If you're running materials R&D today, the bottleneck usually isn't lack of ideas. It's that data lives everywhere, experiments are expensive, and teams still spend too much time deciding what to test next. Spreadsheets hold historical formulations. ELNs capture partial context. Instrument outputs sit in folders no model can use directly. Scientists rely on intuition to bridge the gaps, which works until program complexity outruns human memory.
That's where AI for materials science has become practical. Not as a replacement for chemists, formulation scientists, or process engineers, but as a way to convert fragmented experimental history into a decision system. Its true value isn't a flashy model demo. It's reducing dead-end experiments, tightening the path from hypothesis to validated material, and doing it in a way your scientists can trust and your security team can approve.
Table of Contents
Why AI Is Redefining Materials Science R&D
Traditional materials development is still shaped by a familiar pattern. A team defines target properties, reviews prior work, proposes candidate chemistries, runs a small batch of experiments, learns something useful, then repeats. That loop can produce breakthroughs, but it's slow when the search space is broad and the available data is inconsistent.
The problem gets worse as portfolios expand. A CTO may have active work across polymers, coatings, additives, specialty chemicals, and scale-up constraints, each with different data formats and different standards of evidence. Scientists end up spending as much time reconstructing context as generating insight.
The shift from research topic to operating capability
AI for materials science matters now because it has moved beyond novelty. A 2021 perspective in Nature Communications said applications of AI in materials science had "exploded," and a later review described the field as "rapidly transforming" materials science and becoming an "essential competency." NIST also now operates a dedicated Data and AI-Driven Materials Science Group, which signals that major institutions treat AI as infrastructure for discovery and development, not a side project (Nature Communications perspective and NIST context).
That matters for enterprise teams. Once a capability becomes infrastructure, the question changes from "Should we experiment with it?" to "How do we govern it, integrate it, and get repeatable value from it?"
Practical rule: Don't judge AI for materials science by whether it can generate an interesting candidate. Judge it by whether it helps your team choose better experiments under real formulation, process, cost, and compliance constraints.
What actually changes inside R&D
The strongest implementations don't remove scientists from the loop. They make the loop tighter.
Instead of asking a team to search from scratch, AI systems can learn from prior experiments, infer structure-property patterns, rank the next set of candidate formulations, and explain why certain variables matter. That reduces wasted synthesis work and improves how quickly teams converge on viable options.
Three changes tend to separate productive programs from stalled ones:
- Historical data becomes reusable. Old experiments stop being archive material and start informing current design choices.
- Decision-making becomes explicit. Teams can compare candidate paths using model outputs, confidence signals, and prior evidence rather than gut feel alone.
- Experimentation becomes more selective. Scientists spend more bench time on high-information tests and less on broad, low-yield screening.
That is why AI for materials science is no longer an academic side conversation. For R&D leaders, it's becoming part of how competitive programs are run.
Understanding the Core Concepts of Materials Informatics
Materials informatics is the operating layer that turns experimental history, simulation outputs, and formulation records into a predictive system for R&D. The easiest way to think about it is as a GPS for materials search. Your scientists still choose the destination. The system helps determine the next best route, warns when a path is unlikely to work, and updates recommendations as new results come in.
