You already know the pattern. A resin system gains toughness, then viscosity climbs and processing becomes unstable. A coating hits adhesion targets, then cure time drifts outside what production can tolerate. A polymer blend improves impact resistance, then heat performance softens right where the product team needs margin.
That isn't a failure of experimentation. It's the normal shape of materials R&D.
Most formulation programs don't suffer from a lack of ideas. They suffer from competing objectives. Strength fights elongation. Cost fights performance. Barrier properties fight processability. Trial-and-error can still find useful candidates, but it rarely shows the full boundary of what's achievable. Teams end up debating local wins without seeing the actual full picture of trade-offs.
Multi objective optimization changes that. Instead of asking for one magic formulation, it searches for a set of high-quality compromises that are all defensible for different reasons. For materials scientists, that's the difference between guessing where the frontier might be and mapping it directly.
Table of Contents
- Introduction Beyond Single-Metric Wins
- Why one best answer usually doesn't exist
- What non-dominated actually means in the lab
- The Pareto front is a decision surface, not a final verdict
- Scalarization when priorities are already clear
- Evolutionary methods when the search space is rugged
- Bayesian methods when experiments are expensive
- Start with objectives that reflect decisions
- Move from data to candidates
- Use the front to choose experiments deliberately
- Is this different from running separate optimizations
- What if my lab data is noisy or sparse
- How should I choose weights in scalarization
- How many objectives are too many
- Can multi objective optimization fit into an actual lab workflow
Introduction Beyond Single-Metric Wins
Materials teams often talk as if a project has one target property. In practice, it almost never does. The business asks for lower cost, the application engineer wants better durability, manufacturing needs a stable process window, and regulatory constraints narrow the chemistry before the first sample is even mixed.
That's why single-metric optimization breaks down so quickly in formulation work. If you optimize only tensile strength, you may end up selecting a chemistry no one can scale. If you optimize only cost, you may eliminate the mechanism that produced the performance you needed. A single score can be useful for ranking, but it can also hide the trade-offs that matter most.
Multi objective optimization is useful because it treats those conflicts as the core problem, not as noise around a primary KPI. The field is formally grounded in Pareto optimality, named after Vilfredo Pareto, and the modern goal is not one universal optimum but a representative set of Pareto-optimal solutions that supports decision-making. In practice, problems often involve two or three objectives, though real applications can involve more in engineering, economics, logistics, and materials design, as described in the overview of multi-objective optimization.
Practical rule: If your team argues about which property matters most before it has mapped the feasible trade-off space, it's probably deciding too early.
For formulation chemists, that shift is powerful. It moves the conversation away from “which recipe won” and toward “which compromises are technically efficient, manufacturable, and worth validating.” That's how teams stop wandering through recipe space and start making choices that align with actual program constraints.
Understanding Pareto Optimality and Trade-Offs
Pareto optimality matters the moment a formulation team has two objectives that pull in different directions. Raise toughness and viscosity may climb. Cut cost and durability may fall below spec. Multi-objective optimization gives a disciplined way to identify which trade-offs are real, which candidates are clearly inferior, and which formulations deserve scarce lab time.
Why one best answer usually doesn't exist
In formulation work, a single “best” answer usually appears only after someone chooses how to combine competing goals. That choice may be reasonable, but it is still a choice. The chemistry often supports several efficient candidates, each representing a different balance of performance, processability, cost, stability, or regulatory margin.
This is the practical gap between academic definitions and real R&D decisions. A model can rank candidates. A project team still has to decide whether an extra increment of strength is worth a narrower processing window, or whether lower raw material cost justifies a drop in shelf life. Teams using AI platforms and experimental planning tools, including workflows discussed in Tekk.coach insights on AI planning, get more value when they preserve those trade-offs instead of collapsing them too early.
What non-dominated actually means in the lab
A non-dominated solution is a formulation that no other available option beats on every objective at the same time. That definition sounds abstract until you apply it to a bench program.
Suppose one coating gives better abrasion resistance but needs a higher cure temperature. Another cures under gentler conditions but gives up some surface hardness. Both can remain competitive. A third coating that cures hotter and performs worse is dominated. It should drop out of the conversation unless it offers some unmodeled benefit, such as supply security or easier EHS handling.
