Your team probably already has the symptoms. Formulators are rerunning variations of old experiments because nobody trusts the historical data enough to reuse it. Process engineers have plenty of plant data but can't connect it cleanly to lab decisions. Leadership wants faster development, lower risk, and clearer ROI, while scientists hear “AI” and think “another black box that won't survive contact with the bench.”
That's the actual state of ai chemicals in most organizations. The problem isn't lack of interest. It's the gap between a promising demo and a system that helps chemists choose the next experiment, helps engineers scale it, and helps managers prove the investment was worth making.
Table of Contents
- Start with one problem that matters
- Measure operational value and innovation value
- Build or buy is usually the wrong first debate
The End of Trial and Error in Chemical R&D
Chemical R&D still runs on a familiar loop. A team sets a target property, makes a shortlist of candidate ingredients or structures, runs a batch of experiments, learns something partial, and then starts another round. That method can work. It also burns time whenever knowledge is trapped in notebooks, spreadsheets, test reports, and the memories of senior scientists.
The pressure has changed faster than the workflow. Teams need to shorten development cycles while handling more formulation complexity, stricter performance windows, and tighter production constraints. In that environment, trial and error stops being a scientific method and starts becoming an operational bottleneck.
A useful way to read the current market is this: adoption has moved past curiosity. One industry forecast valued the global market for AI in chemicals at USD 651.65 million in 2023 and projects it to reach USD 10,257.62 million by 2032, a 35.89% CAGR according to SNS Insider's AI in chemicals market forecast. That kind of expansion tells you something practical. Buyers aren't funding AI as a side experiment anymore. They're treating it as infrastructure for R&D, quality, process optimization, and planning.
Why this changes the competitive baseline
When one team can search historical experiments, model likely outcomes, and prioritize the next best test, it doesn't just move faster. It learns faster. That matters more than raw experiment count.
Practical rule: AI in chemicals is most useful when it reduces the number of low-information experiments, not when it simply automates reporting.
The strongest programs don't ask, “Can AI replace chemists?” They ask better questions:
- Where does our cycle slow down most often: candidate screening, formulation tuning, root-cause analysis, or scale-up?
- Which decisions are repetitive but data-rich: property prediction, recipe adjustment, process window selection?
- Where is tacit knowledge doing too much work: when a project succeeds only because one expert remembers what failed five years ago.
What works and what doesn't
A common mistake is to treat AI as a single software purchase. In practice, ai chemicals works when it becomes part of decision flow. It helps teams rank options before synthesis, detect patterns across failed and successful trials, and connect lab work to production constraints.
What doesn't work is chasing a broad “digital transformation” initiative without a concrete technical bottleneck to solve. In chemicals, value shows up when AI narrows search space, improves experimental design, and gives teams a cleaner path from hypothesis to validated material.
What AI in Chemicals Actually Means
Most confusion starts with the term itself. “AI in chemicals” sounds abstract, but in day-to-day R&D it usually means one thing: using models to connect chemistry, process conditions, and outcomes better than manual review alone can manage.
The simplest analogy is a super-scientist assistant. Not a replacement scientist. An assistant that has read your historical lab notes, technical data sheets, patents, test reports, process records, and prior formulations, then helps surface patterns a human team would struggle to assemble on demand.
Predictive models and generative models
These two categories get mixed together, and they solve different problems.
| Model type | What it does | Typical question |
|---|---|---|
| Predictive AI | Estimates likely properties or outcomes from known inputs | If we change this additive level, what happens to viscosity or stability? |
| Generative AI | Proposes new candidate structures, formulations, or routes that meet target constraints | Can we design a new candidate with this performance profile? |
Predictive systems are often the first practical win. They help teams estimate property shifts, flag risky conditions, or prioritize which formulations deserve lab time. Generative systems go further by proposing net-new options instead of only scoring existing ones.
The real technical value
The important part isn't that a model can produce an answer. It's that it can work across structured and unstructured information.
Structured data includes things like compositions, temperatures, mixing sequences, test values, and pass/fail records. Unstructured data includes handwritten observations, batch comments, customer complaints, patent text, and old project summaries. In chemical R&D, the answer you need is usually split across both.
