structured templates fix that by requiring common fields such as sample ID, reagent lot, processing temperature, cure time, instrument method, and acceptance criteria. Scientists still need room for observations, but the critical variables should be captured in a standard schema.
That's one reason digital record-keeping matters operationally, not just administratively. The failure to create digital records accounts for approximately 17% of all data loss incidents in research environments, according to Collaborative Drug Discovery's discussion of why labs adopt ELNs.
Version control and audit trails instead of file chaos
Spreadsheets are notorious for “final_v2_actual_final” behavior. Nobody is certain which version was approved, what changed, or whether a result was copied manually from another source.
An ELN should track revisions automatically. When a protocol changes, the system should preserve the prior version, timestamp the edit, identify the user, and keep the record immutable enough for audit and IP purposes.
Look for:
- Protocol versioning so teams can compare historical methods
- Change history tied to named users
- Electronic signatures where review and approval matter
- Locked records after completion or sign-off
If a system lets users overwrite history without a trace, it's not solving your documentation problem. It's relocating it.
Search, retrieval, and collaboration
Search is where users typically feel the benefit first. Scientists stop flipping through pages and start querying by material, test method, reagent, date range, or project. That changes how people use historical knowledge. Old work becomes reusable.
Collaboration also improves, but only if the ELN supports the way labs work. That means controlled sharing, comments, review workflows, and role-specific permissions. It does not mean turning every experiment into a social feed.
A practical checklist for these features:
- Search that understands metadata rather than only filenames
- Project workspaces that group experiments, files, and decisions
- Permission controls so teams can share selectively across functions
- Linked records connecting protocols, samples, and results
Integration is what separates useful from transformative
An ELN becomes substantially more valuable when it can connect with LIMS, inventory systems, analytical software, and instrument outputs. Without integration, scientists still re-enter data manually, which preserves transcription risk and wastes time.
The first deployment doesn't need every connector on day one. But the platform should support APIs, imports, and clean handoffs from core systems. If it can't participate in your broader data architecture, it will eventually become another silo.
Strategic ELN Benefits for Materials Innovation
Materials R&D has a particular problem that generic ELN discussions often miss. The value of an experiment rarely sits in one measurement. It sits in the relationship between formulation, process history, structure, test conditions, and final performance. If those elements are recorded in different places, scientists can't reliably connect cause and effect.
That's why the strategic payoff from an ELN in materials work is bigger than “better documentation.”

Reproducibility improves when records become structured
In polymer and materials R&D, ELNs enforce data integrity through structured, schema-driven entry rather than open-ended free text. That approach can reduce experimental reproducibility errors by up to 40% compared to paper notebooks.
The significance of that number isn't academic. In a materials team, reproducibility failures mean more than repeated bench work. They delay scale-up, confuse root-cause analysis, and weaken confidence in the data used for customer qualification or internal go/no-go decisions.
IP protection gets stronger when provenance is built in
A paper notebook can support IP claims if it's maintained rigorously. In practice, many organizations rely on habits that don't hold up under pressure. Missing dates, unclear edits, unattached raw files, and informal handoffs create avoidable risk.
A strong ELN closes those gaps with timestamped entries, user attribution, linked attachments, review trails, and controlled visibility. For CTOs, that matters in three situations:
| Scenario | Why the ELN matters |
|---|---|
| Patent support | It preserves the sequence of invention and experimental evidence |
| Personnel turnover | It keeps know-how inside the company, not in individual notebooks |
| Partner collaboration | It supports selective access without giving away the whole program |
Scale-up gets faster when teams can trace failure correctly
Materials programs often break during handoff points. The lab finds a promising formulation. Process engineering changes mixing order or thermal history. Quality sees variability but can't trace whether it came from raw material drift, procedure changes, or testing differences.
An ELN helps by connecting the upstream and downstream story. When formulation records, inventory context, process parameters, and test outputs live in one traceable record, teams can investigate what changed instead of arguing about whose spreadsheet is current.
What works: standard templates for formulations, processing runs, and test methods.
What fails: asking each scientist to “document carefully” in a blank page system and hoping consistency emerges.
Compliance becomes operational instead of reactive
For regulated or audit-sensitive environments, an ELN also changes compliance from a periodic scramble into a normal part of the workflow. Requirements such as 21 CFR Part 11 become easier to support when records are traceable, reviewable, and access-controlled by default.