That filtering step is where Pareto thinking becomes useful in practice. It removes weak candidates without pretending that the remaining trade-offs have disappeared.
The Pareto front is a decision surface, not a final verdict
The Pareto front is the set of non-dominated solutions. For a formulation chemist, it is less a mathematical object than a working shortlist of scientifically efficient options. Every point on that front says the same thing: improving one objective will cost something somewhere else.
In materials R&D, that matters because project constraints change late and often. Procurement may tighten the cost target. Process engineering may reject a viscosity range that looked acceptable on paper. Customer testing may reveal that impact resistance matters more than modulus in the actual use case. A Pareto front keeps those alternatives visible so the team can respond without restarting from trial-and-error.
Three patterns show up often:
- One end of the front contains high-performance formulations with painful penalties in cost, processing, or scale-up risk.
- The middle of the front often holds candidates that survive technical and commercial review because the compromises are easier to justify.
- The other end of the front contains simpler or cheaper systems that still meet minimum thresholds and may be better choices for pilot production.
Pareto optimality does not make the decision for the team. It improves the quality of the options under review.
That is why this concept matters beyond theory. In a real formulation program, the job is not to hunt for one magic recipe. The job is to map the efficient frontier, understand what each compromise buys you, and choose the candidate that fits the current stage of development.
Common Algorithms for Formulation Optimization
Once the objectives are defined, the primary question is operational. How do you search a formulation space that may include compositional constraints, nonlinear interactions, and expensive experiments? Different algorithm families solve different versions of that problem, and using the wrong family can waste cycles even when the chemistry is sound.
Scalarization when priorities are already clear
Scalarization is the most direct approach. You assign weights to objectives and collapse them into one score. That makes optimization easier because the search engine can treat the problem like a single-objective task.
This works well when project priorities are settled. If the business already knows that mechanical performance matters more than raw material cost, a weighted score can be a practical instrument. It's also easier to explain to teams that are just starting with multi objective optimization.
The weakness is obvious. The weights become policy, not discovery. If your weighting scheme is wrong, the optimizer will confidently search in the wrong direction.
Evolutionary methods when the search space is rugged
Evolutionary algorithms are often a better fit when the search space is broad, nonlinear, and full of interacting variables. They operate through populations of candidate solutions, selecting, recombining, and mutating them over successive iterations. In formulation language, think of it as running many candidate recipes through repeated survival rounds while preserving diversity across trade-offs.
A comparative review reports that NSGA-II and NSGA-III are effective on continuous, smooth fronts when the number of objectives is small, while MOEA/D and HypE tend to perform better as the number of objectives increases, as summarized in this comparison of evolutionary multi-objective optimizations.
That distinction matters in industrial R&D. Don't default to one famous algorithm because you've seen it in papers. If your formulation problem has many coupled KPIs, decomposition-based or indicator-based methods may be more reliable than a dominance-first method.
| Algorithm Type | Core Mechanism | Best For |
|---|---|---|
| Scalarization | Converts several objectives into one weighted score | Programs with clear business priorities and straightforward ranking rules |
| Evolutionary methods | Searches with populations of candidate solutions and preserves trade-off diversity | Broad formulation spaces, nonlinear interactions, and complex Pareto fronts |
| Bayesian methods | Uses surrogate models to choose the next most informative experiments | Sparse data, costly experiments, and iterative lab campaigns |
Bayesian methods when experiments are expensive
Multi-objective Bayesian optimization is often the most practical choice when each experiment consumes real money, instrument time, or scarce feedstocks. Instead of evaluating a large population blindly, it builds a predictive model of the response surface and then proposes the next experiment based on expected learning and expected improvement across objectives.
That's attractive in materials programs where synthesis is slow or measurements are noisy. A good surrogate-guided loop won't replace scientific judgment, but it can help teams test fewer, better candidates.
The planning discipline matters here as much as the algorithm. If your objective definitions, constraints, and decision rules are fuzzy, even a powerful optimizer will produce a messy campaign. The same lesson shows up in software planning. Good systems perform better when the workflow captures dependencies clearly, which is why I recommend reviewing Tekk.coach insights on AI planning as a parallel example of how structured problem framing improves machine-guided search.
A practical tooling note belongs here too. Platforms such as Polymerize position multi-objective formulation optimization inside a broader materials informatics workflow, where predictive models, experimental history, and optimization routines live in one system rather than across disconnected spreadsheets and notebooks. That setup is often more important than the exact algorithm brand name.
