A formulation chemist has a target. Better thermal stability, tighter flexibility range, cleaner processing, lower risk at scale. The team runs a batch, tests it, adjusts one ratio, reruns it, then changes a catalyst, then revisits a solvent choice from three months ago because the old notebook suggests a clue. Weeks pass. The result is progress, but it's expensive progress, and most of it comes from eliminating what doesn't work.
That rhythm is familiar in polymer labs. It's also the reason many R&D groups feel stuck between pressure from the business and the realities of materials science. Leadership wants faster development. Scientists want fewer dead-end experiments. Process engineers want formulations that survive the move from bench to plant. Everyone wants better decisions earlier.
AI for polymer development matters because it changes that rhythm. Instead of asking, “What should we try next?” teams can ask, “What is most likely to work, and what experiment will teach us the most if it doesn't?” That is a different operating model. It doesn't remove chemistry, judgment, or lab work. It makes them more focused.
Used well, AI becomes part of the daily R&D system. It helps predict properties before synthesis, narrow formulation options before screening, and connect lab observations to process choices that matter later in manufacturing. The hard part isn't whether the models are interesting. The hard part is getting them into a traditional polymer organization in a way that scientists trust and managers can scale.
Table of Contents
- Phase 1 exploration and pilot
- Phase 2 capability building
- Phase 3 scaling and integration
- Phase 4 optimization and innovation
Introduction The End of Trial and Error
Most polymer teams don't have a science problem. They have a workflow problem.
The knowledge exists, but it's scattered. One part sits in ELNs, one part in spreadsheets on personal drives, one part in instrument files, and a large part in the memory of senior chemists who know which combinations usually fail before anyone writes them down. Traditional development still works, but it works by accumulation. You learn by running enough experiments to corner the answer.
That process made sense when the design space was manageable. It breaks down when the number of possible chemistries, additives, process settings, and end-use constraints grows faster than the team can test. In polymers, that happens quickly. A single formulation change can affect viscosity, stability, cure behavior, mechanical performance, and downstream manufacturability all at once.
The real cost of slow iteration
The obvious cost is calendar time. The less obvious cost is organizational drag.
When chemists spend too much time on low-information experiments, three things happen:
- Programs become harder to prioritize. Leaders can't tell whether a project is underperforming because the concept is weak or because the search strategy is inefficient.
- Scale-up gets delayed. Process teams receive candidates that look promising on paper but haven't been evaluated against real manufacturing constraints.
- Learning stays local. One group discovers a useful pattern, but another group repeats the same failed path because the data isn't structured for reuse.
Practical rule: If your team can't easily compare formulation, process, and performance data in one place, AI won't fix the problem. But it can become the reason you finally solve it.
The appeal of AI for polymer development isn't novelty. It's operational discipline. It gives R&D teams a systematic way to use prior experiments to guide the next ones. That changes the quality of decision-making before any batch is made.
What changes in practice
A modern polymer workflow doesn't start with a broad guess. It starts with a target property profile, historical data, and a model that ranks likely candidates or process windows.
That means fewer blind iterations and better sequencing of lab work. Instead of screening everything you can think of, you screen what is most likely to teach the team something valuable. Some organizations use that for property prediction first. Others start with process optimization or formulation ranking. Both are valid. What matters is that the lab stops behaving like a search party and starts behaving like a guided system.
The Core Shift From Guesswork to Predictive Design
Traditional polymer R&D is a lot like driving through an unfamiliar industrial district with verbal directions from five different people. You'll probably get there, but you'll waste time, double back, and miss important turns. AI gives the team a map. In the strongest cases, it gives the team route guidance that updates as new information arrives.
A 2025 review in the Journal of Polymer Science explains that AI and machine learning are being used to predict polymer properties such as glass transition temperature, biodegradability, and polymer-solvent compatibility directly from structure data, which automates part of the trial-and-error loop and lets teams query models before a polymer is ever made, shifting the workflow from manual experimentation to predictive design (Journal of Polymer Science review).