Many leadership teams under-scope the decision. They treat ELN adoption as a documentation upgrade when it's really a platform choice that affects innovation speed, defensibility of results, and the ability to commercialize work without reconstructing evidence later.
Cloud vs On-Premise ELN Deployment Models
This decision tends to get framed emotionally. Cloud feels fast but less controlled. On-premise feels safer but heavier. A more practical view reveals you're choosing where responsibility sits, how quickly you can move, and what kind of operational burden your IT team can absorb.
For most first-time ELN programs, deployment choice matters less than governance, integration design, and user adoption. Still, the trade-offs are real.
Where cloud usually wins
Cloud ELNs fit organizations that want faster deployment, lower infrastructure overhead, and easier updates. They're often the better choice when the R&D function needs to standardize across multiple sites or when internal IT already has a full queue.
Common strengths of cloud deployment:
- Quicker rollout because the vendor manages the core environment
- Easier scaling when new teams, sites, or collaborators come online
- More predictable maintenance through managed updates and support
- Simpler remote access for distributed technical teams
The catch is governance. A cloud ELN still requires strong role design, identity management, data retention policy, and vendor due diligence. Buying SaaS doesn't outsource accountability.
Where on-premise still makes sense
On-premise ELNs usually appeal to companies with strict internal hosting requirements, legacy infrastructure constraints, or a strong preference for owning the full stack. Some organizations also need deeper customization than a standard SaaS deployment can support.
That said, on-premise environments create work that's easy to underestimate. Someone has to manage upgrades, validation cycles, backups, availability, security patching, and disaster recovery. If your IT organization doesn't already run laboratory systems well, on-premise won't magically create that capability.
A simple decision lens
Instead of debating ideology, evaluate both options against four criteria:
| Decision factor | Cloud ELN | On-premise ELN |
|---|---|---|
| Speed to deploy | Usually faster | Usually slower |
| Internal IT lift | Lower day-to-day infrastructure burden | Higher operational burden |
| Customization control | Moderate, depends on vendor | Higher, if resourced properly |
| Responsibility for uptime and patching | Shared with vendor | Primarily internal |
Choose the model your organization can govern well, not the one that sounds most secure in procurement meetings.
For many materials teams, the practical path is a cloud deployment with disciplined access controls, validated workflows, and a clear integration roadmap. The wrong path is selecting on-premise for “control” and then starving the system of support.
Planning Your ELN Implementation and Integration
