A formulation scientist pulls tensile data from one spreadsheet, rheology data from an ELN export, and thermal results from a legacy instrument database. The columns look familiar until they don't. One file uses “Temp,” another uses “Temperature_C,” a third stores values as text with unit strings attached. Sample IDs almost match, except for the projects where a site code was added halfway through the year.
That's the point where many materials R&D teams discover they don't have an AI problem. They have a data harmonization problem.
In polymers, coatings, adhesives, composites, battery materials, and specialty chemicals, the science is already hard. The data environment often makes it harder. Experimental context lives in notebook entries, test methods differ across labs, formulations are described with inconsistent ingredient names, and process conditions get captured at different levels of detail. If you want predictive models that connect chemistry, process, structure, and performance, harmonization is the bridge between scattered records and something a scientist can trust.
Table of Contents
The Data Dilemma in Modern Materials R&D
In materials and formulation work, the same experiment rarely appears the same way twice. A viscosity sweep from one lab may be saved as a clean table with shear rate and viscosity columns. Another team may attach the raw export as a CSV with instrument field names only a specialist understands. A third may summarize the result in a slide deck and omit the conditions that matter.
That fragmentation shows up everywhere. Polymer names drift between shorthand, trade names, and internal aliases. Fillers get recorded by supplier grade in one project and by chemistry class in another. One DSC run includes heating rate and atmosphere. Another stores only the transition temperature. Scientists can still interpret each record locally, but cross-project analysis starts to fail.
The result is familiar. Teams trying to build a formulation recommender or a property prediction model spend more time reconciling data than learning from it. Historical experiments exist, but they aren't comparable enough to reuse with confidence. Scientists end up rerunning work they've effectively already done because finding the right precedent takes too long.
Where the pain becomes strategic
This isn't just an informatics annoyance. It directly affects how fast a lab can move from hypothesis to validated result.
If your binder content is recorded one way in coatings data, another way in adhesive data, and a third way in pilot-scale records, you can't reliably connect formulation choices to outcomes. If processing conditions aren't aligned with test results, you can't separate chemistry effects from manufacturing effects. And if metadata is incomplete, your machine learning model won't know whether it's learning physics or noise.
Practical rule: In materials R&D, every useful model depends on context. A property value without formulation, process, method, and sample identity is usually just an isolated number.
Data harmonization is the discipline that turns those isolated numbers back into usable scientific evidence. Done well, it creates a shared experimental language across teams, instruments, and time periods. That's what makes retrospective learning possible.
What Is Data Harmonization for Scientists
For scientists, data harmonization is best understood as a universal lab notebook grammar. It doesn't erase differences between experiments. It makes those differences explicit and comparable, so datasets collected in different ways can still be pooled and analyzed together.
Historically, harmonization emerged because researchers and public-sector statisticians needed to combine heterogeneous datasets from different studies or systems. In cohort research, it is framed as improving comparability across variables so data collected in different ways can be pooled for combined analysis, reducing heterogeneity across sources. UK government guidance also ties harmonisation to recognized standards and consistency requirements in official statistics, which is why the idea sits as much in research governance as in data engineering, as described in this foundational overview of harmonisation in research and statistics.