A good AI system in a lab behaves less like a search engine and more like a second pair of scientific eyes. It connects what was tested, what was observed, and what should happen next.
That's why platforms matter. The useful ones don't just run a model in isolation. They connect fragmented records into a system scientists can query, validate, and act on. One example is Polymerize's AI-native system of intelligence, which combines centralized experimental data with domain-specific models to support property prediction, formulation optimization, and experiment planning. That's a concrete expression of what ai chemicals should look like in practice. Not chatbot novelty, but a working layer between raw data and scientific decision-making.
What AI is not
It isn't chemistry by autopilot. It won't fix a vague target profile, poor test discipline, or inconsistent measurement methods. If the team can't define what “better” means, the model can't optimize for it.
It also doesn't remove the need for scientific judgment. In regulated, high-stakes environments, the model proposes and ranks. The scientist still decides, tests, and signs off.
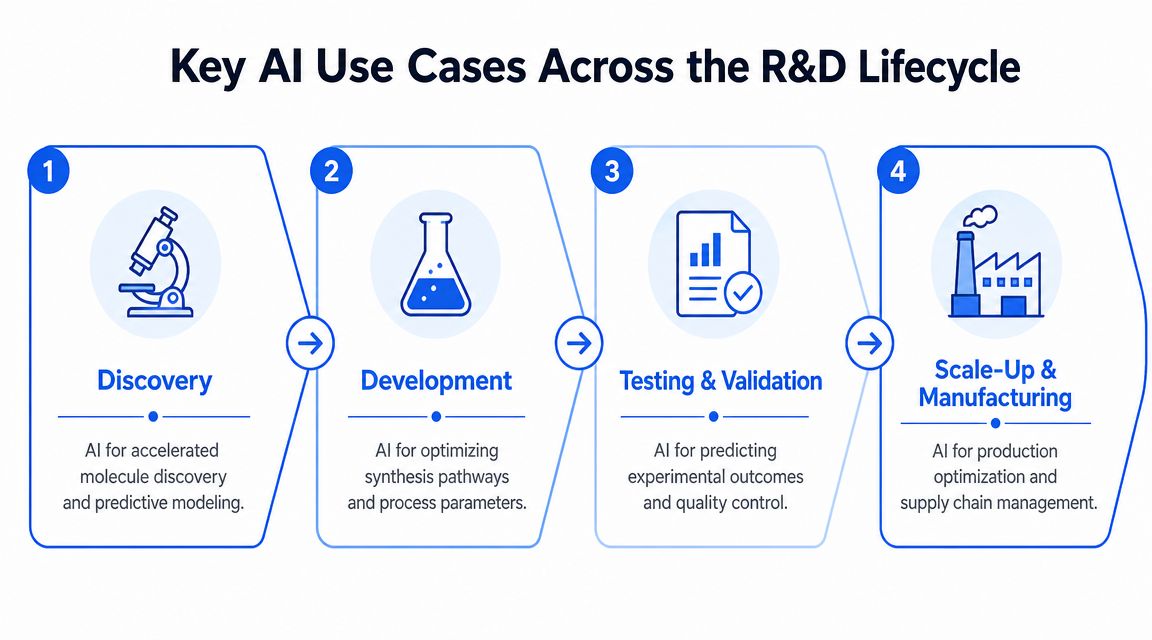
Key AI Use Cases Across the R&D Lifecycle
The fastest way to understand ai chemicals is to follow a product through the lifecycle. Start with a target. Maybe it's a coating that needs better durability, a polymer blend that needs tighter thermal behavior, or a specialty formulation that has to survive scale-up without drifting off spec.
At each stage, AI helps for a different reason.
Discovery and candidate generation
In early discovery, the problem is search space. There are too many possible structures, ingredient combinations, and pathways to evaluate manually. Generative and ranking models provide the most assistance.
McKinsey notes that generative AI can accelerate materials or molecule discovery two- to threefold when models propose and optimize net-new chemistries for target properties in a closed-loop discovery cycle, as described in McKinsey's analysis of AI in chemicals. The key phrase there is closed loop. The model proposes candidates, experiments test a subset, results feed back, and the next round gets sharper.