What predictive design actually means
Predictive design isn't just “using software before the lab.” It means converting prior experimental knowledge into a quantitative system that can evaluate options at a scale no scientist can do manually.
In practice, teams feed models with combinations such as:
- Structure data tied to measured properties
- Formulation variables such as ratios, additives, and solvent choices
- Process conditions including temperature, pressure, or catalyst selection
- Outcome data from screening, validation, and failure analysis
The model learns patterns across those variables and estimates what's likely to happen for untested candidates. That reduces the search space before synthesis starts.
Why this matters more in polymers than in many other domains
Polymer systems are messy. Nonlinear behavior is the rule, not the exception. Small changes in composition or processing can create large changes in final performance. That makes intuition important, but it also makes intuition unreliable when the interaction effects get too complex.
A predictive workflow helps in two specific ways:
| Traditional approach | Predictive approach |
|---|---|
| Start with a few expert guesses | Start with a broad but ranked design space |
| Run batches to find direction | Use models to identify likely candidates first |
| Learn mainly from failures after the fact | Learn before synthesis and refine after validation |
| Scale-up concerns often appear late | Process-aware modeling can be introduced earlier |
The best AI systems in materials R&D don't replace experienced formulators. They make expert judgment easier to apply where it has the highest value.
That is the core shift. The lab still experiments. It just stops experimenting blindly.
Your AI Toolkit Core Models and Workflows Explained
A lot of teams hear “AI for polymer development” and assume it means one giant platform that generates miracle formulations. That isn't how good programs work. Most successful implementations use a small set of model types in a disciplined workflow.
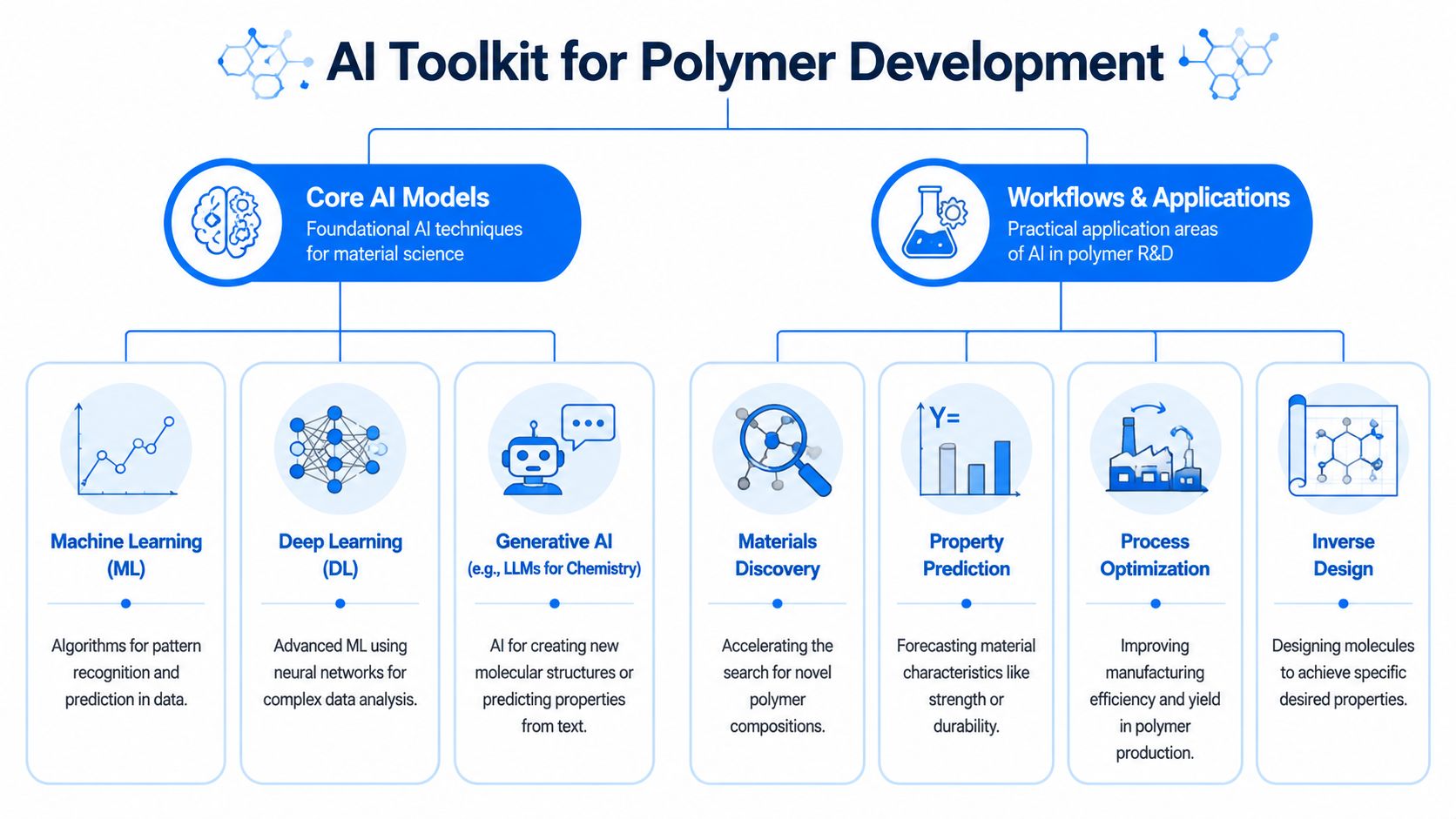
In polymer R&D, AI tends to create the most practical value in property prediction and synthesis optimization. Machine-learning systems can connect structure, composition, and processing variables to outcomes such as tensile strength, thermal stability, flexibility, and energy-density performance, helping teams identify operating windows that reduce failed experiments and shorten development timelines (practical overview of AI in custom polymer synthesis).
Property prediction
Property prediction is the entry point for many labs because it's concrete and easy to frame around an existing pain point.