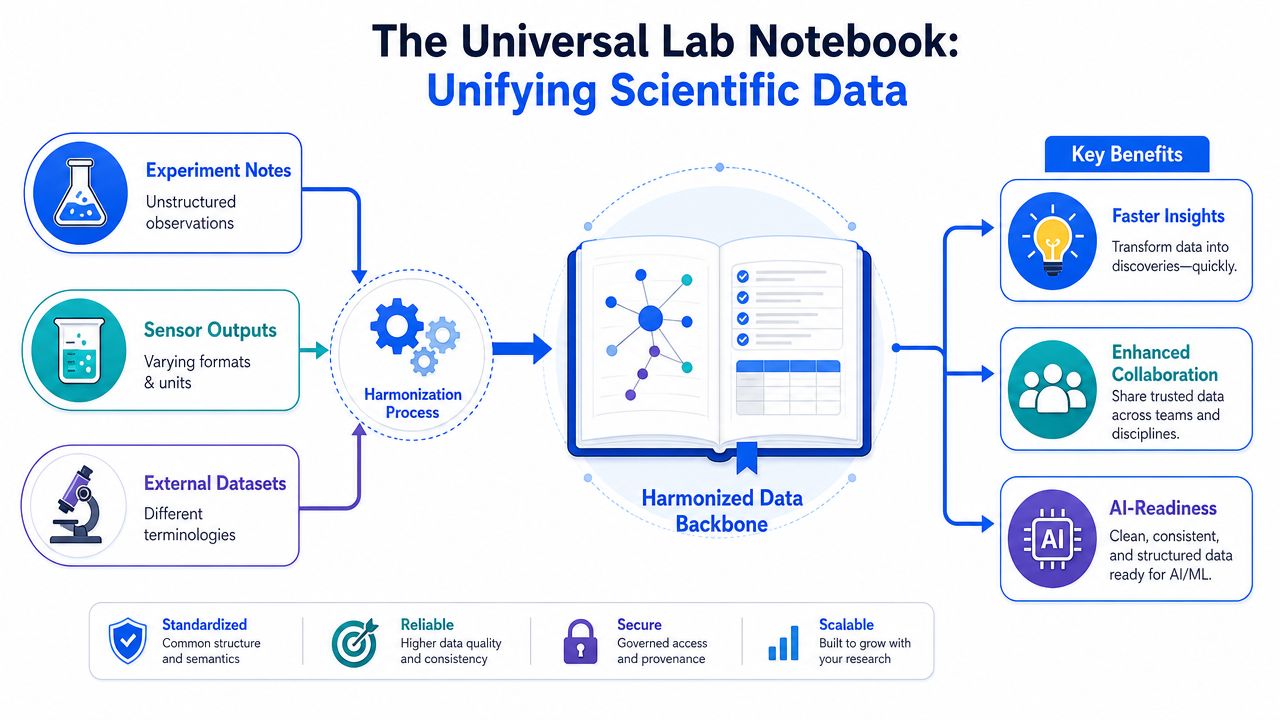
A common grammar for experimental data
In a chemistry lab, that grammar usually has four jobs.
- Align names: “Temp,” “Temperature_C,” and “oven setpoint” may all need to resolve to a defined field with a clear meaning.
- Align units: MPa and psi can both be valid, but they can't remain mixed if you want model-ready property tables.
- Align concepts: “polymer additive,” “processing aid,” and a supplier-specific ingredient description may need to map to the same ontology class or controlled vocabulary.
- Align context: The result isn't only the measured value. It includes method, operator, instrument, formulation composition, processing conditions, and sample lineage.
What actually gets harmonized
Scientists sometimes hear “harmonization” and assume it means flattening all data into one giant sheet. That's not the goal. The goal is to make data from different origins interpretable within a coherent framework.
For materials teams, the practical targets usually include:
| Harmonization target | What it means in the lab |
|---|---|
| Variable definitions | Defining whether “modulus” means tensile modulus, storage modulus, or a project-specific surrogate |
| Sample identity | Connecting formulation batch, specimen, and test result without ambiguity |
| Measurement conditions | Preserving temperature, humidity, cure profile, shear history, and method settings |
| Material classification | Standardizing how resins, additives, solvents, fillers, and substrates are described |
| Metadata completeness | Capturing enough context for reuse, traceability, and downstream modeling |
Harmonization doesn't make different experiments identical. It makes them comparable without pretending they were the same experiment.
That distinction matters. If two coating studies used different gloss methods or different cure schedules, harmonization should preserve that fact. Good harmonization increases comparability while protecting scientific meaning.
Why Harmonization Is a Non-Negotiable for AI in R&D
Most AI projects in R&D don't break because the algorithm is weak. They break because the training data mixes incompatible meanings, missing context, and inconsistent structure.

A model that predicts tensile strength from formulation inputs needs more than a target column. It needs confidence that ingredient identities are resolved consistently, process conditions are represented the same way across projects, and test outputs mean the same thing each time. Without that, the model can still fit patterns. They just won't be patterns you should trust.
AI fails first at the data layer
Harmonization becomes essential, no longer merely “helpful”. AI in the lab depends on comparability. If one team records solids loading by weight percent, another uses phr, and a third stores free-text composition notes, you don't have a coherent feature set. You have disconnected fragments.
That cost is operational as much as scientific. A harmonization engine described by Elucidata reports ~24x faster downstream analysis, 99.99% metadata annotation accuracy, 30+ metadata fields added per dataset, and around 50 QA/QC checks during processing in an early-stage R&D setting, according to Elucidata's discussion of data harmonization for analysis-ready R&D workflows. Those figures are a useful reminder that harmonization isn't only about cleanliness. It changes how much time teams can spend interpreting results instead of preparing them.
