Your formulation team probably isn't short on ideas. It's short on throughput. Projects stall because the same pattern keeps repeating: a promising lab result fails when one raw material lot changes, a scale-up run behaves nothing like the bench batch, and years of experimental work sit trapped in spreadsheets, ELNs, PDFs, instrument files, and personal folders that nobody can search with confidence.
That isn't a chemistry problem alone. It's an operating model problem.
Chemical R&D still runs too often on fragmented memory, heroic scientists, and trial-and-error loops that made sense when portfolios were smaller and development timelines were looser. Leadership teams trying to accelerate product development in chemicals usually hear the same advice: adopt AI, modernize data, digitize the lab. The advice isn't wrong. It's just incomplete. What matters is the sequence. If you apply AI on top of messy experimental records and inconsistent process metadata, you'll automate confusion.
A better path is phased and practical. Start by making your data usable. Then apply models that scientists can interrogate. Then use those models to design the next experiment with intent. Finally, connect development decisions to scale-up outcomes and business KPIs leadership tracks.
Table of Contents
- Why chemical data breaks most AI projects
- What your unified data backbone should contain
- How to structure data without slowing the lab down
- Why generic models struggle in formulation work
- What explainability looks like in a lab
- How teams choose a model they can trust
- From exhaustive screening to sequential learning
- What a good next-experiment workflow looks like
- Why this changes R&D economics
The End of Trial and Error in Chemical R&D
Most chemical development programs don't fail because scientists lack skill. They fail because the system around those scientists makes learning too slow. One chemist adjusts a dispersant based on memory. Another repeats a similar test because the original result is buried in an attachment. A process engineer inherits a formulation package that lists ingredients and target properties but leaves out the conditions that made the batch work.
That cycle looks productive from the outside because the lab is busy. It isn't efficient.
Leaders who want to accelerate product development in chemicals need to start with a harder truth: more experiments don't automatically produce more insight. In many organizations, extra lab work adds more disconnected data, more inconsistent naming, and more debate about which result to trust. The result is a reactive culture. Teams respond to failures after they occur instead of designing programs that learn systematically.
Why the old model keeps slowing down
The traditional model worked when product portfolios were narrower and development complexity was lower. Today, specialty chemicals and advanced materials teams are balancing performance, cost, sustainability, regulatory requirements, and manufacturability at the same time. Every added variable multiplies the search space.
Three constraints show up repeatedly:
- Fragmented records: formulation ratios, batch notes, rheology data, microscopy images, and customer performance feedback live in different systems and formats.
- Uncaptured context: scientists often record outcomes, but not enough about process history, operator decisions, environmental conditions, or raw material variability.
- Weak reuse of prior learning: teams remember successful formulations better than failed paths, even though failed paths often contain the most useful boundary conditions.
Practical rule: If your scientists can't quickly answer "what have we already tried that is chemically similar under similar process conditions?", your R&D engine is still running on memory, not intelligence.
What replaces trial and error
The replacement isn't generic automation. It's a System of Intelligence that turns past experiments into decision support for the next one. That shift changes the role of AI in the lab. Instead of acting as a reporting layer, it becomes a planning layer.
A practical roadmap has four moves. Unify experimental data. Apply domain-specific, explainable models. Use those models to propose the next best experiment. Then connect lab choices to manufacturing behavior early enough to de-risk scale-up.
What works is deliberate sequencing. What doesn't work is buying a model first and hoping the organization catches up later. In chemical R&D, the quality of your decisions won't exceed the quality and structure of the experimental history behind them.
Building Your AI-Ready Data Foundation
Chemical companies often say they have a data problem when they really have a data-shape problem. The information exists. It just isn't organized in a way that supports prediction, comparison, or reuse. A polymer formulation spreadsheet may contain ingredient levels and tensile results, while the process history sits in a separate worksheet and the microscopy images live in a shared drive with filenames only the original scientist understands.
That fragmentation makes AI look harder than it is. Most failures start before modeling begins.

Why chemical data breaks most AI projects
Chemical R&D data has three characteristics that make simple digitization insufficient.
