Your lab probably already has enough data to support better decisions, but it doesn't feel that way. Results sit in spreadsheets with inconsistent naming. Pilot runs live in slide decks. Instrument outputs are stored separately from formulation notes. When a scientist asks, “Have we tried anything close to this before?”, the answer depends on who remembers.
That's the actual state of artificial intelligence materials science inside many R&D organizations. The limiting factor usually isn't whether a model exists. It's whether the organization can turn years of scattered experimental history into something a model and, especially, a scientist can trust. Teams that get this right don't use AI to replace experimental work. They use it to choose the next experiment with more confidence, less repetition, and a clearer line between data, reasoning, and action.
Table of Contents
- A practical comparison of common model families
- Why tree-based models often win in industrial settings
- Property prediction for polymer development
- Formulation optimization under cost pressure
- Reducing scale-up surprises
- Phase one centralize and standardize
- Phase two validate and explain
- Phase three embed into daily R&D work
The New R&D Paradigm Artificial Intelligence Materials Science
A materials team finishes a quarter with hundreds of experiments, several promising signals, and no reliable way to compare results across instruments, sites, or naming conventions. That is where many AI efforts stall. The model is rarely the first problem. The records are.
Materials R&D has long relied on informed trial and error. Scientists use theory, prior art, and experience to choose the next formulation, process condition, or characterization plan. That approach still produces breakthroughs, but it also burns time, material, and lab capacity when historical results are fragmented or hard to trust.
Artificial intelligence materials science changes how teams choose the next experiment. Its practical value comes from narrowing the search space, surfacing relationships across composition, processing, and performance, and reducing repeat work caused by poor record reuse. In real programs, better models help only after the underlying data is searchable, comparable, and tied to the conditions that produced it.
The business context supports that shift. The Generative AI in material science market analysis estimates the market at USD 1.1 billion in 2024 and projects it will reach USD 11.7 billion by 2034, with a projected 26.4% CAGR over 2025 to 2034. The same analysis notes that North America held more than 36% share in 2024 with about USD 0.3 billion in revenue, and that the software segment accounted for over 71% of revenue. For R&D leadership, that points to a clear spending pattern. Companies are investing in software infrastructure that turns experimental history into something teams can use repeatedly.
Why the competitive pressure is operational
Early advantage is going to companies that make past experiments searchable, comparable, and reusable while they build their modeling capability. A lab that can connect formulation, process settings, test methods, and resulting properties in one system can generate predictions that scientists will trust. A lab with scattered spreadsheets and inconsistent metadata usually cannot, even with a strong modeling team.
Practical rule: The first win in materials AI usually comes from selecting better experiments, not from automating the whole lab.
Leadership teams outside materials are reaching the same conclusion. If you want a broader business lens on why AI adoption is becoming operational rather than theoretical, this guide on AI for DFW businesses offers a useful cross-industry perspective.
What this shift changes
A data-driven R&D workflow changes three habits:
- Experiment selection gets tighter. Scientists spend less time on ideas with weak support from mechanism, precedent, or adjacent formulations.
- Knowledge survives turnover. Historical know-how stops living only in notebooks, inboxes, and individual memory.
- Scale-up questions show up earlier. Teams can assess process sensitivity sooner instead of finding manufacturability problems late.
This is why the change matters. AI in materials is becoming a practical operating method for organizations that treat data quality, context, and reproducibility as part of the science, not as cleanup work for later.
What AI Actually Does in the Lab
The easiest way to explain AI in a materials lab is to call it a superpowered lab assistant. Not because it replaces judgment. It doesn't. It helps a scientist review far more historical information than any person can hold in working memory, then turns that history into ranked, testable options.
