Most R&D leaders aren't asking whether AI is interesting anymore. They're asking why their materials programs still feel like a sequence of educated guesses, disconnected datasets, and expensive retesting. A formulation team runs one set of experiments in the lab, process engineers adjust conditions later, and months after that someone realizes the original assumptions were never captured in a reusable way.
That's the key opening for AI for material discovery. Not as a science-fair demo. As a way to turn scattered experimental history into a working system for choosing better experiments, earlier, with fewer dead ends and a clearer path to scale-up.
The mistake I see most often is treating discovery and development as separate worlds. They aren't. If a model suggests a promising material that can't be made reproducibly, can't tolerate process variation, or can't survive the handoff to pilot production, the discovery win was incomplete from the start.
Table of Contents
- Start with the records you already have
- What an AI-ready foundation actually includes
- What to fix first
Beyond Trial and Error The New R&D Imperative
Traditional materials development isn't broken. It's just reaching the limit of what manual iteration can do. Teams still rely on domain knowledge, bench skill, and hard-won intuition, but they're now working in material spaces that are too large and too interdependent for spreadsheet-era methods.
That's why AI for material discovery has moved from experimental curiosity to operating priority. One market estimate values the sector at USD 536.4 million in 2024 and projects USD 5,584.2 million by 2034, a 26.4% CAGR, while the same industry analysis says AI can shorten R&D cycles by 5 to 10 times and improve success rates for new materials by 40% to 60% when integrated into materials workflows, according to Market.us research on AI in materials discovery.
The numbers get attention. The operational implication matters more. If your team can screen broadly in silico, prioritize experiments with stronger odds, and learn from every failed run instead of burying it in a PDF or notebook entry, the entire R&D system changes shape.
Why legacy workflows now cost too much
The old pattern is familiar:
- Data stays fragmented: Formulation history lives in spreadsheets, characterization sits in instrument folders, and scale-up notes remain trapped in slide decks.
- Failure isn't encoded: A scientist knows why a sample failed, but the reasoning never becomes searchable training data.
- Development starts too late: Teams optimize for an attractive lab result, then discover later that viscosity, stability, throughput, or raw material variation break the concept in production.
Those problems don't disappear with a better model. They disappear when leadership treats historical experiments as a strategic asset.
Practical rule: If your scientists can't easily trace property outcomes back to composition, process conditions, and test method, you don't have an AI problem yet. You have a systems problem.
The shift leaders need to make
The useful framing isn't “Can AI invent a breakthrough material?” It's “Can we use AI to reduce search cost, increase learning per experiment, and connect discovery to manufacturability?”
That changes what good looks like. A successful program doesn't chase novelty first. It builds a repeatable decision loop where scientists use data to narrow the design space, test the right candidates, and carry forward process-relevant knowledge.
For enterprise teams, that's the critical imperative. Faster discovery only matters if it also improves development discipline.
What Is AI for Material Discovery Really
At its best, AI for material discovery acts like a digital working model of your material system. Not a perfect replica, and not a magic oracle. More like a lab partner that has studied years of formulations, process settings, property measurements, and failed trials, then uses those patterns to estimate what's worth trying next.
That distinction matters. The goal isn't for AI to replace scientific judgment. Rather, it is to extend judgment across a search space too large to explore manually.
