A familiar pattern plays out in chemical R&D every quarter. A team has years of formulation notes, pilot results, plant deviations, and characterization data. None of it lives in one place. Some sits in spreadsheets with cryptic column names, some in ELNs, some in instrument exports, and some in the heads of senior scientists who know which experiments “almost worked.”
Then leadership asks for faster iteration, fewer failed runs, and more confidence before scale-up.
That's the moment when trial and error stops being a scientific method and starts becoming an operating problem. The bottleneck usually isn't a lack of ideas. It's the inability to connect historical evidence, process knowledge, and predictive models in a way scientists can trust. Chemical process optimization software matters because it changes that operating model. Instead of running broad experimental campaigns and hoping patterns emerge, teams can narrow the search space, test better hypotheses, and carry stronger process understanding into development and manufacturing.
The technology is powerful. Adoption is where most programs succeed or fail. The companies that get value from it usually do three things well: they unify messy data early, they insist on explainable outputs instead of black-box recommendations, and they choose software that matches the physics and process mode of their business.
Table of Contents
- Introduction From Trial and Error to Targeted Innovation
- More than simulation
- Why this category matters now
- Predictive models that create a usable process memory
- AI optimization that searches where scientists would actually search next
- Experiment planning that improves learning velocity
- Unified data integration that fixes the hidden bottleneck
- Explainable AI that earns scientist trust
Introduction From Trial and Error to Targeted Innovation
In most labs, the official process looks disciplined. Design an experiment, run it, measure the output, record the result, repeat. The actual process is messier. Conditions drift. Raw materials vary. Operators annotate exceptions in free text. One team tracks viscosity one way, another uses a different naming convention, and a third stores key context in slide decks no model will ever read without help.
That's why many R&D groups feel data-rich and insight-poor at the same time.
Chemical process optimization software changes the conversation when it's treated as a decision system rather than a modeling accessory. It can connect thermodynamics, kinetics, historical runs, and operating constraints into a practical workflow for choosing what to run next and what to stop running. For a CTO, that matters because wasted experiments aren't just lab costs. They cascade into delayed scale-up, weak technical transfer, and slower product commercialization.
Practical rule: If your scientists still spend more time assembling past results than evaluating the next experiment, the problem isn't only experimentation. It's infrastructure.
The shift is strategic because it moves R&D from retrospective reporting to targeted innovation. Teams stop asking, “What happened in the last campaign?” and start asking, “Given what we know, which variables are most likely to move yield, purity, stability, or cycle time?”
That doesn't mean software replaces scientific judgment. It means scientists finally get a system that can hold more history, more interactions, and more constraints than any single expert can keep in working memory. In practice, the best deployments feel less like automation and more like giving every technical team a shared process memory with predictive guidance layered on top.
What Is Chemical Process Optimization Software
Chemical process optimization software is best understood as a GPS for chemical R&D and process development. A basic map tells you where things are. A GPS goes further. It uses current conditions, known constraints, and destination priorities to recommend a route. Good optimization software does the same for experiments and process decisions.
It ingests process data, experimental outcomes, material properties, and engineering models. Then it helps teams simulate likely outcomes, identify bottlenecks, and recommend where to focus effort. Legacy simulation tools often stop at “what if.” Modern optimization environments push toward “what next” and “why this recommendation.”