Why this changes lab velocity
In materials development, speed comes from reuse. You want to learn from failed formulations, noisy pilot runs, borderline candidates, and historical edge cases. Harmonized data makes that possible because it lets scientists ask questions across programs rather than inside one project folder.
Three outcomes matter most:
- Model reliability: Predictive models become easier to audit because the inputs and outputs have clear definitions.
- Historical learning: Teams can compare old and new experiments without manually decoding every archive.
- Experimental efficiency: Scientists spend less effort rebuilding datasets and more effort designing the next experiment.
A short primer on the broader AI context can help align the team before implementation:
If your lab wants explainable AI, start by making the data explainable to another scientist.
That's the threshold. Before an AI model can explain a formulation recommendation, the underlying records have to explain themselves.
Common Approaches to Harmonizing R&D Data
There isn't one correct architecture for every lab. The right approach depends on the diversity of your data, the maturity of your systems, and how much scientific nuance you need to preserve. What does hold across environments is the sequence.
A technically sound workflow starts by profiling each source for structure and content, then mapping every field into a common data model before transformation and validation, because semantic mismatches and schema drift are the main causes of downstream inconsistency, as outlined in Lifebit's review of data harmonization workflow design.
Start with profiling, not transformation
Teams often jump straight into ETL. That's usually a mistake in R&D.
Before you transform anything, profile the source. Check null patterns, duplicate behavior, identifier logic, data types, controlled terms, and the distribution of key fields. In materials datasets, this quickly reveals where the core ambiguity lies. Sometimes the problem isn't unit conversion. It's that “sample” means formulation in one system and molded coupon in another.
A practical profiling pass should answer:
- What is the entity? Raw material, formulation batch, test specimen, process run, or finished sample.
- What is the measurement? Property, observation, intermediate signal, or instrument output.
- What is the context? Method, conditions, equipment, and version of the procedure.
- What is the key? Which identifiers allow traceability across systems.
Methods that actually fit lab environments
Different harmonization methods solve different problems. In most organizations, you'll combine several.
| Approach | Core Mechanism | Best For... | R&D Example | Complexity |
|---|---|---|---|---|
| Schema mapping | Direct field-to-field alignment between source and target | Structured datasets with stable columns | Mapping ELN export fields into a standard formulation table | Low to moderate |
| Ontology alignment | Mapping terms by meaning, not just label | Ingredient classes, material taxonomies, test methods | Resolving supplier-grade names into shared additive classes | Moderate to high |
| Common data model | Defining a canonical structure for recurring entities | Enterprise-scale reuse across projects | Standard tables for formulations, process steps, and properties | High |
| ETL or ELT pipelines | Automating extraction, transformation, and loading | Repeated ingestion from multiple systems | Pulling instrument exports and ELN records into a governed backbone | Moderate to high |
| Semantic enrichment | Adding metadata that wasn't explicit in the source | Sparse historical data and AI-readiness | Tagging experiments with material family, end use, or processing route | Moderate |
What works well in materials R&D is usually a layered pattern:
- Use schema mapping for well-behaved tabular data.
- Add ontology alignment where scientific meaning varies by team or supplier.
- Anchor the result in a common data model so future projects don't restart from scratch.
- Apply semantic enrichment to capture the context needed for modeling.
One useful adjacent tool for enterprise datasets is a naics classification api when external commercial or supplier data needs to be aligned by industry category before it enters the broader R&D data environment. That isn't core lab harmonization, but it can reduce manual classification work in cross-functional programs.
What usually doesn't work is trying to solve everything with a giant one-time migration. Lab data keeps changing. New test methods appear, naming conventions drift, and projects invent fields no one anticipated. Harmonization has to operate as a maintained capability, not a cleanup event.
Overcoming Technical and Organizational Challenges
The hard part of data harmonization isn't only the data. It's the collision between evolving science, local lab habits, and enterprise expectations.