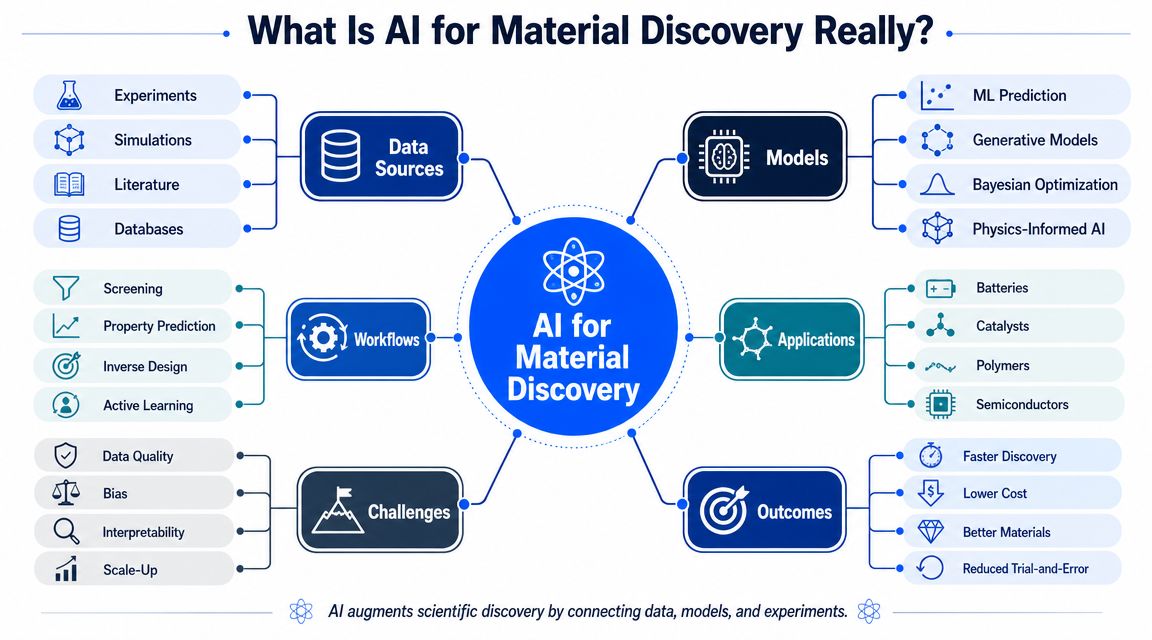
A digital twin mindset for formulations and materials
In practical terms, the model learns relationships such as these:
- Composition to property: Which monomer ratios, additives, fillers, or catalysts correlate with target performance
- Process to outcome: How mixing sequence, temperature, curing profile, residence time, or shear history affect the final result
- Trade-off patterns: Why improving one property often hurts another, and where the compromise zones sit
- Failure signatures: Which combinations tend to produce instability, poor reproducibility, weak adhesion, phase separation, or off-target morphology
That's why I prefer the phrase “decision support for materials design” over “AI replaces the lab.” The lab is still where truth gets established. AI helps the team spend lab time on options that are more defensible.
What the model is actually learning
For a materials team, the useful question isn't whether the algorithm is advanced. It's whether the system captures the variables your scientists know matter.
A decent platform should connect structured and semi-structured evidence. That includes formulations, test conditions, processing metadata, instrument outputs, and scientific notes. This is also why enterprise teams evaluating broader AI operating models can benefit from a practical resource like MTechZilla's guide on AI solutions, especially when they're aligning laboratory use cases with business systems and governance.
AI is most valuable when it turns past experiments into a ranked list of better future experiments.
A lot of disappointment in this field comes from asking models to answer questions the data never encoded. If particle size distribution was never captured consistently, the model won't infer it by force of optimism. If test methods changed across sites without standardization, the model may learn noise instead of chemistry.
That's why useful AI for material discovery is less about flashy prediction screens and more about building a system that understands the practical rules of your materials program. It learns from what your team has already seen, then helps them search the next layer of possibility with more discipline than trial and error alone.
The Engines Behind the Innovation AI and Physics Models
Most modern materials platforms rely on two different engines. One proposes candidates quickly. The other checks whether those candidates make physical sense. If you only have the first engine, you get creative ideas with weak grounding. If you only have the second, you get rigor at a pace many industrial programs can't afford.
Microsoft describes this workflow directly: generative models such as MatterGen can produce thousands of candidate materials under user-defined constraints, and physics-based validation through MatterSim is then used to test which candidates remain viable under realistic conditions such as temperature and pressure, as outlined in Microsoft's materials discovery research overview.
Prediction is not generation
A lot of teams conflate property prediction with generation. They're related, but they solve different problems.
A predictive model asks, “Given this known formulation or structure, what property should I expect?” That's useful when you already have candidate recipes and want to prioritize them.
A generative model asks, “What new candidates should I consider if I want a target property profile?” That's useful when the search space is broad and you don't want scientists manually enumerating possibilities.