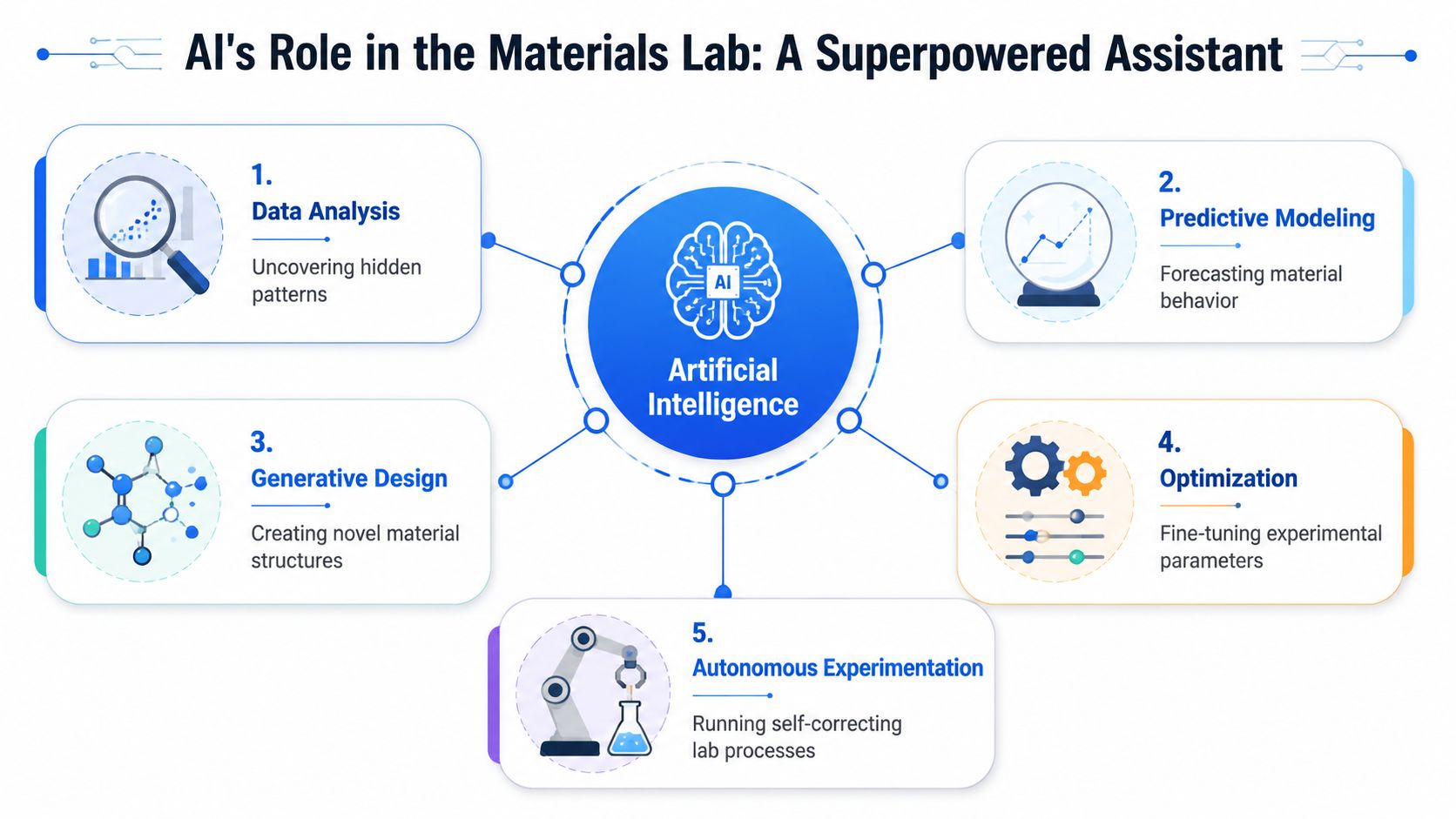
From property prediction to inverse design
In day-to-day R&D, AI usually shows up in a few practical forms.
- Property prediction helps estimate how a formulation or material candidate might behave before a team runs the next round of testing.
- Inverse design starts with a target, such as thermal stability, impact performance, clarity, or processability, and works backward to suggest candidate compositions or parameter ranges.
- Knowledge extraction pulls useful facts from reports, PDFs, patents, and other unstructured text so teams can reuse prior learning.