Evaluating Success The Pareto Front and Hypervolume
Single-objective optimization ends with a winner. Multi objective optimization ends with a set. That changes how success should be judged. A run is useful if it returns a front that is both close to the best achievable trade-off boundary and broad enough to support an actual decision.
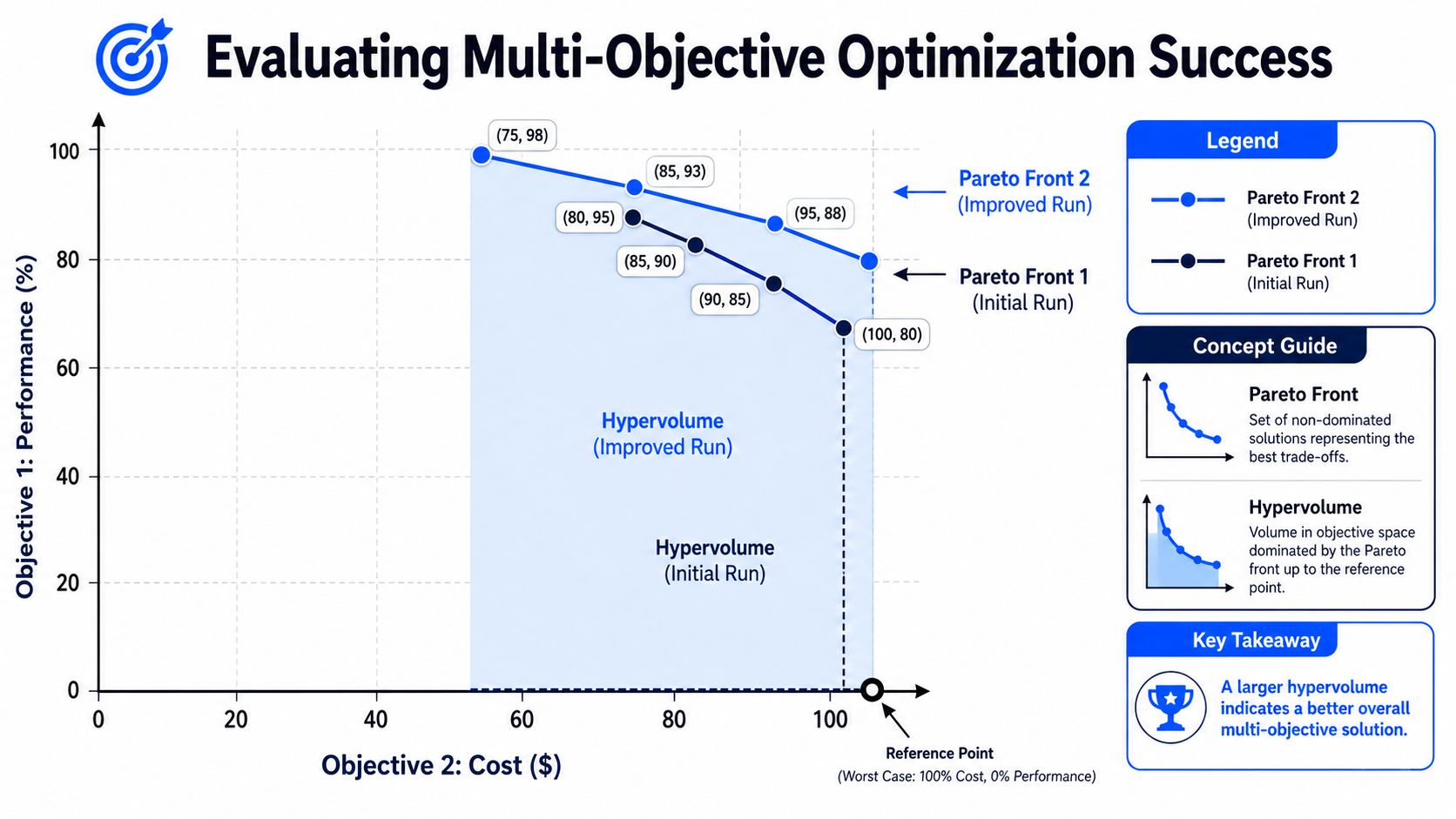
What a useful front looks like
In formulation work, the core output is a Pareto front, meaning a set of nondominated solutions where improving one objective necessarily worsens at least one other. That makes the result a family of trade-off designs rather than one point estimate. For recipe development, it helps teams rank candidate formulations by how efficiently they move along the frontier instead of chasing a scalar score that may conceal unacceptable compromises, as described in this explanation of Pareto fronts in multi-objective optimization.