That changes the role of the lab. Instead of brute-force searching, the lab runs the most informative experiments first.
A useful mental model:
- Traditional discovery: throw more darts at a very large board.
- AI-guided discovery: shrink the board before throwing.
Later in the workflow, this kind of explanation can be easier to see in action:
Formulation and experiment planning
Formulation work is where many teams get immediate traction. The chemistry is often constrained enough to model, and the business value is easy to recognize.
A formulator might need to balance hardness, adhesion, cure behavior, and cost in the same system. AI can rank combinations that are more likely to land inside that performance window before the bench team starts mixing. It can also suggest where to sample the formulation space next, especially when prior runs already show which regions fail.
The best formulation models don't tell chemists to trust the machine. They tell chemists where not to waste a week.
This is also where unstructured data matters. A model may learn from the numbers in the table, but the comments often explain why a formula failed. Foaming during mixing. Unexpected incompatibility after storage. Visual defects that never made it into a formal field.
Process and scale-up decisions
AI becomes even more practical when development moves closer to production. The target isn't novelty anymore. It's reliability.
Here are three places where teams use it well:
- Synthesis and process tuning: Models can identify operating regions associated with better yield, stability, or consistency.
- Testing and quality review: Pattern recognition can flag runs that look likely to drift off spec before problems become obvious.
- Scale-up risk assessment: Teams can compare lab and pilot behavior, then estimate which variables are most likely to break when the process gets larger.
One underused application sits outside the factory. Recent University of Birmingham research showed AI can identify combinations of chemicals in rivers that may be harmful to aquatic life even at low concentrations, as covered in this report on AI-driven mixture toxicity detection. That matters because chemical risk rarely appears as a single clean substance in practice. Mixtures are the rule.
So the full value of ai chemicals isn't only speed. It's better decisions across discovery, formulation, manufacturing, and environmental screening.
Building Your AI-Ready Data Foundation
Most leaders know data is the issue. They also overestimate what “ready” means.
If you wait for perfectly standardized data across every lab, plant, business unit, and legacy repository, you won't start. In chemicals, that delay is usually more expensive than imperfect data. The practical goal is not perfection. It's a usable backbone that lets one priority workflow run better than it does today.
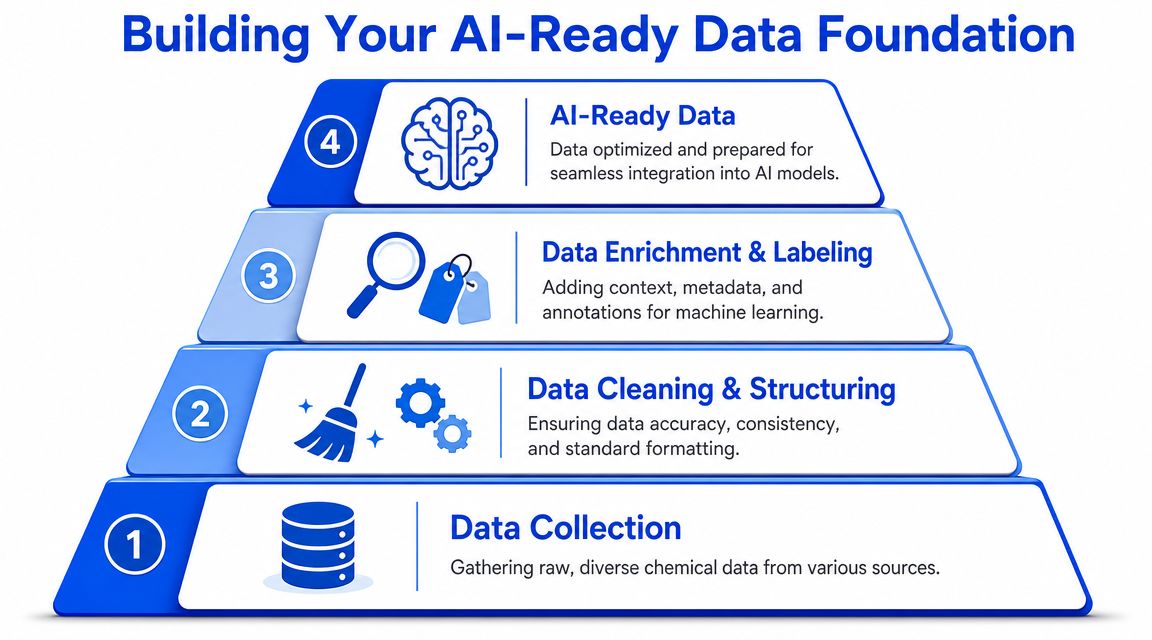
What AI-ready data looks like in practice
AI-ready data in a chemical organization usually combines four layers:
Experimental results
Compositions, conditions, test methods, measured properties, and batch outcomes.Context and metadata
Who ran it, which instrument was used, which protocol version applied, and what changed between runs.Unstructured scientific records
Lab notes, specification sheets, technical reports, patents, and troubleshooting comments.Operational signals
Process variables, quality events, and scale-up observations that connect bench work to production reality.