- Process optimization links operating conditions to material performance so engineers can understand which settings matter most.
- Decision support ranks candidate experiments instead of leaving scientists with a blank page.
AI earns trust not by making grand claims, but by helping teams answer ordinary questions faster. Which inputs matter most? Which experiments are close analogs? What should we test next if cost, performance, and manufacturability all matter?
AI is most useful when it narrows choices in a way the lab can verify quickly.
Why institutions are formalizing the field
A useful sign of maturity is that established institutions are treating this work as a discipline, not a novelty. NIST's Data and AI-Driven Materials Science Group exists to develop “methods, algorithms, data, and tools” that accelerate discovery, development, commercialization, and circularity of industrially relevant materials. The same institutional trend includes groups such as the Max Planck Institute's AI for Materials Science effort, which emphasizes interpretable, physics-informed machine learning to explain links among composition, processing, and properties.
That emphasis on interpretability matters in real labs. A model that predicts well but can't explain likely drivers often stalls at adoption. Scientists want to know whether the system is responding to a plausible additive interaction, a processing artifact, or noise in the record.
A good lab deployment usually pairs prediction with explanation. The model proposes. The scientist challenges. The experiment decides.
Key AI Methods and Their Data Appetites
A model choice is a lab operations choice. It determines what data must exist, how much cleanup is required, and whether scientists will trust the output enough to act on it.
Teams often start with the wrong question. They ask which method is most advanced, then discover their records cannot support it. A better starting point is the decision itself: predicting a property, flagging a likely failure, grouping similar formulations, or ranking the next experiment. The method should follow from that decision and from the condition of the historical data.
If your team needs a clear primer on model categories before going deeper into materials-specific use cases, TekRecruiter's machine learning breakdown is a good general refresher on supervised versus unsupervised approaches.
A practical comparison of common model families
The useful question is simple. Which model fits the data you can defend?
| Model Type | Best For | Data Requirement | Explainability |
|---|---|---|---|
| Regression models | Predicting continuous properties such as strength, viscosity, or conductivity | Structured historical examples with consistent inputs and measured outputs | Often moderate to high, depending on model choice |
| Classification models | Pass/fail screening, defect risk, compliance categories, or likely performance bands | Labeled outcomes and clear class definitions | Often moderate to high |
| Clustering methods | Finding formulation families, hidden groupings, and unexpected similarities | Can work without labeled outputs, but still needs reasonably consistent descriptors | Moderate, but interpretation depends on domain review |
| Neural networks | Complex nonlinear relationships and high-dimensional data environments | Larger, cleaner, and more standardized datasets than many teams expect | Often lower without dedicated interpretability work |
| Tree-based models | Mixed industrial datasets with nonlinear interactions among formulation and process variables | Structured tabular data, tolerates imperfect industrial data better than many alternatives | High enough for many scientific decisions when paired with feature attribution |
Why tree-based models often win in industrial settings
In materials R&D, tree-based models such as Random Forest, XGBoost, and LightGBM often prove to be the most practical starting point. They handle nonlinear behavior well, they work with tabular experimental records, and they give scientists enough visibility into the drivers of a prediction to support real lab decisions.
That matters because materials systems are full of interactions. A dispersant can help in one resin family and hurt in another. A small compositional change may matter only after a specific thermal history. Processing variables can dominate a result that the team first assumed was chemistry-driven. Tree-based methods usually capture these patterns without demanding the volume and uniformity that neural networks often need.
Interpretability is the other reason they get adopted. Feature importance and SHAP-style analyses do not prove mechanism, but they do give the team a testable hypothesis. If the model ranks screw speed or cure temperature above additive loading, the next experiment can be designed to challenge that result instead of treating the prediction as a black box.
I have seen this trade-off matter more than headline accuracy. A slightly less accurate model that uses clean, traceable variables will usually create more value than a more complex model built on poorly labeled records.
Decision criterion: Choose the simplest model that improves the next experimental decision.