A useful front usually has two properties:
- Convergence: The candidates appear close to the true efficient boundary rather than floating in clearly suboptimal regions.
- Diversity: The solutions are spread across the trade-off curve so the team can choose among distinct options.
A narrow cluster isn't enough. It may indicate the algorithm found one neighborhood and never explored the rest of the feasible chemistry space.
Where hypervolume helps and where it doesn't
Hypervolume is one of the most practical ways to compare fronts because it rewards both quality and spread. Conceptually, it measures how much of the objective space is dominated by the returned front relative to a chosen reference point. If one run produces a front that is both better positioned and more extensive, its hypervolume will be larger.
That makes hypervolume useful for comparing algorithms, settings, or campaign rounds. It's especially helpful when teams are tempted to overreact to one attractive point on the front. A single flashy candidate doesn't necessarily mean the run was better overall.
Don't evaluate an optimization campaign by its favorite point alone. Evaluate whether it gave the team enough high-quality options to make a strong decision.
Hypervolume still has limits. It depends on the reference point, and it compresses several qualities into one metric. In practice, I treat it as a screening metric, then inspect the front itself. Scientists should still look at candidate spacing, chemical plausibility, manufacturability, and whether the front captures the decision region the business cares about.
A Practical MOO Workflow in Materials R&D
Teams don't need a more elegant definition of optimization. They need a workflow they can run next week on a live project. A good example is adhesive development, where peel strength, open time, viscosity, and cost can all pull against one another.
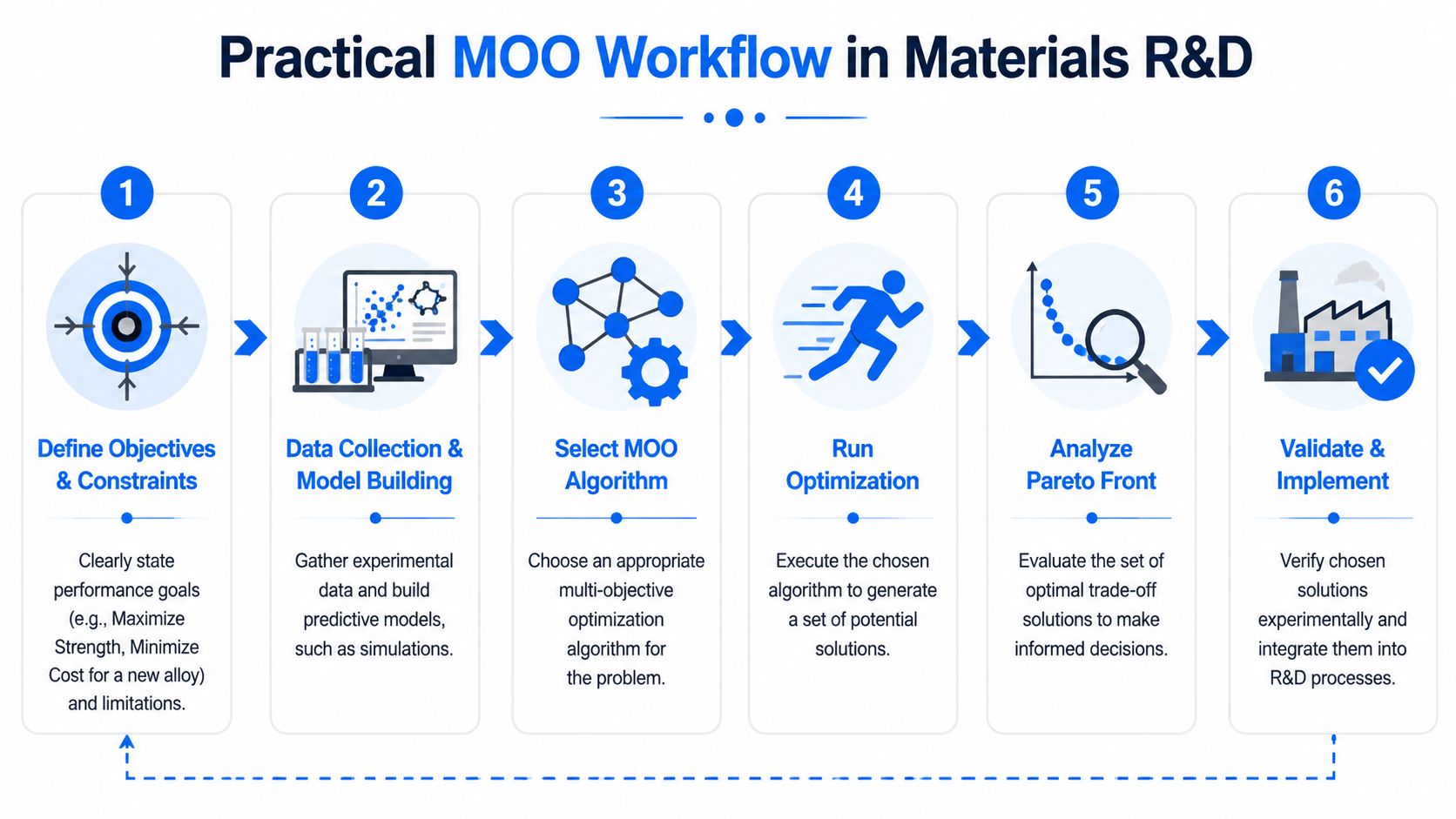
Start with objectives that reflect decisions
The first step is not model building. It's choosing objectives that map to real go or no-go decisions.
For an adhesive program, “maximize performance” is too vague. Better objectives are things like peel strength, open time, viscosity within a process window, and raw material cost within an acceptable bracket. Constraints matter just as much. If a solvent class is off-limits or a cure schedule cannot exceed a plant limit, encode that early.
A simple working sequence looks like this:
- Define the KPIs that matter commercially: Use the same metrics procurement, process engineering, and application teams will later use to accept or reject a candidate.
- Separate objectives from constraints: Shelf-life minimums, regulatory exclusions, and processing ceilings usually belong as hard filters, not as soft wishes.