You have historical examples. You know the property you care about. You want the model to estimate likely results for untested candidates.
Typical uses include:
- Screening before synthesis. Teams rank which formulations deserve lab time.
- Prioritizing trade-offs. A model can help compare candidate materials across multiple target properties.
- Finding hidden drivers. Variable importance and model interpretation often reveal which formulation or process parameters matter most.
This is usually where trust gets built. Scientists can compare predictions against known results, challenge the model, and see whether it captures behavior they recognize.
Formulation optimization
Once a team can predict outcomes, the next step is deciding how to improve them.
Formulation optimization treats the problem as a search over constrained options. The goal isn't just to find a high-performing composition. It's to find one that fits the business rules. Cost, availability, processing limits, sustainability goals, and regulatory boundaries all shape what “optimal” means.
Here, many projects either mature or fail. If a model suggests candidates that are impossible to manufacture or incompatible with existing process equipment, scientists will stop using it.
A useful optimization workflow usually includes:
- Hard constraints such as banned inputs or process limits
- Target ranges for key performance outcomes
- Confidence scoring so users know which recommendations are more speculative
- Human review before experimental commitment
Active learning
Active learning is one of the most valuable ideas in modern lab AI because it answers a better question than “What is the best candidate?”
It asks, “What is the next experiment that will improve the model and the project fastest?”
That distinction matters. In a sparse data environment, the single most informative experiment is often more valuable than the highest-ranked predicted candidate. A smart active learning loop helps teams spend experiments where they create maximum knowledge, not just maximum optimism.
A weak AI workflow tries to be right on day one. A strong AI workflow gets better every time the lab runs.
Closed-loop experimentation
Closed-loop systems combine prediction, candidate generation, experimental validation, and model updating into one cycle. Georgia Tech describes this pattern directly in polymer informatics: scientists define target properties, train models on existing data, generate new polymers, validate top candidates experimentally, and feed results back to improve future predictions. The same source notes that AI-enabled methods can reach prediction accuracy above 95% for target properties in some polymer-design contexts while keeping target deviation within 10% when training data is strong (Georgia Tech polymer informatics workflow).