Data appetite still sets the ceiling. Even forgiving methods break down when ingredient names are inconsistent, test methods changed over time, units were merged carelessly, or failed runs never made it into the system. Better models do not fix weak experimental history. The operational path starts with standardizing records, preserving context, and making results reproducible enough that a prediction means the same thing across teams and time.
Concrete Applications and Success Stories
The most convincing applications of artificial intelligence materials science are the boring ones. They help labs make routine decisions with more discipline. That's where adoption sticks.
Property prediction for polymer development
A polymer team is trying to improve a target property while preserving processability. Historically, the group would start from familiar chemistries, vary a few additives, and run many rounds of screening. AI changes the opening move.
Instead of asking the team to search from scratch, the model reviews prior formulations, processing settings, and measured outcomes, then ranks a smaller set of candidates that are most consistent with the target profile. The scientist still decides what to test, but the short list is grounded in historical evidence rather than memory alone.
This tends to work best when the team has recorded both successful and unsuccessful experiments. Failed trials aren't noise. They define the boundary of the design space.
Formulation optimization under cost pressure
A chemical company often faces a more commercial question. Can we replace or reduce an expensive additive without losing the properties customers care about? AI-guided formulation work becomes attractive in such situations because the problem has multiple constraints at once.
A useful workflow looks like this:
- Start with the known formulation. Use it as a reference point instead of chasing novelty for its own sake.
- Map sensitivity. Identify which ingredients are tightly linked to performance and which ones have room for substitution.
- Generate constrained options. Produce alternatives that stay within practical formulation and processing bounds.
- Validate in the lab. Confirm that the recommended substitutions behave as expected under real processing conditions.
Many teams discover that the model's biggest value isn't finding a miracle substitute. It's showing which changes are low-risk and which ones are likely to destabilize the system.
A short video overview can help make these workflows more concrete in practice.
Reducing scale-up surprises
Scale-up is where many promising formulations become expensive lessons. A material that performs well in controlled lab conditions can drift when mixing energy, residence time, temperature profile, or raw-material variability changes in production.
AI helps by connecting process history to performance outcomes. Instead of treating scale-up as a separate problem, the team can model how process parameters interacted with formulation choices in prior work. That gives engineers a way to identify sensitive variables before the transfer happens.
The strongest scale-up models don't just predict failure. They show which parameter combinations deserve tighter control.
The key point across all three examples is simple. AI is most useful when it supports an experimental decision that the lab can validate quickly.
The Measurable Business Impact of AI in R&D
R&D leaders don't need another abstract promise about “innovation acceleration.” They need to know where AI changes economics, decision quality, and organizational risk.
Where leaders actually see value
The clearest value usually appears in four places.
- Fewer avoidable experiments. When teams stop repeating dead ends or testing poorly framed options, they save materials, instrument time, and scientist attention.
- Shorter learning cycles. Better experiment selection means the team reaches a useful answer with fewer loops.
- Stronger continuity of know-how. Experimental reasoning becomes searchable and reusable instead of disappearing when a project owner changes.
- Better cross-functional handoff. Process, quality, and manufacturing teams inherit more structured evidence instead of fragmented project history.
These gains matter because materials programs rarely fail for a single reason. They stall when uncertainty compounds across formulation, process, scale-up, and documentation.
How to think about ROI without fantasy math
A realistic ROI discussion starts with current waste. Look at where projects lose time. Repeated tests because records were incomplete. Delays because data lived in multiple formats. Reformulation cycles triggered by late discovery of process sensitivity. Those are operational problems, not modeling problems.
A disciplined evaluation usually asks:
- What decisions are expensive today? Candidate selection, additive substitution, scale-up transfer, root-cause analysis.
- Which of those decisions already have enough historical data? Not perfect data. Enough to start with bounded use cases.
- What would better decision quality prevent? Rework, duplicated testing, delayed customer samples, or slow troubleshooting.
- Can the team verify model output quickly? Fast validation creates trust and shortens adoption time.