First, much of it is unstructured or semi-structured. Scientists write free-text observations such as "gelled during hold" or "phase separation after overnight rest." Those notes matter. They often explain outcome shifts better than a single numeric field.
Second, outcomes depend on both composition and process. A formulation isn't just a recipe. Mixing order, shear, temperature profile, hold time, pH adjustment sequence, drying conditions, and cure schedule can change performance materially.
Third, chemical programs evolve over time. Raw material grades change. Test methods get updated. Different sites use different naming conventions. If you don't normalize those differences, your historical data becomes harder to trust as it grows.
A centralized repository is useful. A contextualized repository is what enables prediction.
For teams dealing with image-heavy workflows, external resources such as a marketplace for AI training data can also help frame how annotation quality, schema design, and metadata consistency affect downstream model performance. That matters when microscopy, defect imaging, or spectral interpretation becomes part of your development workflow.
What your unified data backbone should contain
A useful R&D backbone doesn't need every field on day one. It does need the fields that explain why a result happened. At minimum, leadership should expect consolidation across these categories:
| Data category | What to capture |
|---|---|
| Material identity | ingredient names, synonyms, supplier references, lot identifiers, grade, purity, key descriptors |
| Formulation structure | component ratios, concentration basis, order of addition, premix details, solvent system |
| Process conditions | mixing speed, temperature path, pressure, residence time, cure conditions, drying profile |
| Analytical outputs | viscosity, particle size, thermal behavior, mechanical properties, stability observations |
| Experiment context | operator notes, protocol version, instrument method, deviations, pass/fail interpretation |
| Visual and instrument files | microscopy images, spectra, chromatograms, raw exports, linked attachments |
| Scale and downstream results | bench batch details, pilot outcomes, quality deviations, production observations |
How to structure data without slowing the lab down
The wrong way to build an AI-ready foundation is to impose a documentation burden scientists won't maintain. The right way is to capture a small set of mandatory fields consistently, then layer richer metadata where it adds decision value.
A practical build sequence looks like this:
- Standardize names first. Create controlled vocabularies for materials, tests, units, and projects. Don't let one resin exist under four aliases.
- Map critical workflows. Start with high-value programs such as formulation screening, stability testing, or scale-up transfer.
- Define minimum viable metadata. Require the fields that are essential for comparison and search. Keep optional fields where flexibility matters.
- Link raw files to structured records. Don't strip away source evidence. Keep instrument outputs and images connected to the experiment record.
- Set ownership. Someone must govern schemas, quality checks, and change control. AI readiness doesn't emerge by committee.
One option in this category is Polymerize Connect, which is designed to unify fragmented experimental data across spreadsheets, ELNs, and silos into a centralized backbone for materials R&D. The important consideration isn't the brand name alone. It's whether the system preserves scientific context while making records searchable and interoperable.
Applying Domain-Specific and Explainable AI Models
Once data is unified, the next mistake is reaching for the most impressive-looking algorithm rather than the most usable one. In chemical R&D, scientists don't adopt models because they are mathematically elegant. They adopt them when the models help make better decisions under uncertainty.
That usually means domain-specific and explainable AI, not a generic black box.