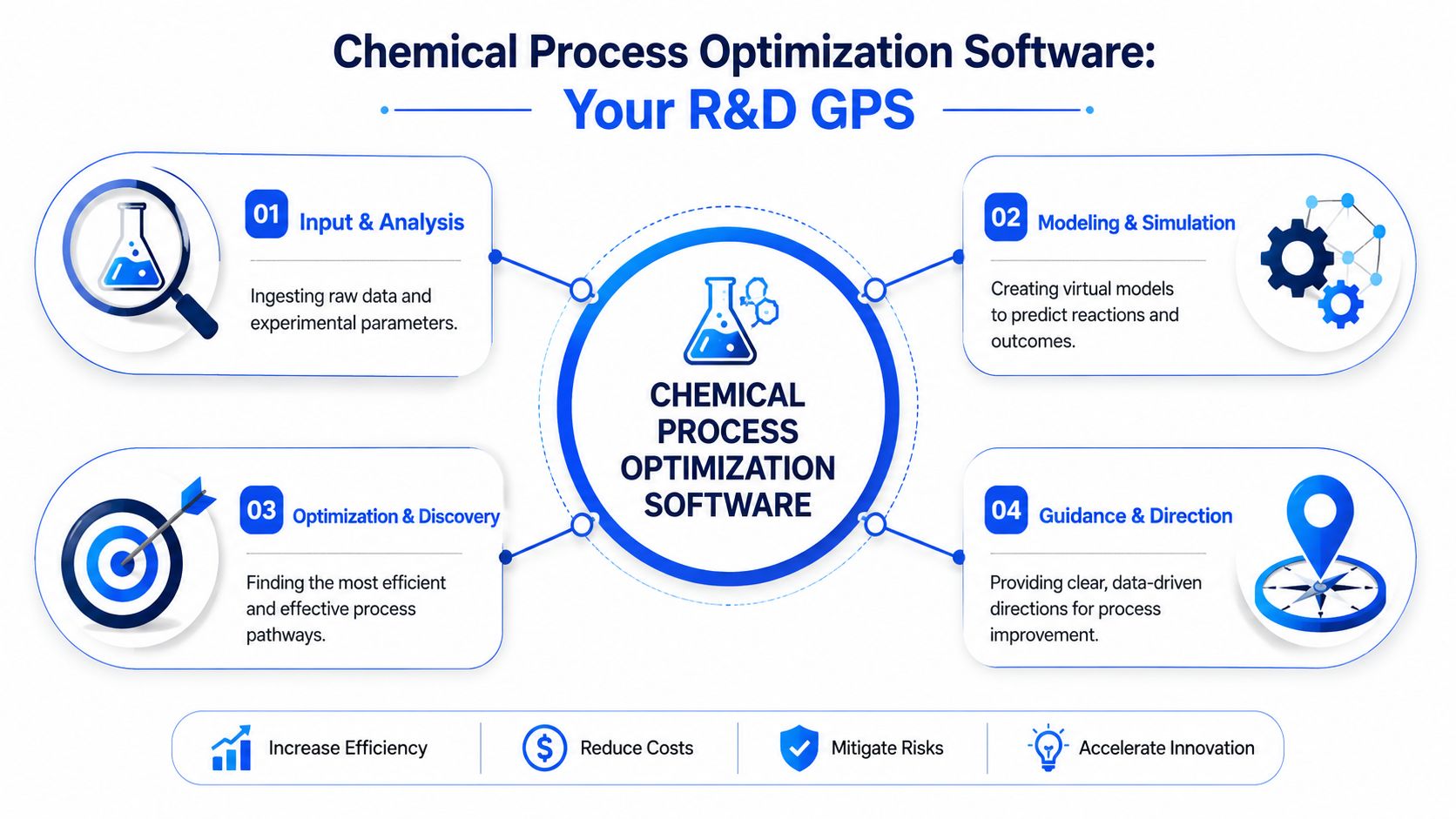
More than simulation
Simulation remains the foundation. The chemical process simulation software market was valued at USD 1.2 billion in 2024 and is projected to reach USD 2.5 billion by 2033, with a CAGR of 8.8% from 2026 to 2033. That matters because it shows this category isn't experimental shelfware. It's becoming core infrastructure for organizations that need to model and optimize complex operations.
But there's an important distinction between simulation and optimization.
| Type | Primary question | Common limitation |
|---|---|---|
| Traditional simulation | What happens if I change these inputs? | Often depends on an expert user to interpret and iterate manually |
| Optimization software | Which combination of variables is most likely to achieve the target under real constraints? | Fails if data quality, integration, or trust is weak |
The strongest platforms combine several layers:
- First-principles modeling: Thermodynamics, mass balances, energy balances, and kinetics.
- Data-driven learning: Pattern recognition from historical experiments and plant data.
- Decision support: Ranking the next best experiment or operating window.
- Enterprise integration: Pulling context from multiple systems rather than one clean sandbox.