- Agree on what success looks like: Decide whether the team wants a broad frontier for learning or a narrow search around a known operating window.
Move from data to candidates
Once the objectives are stable, organize the experimental data so the optimizer can learn from it. That means consistent formulations, comparable test methods, and clear metadata for process conditions. If one viscosity value came from a different shear protocol and no one marked it, the optimizer will absorb the inconsistency as if it were chemistry.
Then choose the search method that matches the campaign reality.
- If you have abundant historical data: Evolutionary methods can search broadly and expose unexpected trade-offs.
- If experiments are expensive and slow: Bayesian methods are usually more efficient because they propose the next informative trial rather than a large generation of candidates.
- If priorities are fixed by the program brief: Scalarization can be acceptable, especially early in adoption.
The best optimization workflow usually starts with a boring task done well: cleaning the experimental record so the model learns chemistry instead of lab noise.
Use the front to choose experiments deliberately
The optimizer should return a set of candidate formulations, not a single recommendation. That's where many teams slip back into old habits and pick the middle point. Don't do that automatically.
Choose validation candidates for different reasons. Take one formulation near the high-performance extreme if the team needs to know the technical ceiling. Take one balanced point if the product profile looks commercially realistic. Take one lower-cost or easier-to-process candidate if scale-up risk is becoming a gating factor.
A practical review meeting should ask:
| Decision question | What to inspect on the front |
|---|---|
| Where is the technical limit | The edge points that maximize a critical property |
| Where is the commercially balanced option | The central region with acceptable trade-offs across all KPIs |
| Where is the lowest implementation risk | Points that preserve processability, robustness, or cost discipline |
Then run the lab validation loop. Measure the candidates. Compare predicted and observed performance. Update the model. Repeat. That cycle is where multi objective optimization stops being a presentation concept and becomes an operating system for formulation work.
Common Pitfalls and How to Avoid Them
The most common failure mode in multi objective optimization isn't a bad algorithm. It's an undisciplined problem definition. Teams often ask the optimizer to solve every stakeholder concern at once, then wonder why the output is confusing.