The corporate IP angle is often underrated. Once historical experiments are centralized and linked to outcomes, an organization converts tribal knowledge into an asset that survives personnel changes and can support future programs. That often outlasts the first model itself.
The most credible business case for AI in R&D isn't that it makes chemistry automatic. It's that it makes organizational learning cumulative.
Your Implementation Roadmap From Data Chaos to AI-Ready
Most organizations don't need a moonshot plan. They need a sequence that starts from messy reality. That's why data readiness deserves more attention than model selection.
Recent institutional work points the same way. The NSF AI Materials Institute announcement from Cornell frames the opportunity around harnessing the “rising tide of materials data” across experiments, simulations, images, and papers. In practice, that supports a simple conclusion. The main bottleneck is often not lack of algorithms. It's lack of usable, trustworthy data infrastructure.
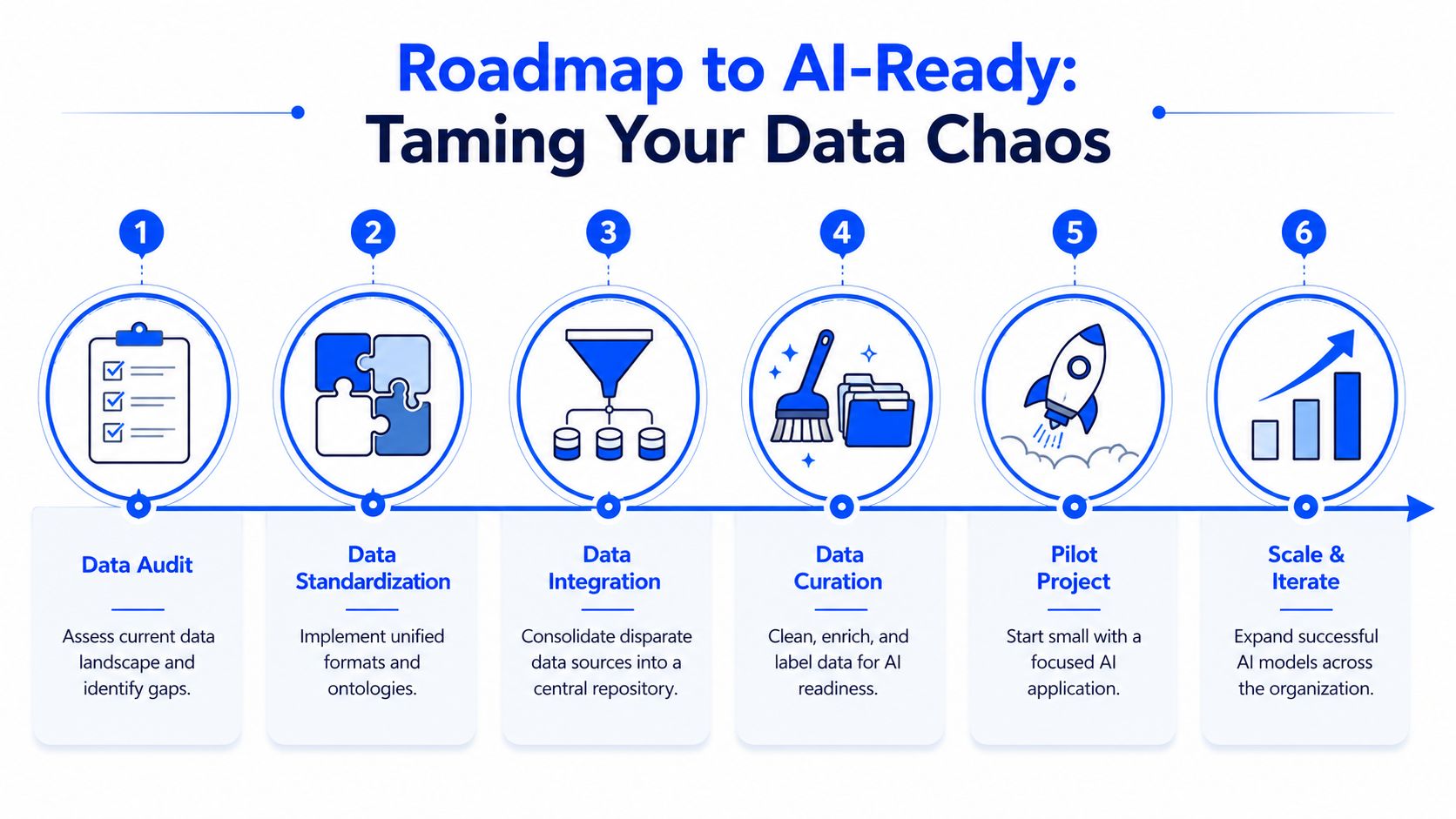
Phase one centralize and standardize
Start by building a shared experimental record. This doesn't require a perfect migration of every legacy file on day one. It requires agreement on what the organization considers a usable record.