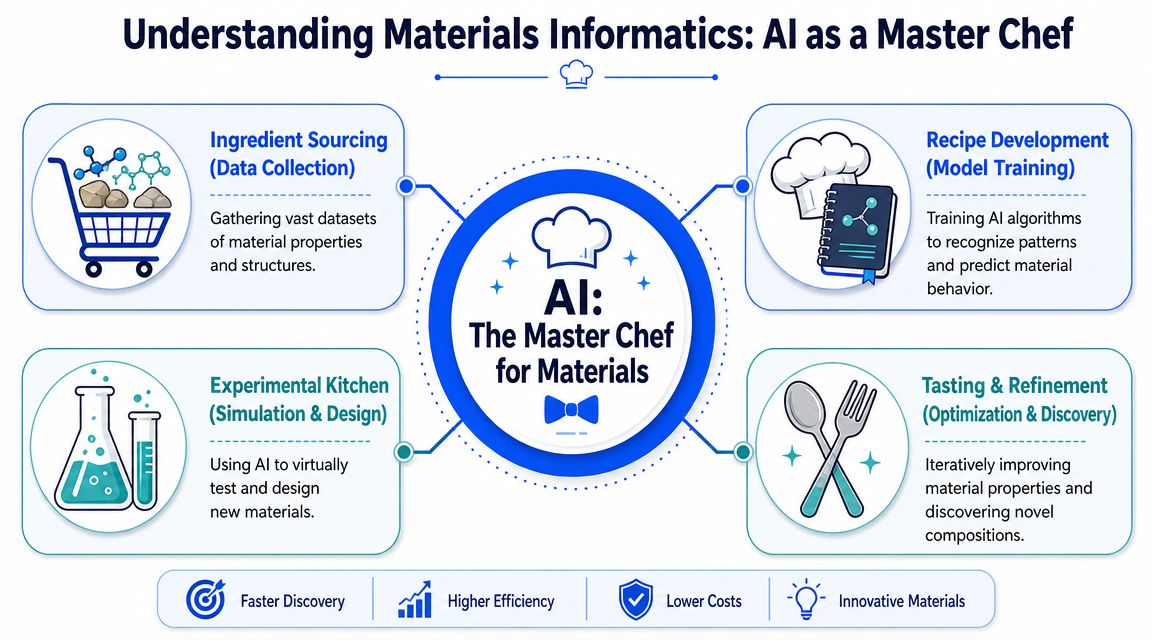
A GPS for formulation and materials search
Without materials informatics, teams often operate based on partial memory. One scientist remembers a failed additive combination from a past project. Another knows a processing condition that affected viscosity but never made it into a structured record. Valuable knowledge exists, but it's trapped in people, files, and disconnected systems.
A stronger setup creates a shared decision layer. Historical formulations, raw measurements, metadata, and test conditions get normalized into something models can use. This is also where knowledge capture matters. Many R&D teams are starting to use systems like Company Brain to make internal scientific context more searchable before they attempt more ambitious AI workflows.
What the closed loop looks like in practice
Materials informatics works best as a loop, not a one-time modeling exercise:
- Ingest the evidence. Pull in formulation records, compositions, process parameters, assay results, and notes from historical and active work.
- Train models on relationships. The model learns which variables correlate with target properties, failure modes, and process sensitivity.
- Predict and prioritize. The system ranks new candidates or experimental settings worth testing next.
- Learn from outcomes. Fresh lab results go back into the dataset so the next round is sharper than the last.
Materials informatics isn't about replacing domain expertise. It's about making domain expertise cumulative.
This distinction matters. In weak implementations, AI outputs get treated as answers. In strong ones, AI outputs are treated as recommendations with traceable reasoning. Scientists still apply feasibility judgment, synthetic accessibility constraints, safety requirements, and knowledge of manufacturing realities.
A good materials informatics program also accepts that not all data is equally useful. Clean failure data is often more valuable than polished success data because it tells the model where not to search. Process metadata can be as important as composition. And if your assay methods changed over time, the model needs that context or it may learn noise instead of chemistry.
The payoff is practical. Teams stop treating every campaign as a fresh search problem. They build a system that gets better as R&D proceeds.
Choosing the Right AI Models for Your R&D Goals
Most confusion around AI for materials science comes from treating "AI" as one thing. It isn't. Different model families answer different questions, and the wrong choice can waste months. The useful split is simple: predictive models estimate what a candidate is likely to do, while generative models propose what to try.
Predictive models versus generative models
If your team already has a decent amount of historical data and needs to forecast properties, a predictive approach usually creates value first. These models estimate outcomes such as stability, conductivity, strength, viscosity behavior, compatibility, or process response based on known inputs.
Generative approaches are different. They search for new candidates that meet a target profile. In current materials AI practice, one important pattern combines diffusion models to generate candidate crystal structures, graph neural networks to predict their properties, and natural-language interfaces to specify design constraints. That combination expands the search space while making it easier for scientists to describe what they want. Microsoft's MatterGen is one example of a generator whose candidates are then screened for viability by a physics-based model (practical overview of diffusion models, GNNs, and MatterGen-style workflows).
That generator-validator split is critical. A model that proposes thousands of candidates isn't useful by itself. You need a second layer that can reject implausible options before they reach the lab.