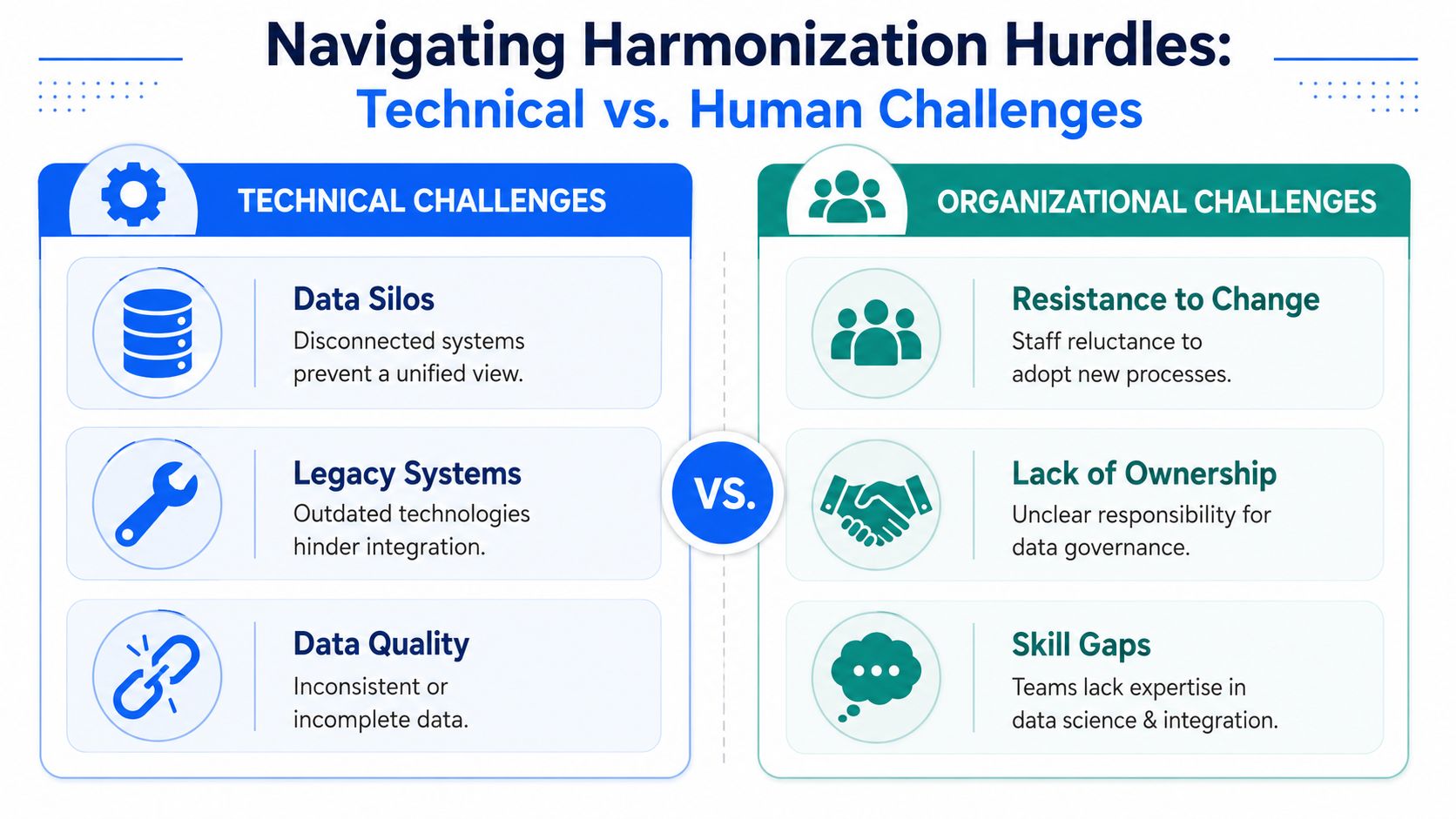
A microscopy image, a spectral curve, and a formulation table don't fit naturally into the same processing pattern. Nor should they. The challenge is connecting them through shared identifiers, metadata, and lineage without stripping away the detail that makes them scientifically useful.
The technical problems are usually obvious
Scientists recognize the visible issues quickly. Legacy systems export inconsistent formats. Instrument software changes field names after an update. Different sites use different method templates. Historical data often arrives with sparse metadata and no clear ownership.
In materials R&D, three technical trouble spots come up repeatedly:
- Complex modalities: Spectra, images, and time-series signals need links to the tabular context around them.
- Schema drift: Experimental methods evolve faster than enterprise schemas.
- Lineage gaps: Teams can't always trace a property result back to the exact formulation, process path, and test protocol.
These are manageable problems if the data model preserves provenance and versioning from the start.