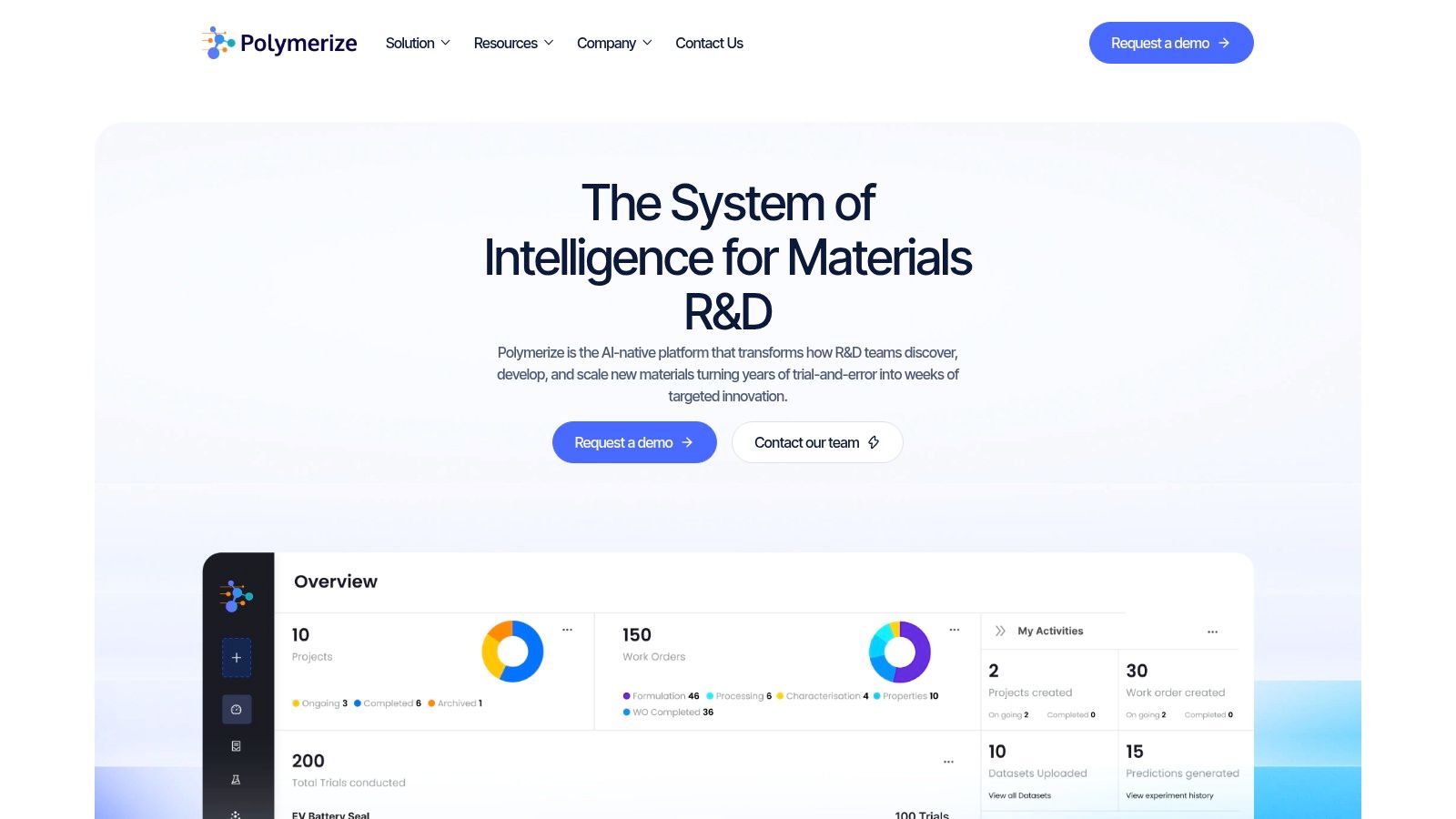
Why generic models struggle in formulation work
A generic machine learning stack can classify, rank, and optimize patterns. But chemical development has constraints that generic tools often treat as noise. Ingredient interactions aren't independent. Process variables affect outcomes in nonlinear ways. Sparse historical datasets are common. Failed experiments matter as much as successful ones. Scientific plausibility matters because teams need to decide whether to run a recommendation in the lab.
A domain-specific model is built around those realities. It should handle compositional data, process metadata, mixed data types, and practical experimental sparsity. It must also support the way chemists reason: trade-offs, boundary conditions, and mechanism-informed judgment.
Leadership should be careful with vendor selection. If a platform only outputs a score and a recommendation, it may impress in a demo and fail in the lab.
What explainability looks like in a lab
Scientists don't reject AI because they dislike prediction. They reject unsupported prediction. If a model says a formulation is likely to hit the target property range, the team needs to know why the model believes that.