Why this category matters now
The recent interest isn't hype alone. Chemical manufacturers are under pressure to reduce waste, shorten development cycles, and carry better process understanding from bench to plant. Optimization software helps because it turns fragmented evidence into structured guidance.
A useful mental model is this: traditional software is a calculator. Chemical process optimization software is a copilot. It doesn't invent chemistry. It helps scientists and engineers see interaction effects, compare routes, and avoid dead ends sooner.
The value doesn't come from having an AI model. It comes from combining domain physics, historical evidence, and recommendation logic in a way technical teams will use every week.
Core Capabilities That Accelerate R&D
The fastest way to evaluate a platform is to ignore the feature grid and ask one question: does it help a scientist make a better next decision with imperfect data? That's the standard that matters.
Chemical process optimization software earns its place when it closes the gap between raw data, process understanding, and action. In sectors such as petrochemicals and polymers, these tools use rigorous thermodynamic models to identify bottlenecks and maximize efficiency before physical implementation, which can reduce energy consumption by 10 to 25% while maintaining product quality.
Here's what separates useful systems from expensive dashboards.
Predictive models that create a usable process memory
A predictive model is valuable when it captures relationships your team already suspects, plus a few interactions they haven't quantified yet. In practice, this often behaves like a digital memory for the lab. It connects temperature, residence time, catalyst loading, solvent choice, order of addition, and feed quality to outcomes such as conversion, particle size, viscosity, or purity.
That helps in two ways:
- It narrows search space: Teams stop screening everything and start screening what is plausible.
- It preserves learning: Past runs no longer disappear into project folders after a team changes or a program pauses.
For CTOs, this is one of the biggest hidden returns. Institutional knowledge becomes queryable rather than tribal.
AI optimization that searches where scientists would actually search next
A good optimization engine doesn't just maximize a single target. It balances competing objectives. Yield may improve while impurity risk rises. Throughput may increase while thermal margin shrinks. The software should surface those trade-offs clearly.
The easiest analogy is route planning. If your destination is “best product performance,” the system should still ask whether you care more about shortest time, lowest tolls, or safest roads. In process terms, that means selecting for the best achievable operating window under real limits, not an unrealistic mathematical optimum.
What doesn't work is a model that produces a recommendation with no path back to the drivers behind it. Scientists will reject it, and they should.
Experiment planning that improves learning velocity
Many teams still run experiments in the order that is most convenient, not most informative. That's understandable. Labs are busy. Instruments have queues. Material availability changes.
Optimization software improves this by proposing the next experiment that is most likely to reduce uncertainty, validate a hypothesis, or move a target property. That's where design of experiments becomes operational rather than academic. Instead of a static DoE created at project kickoff, teams can use adaptive planning as new results arrive.
What works in practice: Start with a bounded objective, a small set of controllable variables, and one decision the team already struggles to make consistently.
Unified data integration that fixes the hidden bottleneck
The hard part usually isn't model selection. It's data assembly.
Most organizations have the right ingredients in the wrong architecture. Process historians, ELNs, LIMS, spreadsheet trackers, pilot logs, and supplier COAs all describe the same reality from different angles. Until that data is reconciled, optimization stays fragile. Models train on partial context. Scientists spend time cleaning rather than learning. Leadership loses patience because the platform looks underused.
The best systems treat integration as part of the product, not a side project for IT. They map identifiers, normalize units, preserve provenance, and let teams trace a recommendation back to the underlying evidence.
Explainable AI that earns scientist trust
Explainable AI is not a nice-to-have in this category. It is the adoption layer.
A chemist or process engineer needs to know why the model prefers one region of the design space over another. That explanation might include feature importance, confidence intervals, nearest historical precedents, sensitivity views, or causal hypotheses. The exact method matters less than the result: a user can challenge, validate, and refine the recommendation.
Without explainability, the software behaves like a weather app that gives a storm warning with no radar, no map, and no indication of confidence. People won't change plans based on it.
With explainability, the interaction changes. Scientists can say, “The model is weighting solvent ratio heavily because similar runs failed outside this window,” and then decide whether that aligns with mechanism, scale-up constraints, and known plant behavior. That is how AI becomes a partner in R&D instead of a black box no one wants to own.