Most ELN projects don't fail because the software is bad. They fail because teams try to digitize chaos. If you move inconsistent naming, duplicate records, unowned spreadsheets, and half-documented protocols into a new platform, you don't get transformation. You get a cleaner-looking mess.
Implementation should start with process design, not migration scripts.
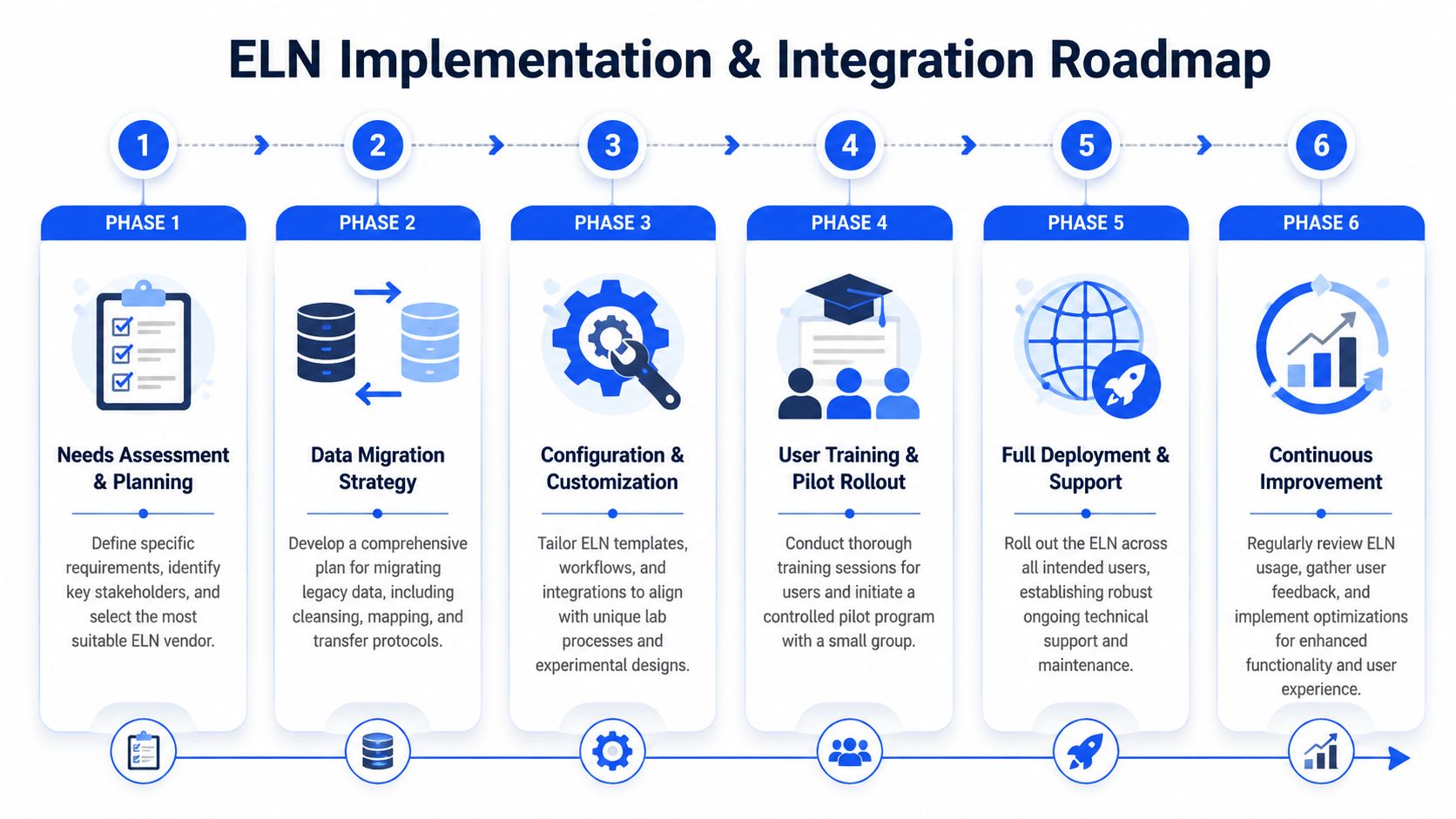
Start with a bounded pilot
The best first deployment is narrow enough to control and broad enough to matter. Pick one workflow family, not the entire enterprise. In materials R&D, good pilot candidates are formulation screening, test method execution, or scale-up trial documentation.
A solid pilot answers practical questions:
- Which records need templates and which need flexible note capture
- Which metadata fields are mandatory for later search and analysis
- What raw files should attach automatically versus manually
- Who reviews and signs off on completed work
- Where the current process breaks when scientists are busy
Don't start by migrating everything historical. Start by making new work clean.
Design the data model before moving data
Many teams lose momentum by underestimating how much interpretation sits inside old records. One spreadsheet says “Temp.” Another says “Tset.” A notebook entry says “mixed until uniform.” An instrument file uses an operator code nobody can decode.
Before migration, define a common vocabulary for the records you care about. For materials work, that usually includes:
| Data domain | Typical fields to standardize |
|---|---|
| Formulations | component identity, concentration, lot, order of addition |
| Processing | temperature, pressure, mixing profile, cure conditions |
| Testing | method, instrument, sample prep, operator, acceptance notes |
| Samples | sample ID, parent batch, storage condition, status |
Once that model is defined, migration becomes a mapping exercise instead of a guessing exercise.
Migration rule: Don't import legacy ambiguity into your new system just because it exists. Archive some history. Normalize the part you'll actually reuse.
Build integrations in order of scientific value
A first ELN doesn't need every system connected on launch day. It does need the right first connections. In materials R&D, that often means linking the ELN with inventory, key instrument outputs, and any LIMS or sample tracking system that already holds operational truth.
A sensible sequence is:
- User identity and access so governance is stable from day one
- Template and workflow setup so teams capture data consistently
- High-value instrument or file imports that remove manual transcription
- Inventory or LIMS links where lot traceability matters
- Historical data unification for reuse and analytics
This is also where a dedicated unification layer helps. When data is spread across spreadsheets, legacy databases, prior ELNs, and instrument exports, the hard problem isn't storage. It's cleaning, mapping, reconciling, and linking records so the new ELN starts with coherent context rather than inherited fragmentation.
Treat training as workflow adoption
Scientists don't resist ELNs because they hate software. They resist systems that slow them down, force unnecessary fields, or ignore how experiments happen.