In materials R&D, several model families show up repeatedly:
| Model Type | Best For | Data Requirement | Interpretability |
|---|---|---|---|
| Graph neural networks | Structure-property relationships where connectivity matters | Strong structured data and consistent representations | Moderate |
| Transformers | Learning patterns across sequences, text, and multimodal scientific data | Large, diverse datasets help | Lower without added explanation layers |
| Bayesian optimization models | Recommending next experiments in constrained search spaces | Works with smaller, iterative datasets | High to moderate |
| Generative models | Proposing novel structures or formulations under design constraints | Benefits from broad historical design space coverage | Lower unless paired with explanation tools |
| Physics-informed models | Blending learned patterns with domain constraints | Useful when data are limited or noisy | Higher than black-box alternatives |
Why physics still matters
Generative AI is fast. Physics is selective.
That's the right division of labor. The model can suggest many plausible candidates, but materials scientists still need a reality check on stability, feasibility, and behavior under conditions that resemble actual conditions. In chemistry terms, think of the generative model as the ideation engine and the simulator as the screening assay before anyone books instrument time.
This hybrid pattern works because materials discovery isn't just pattern recognition. It's a constrained physical problem. A formulation may look promising statistically and still fail because the underlying interactions don't support the result.
If your AI stack can generate candidates but can't tell you why they'll fail under realistic conditions, it's still a search accelerator, not a development system.
Comparing AI Model Approaches in Materials R&D
The practical trade-off isn't “Which model is smartest?” It's “Which model suits the maturity of our data and the decision we need to make?”
Some quick guidance:
- Use predictive models when your team has a known chemistry family and wants to reduce screening volume.
- Use generative models when the opportunity requires broader exploration across materials or formulations.
- Use Bayesian approaches when lab capacity is limited and each experiment must carry learning value.
- Use physics-informed systems when the cost of a false positive is high, especially near scale-up or qualification.
Teams also need to remember that model elegance doesn't compensate for poor question design. Asking a model to maximize tensile strength without capturing processability, cost constraints, or environmental durability often creates impressive outputs that no manufacturing team wants to inherit.
The winning stack is usually hybrid. Fast candidate generation. Domain-aware prediction. Physics-based filtering. Then human review before lab execution. That's how AI becomes useful in materials work instead of merely interesting.
Creating Your Data and Infrastructure Foundation
Most failures in AI for material discovery don't start with weak modeling. They start months earlier with bad data plumbing. A team tries to train a model and discovers the same ingredient has five names, processing conditions weren't logged consistently, and test results can't be linked back to exact sample histories.
An ACS review notes that progress in materials AI is still constrained by inconsistent data quality, limited interpretability, and weak standardized data-sharing frameworks, and highlights causal reasoning, physics-informed AI, and multimodal models as important next steps for more reliable industrial use, according to the ACS review on materials AI bottlenecks and next steps.
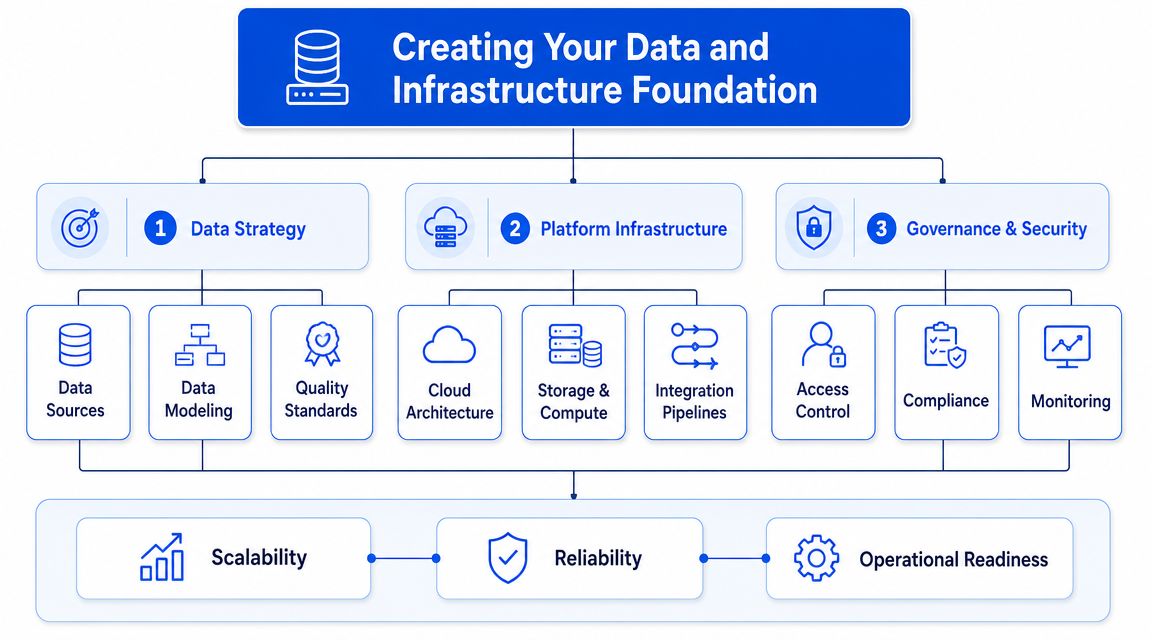
Start with the records you already have
You don't need perfect data to begin. You need traceable data.