A useful explainable workflow surfaces things such as:
- Key drivers: which ingredients, ratios, or process conditions most influenced the prediction
- Confidence cues: where the model is interpolating from similar history and where it's extrapolating into less familiar space
- Historical precedents: which prior experiments look most relevant to the current recommendation
- Trade-off visibility: how pushing one property may affect another
Imagine reviewing a junior scientist's recommendation. You wouldn't accept "I have a good feeling about sample 42" as a basis for the next run. You'd ask what data supports it, what assumptions are built in, and how comparable the prior examples really are. Explainable AI should answer those questions before the lab spends a day on the batch.
If a model can't show its reasoning in scientist-friendly terms, it won't change behavior. It will become a dashboard people visit and then ignore.
For leadership evaluating partners and broader digital maturity, it can help to compare how providers frame AI solutions for business growth across governance, adoption, and operational fit. In R&D, growth comes from better scientific decisions, not just more software features.
How teams choose a model they can trust
Trust doesn't come from marketing claims. It comes from disciplined validation in real workflows. I recommend three tests.
First, test whether the model can rank plausible experiments, not just fit historical data. A model that explains the past but doesn't improve future experiment selection isn't doing enough.
Second, compare model outputs against scientist intuition in a structured review. Alignment isn't required every time. Useful disagreement is fine. But the disagreement must be interpretable.
Third, validate in the smallest meaningful deployment. Pick one formulation family, one property cluster, and one decision point that matters. Trust grows when scientists can see a model influence live work without forcing a full organizational reset.
Designing the Next Best Experiment
A project review goes off track in a familiar way. The team has already run 40 formulations, learned a little from each, and still cannot say which three runs should happen next. One scientist wants to follow intuition. Another wants a larger DoE matrix. Leadership sees a queue of experiments, but not a faster path to a decision.
That is the point where AI should start paying for itself.
AI earns its place in chemical R&D when it helps teams choose the next experiment with higher confidence and fewer wasted runs. The goal is not more model output. The goal is a shorter route from messy experimental history to a formulation or process window worth scaling.
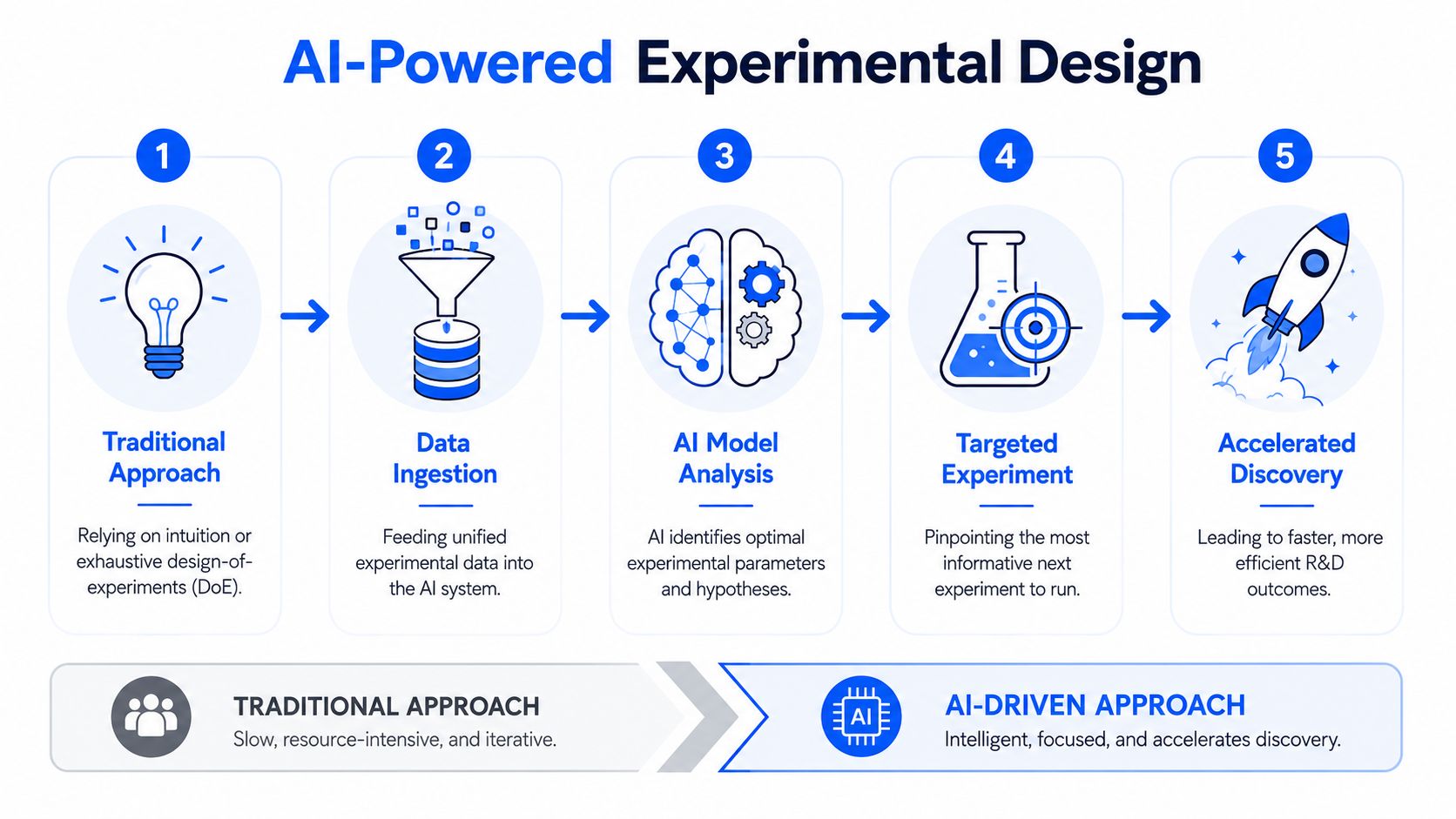
From exhaustive screening to sequential learning