The harder problems sit with ownership and incentives
The bigger friction is organizational. Scientists will support harmonization when it helps them interpret data faster. They resist when it feels like extra documentation for someone else's dashboard.
That's why governance has to be practical. Someone needs authority over ingredient vocabularies, sample identifiers, test method definitions, and metadata requirements. But that authority can't live only in central IT. It has to include the scientists who understand what a field means.
A broken ontology is usually a broken conversation between domains, not a broken piece of software.
There's also a deeper architectural question. Should every dataset be merged into one master repository? Not always. Recent guidance emphasizes that harmonization can happen without physically combining all data, and warns that forced consolidation can create false equivalences when datasets measure different concepts. In many settings, the better question is what should remain source-native and only be harmonized at query time, as discussed in this review of retrospective and federated harmonization approaches.
That federated mindset is often a better fit for large materials organizations. It preserves local control, protects provenance, and avoids flattening distinct experimental contexts into misleading sameness. If one site measures abrasion resistance using a different protocol, the system should expose the difference, not hide it.
An Implementation Roadmap for Your AI-Ready Data Backbone
Most harmonization programs stall because they start too broadly. A better pattern is to treat the backbone as a product with phases, owners, and narrow early wins.
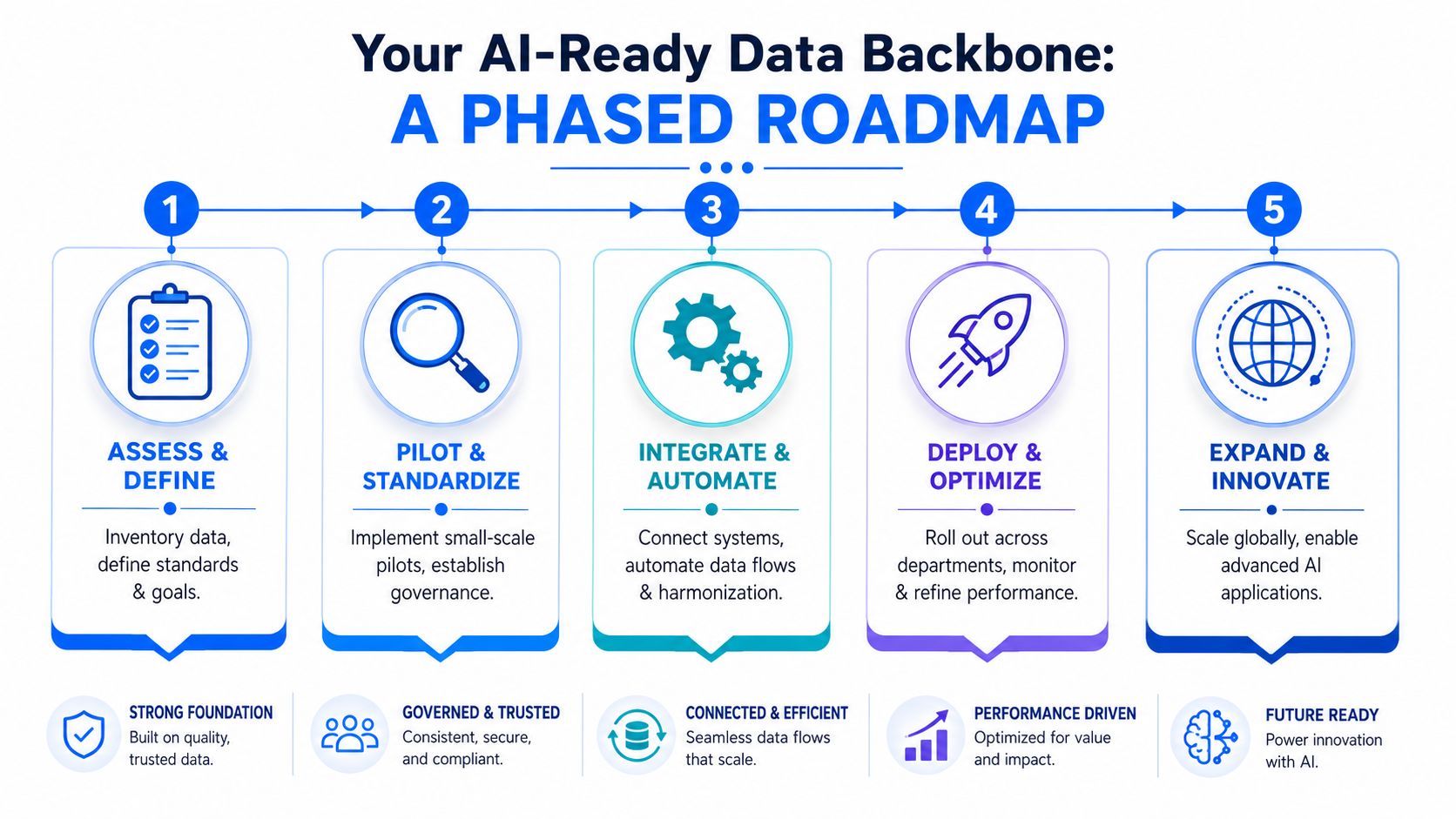
Phase 1 and Phase 2
Start with one high-value experimental stream. In a formulation lab, that might be rheology for a single product family, tensile and DSC for a polymer platform, or dispersion stability for one coatings line. Pick a use case where scientists already feel the pain and where better comparability would change actual decisions.