What each model family needs from your data
The model question is really a data question. Teams often ask which architecture they should use before they've checked whether their data includes consistent identifiers, process conditions, and trustworthy labels.
Here is a practical mapping:
| Model Type | Primary Function | Typical Data Required |
|---|---|---|
| Regression and classification models | Predict material properties, pass-fail outcomes, or formulation performance | Structured historical experiments with labeled outcomes, input variables, and consistent test conditions |
| Graph neural networks | Model atomic or molecular structures and infer structure-property relationships | Structural representations such as graphs, crystal information, composition details, and property labels |
| Diffusion models | Generate novel candidate structures or compositions | Large, well-curated sets of structures or compositions with enough consistency to learn realistic patterns |
| Language models and natural-language interfaces | Translate design intent into search constraints, summarize literature, and improve usability | Text corpora, internal notes, experiment records, and domain vocabulary connected to structured data |
| Physics-based screening models | Validate viability, stability, or feasibility of generated candidates | Simulation-ready representations, physical constraints, and integration with scientific modeling workflows |
A few trade-offs show up repeatedly in practice:
- If data is sparse but high quality, start with predictive models on one narrow problem.
- If data is broad but messy, invest first in normalization and ontology work.
- If scientists can't explain the recommendation, adoption will stall even if model accuracy looks good on paper.
- If your workflow requires novel candidate generation, keep a hard validation gate between ideation and experimental execution.
The best model for R&D isn't the most sophisticated one. It's the one your team can feed, audit, and use to make better experimental decisions this quarter.
For most enterprises, the first win doesn't come from a frontier architecture. It comes from matching the model to a tightly defined decision, then improving data quality around that decision.
Implementing an AI-Guided Experimentation Workflow
An AI-guided workflow should feel like a better version of how your lab already operates. If the system demands that scientists abandon their normal review, planning, and validation habits, adoption won't last. The goal is to build a loop where data capture, model inference, and experiment selection reinforce each other.
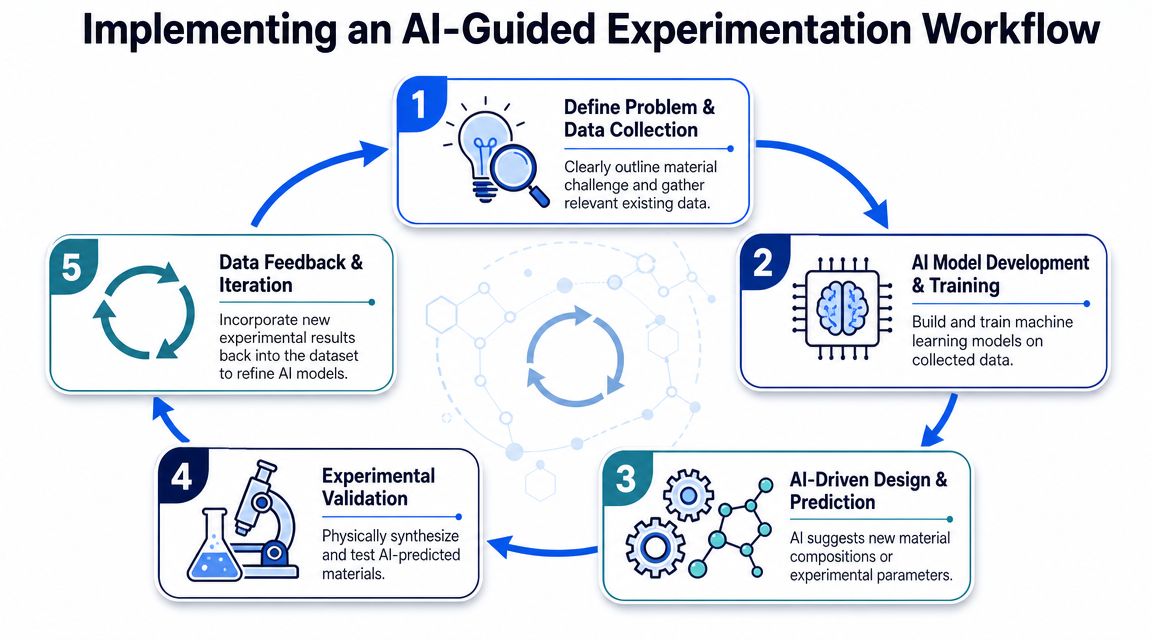
Start with data unification, not model selection
The first operational step is to unify data from spreadsheets, ELNs, LIMS exports, instrument files, and project notes into one governed backbone. This is the least glamorous part of the program, but it's usually where value starts. If your assay names vary by team, units shift between projects, or scale-up results aren't linked to lab records, your models won't be reliable.