For most enterprise labs, the starting sources are predictable:
- Spreadsheets: Legacy formulation tables, sample logs, property summaries
- ELNs and LIMS: Experimental procedures, instrument records, test outcomes
- Analytical files: Spectra, thermal analysis, microscopy, rheology, mechanical testing
- Human notes: Comments on anomalies, failed runs, operator observations, supplier changes
The key is to map these into a common experimental object. One sample, one formulation, one set of process conditions, one testing context, one outcome trail. If that object doesn't exist, your team will spend more time reconciling records than learning from them.
What an AI-ready foundation actually includes
An AI-ready materials data backbone usually has four parts.
First, ingestion. Data has to come out of spreadsheets, instrument exports, legacy repositories, and local folders without heroic manual effort.
Second, normalization. Ingredient names, units, process labels, and test methods need common definitions. Many teams find that “same formulation” isn't truly the same.
Third, context linking. Composition without process metadata is weak. Property data without sample lineage is weak. Scale-up notes without the originating formulation are weak. Value comes from connecting the chain.
Fourth, governance. Access controls, version history, auditability, and IP protection aren't IT extras. They determine whether scientists trust the system enough to use it.
A platform such as Polymerize can fit here as one option, since it's designed to unify fragmented experimental data across spreadsheets, ELNs, and silos into a centralized backbone for materials R&D, then layer explainable models on top. The specific tool matters less than the architecture principle. Your data foundation has to support both scientific traceability and model readiness.
Clean data isn't the goal. Useful data with lineage is the goal.
What to fix first
Don't launch with an enterprise-wide ontology project. Start where prediction and experiment planning can improve near-term decisions.
Good first targets include:
- A narrow material family where the chemistry and tests are already fairly consistent
- A high-friction workflow where scientists repeatedly search old results by memory
- A bottleneck property that drives many iterations, such as stability, cure behavior, or mechanical performance
- A recurring handoff problem between formulation and process teams
Teams get traction when they solve a painful workflow, not when they promise a perfect future data model. In practice, the best infrastructure programs begin with one live use case, then expand as scientists see that better structure leads to better recommendations.
An End-to-End Discovery Workflow in Action
The cleanest way to understand AI for material discovery is to follow a program from target definition to validated learning. Not in abstract terms, but in the way a real team works when it's trying to develop a material that has to survive both technical review and manufacturing scrutiny.
MIT's CRESt platform offers a useful proof point for this closed-loop style of work. It explored more than 900 chemistries and ran 3,500 electrochemical tests to discover a fuel-cell catalyst with record power density, showing the practical value of coupling AI with automated experimentation, as reported by MIT News on the CRESt closed-loop discovery platform.