The Business Impact From Lab to Scale-Up
The business case becomes clear when you stop treating this software as a lab tool and start viewing it as a continuity layer between discovery, development, and manufacturing. The handoff points matter. That's where companies lose time, repeat work, and discover that a promising bench result doesn't survive contact with scale.
The market direction is also hard to ignore. The global chemical software market is projected to grow by USD 561 million between 2025 and 2029, driven by an 11.4% CAGR from 2024 to 2029. That projection is tied to Industry 4.0, big data analytics, and AI adoption, which tells you this category is moving into mainstream operational strategy.
A visual summary helps show where the impact lands across the organization.

For R&D leaders
R&D leaders care about portfolio velocity and technical risk. Optimization software helps by reducing the number of blind turns in a program. Teams can rank which formulations, reaction paths, or operating ranges are worth scarce lab time. They can also document why a program advanced or stopped, which improves governance.
That usually leads to a healthier pipeline. Not because every project succeeds, but because weak options are eliminated earlier and stronger candidates reach scale-up with better evidence.
For formulation chemists and lab teams
Chemists don't need more dashboards. They need less manual reconciliation and fewer repetitive screens of low-value experiments.
When the system is configured well, routine work gets lighter. Historical comparisons become faster. Variable interactions become visible. “Next best experiment” suggestions help scientists focus on interpretation rather than bookkeeping. That leaves more room for the core work of formulation science, troubleshooting, and mechanism-based judgment.
Later in the process, video can help align technical and non-technical stakeholders around what scale-up optimization looks like in practice.
For CTOs and process engineers
This group usually asks the hardest and best questions. Will the model survive real plant data? Can we trust recommendations at production conditions? Will this shorten transfer from development to manufacturing, or just create another analytics layer?
Those are the right questions because the value is operational, not cosmetic.
Buy software that improves decisions at handoff points. Bench to pilot. Pilot to plant. Lab data to process limits. That's where return shows up.
When optimization software is tied to actual process constraints, scale-up gets less adversarial. Development can hand manufacturing not just a nominal recipe, but a clearer operating window, known sensitivities, and explicit trade-offs. That reduces the usual back-and-forth where production teams relearn what R&D already discovered but failed to encode.
How to Select the Right Optimization Software
Vendor selection goes wrong when teams buy broad capability instead of fit. A demo can look impressive and still be wrong for your chemistry, operating mode, or regulatory environment. The right question isn't “Which platform has the most AI?” It's “Which platform can represent our process reality accurately enough that scientists will rely on it?”
Start with process reality, not vendor demos
Begin with your actual use case. Continuous polymerization has different needs from batch pharmaceutical synthesis. A formulation lab optimizing additives faces different constraints from a process engineering team tuning a distillation sequence. If you don't anchor selection in that reality, you'll end up evaluating interfaces instead of capability.
One blind spot appears often in pharma, biotech, and fine chemicals. Mainstream coverage leans heavily toward general-purpose tools and continuous operations. But over 70% of global pharmaceutical manufacturing relies on batch processes, and specialized tools such as SuperPro Designer are identified for batch and semi-batch simulation needs. That's a practical distinction, not a niche detail.
A general simulator may still work, but only if your team is willing to build domain-specific adjustments around it. Many organizations underestimate that burden.
Questions that expose fit fast
Use procurement meetings to force specificity. If a vendor can't answer these clearly, expect trouble after purchase.
- Modeling fit: Can the system represent our process mode accurately, including batch, semi-batch, or continuous behavior as needed?
- Scientific transparency: What exactly can users inspect when a model recommends a parameter window or next experiment?
- Data burden: How much historical cleanup is required before the platform becomes useful?
- Integration realism: Which systems can it connect to out of the box, and where will custom work be required?
- Validation workflow: How does the vendor support model review, override, retraining, and auditability?
A short comparison workshop often reveals more than a formal RFP. Put two vendors in front of the same hard problem from your own environment. Ask them to show how they would ingest the data, structure the variables, explain the recommendation, and handle exceptions.