This is also where a platform approach can help. For example, Polymerize provides a system that unifies fragmented experimental data, applies explainable domain-specific models, and supports secure deployment with enterprise controls. That combination is useful when the core problem is not just prediction, but operationalizing AI inside live R&D programs.
Once data is unified, build around a narrow, high-frequency decision. Good starting points include selecting the next formulation batch, identifying likely failure drivers, or ranking candidate compositions for a target property window.
Build a loop your scientists will actually use
The working loop is straightforward:
- Define the decision clearly. Ask one focused question such as which candidates should enter the next experiment round.
- Model with explanation in mind. Show feature importance, confidence signals, similar historical precedents, or causal clues where possible.
- Run a ranked shortlist. Give scientists a manageable set of candidates rather than flooding them with possibilities.
- Capture outcomes immediately. Don't let new results fall back into PDFs and slide decks.
- Refine the model continuously. Every new validated result should sharpen future recommendations.
A useful benchmark for workflow quality is whether scientists can answer three questions after each recommendation:
- Why did the system suggest this?
- What evidence supports the suggestion?
- What result from the next experiment would most improve the model?
When teams can answer those questions, trust rises.
A short demo of an AI-guided process helps make the operating model concrete:
The biggest implementation mistake is trying to automate the entire lab at once. Start with experiment prioritization, establish reliable feedback capture, then expand into formulation optimization, process tuning, and scale-up decision support.
Measuring Success with Real-World Use Cases
The best AI programs in materials R&D aren't judged by elegant model architecture. They're judged by lab economics. Did the team cut wasted work? Did they reach a viable formulation faster? Did they make better scale-up decisions with less rework?
The business metrics that matter in the lab
For a CTO or VP of R&D, the most useful KPIs are usually operational:
- Failed experiment reduction. Are scientists spending less time on low-probability candidates?
- Cycle-time compression. Does the team move faster from hypothesis to validated next step?
- Scale-up readiness. Are process-sensitive issues showing up earlier, before pilot and production work?
- Knowledge reuse. Are current teams benefiting from historical experiments instead of repeating them?
These metrics matter because they connect AI output to cost, throughput, and technical risk. A model can look impressive in a notebook and still create no enterprise value if scientists don't use it to change experiment selection.
Good AI use cases in materials science don't start with "Where can we use AI?" They start with "Where are we wasting the most lab effort today?"
That lens works across polymers, specialty chemicals, and advanced materials. In polymers, AI can help narrow additive and composition combinations worth testing. In specialty chemicals, it can expose process-property trade-offs earlier. In advanced materials programs, it can improve candidate ranking before expensive synthesis and characterization.
Why commercial adoption matters to technical teams
The commercial signal also matters. A market report projects the generative AI in material science market will reach USD 11.7 billion by 2034 with a 26.4% CAGR, and says the software segment held over 71% of total revenue in 2024, which supports the idea that practical value is concentrated in simulation, predictive modeling, and candidate screening rather than physical infrastructure alone (generative AI in material science market outlook).
That doesn't prove every deployment will work. It does show where buyers are putting money. They're not paying for AI as a science fair project. They're investing in software that helps teams screen candidates earlier and reduce unnecessary physical experimentation.
For R&D leaders, that's the use-case test. If a workflow changes what gets synthesized, tested, and scaled, it has business value. If it only produces interesting slides, it doesn't.
Your Roadmap for Enterprise-Scale Adoption
Enterprise adoption lives or dies on operating discipline. A promising pilot can still fail if security reviews drag on, data ownership is unclear, and scientists don't trust the recommendations. The path that works is phased, tightly scoped, and governed from the start.