Training works best when it's tied to real workflows, not feature tours. Show chemists how to run their next formulation screen in the new system. Show analysts how to attach instrument outputs without duplicate entry. Show managers how review queues work. Then refine templates quickly based on what people do.
A phased rollout beats a hard cutover in most organizations. It reduces disruption and exposes integration issues before they spread.
Making Your ELN the Foundation for AI and ML
An ELN becomes strategically valuable when it stops acting like a record archive and starts acting like a structured data source. That's the threshold between digitization and intelligence.
AI in materials R&D doesn't fail because models are weak. It usually fails because experimental data is incomplete, inconsistent, and stripped of context. If the underlying records don't capture composition, processing history, test conditions, deviations, and outcomes in a machine-readable way, the model learns very little and scientists trust it even less.
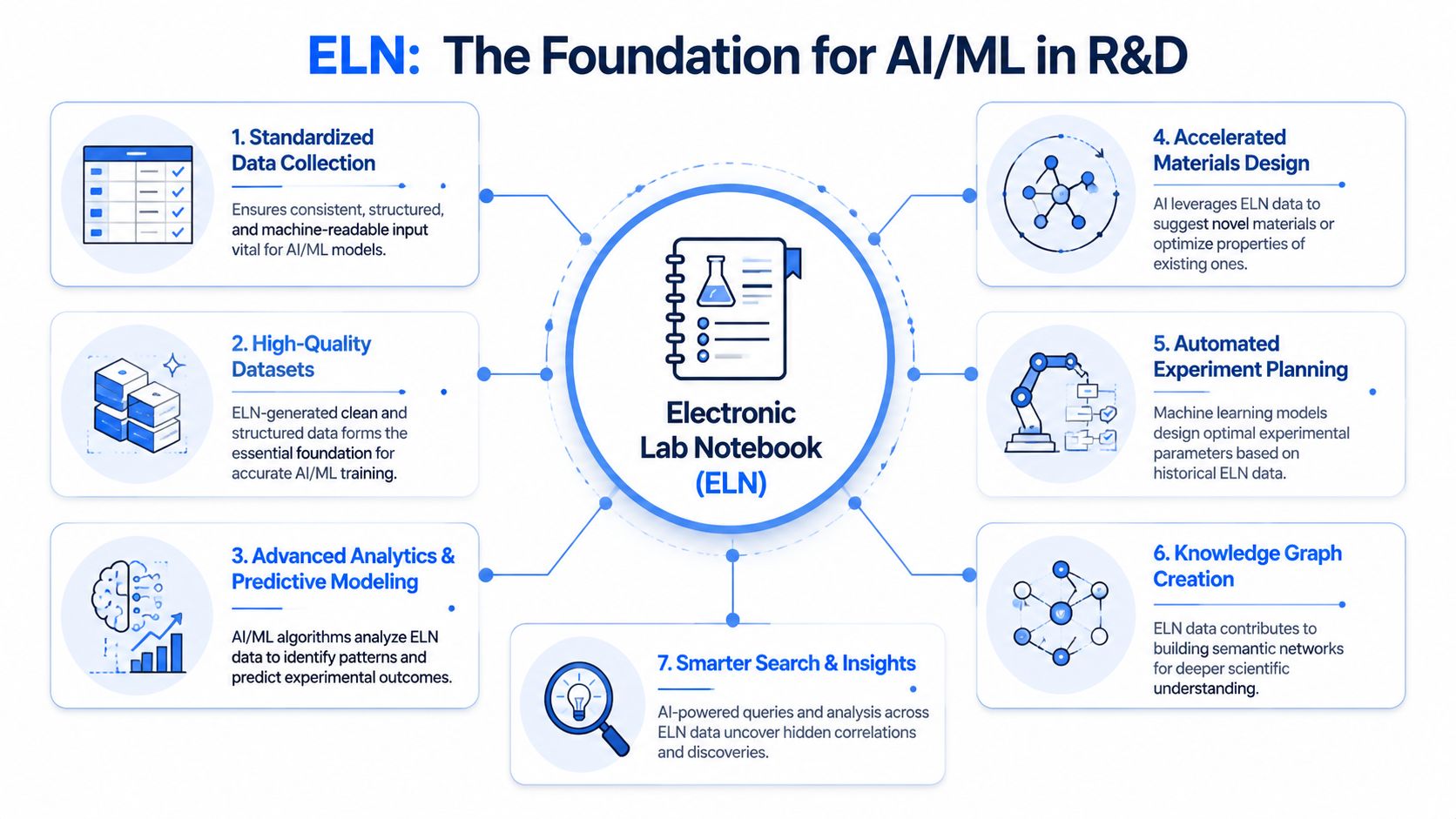
What AI-ready ELN data looks like
In advanced materials development, ELNs support AI-driven experimentation when data is captured in FAIR formats and tagged with machine-readable metadata for each relevant experimental parameter. That structure makes it possible to train models that predict properties, optimize formulations, and identify likely causal drivers rather than just surface loose correlations.