If a platform only looks good with clean demo data, it probably won't perform well in your organization's first six months.
Security and governance also matter, especially when formulation IP and process know-how sit in the same environment. Enterprise buyers should look closely at access controls, deployment options, auditability, and compliance posture. Those features won't win the demo, but they often determine whether adoption can scale beyond a pilot.
Implementation Roadmap and Avoiding Common Pitfalls
Implementation succeeds when you treat the first deployment as an operating change, not a software rollout. The objective isn't to “turn on AI.” It's to improve one meaningful decision loop, prove trust, and expand from there.
A phased roadmap is the safest route because it lets you validate data pipelines, user behavior, and model usefulness before the platform becomes business-critical.
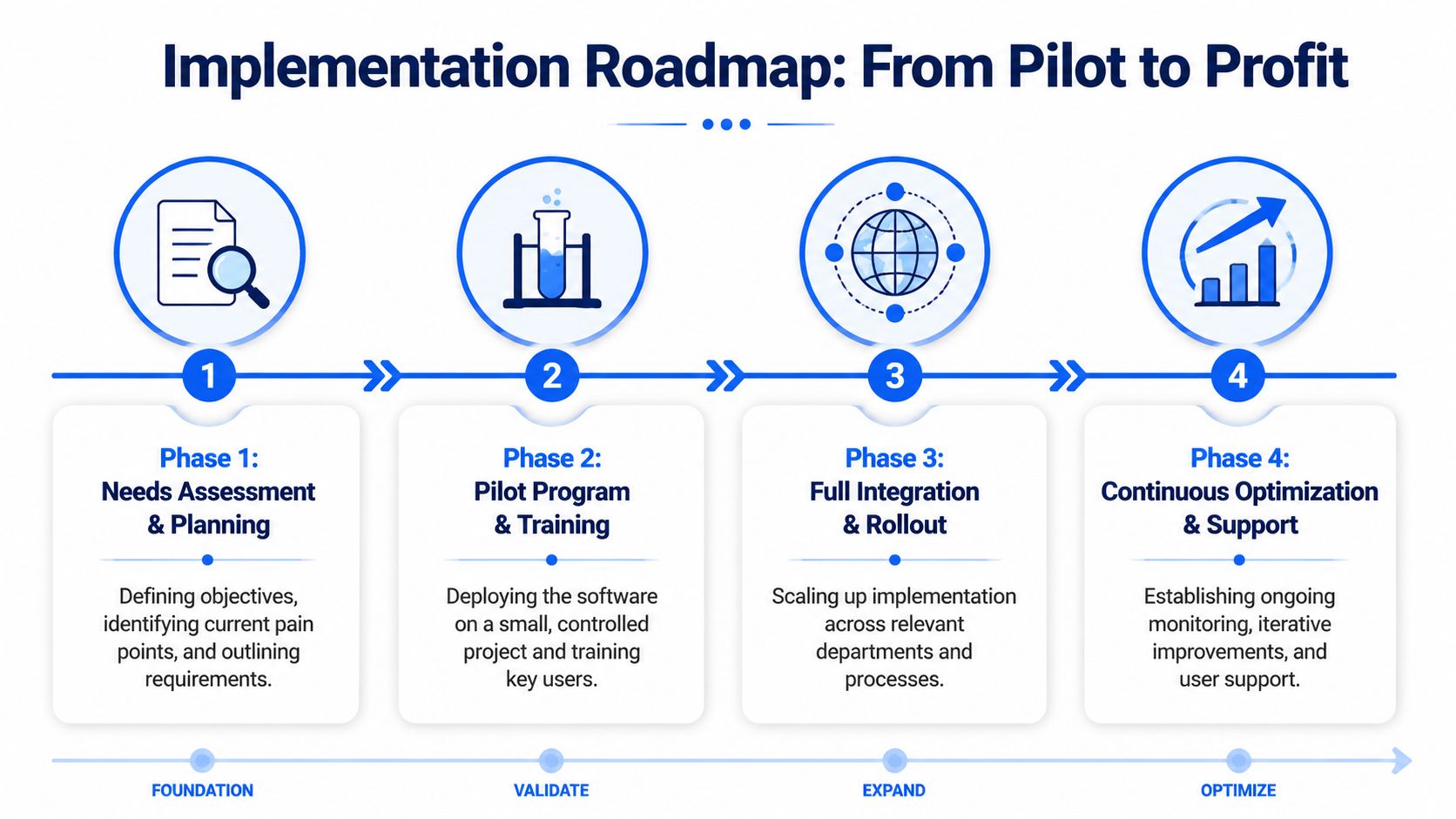
Phase the rollout around one hard problem
Start with a problem that already has visibility and pain. Good candidates include unstable yield, unpredictable scale-up behavior, recurring off-spec outcomes, or a formulation space that consumes too many experiments.