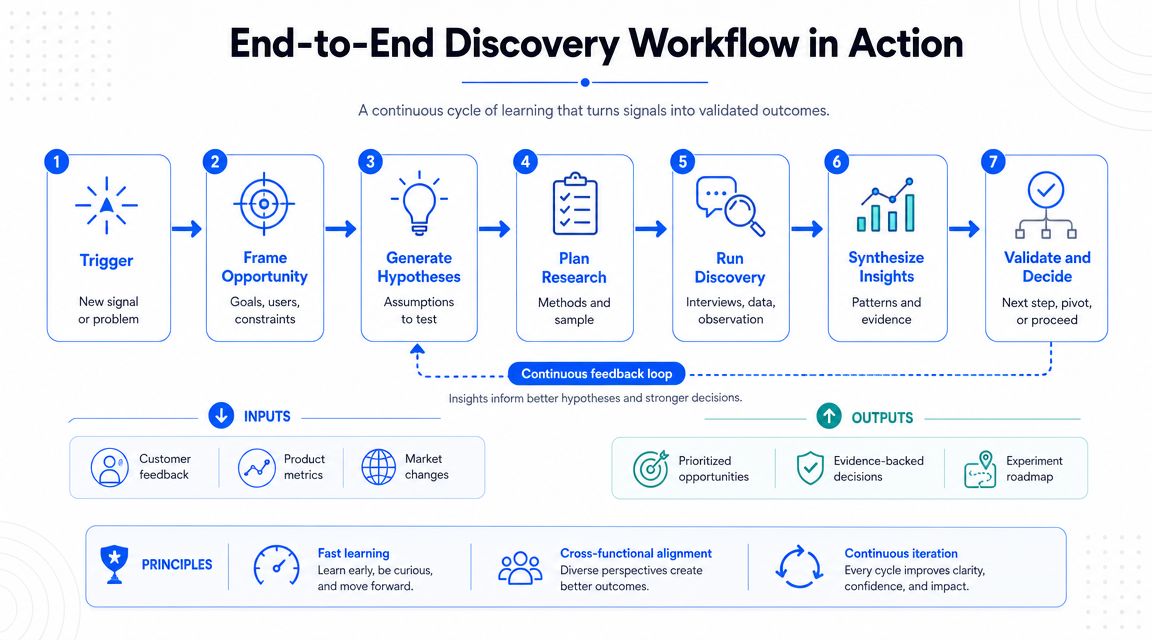
A polymer program example
Take a team developing a new high-performance polymer formulation. The commercial brief sounds simple enough: improve toughness, maintain thermal performance, preserve processability, and avoid unstable formulations. In the lab, that brief quickly becomes a multidimensional trade-off problem.
A workable AI-driven loop often looks like this:
Define the target window
The team sets acceptable ranges for key properties and flags hard constraints such as processing limits or material exclusions.Assemble historical evidence
Past formulations, compounding conditions, cure schedules, additive packages, and characterization results are linked into a common dataset.Train task-specific models
Separate models may estimate different outcomes, because toughness, viscosity, thermal resistance, and stability often respond to different factors.Generate or enumerate candidates
The platform proposes new formulations or ranks unexplored combinations near promising historical regions.Filter before synthesis
Candidates that violate obvious physical, formulation, or process constraints get removed early.Run the next best experiments
The lab executes a small, strategically chosen batch instead of a broad, intuition-heavy matrix.Feed results back into the system
Successful and failed runs both improve the next recommendation cycle.
That last step is where the system becomes cumulative rather than episodic. Every round sharpens the next one.
Where teams usually get stuck
The process sounds straightforward on a whiteboard. In real programs, the friction points are predictable.
- Targets are underspecified: The team asks for “better strength” without defining acceptable viscosity or line-speed behavior.
- Data misses experimental context: A result is logged, but mixing order or dwell time wasn't captured.
- Lab execution drifts: The recommended experiment is sound, but uncontrolled differences in preparation make the outcome hard to interpret.
- Development constraints arrive too late: Procurement, EHS, regulatory, or process engineering requirements appear after discovery choices have already narrowed the field.
Closed-loop discovery only works when the loop includes the realities that kill materials in development.
That's the reason the strongest workflows don't stop at ranking candidate materials. They also surface why a recommendation was made, what assumptions underlie it, and which unknowns still need empirical confirmation.
For leadership teams, that's the operational benefit. AI doesn't just accelerate ideation. It creates a tighter cycle between prediction, experiment, and manufacturing relevance. That's the bridge from discovery to development.
Calculating Business Value and Demonstrating ROI
The ROI discussion often gets framed too narrowly. Leadership teams ask whether the model is accurate. That matters, but it isn't the first business question. The first question is whether the system changes how money, time, and technical risk move through the R&D pipeline.
The economic case usually starts with waste reduction. Fewer low-information experiments. Faster elimination of bad candidate regions. Better reuse of existing knowledge. Earlier detection of formulations that won't survive process conditions. That's how AI for material discovery earns credibility with finance and operations, not by promising scientific magic.