The issue isn't only storage. It's alignment. If one team records a raw material by trade name, another by internal code, and a third by shorthand in a spreadsheet comment, the model can't easily see those as the same thing without cleanup and mapping.
How to start without rebuilding everything
A better approach is selective unification. Pick one use case with visible waste. Then gather the minimum useful dataset around it.
For example:
- If formulation is slow: centralize historical recipes, property data, and bench comments.
- If scale-up fails too often: connect lab conditions, pilot runs, and off-spec production events.
- If knowledge keeps disappearing: extract old reports and notebooks into a searchable, tagged repository.
Tooling provides valuable assistance. Teams that need to pull structured information from fragmented scientific documents often look at products like Ekipa AI's data engine, which is designed for AI-powered data extraction from messy enterprise records. The value isn't automation for its own sake. It's getting buried technical knowledge into a form models and scientists can both use.
A short decision table can keep the effort honest:
| Situation | Bad move | Better move |
|---|---|---|
| Scattered legacy files | Launch a multi-year master data overhaul | Normalize the records needed for one high-value workflow |
| Mixed-quality historical data | Throw it all into a model untouched | Curate a narrower dataset with clear test lineage |
| Unstructured reports | Ignore them because they're hard to use | Extract key entities, conditions, and observations |
Field note: The first data backbone should support a business decision, not a dashboard.
For organizations trying to centralize fragmented experimental records, Polymerize Connect is one example of a data backbone built for this problem. It brings data from spreadsheets, ELNs, and silos into a unified foundation that scientists can work from. That's the kind of architecture that makes ai chemicals usable at the bench, not just visible in a presentation.
From Black Box to Glass Box Model Explainability
Scientists don't reject AI because they dislike automation. They reject recommendations they can't interrogate.
If a model says “increase additive A” or “avoid candidate B,” a chemist wants to know why. Which variables mattered most. How confident the model is. Whether the recommendation comes from a meaningful precedent or a thin statistical guess. That's the difference between a black box and a glass box.
What scientists need from an AI recommendation
A trustworthy model should show more than an output. In practice, teams usually need some combination of these signals:
- Driver visibility: which ingredients, conditions, or descriptors pushed the prediction most strongly.
- Confidence or uncertainty: whether the model is speaking from dense precedent or sparse evidence.
- Similarity to prior work: whether the recommendation resembles experiments the organization has already run.
- Boundary awareness: where the model is extrapolating beyond known chemistry or process space.
That last point matters a lot. Many failed pilots happen because teams apply a model far outside the data it learned from, then blame “AI” when the recommendation collapses. The problem wasn't intelligence. It was scope.
Where explainability helps and where it does not
Explainability is useful, but it isn't magic either.
| Explainability helps when | Explainability does not fix |
|---|---|
| Scientists need to validate a recommendation against chemistry intuition | Poorly measured training data |
| Teams must defend decisions across R&D, quality, and operations | Vague target definitions |
| A model ranks candidates and needs to justify prioritization | Missing experimental lineage |
| A pilot needs user trust to drive adoption | A dataset that never captured failure modes |
A practical example: if a model recommends increasing a stabilizer because similar historical formulations showed improved thermal behavior under related conditions, that's useful. If it also flags that confidence is moderate because the current composition sits near the edge of prior data, that's even better. The scientist can act with caution instead of false certainty.