Chemical teams usually choose between two imperfect options. They trust experienced formulators to spot the next promising combination, or they expand the experimental grid and hope coverage reveals the answer. Both methods can work. Both also burn time when the design space includes formulation variables, process settings, raw material variability, and multiple property targets.
Sequential learning changes the operating model. The system reviews what has already been tested, estimates where uncertainty is highest, and ranks the next run by expected decision value. In practice, that means selecting experiments that either move the team closer to the target region or eliminate a costly dead end early.
That distinction matters in chemicals because the objective is rarely one variable in isolation. Teams may need to improve adhesion while holding viscosity inside a processing limit. They may need better thermal resistance without destabilizing cure behavior. They may need to remove a regulated ingredient and still preserve performance across several test methods.
A practical comparison looks like this:
| Approach | What usually drives selection | Common weakness |
|---|---|---|
| Intuition-led | expert memory, heuristics, recent project experience | hard to scale, easy to bias toward familiar chemistry |
| Broad DoE | statistical coverage of factor space | can spend too much effort on low-value regions |
| AI-guided sequential learning | model-informed ranking of informative next runs | depends on data quality and disciplined feedback loops |
Polymerize has reported fewer failed experiments early in deployment for teams using AI-guided experimental design. For leadership, the significance is straightforward. Failed experiments do not only consume reagents. They use analyst hours, instrument capacity, project attention, and often delay the moment when a program can either advance or be stopped with confidence.
A short demo of the workflow is useful before you try to redesign a whole pipeline:
What a good next-experiment workflow looks like
The strongest teams treat this as an operating loop, not a recommendation engine dropped on top of the lab.
Start with a decision the business cares about. That could be finding a viable formulation window for a customer brief, reducing the number of screening rounds before pilot material, or identifying whether a reformulation path is still worth funding. If the objective is vague, the model will return technically interesting suggestions that do not help the program move.
Then define the search space with real constraints included. In chemicals, that means composition ranges, process variables, raw material substitutions, test methods, supply limitations, safety limits, and any property thresholds that would disqualify a candidate. Teams often miss value here because they score theoretical combinations that no lab or plant would ever run.