The ROI case starts with avoided waste
A practical business case should track value across several layers:
| Value Area | What to Measure Qualitatively |
|---|---|
| Experiment efficiency | Whether scientists run fewer low-probability tests and learn more per run |
| Cycle time | Whether teams make formulation decisions earlier and with less rework |
| Scale-up readiness | Whether promising candidates fail less often when process constraints are introduced |
| Knowledge retention | Whether failed experiments become reusable assets instead of dead ends |
| Portfolio capacity | Whether the same team can advance more programs without proportional headcount growth |
These aren't vanity metrics. They map to real budget lines: consumables, instrument utilization, scientist time, pilot runs, qualification delays, and opportunity cost from slow launches.
Why trustworthy AI matters to finance as much as science
One of the most important shifts in this field is the move from single-point prediction toward trustworthy AI that exposes uncertainty. Brookhaven researchers, for example, developed a model that classifies XRD patterns across organic and inorganic materials while explicitly surfacing uncertainty, making outputs more actionable in real lab settings, according to Brookhaven National Laboratory's report on uncertainty-aware materials AI.
That matters for ROI because a confident-looking wrong answer is expensive. It burns lab time and erodes trust. A model that says “this is promising, but uncertainty is high because the data region is sparse” supports better portfolio decisions than one that hides its own limits.
Leadership should ask every vendor and internal team the same question: when the model is uncertain, how will a scientist know?
The strongest business cases combine three elements:
- Decision quality: Are teams selecting better next experiments?
- Scientific transparency: Can researchers see the drivers behind a recommendation?
- Development relevance: Do model outputs reflect the constraints that matter beyond the bench?
If those three pieces are in place, ROI becomes easier to show. Not because every prediction is correct, but because the organization gets better at spending effort where the odds justify it.
Your Implementation Roadmap and How to Avoid Pitfalls
Enterprise adoption usually goes wrong in one of two ways. Some teams start too big and drown in integration work. Others start with a flashy pilot that never connects to an operational problem. The right path sits in the middle. Narrow enough to deliver quickly, but important enough that people care about the result.
For leaders working through the broader question of what makes enterprise AI usable, I'd point them to the TrainsetAI perspective on enterprise AI. The useful lesson is simple: workable systems solve real workflow constraints first.
A phased rollout that works in enterprise R&D
Phase one is the pilot. Pick one material family, one decision bottleneck, and one cross-functional team. The ideal pilot has enough historical data to train a useful model and enough business pressure that improvement will be noticed. Examples include formulation optimization in a polymer line, additive screening in a coating system, or stability prediction in a specialty chemical workflow.
Phase two is controlled expansion. Once the pilot shows that scientists will use the recommendations, widen the scope carefully. Add more properties, more process variables, and more data sources. At this point, many teams should formalize governance, data definitions, and review routines.
Phase three is enterprise integration. Connect the system to how R&D operates. That means project reviews, lab planning, knowledge capture, and development handoffs. AI should become part of experiment selection and portfolio discussion, not a separate analytics island.
Common mistakes that slow adoption
Some pitfalls are technical. Most are organizational.
- Starting with the hardest science problem: Teams often choose a moonshot target with sparse data and many unknown variables. Start where repeat decisions already exist.
- Waiting for perfect data: You won't get it. Build around traceability, then improve data quality while the system is in use.
- Ignoring scientist trust: If recommendations arrive without rationale, adoption stalls. Scientists need context, not just scores.
- Separating discovery from development: If process and scale-up constraints aren't present early, the model optimizes for a lab result that won't travel.
- Treating AI as an IT deployment: This is a scientific operating model change. R&D leadership has to own it.
A strong implementation team usually includes a formulation or materials lead, a data owner, someone from process or scale-up, and an AI or digital lead who understands lab workflows. That mix matters more than a flashy launch plan.
The best sign that adoption is real isn't a dashboard. It's when scientists start asking the system before they design the next experiment, and process teams trust that early-stage recommendations already reflect downstream realities.
If you're evaluating how to connect AI-driven discovery with real development and scale-up work, Polymerize is built for that gap. It combines a centralized data backbone for materials R&D with explainable models for property prediction, formulation optimization, and next-experiment planning, so teams can move from scattered experimental history to a more disciplined path toward manufacturable materials.