That workflow matters because polymer property spaces are high-dimensional. Static models degrade. Closed loops improve.
One practical example of tooling in this area is Polymerize, which is built to unify fragmented experimental data and apply domain-specific models for property prediction, formulation optimization, and next-experiment planning. It's one option in a broader category of materials informatics systems that are trying to make AI usable inside real enterprise R&D operations rather than as a standalone modeling exercise.
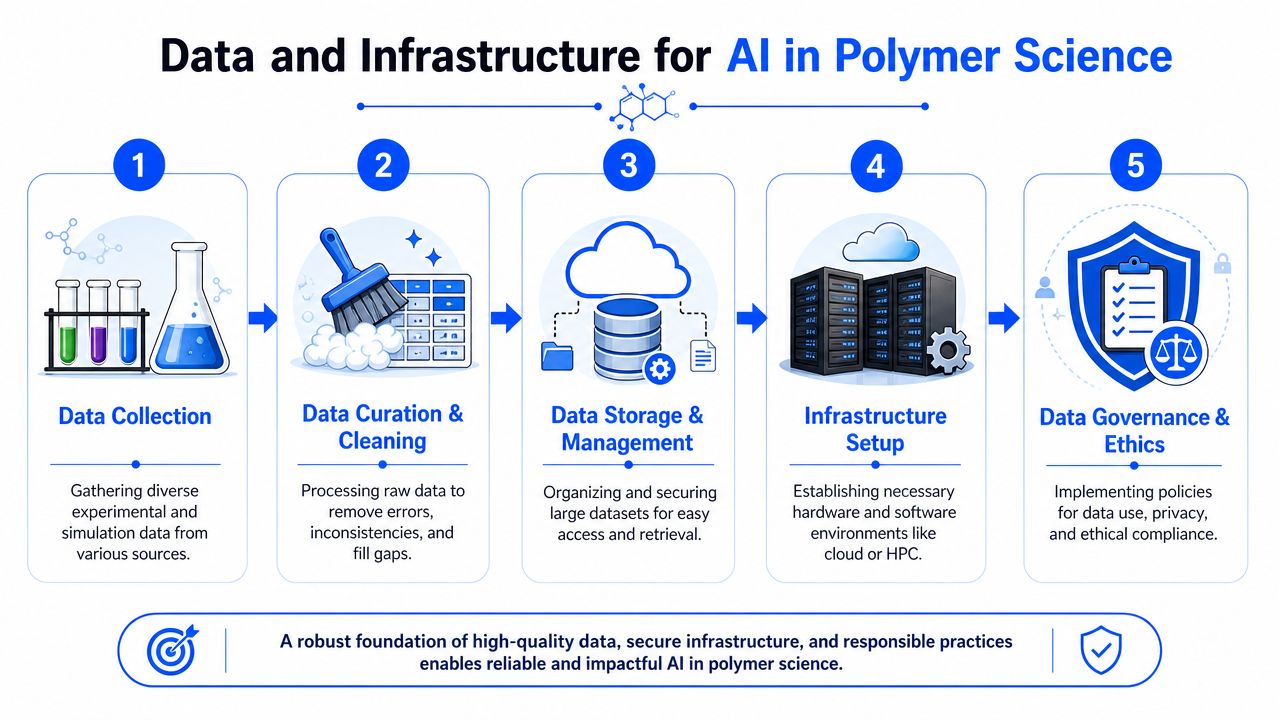
Building Your Foundation Data and Infrastructure Needs
Most failed AI efforts in polymer R&D don't fail because the chemistry is too hard. They fail because the data environment is too fragmented for the models to learn from the right signals.
The good news is that you don't need perfect data to start. You do need data that can be found, interpreted, and connected. That is a very different standard.
Public discussion often treats model scale as the main differentiator, but that misses the practical issue. Both very large and smaller domain-specific models have roles in polymer R&D. NSF coverage of polyBERT highlights a model trained on 80 million polymer chemical structures and notes that it runs over two orders of magnitude faster than traditional methods, yet the more useful lesson for proprietary programs is that data integration, interpretability, and confidence in recommendations often matter more than raw model size (NSF coverage of polyBERT).