Trust grows when the model can say, in effect, “Here's my recommendation, here's what it depends on, and here's where I might be wrong.”
This is why domain-specific systems tend to outperform generic AI interfaces in chemical settings. They're built to connect recommendations to experimental context. Polymerize Labs is one example of that design choice, using explainable models with confidence scores and historical precedents so scientists can inspect the reasoning rather than treat the output as an oracle.
The adoption lesson is simple. Don't ask whether a model is explainable in the abstract. Ask whether a chemist can use its explanation to choose the next experiment with more confidence and less wasted effort.
Implementing AI and Measuring Your Return on Innovation
Most AI programs in chemicals stall for one reason. They start with a platform decision before they define the scientific or business problem.
That sequence is backwards. A useful implementation starts with a bottleneck that already costs time, scrap, delay, or uncertainty. Then the team builds enough data flow and model support to improve that bottleneck. After that, it scales.
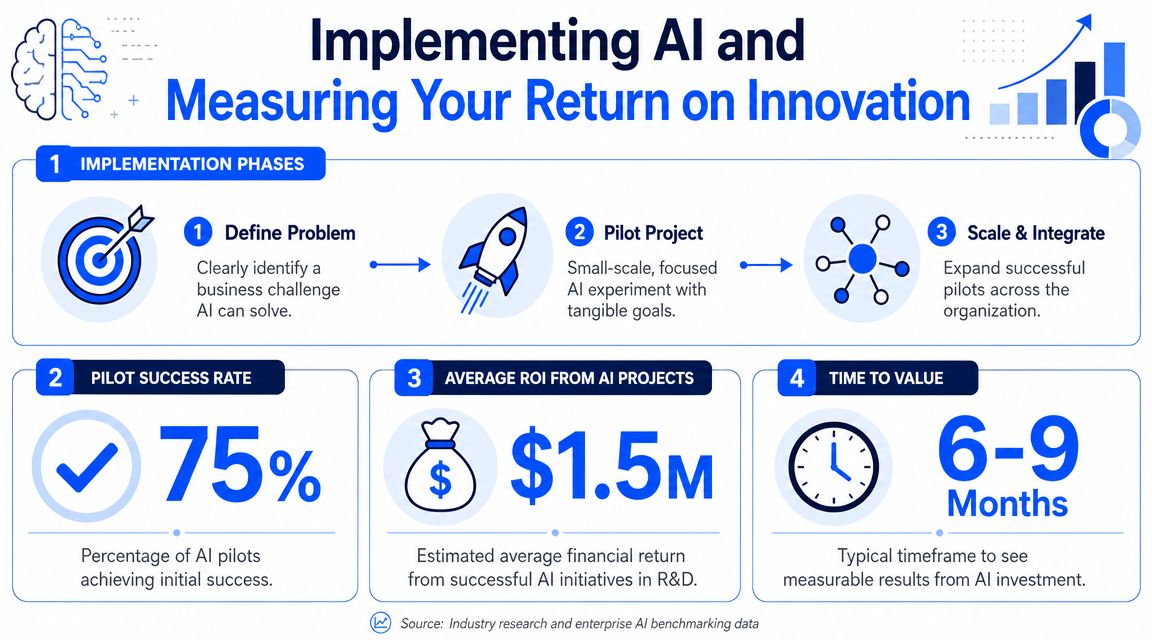
Start with one problem that matters
The strongest first projects usually have four traits. They matter commercially. Scientists feel the pain already. Historical data exists, even if imperfect. And the outcome can be measured within a reasonable operating cycle.
Good first targets often include:
- Formulation optimization: reduce the number of bench iterations needed to hit a target profile.
- Process stability: identify settings linked to downtime, drift, or energy waste.
- Quality prediction: detect which combinations of conditions tend to create off-spec outcomes.