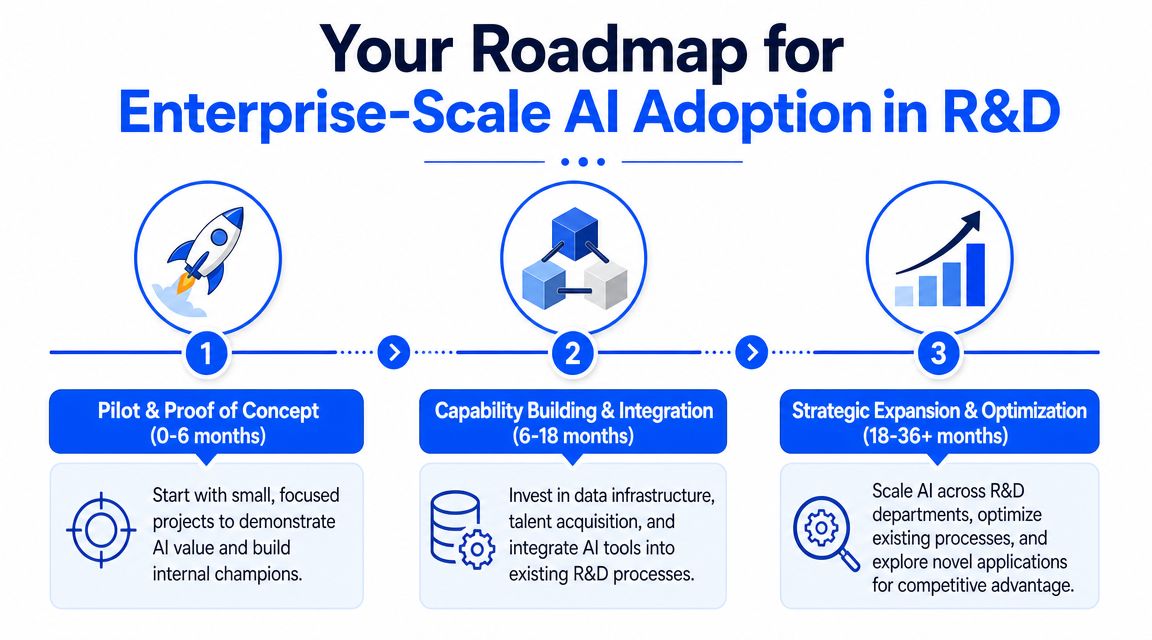
Phase one and phase two
Phase one is a pilot. Pick one problem with visible cost and a realistic data base. Good examples include formulation ranking, property prediction for a constrained materials family, or identifying variables associated with failed runs. Keep success criteria concrete and operational. Your scientists should be able to tell whether the system improved prioritization, not just whether a model achieved a decent benchmark.
Phase two is foundation building. In this phase, most organizations discover that AI readiness is really data readiness plus governance. You need a shared ontology, traceable experiment lineage, access controls, and clear ownership of model outputs. If this layer is weak, every new use case becomes a custom integration project.
A few controls matter early:
- Security and IP protection. Enterprise teams need role-based access, auditable workflows, and controls aligned to standards your procurement and infosec teams already recognize.
- Explainability. Scientists need to see why the model prefers one path over another.
- Human review points. Keep expert signoff in decisions that affect synthesis, safety, or process transfer.
- Data stewardship. Someone must own naming conventions, metadata completeness, and assay consistency.
Phase three and the operating model
By phase three, AI stops being a pilot capability and becomes part of how R&D runs. Teams use it across project intake, experiment design, candidate ranking, root-cause analysis, and handoff to scale-up groups. The system starts functioning as an institutional memory layer, not just a modeling layer.
The hard part at this stage isn't technical sophistication. It's consistency. Different business units need shared standards without losing local flexibility. Central teams need governance without turning every model request into a months-long process. Scientists need enough transparency to challenge the system when it conflicts with domain judgment.
The strongest enterprise programs treat AI as a governed decision system for R&D, not a collection of disconnected notebooks.
That mindset de-risks adoption. It also creates compounding returns, because every validated experiment improves not just one project, but the organization's ability to make better technical decisions across the portfolio.
If you're evaluating how to bring AI into materials R&D without creating another disconnected toolchain, Polymerize is worth a close look. It's built for polymers, chemicals, and advanced materials workflows where the challenge is combining fragmented experimental data, explainable modeling, and enterprise controls into one operating system for faster discovery and development.