Then define the minimum viable common model. Don't aim for every data type in the lab. Focus on the entities needed for that pilot: materials, formulations, process steps, samples, methods, and results.
A useful early checklist looks like this:
- Choose one decision problem: For example, ranking candidate formulations or predicting a target property.
- Inventory data sources: Spreadsheets, ELN exports, LIMS records, instrument files, and shared drives.
- Define controlled terms: Ingredient names, units, test methods, and sample identifiers.
- Set governance early: Decide who approves schema changes and vocabulary updates.
At this stage, metadata discipline matters as much as the tables themselves. Teams that want to streamline content workflow with metadata often find the same principle applies in R&D. If metadata rules are vague, reuse collapses quickly.
Phase 3 and beyond
Once the pilot proves useful, scale by standardizing repeatable patterns rather than cloning bespoke pipelines. Build reusable mappings for common test types. Create versioned dictionaries for ingredients and methods. Integrate with ELNs, LIMS, and instrument exports so harmonization starts closer to data capture.
This is also where tools matter. Some teams build a modular stack around a data lakehouse, transformation layer, ontology service, and governed analytics environment. Others use specialized R&D platforms. For example, Polymerize is one option for materials teams that need to unify experimental data across spreadsheets, ELNs, and silos into a centralized backbone for AI workflows. The right choice depends on your architecture, security requirements, and how intricately you need to model scientific entities.
A mature roadmap should also include:
- Role-based access control so proprietary formulations and sensitive programs stay partitioned.
- Compliance design for frameworks such as ISO 27001 and privacy obligations such as GDPR where relevant.
- Change management so schema evolution doesn't break downstream models.
- Model feedback loops that capture which harmonized fields improve prediction and decision-making.
Build the backbone for the decisions scientists make every week, not for an abstract ideal of perfect enterprise data.
That's how harmonization becomes durable. It earns adoption by improving experimental work, not by demanding faith in a future platform.
Data Harmonization in Action Real-World Use Cases
A global polymer team wants to compare tensile behavior across sites. One lab reports modulus in one unit system, another stores operator comments in the result field, and a third tracks specimen conditioning in a separate workbook. Harmonization connects formulation, molding conditions, conditioning history, and test output into one comparable structure. Once that happens, scientists can separate material effects from preparation effects and stop treating each site's history as isolated.
A specialty chemicals group has decades of formulation work trapped in spreadsheets and newer work captured in an ELN. On paper, they have a rich archive. In practice, ingredient names changed over time, solvents were grouped inconsistently, and pass-fail comments replaced measured performance in many records. Harmonization doesn't magically fix every gap, but it creates enough consistency to surface clusters of related experiments and identify where older work can still inform current programs.
An advanced materials startup links microscopy outputs with process settings and final property measurements. Before harmonization, the image data lived in one environment, processing notes in another, and performance data in analyst-curated files. After alignment, the team can ask a more valuable question: which process changes tend to produce the microstructures associated with the target property profile?
These aren't edge cases. They're normal materials R&D situations. The labs that learn fastest usually aren't the ones generating the most data. They're the ones making past data reusable.
If your team is trying to turn fragmented formulation and materials data into an AI-ready backbone, Polymerize is built for that exact operating environment. It helps R&D organizations connect spreadsheets, ELNs, and siloed experimental records into a structured foundation that scientists can use for prediction, optimization, and next-experiment planning.