- Scale-up planning: estimate where lab success is most likely to break in pilot or manufacturing.
IBM's analysis shows the sector is already beyond isolated experiments. 76% of chemicals executives are using AI to optimize production processes, and roughly half are using it for real-time process control and optimization, quality inspection, and production planning and scheduling, according to IBM's report on chemicals in the AI era. The same report says AI-powered automation for chemical formulation R&D is projected to rise from 31% in 2025 to 95% by 2028. That's a strong signal that the implementation question is no longer “if.” It's “where first.”
Measure operational value and innovation value
R&D leaders often undermine their own case by measuring only cost takeout. In chemical innovation, the more useful frame is return on innovation.
That means tracking metrics such as:
- Cycle time reduction: how much faster a team moves from hypothesis to validated result.
- Experiment efficiency: whether fewer runs are needed to find a viable candidate.
- Scale-up readiness: whether handoff from lab to plant becomes more predictable.
- Operational impact: whether the downstream plant sees fewer disruptions tied to development choices.
IBM reports measurable gains from current AI deployments in chemicals, including a 20% reduction in R&D cycle time, a 24% decrease in plant downtime, and a 14% reduction in energy use, all in the same IBM chemicals AI analysis. Those numbers are useful as directional benchmarks, but each team still needs its own baseline. A pilot only proves value if you can compare before and after on a real workflow.
Build or buy is usually the wrong first debate
Many companies waste months deciding whether to build a custom AI stack from scratch. In most cases, the better question is which parts must be custom and which can come from a platform with the right controls.
For enterprise chemical programs, controls matter as much as model quality:
- IP protection: role-based access and clear data segregation
- Compliance alignment: support for internal governance and privacy obligations
- Auditability: the ability to trace model inputs, outputs, and decisions
- Workflow fit: integration with how scientists and engineers already work
Platforms built for enterprise R&D can shorten the path because they package data handling, security, and domain workflows together. Polymerize, for example, provides ISO 27001 and SOC 2 controls along with role-based access and GDPR/CCPA compliance. That kind of setup doesn't guarantee value, but it removes a class of adoption friction that can sink a pilot before the science is tested.
The Future is Accelerated Real-World Success Stories
The future of ai chemicals won't be defined by flashy demos. It will be defined by teams that can move from question to answer with less waste in the middle.
The pattern is already clear. One team uses AI to rank candidates before synthesis, so scientists spend bench time on the most informative experiments. Another connects formulation records to production feedback, so scale-up stops feeling like a reset. Another uses explainable models to justify ingredient changes, making it easier for R&D, quality, and manufacturing to agree on what to test next.
Here's what that looks like in practice, without pretending every organization starts from the same maturity level:
- A specialty materials group uses AI-guided experiment planning to stop repeating low-value variants and focus on formulations near the target window.
- A process team links plant data with development history and spots which conditions consistently precede instability or downtime.
- An environmental screening program applies AI to mixture effects, not just single-compound hazard review, and gets a more realistic view of exposure risk.
None of those wins require a fully autonomous lab. They require a narrower and more disciplined shift. Better data plumbing. Models that show their work. Metrics tied to scientific throughput, not just software usage.
The practical promise of AI in chemicals is simple. Fewer blind alleys, faster learning, and a shorter path from lab insight to production confidence.
If you're evaluating vendors or partners, don't let the conversation stay at the level of dashboards and demos. Review security, integration burden, explainability, model scope, and ownership of outcomes. A useful starting point is this guidance for AI vendor selection from CTO Input, especially for teams that need procurement discipline without slowing innovation to a crawl.
The organizations that gain the most from ai chemicals won't be the ones with the loudest AI strategy. They'll be the ones that pick one high-value workflow, build a usable data backbone, insist on explainability, and measure whether scientists reach answers faster.
If you're trying to reduce failed experiments, connect fragmented R&D data, and move formulations from concept to production with more confidence, Polymerize is worth evaluating. It combines a centralized data backbone, explainable domain-specific models, and enterprise controls in a workflow built for materials and chemical R&D rather than generic AI use.