Focus first on:
- Common identifiers. Raw materials, formulations, batches, test methods, and units need consistent naming.
- Linked context. Composition without process conditions, or test results without sample history, won't support reliable modeling.
- Inclusion of failures. Negative results define what doesn't work and often matter as much as successes.
- Provenance. Teams should be able to trace where a record came from and who modified it.
If this step feels slow, that's normal. It's also where many AI programs either become credible or collapse later.
Phase two validate and explain
Once the data backbone exists, start with a narrow use case. Property prediction for one product family is better than a grand enterprise rollout with vague objectives. Use cases should be specific enough that scientists can challenge model output against known chemistry and recent lab results.
Validation should include both performance and interpretability. Scientists need to ask whether the important variables make sense, whether the model is extrapolating too far, and whether confidence changes across regions of the design space.
Field note: Trust grows when the model can show its reasoning path in terms scientists already use, such as composition, process settings, and test history.
Phase three embed into daily R&D work
The last step is workflow integration. A good model that lives outside normal lab practice won't change outcomes. Teams need predictions inside the places where they already review candidates, plan experiments, and decide scale-up readiness.
That usually means three things:
- Decision points are explicit. The team knows when AI guidance is consulted and when human override is expected.
- Governance is clear. Access, traceability, and IP protection are built into the system, not added later.
- Iteration is normal. Models are refreshed as new experiments come in and design spaces shift.
AI readiness isn't a finish line. It's an operating discipline built on clean records, transparent reasoning, and regular scientific challenge.
Accelerating Your Journey with an AI-Native Platform
Once a team understands the roadmap, the next decision is whether to build the stack internally or adopt a platform built for materials R&D. That choice is less about ideology and more about time, talent, and integration burden.
Build versus buy in a regulated R&D environment
An internal build can make sense if the company already has strong data engineering, ML operations, scientific informatics, and governance teams that can work closely with the lab. Even then, the challenge isn't only model development. It's data ingestion, schema design, lineage, permissions, validation workflows, explainability, and maintenance.
For many materials organizations, that's a long list to assemble before the first scientist gets a useful recommendation. Buying a specialized platform often shortens the distance between scattered records and a working decision tool.
What a purpose-built stack changes
A purpose-built option such as Polymerize focuses on the parts general AI stacks usually miss in materials work: unifying fragmented experimental data across spreadsheets, ELNs, and silos, creating an AI-ready backbone, and supporting domain-specific, explainable modeling for formulation and property decisions. That doesn't eliminate scientific judgment. It gives scientists and R&D leaders an environment where judgment can operate on cleaner evidence.
The practical test is simple. Can the platform help your team centralize data, explain predictions in scientific terms, and support the next best experiment without forcing a multi-year internal systems project first? If yes, the implementation path becomes much more manageable.
A good AI-native stack doesn't promise magic. It reduces friction between the data you already have and the decisions your scientists need to make this week.
If your team is trying to turn fragmented experimental history into a reliable foundation for AI, Polymerize is worth evaluating. It's built for materials R&D workflows where data readiness, explainability, and secure knowledge reuse matter as much as model output.