Objective bloat is a real problem
Adding objectives feels rigorous. It often does the opposite. Research on many-objective optimization notes that adding more objectives does not automatically improve decision quality. Beyond a few objectives, dominance relations weaken and the Pareto set becomes harder to interpret, which is why methods increasingly rely on reference points and structured exploration rather than simple weighted-sum intuition, as discussed in this review of many-objective optimization challenges.
In lab terms, too many objectives can produce a frontier that is technically valid but strategically unusable. If every candidate is non-dominated because the objective set is too crowded, the optimizer hasn't narrowed the decision space in a meaningful way.
A better practice is to keep the objective set compact and move the rest into constraints, diagnostic metrics, or later-stage screening.
- Keep true decision drivers as objectives: Use the handful of KPIs that trade off and shape selection.
- Move pass-fail requirements into constraints: Regulatory exclusions and minimum thresholds usually belong here.
- Track secondary metrics separately: They still matter, but they don't all need to steer the search directly.
Bad front reading creates false confidence
Another pitfall is assuming the front explains itself. It doesn't. A point in the middle is not automatically the sensible compromise. Sometimes an endpoint is more valuable because it defines the technical ceiling. Sometimes a supposedly balanced point is fragile and will collapse under normal process variation.
No algorithm can rescue poorly measured data, either. If the training set mixes inconsistent test protocols, unlogged process changes, or sparse chemistry coverage, the front will look cleaner than the underlying evidence deserves.
If the Pareto front looks impressive but the lab notebook is messy, trust the notebook first.
The last trap is algorithm loyalty. Teams learn one method, often NSGA-II, then apply it to every problem. That's convenient, not strategic. Search method should follow objective count, data quality, experiment cost, and front geometry. In practice, matching the optimizer to the campaign matters more than having a favorite acronym.
FAQ About Multi-Objective Optimization
Is this different from running separate optimizations
Yes. Separate single-objective runs tell you the best tensile strength point, the best cost point, or the best viscosity point in isolation. They do not show which formulations stay competitive once those requirements collide in the same experiment plan.
In practice, that distinction matters at the bench. A coating that maximizes hardness on its own may become unusable once you add flexibility and cure speed to the decision. Multi objective optimization helps teams see the viable compromise set early, instead of discovering conflicts one screening round at a time.
What if my lab data is noisy or sparse
That is standard in materials R&D, especially in early formulation work where recipe space is broad and measurements come from multiple instruments, operators, or batches.
The right response is to treat uncertainty as part of the workflow. Use optimization methods that can rank candidates without overstating tiny differences, confirm promising regions with targeted experiments, and avoid acting as if two nearly identical predicted points are meaningfully different. For expensive lab programs, surrogate-guided search is often a better fit than brute-force exploration because it helps the team spend experiments where they reduce uncertainty or improve the trade-off surface.
How should I choose weights in scalarization
Choose weights only if the team can explain them in operational terms. If one objective gets twice the weight, someone should be able to defend that decision with product requirements, margin targets, processing constraints, or customer priorities.
Otherwise, weighted scalarization becomes a disguised opinion. It is still useful, but it should be treated as one decision policy, not a neutral answer. In formulation programs, I usually reserve weighting for cases where the business already has a clear preference structure, such as accepting a modest raw-material cost increase to hit a processing window that manufacturing requires.
How many objectives are too many
Too many objectives show up fast in real projects. The optimization keeps returning large sets of non-dominated candidates, and the team still cannot decide what to make next.
That usually means the objective set is mixing true selection criteria with secondary observations. A good rule in formulation work is to keep only the properties that determine the go or no-go decision as objectives. Put pass-fail requirements into constraints. Keep the rest as tracking metrics for later review. That structure makes the search easier to interpret and easier to act on in the lab.
Can multi objective optimization fit into an actual lab workflow
Yes, if the workflow is set up around decisions rather than algorithms.
A practical campaign starts with a narrow set of decision variables, a small number of competing KPIs, and test methods the lab can run consistently. The optimizer proposes candidates, the lab measures them, and the team updates the model with each batch of results. That loop is where multi objective optimization stops being an academic exercise and starts replacing trial-and-error with directed learning. Platforms such as Polymerize can support that process by keeping experimental data, property prediction, and formulation optimization in one environment instead of spreading them across disconnected files and tools.