A practical rollout often follows this pattern:
Define the decision to improve
Pick one high-value question, such as selecting the next experiment or tightening a process window before pilot work.Assemble the minimum useful data backbone
Don't wait for perfect harmonization across the enterprise. Build enough structure to connect relevant historical runs, inputs, outputs, and metadata.Train a small user group
Choose respected scientists and engineers, not only digital enthusiasts. Their judgment will shape credibility.Review recommendations against expert intuition
Early on, the comparison matters as much as the prediction. Teams need to see where the model agrees, where it diverges, and why.Expand only after workflow fit is proven
Scale from one process family or program to adjacent use cases once people are using the output in real decisions.
Pitfalls that quietly kill adoption
The first trap is the perfect data trap. Teams delay launch because the historical record is incomplete, naming conventions are inconsistent, or old experiments are hard to normalize. Those issues are real, but waiting for perfect data usually means waiting forever. Start with a bounded problem and improve the data backbone in parallel.
The second trap is buying a black box and assuming trust will appear later. It won't. Scientists need to inspect the basis for a recommendation, compare it with mechanism, and understand confidence before they'll act on it.
The third trap is failing to validate edge conditions. This is especially serious in advanced process environments. A known restraint in the simulator market is inaccurate modeling of extreme conditions such as high-pressure reactions, which creates safety and efficiency risks in areas like hydrogen electrolysis and carbon capture. If your process lives in those regimes, vendor claims need hard scrutiny.
A simple risk table helps align stakeholders early.
| Pitfall | What it looks like | Better response |
|---|---|---|
| Waiting for perfect data | Pilot never starts | Define a minimum viable dataset and move |
| No scientist buy-in | Recommendations are ignored | Make explainability and review workflows mandatory |
| Wrong process fit | Model doesn't match batch or extreme conditions | Validate against your actual operating regime |
| IT-only rollout | Tool is installed but unused | Assign scientific owners, not just technical admins |
Adoption follows credibility. Credibility comes from transparent recommendations, relevant use cases, and early wins that scientists recognize as real.
Conclusion Your Next Steps to Targeted Innovation
Chemical process optimization software is no longer just a specialist tool for simulation experts. In the right enterprise setup, it becomes a decision layer across R&D, scale-up, and manufacturing. That's a significant shift. Teams move from retrospective analysis and broad trial-and-error work toward guided experimentation with clearer logic behind each move.
The hard part isn't buying software. It's building the conditions that let it matter. Unified data infrastructure gives the models something trustworthy to learn from. Explainable AI gives scientists a reason to use the outputs. Careful vendor selection keeps you from forcing the wrong tool onto the wrong process.
If you're deciding what to do next, take three concrete steps:
- Audit your current data environment: Find where experimental, analytical, and process data are fragmented.
- Choose one high-impact pilot: Pick a decision that is costly, repeated, and currently inconsistent.
- Prioritize explainability in every vendor conversation: If the model can't show its work, don't expect adoption.
Targeted innovation doesn't start when the model is perfect. It starts when your team can make the next decision with more evidence and less guesswork.
If you're evaluating how to unify fragmented R&D data and apply explainable AI to formulation and process decisions, Polymerize is built for that exact enterprise challenge. It gives materials teams a secure data backbone, domain-specific models, and scientist-friendly guidance that helps reduce failed experiments and accelerate scale-up without asking teams to trust a black box.