A mature setup links the ELN to domain-specific models for things like rheology, thermal stability, or tensile behavior. The point isn't just prediction. It's explanation. Teams need systems that can suggest the next experiment and show why that recommendation makes sense.
That need for reliable context isn't unique to materials science. It's also a core theme in SpecStory's insights on AI reliability, which explain why better structured context leads to more dependable AI behavior.
Why explainability matters in the lab
Scientists won't trust a recommendation engine that behaves like a black box. They need to see the chain of reasoning, the relevant historical precedent, and the variables that likely drove the output.
A key benchmark here is the ability of ELNs to integrate with domain-specific models that produce not only predictions but causal explanations. That capability can reduce failed experiments by 50% in industrial settings, because scientists can plan the next best experiment from causal insight rather than guesswork.
A short demo is useful here because the value is easier to grasp when you see how structured experimental context can feed smarter decision-making.
The progression most organizations should expect
The path from ELN adoption to AI-assisted R&D usually looks like this:
- First, standardize experimental capture so critical variables stop disappearing.
- Then, unify historical and ongoing records so data can be reused across programs.
- Next, connect modeling workflows that can query and learn from that record.
- Finally, use model outputs to guide experiment planning, not just post hoc analysis.
Better AI starts with better lab records. If your ELN can't produce clean, linked, contextualized data, no modeling layer will rescue it.
For a CTO, this is the main reason to care about ELN design early. The fields you standardize today determine whether your organization can do trustworthy predictive work later.
ELN Governance Best Practices and ROI Metrics
Once the ELN is live, the hard part changes. The question is no longer “can we deploy it?” It becomes “can we keep the data reliable enough that scientists trust it and leadership can measure value?”
That's a governance issue, not a software issue.
Governance practices that hold up
Strong ELN governance is usually lightweight but explicit. It defines ownership, naming conventions, review expectations, permission models, and change control for templates. Without those rules, even a good ELN drifts back toward inconsistency.
A practical governance model includes:
- A cross-functional owner group with R&D, quality, IT, and data stakeholders
- Template stewardship so fields don't proliferate without purpose
- Role-based access rules that reflect project sensitivity and IP boundaries
- SOPs for record completion and review so the ELN remains a trusted system of record
- Periodic audits of data quality focused on missing metadata, naming drift, and inactive workflows
One warning from experience: don't over-govern the first year. If every template change needs a committee cycle, scientists will route around the system. Governance should protect data quality without making routine work painful.
What ROI should look like
The ROI case for an ELN is real, but it's often measured poorly. Teams make the mistake of trying to reduce value to one finance number too early. In practice, early ROI shows up in operational signals first, then strategic outcomes later.
Track metrics in three layers.
| ROI layer | What to measure qualitatively or operationally |
|---|---|
| Workflow efficiency | retrieval speed, time spent reconstructing experiment context, duplicate entry burden |
| Scientific quality | repeated experiments, documentation completeness, protocol consistency |
| Strategic impact | IP defensibility, cross-site reuse of historical data, readiness for analytics and AI |
If you want hard evidence that leadership will respect, start with before-and-after baselines in one pilot area. Measure how long it takes to find prior experiments, how often teams repeat work because context is missing, and how frequently managers can review complete records without follow-up. Those are credible indicators because they tie directly to researcher time, project delay, and decision quality.
A well-run ELN pays back twice. First by reducing friction in current work, then by making historical work reusable.
For CTOs, that second payoff is the bigger one. Once the organization can trust its experimental record, it can build analytics, stronger IP processes, and AI programs on top of something solid instead of improvising around missing context.
If your materials R&D team is trying to unify fragmented data, create an AI-ready foundation, and move beyond disconnected ELNs, spreadsheets, and lab silos, Polymerize is built for that transition. It helps enterprises connect experimental data into a secure system of intelligence, so scientists can protect IP, reduce failed experiments, and use explainable models to plan better next experiments.