What data actually matters
A usable foundation usually spans three layers.
| Data layer | What it includes | Why it matters |
|---|---|---|
| Experimental inputs | Composition, molecular descriptors, additives, solvent systems | Gives the model candidate context |
| Process conditions | Temperature, pressure, mixing sequence, catalyst choice, residence time | Explains why similar formulas behave differently |
| Outcomes | Mechanical, thermal, rheological, stability, yield, defect observations | Trains the prediction target |
What teams often miss is the linkage between these layers. If tensile data is stored one way, processing notes another way, and formulation versions in a third place, model training becomes an expensive reconciliation project.
For organizations trying to build production-grade AI employees, the lesson carries over directly. AI performance depends less on collecting everything and more on turning operational knowledge into structured, reusable context.
Why imperfect data should not stop you
Many R&D leaders delay adoption because they believe they need a fully cleaned, enterprise-wide data lake before any modeling can start. That usually leads to a long infrastructure project with no scientific output.
A better approach is to start with a bounded use case and the best available data around it. Then improve the dataset as part of the pilot.
Focus on these questions first:
- Can the team identify the same formulation consistently across experiments?
- Are process conditions recorded in a comparable format?
- Can outcomes be matched to inputs without manual detective work?
- Do scientists trust the provenance of the records enough to act on a prediction?
Start with the data you can defend, not the data you wish you had.
Infrastructure should follow the same logic. Choose storage, access controls, and compute environments that fit your IP posture and collaboration model. Don't over-architect the stack before the lab has proven the workflow.
A Practical Roadmap for AI Implementation
The safest way to deploy AI in a polymer lab is not to launch a giant transformation program. It's to build a capability in stages, each with a visible scientific outcome and an operational lesson.
The sequence matters because trust, data quality, and workflow adoption rarely arrive at the same time.
A phased approach like the one below keeps the effort grounded.
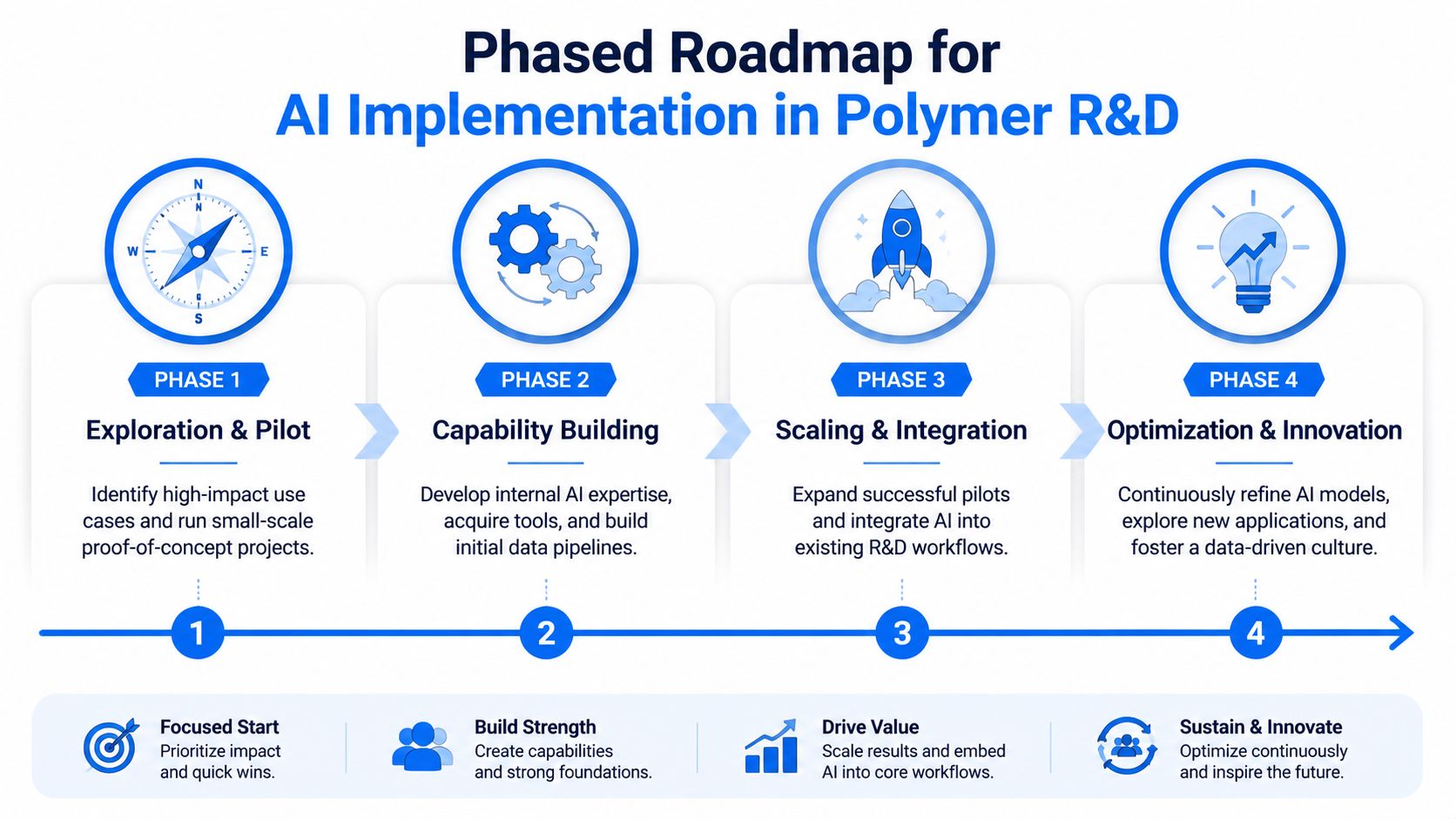
Phase 1 exploration and pilot
Pick one problem that is painful, narrow, and measurable.
Good first pilots often involve predicting a single property, ranking formulations for a well-defined application, or identifying process settings associated with failed batches. Avoid broad discovery programs at the start. They are harder to bound and easier to overpromise.
A strong pilot has four features:
- One owner. A named scientist or technical lead is accountable for adoption, not just the model build.
- One decision point. The output should influence an actual experiment queue or project review.
- One dataset with known limits. The team should understand what is missing.
- One success criterion. Usually this is better prioritization, fewer wasted experiments, or faster convergence on a target.
Phase 2 capability building
After the pilot, don't jump straight to enterprise rollout. Build repeatable support around the workflow.
That usually means:
- Data pipelines that reduce manual wrangling
- Model governance so users know version, training scope, and intended use
- Scientist training focused on interpretation, not just tool access
- Cross-functional reviews with process, quality, and manufacturing stakeholders
Teams that want a broader operating model can use an actionable enterprise AI roadmap as a planning reference for sequencing governance, infrastructure, and adoption work across departments.
A short technical overview can also help align mixed audiences before rollout:
Phase 3 scaling and integration
Once the workflow proves itself, expand horizontally and vertically.
Horizontally means applying the method to more product lines, chemistries, or property targets. Vertically means pushing earlier into design and later into process optimization, scale-up, and quality control. At this stage, most companies discover whether they're building a durable R&D capability or just collecting pilot wins.
Phase 4 optimization and innovation
At maturity, AI becomes part of how R&D plans work rather than a separate digital initiative.
Models are retrained from new results. Experimental strategy becomes more deliberate. Scientists spend less time debating which obvious test to run and more time deciding which high-value uncertainty to reduce next.
The point of implementation is not software adoption. It is better scientific throughput with stronger decision quality.
Measuring Success and Managing Enterprise Risks
If the only metric you track is model accuracy, you'll miss the business case.
Enterprise leaders care about whether AI changes R&D output, resource allocation, and risk. Scientists care whether it improves experiment selection, not whether the algorithm appears advanced. Both groups are right.
Reports on AI in the polymer industry indicate that high-throughput AI screening can cut formulation development time by up to 50%, showing why many organizations now treat AI-for-polymers as enterprise R&D infrastructure rather than an academic exercise (industry coverage on AI in the polymer industry).
What success should look like
A useful scorecard mixes scientific and operational indicators.
Consider tracking:
- Experiment efficiency. Are teams reducing low-value experimental runs?
- Cycle speed. Is the program moving from hypothesis to validated learning faster?
- Decision quality. Are chemists using model outputs to reprioritize work?
- Transferability. Can the same workflow support another formulation family or product line?
- Scale-up readiness. Are process and manufacturing constraints being considered earlier?
Notice what isn't on that list. Fancy dashboard usage. Total number of predictions generated. Model complexity for its own sake.
A practical review process often works better than a giant KPI deck. At each project checkpoint, ask three questions:
| Question | Why it matters |
|---|---|
| Did the model change what the team chose to test? | Shows real behavioral adoption |
| Did those choices produce faster learning? | Connects AI to R&D throughput |
| Can the workflow be trusted in adjacent programs? | Signals whether scale is realistic |
Risk controls that matter in enterprise R and D
Risk management starts with IP and decision governance.
Polymer datasets often encode trade secrets directly through formulations, process know-how, and failure history. That means access control, auditability, and deployment architecture matter from the beginning. Legal, IT, and R&D should agree early on what data can leave controlled environments, who can retrain models, and how predictions are documented in regulated or customer-facing programs.
Other common failure points include:
- Unclear model scope. Users apply a model outside the chemistry space it was trained on.
- No provenance. Teams can't trace which records influenced a recommendation.
- No escalation path. Scientists find edge cases, but there's no review loop for updating the system.
- Weak ownership. Everyone is “supportive,” but nobody owns model performance and usage.
Good governance doesn't slow materials innovation. It keeps promising tools from becoming untrusted ones.
When AI is treated like part of the R&D operating system, risk management becomes easier. The organization knows what the model is for, what data supports it, and when human judgment overrides it.
Conclusion Your Next Steps in Materials Innovation
The strongest argument for AI for polymer development isn't that it discovers new materials in theory. It's that it helps real teams make better choices across the full R&D lifecycle, from property prediction to formulation optimization to the harder handoff into manufacturing reality.
That last step matters more than most discussions admit. A recent research review notes a key challenge in moving AI from property prediction to scale-up reality. Models can shortlist enormous candidate spaces, but the actual bottleneck is whether those materials survive extrusion, curing, thermal aging, and other processing conditions. The next wave of progress will come from integrating those manufacturing constraints directly into AI models (review on polymer lifecycle and scale-up challenges).
For scientists
Start smaller than you think.
Choose one property or formulation family where your team already has historical data and repeated decision pain. Standardize naming. Capture failed experiments, not just successful ones. Record processing context with the same care you give final performance data. If a model can't see how a sample was made, its recommendation will often be less useful than your own intuition.
Also, challenge the outputs. The goal isn't obedience to the model. It's a better experimental conversation.
For R and D leaders
Treat AI as a capability-building program, not a software purchase.
Fund the data work. Put technical ownership in the hands of respected scientists. Involve manufacturing and process engineering earlier than usual. Make success depend on changed decisions and faster learning, not on slideware. If your teams can connect lab inputs, process variables, and outcomes in one governed environment, you'll create the conditions for durable advantage.
The broader shift is straightforward. Polymer labs are moving away from broad trial-and-error loops and toward predictive, iterative, data-guided development. The organizations that benefit most won't be the ones with the loudest AI messaging. They'll be the ones that integrate models into daily scientific work, preserve trust, and close the gap between a promising candidate and a manufacturable product.
If your team is trying to connect fragmented materials data, apply explainable models in polymer R&D, and reduce the gap between bench results and production-ready decisions, Polymerize is worth evaluating as a practical system for enterprise materials development.