Next, rank experiments by learning value. Some runs are attractive because they are likely to succeed. Others are more useful because they clarify a boundary condition, expose a nonlinear effect, or test whether a process variable matters more than composition. Good systems support both. Great systems make the trade-off visible so scientists can choose deliberately.
Then close the loop with full experimental context. Capture failed runs, partial results, operator notes, lot-specific raw material behavior, and deviations from the intended method. In my experience, many programs lose momentum at this point. The model improves slowly if the lab records only final pass-fail outcomes and drops the details that explain why an experiment behaved differently than expected.
Field note: The next best experiment is often the run that reduces uncertainty around a critical boundary, not the one with the highest predicted performance.
Why this changes R&D economics
The value comes from reducing low-information work. When scientists stop spending weeks on combinations that add little insight, the lab can redirect time toward confirmation, application testing, customer samples, and preparation for transfer.
There is a trade-off. Sequential learning requires discipline. Teams need cleaner capture of experimental conditions, faster feedback into the model, and agreement on what success means. Without that operating discipline, AI produces ranked suggestions but does not change cycle time.
Leaders should evaluate the workflow with simple questions. Did the team cut avoidable experiments? Did it reach a decision point sooner? Did it identify failure modes earlier, before scale-up planning began? Those are the markers of a system that improves product development, rather than adding another layer of software.
Optimizing Pathways from Lab to Production
A formulation that performs well in a controlled lab environment can still fail during transfer. The usual reasons aren't mysterious. The process window was narrower than the team realized. A raw material attribute shifted outside a hidden tolerance. Mixing energy changed with vessel geometry. Drying or cure behavior amplified a variability source that looked harmless at bench scale.
Scale-up problems often appear late because development records separate formulation knowledge from production knowledge. R&D stores composition and test results. Manufacturing stores process data and deviations. Quality stores release outcomes. Each group sees part of the pattern.
Scale-up fails for predictable reasons
The handoff breaks down when the development package treats process as an implementation detail rather than part of the product definition. In chemicals, process is often inseparable from performance.
Leaders can reduce that risk by connecting specific development variables to downstream manufacturing behavior, including:
- Raw material variability: changes in grade behavior, moisture, particle size, or impurity profile
- Process sensitivity: dependence on shear history, temperature ramp, hold time, or order of addition
- Measurement drift: method changes between lab, pilot, and plant that make results look inconsistent
- Quality boundaries: subtle conditions where a product still passes lab screens but becomes difficult to manufacture consistently
The most expensive failed experiment may be the one that "worked" in the lab but taught the organization the wrong lesson about scale.
A connected model of formulation and process
The value of a unified R&D backbone becomes evident once more, though for a different application. Instead of asking only "which formulation should we test next?", the organization starts asking "which formulations are stable enough to survive transfer?"
The answer usually comes from combining formulation data with process windows and production observations. A model can then help teams identify conditions under which a formulation remains stable, processable, and within quality specifications. That gives process engineers a more realistic starting point than a nominal recipe and a handful of lab test values.
An effective scale-up workflow typically includes:
- Transfer the full experiment context. Bench success criteria should include process history, not just formulation composition.
- Model reliability, not peak performance alone. The highest-performing sample may be too sensitive to run reliably at production scale.
- Simulate likely variability sources. Raw material and process shifts should be tested against expected operating conditions.
- Feed plant learning back into R&D. Production deviations are not downstream noise. They are training data for better development decisions.
Companies that do this well shorten the distance between invention and manufacturability. They stop rewarding formulations only for peak lab performance and start rewarding them for operational resilience.
Implementing and Measuring Your R&D Transformation
Most digital transformation programs in chemical R&D fail at the operating-model layer, not the technical layer. The company buys tools, runs a pilot, and then discovers that nobody agreed on data ownership, validation standards, access controls, or success metrics. The result is predictable: the science team sees extra work, IT sees risk, and leadership sees no clear return.
That failure is avoidable if implementation starts with governance and ends with measurement.
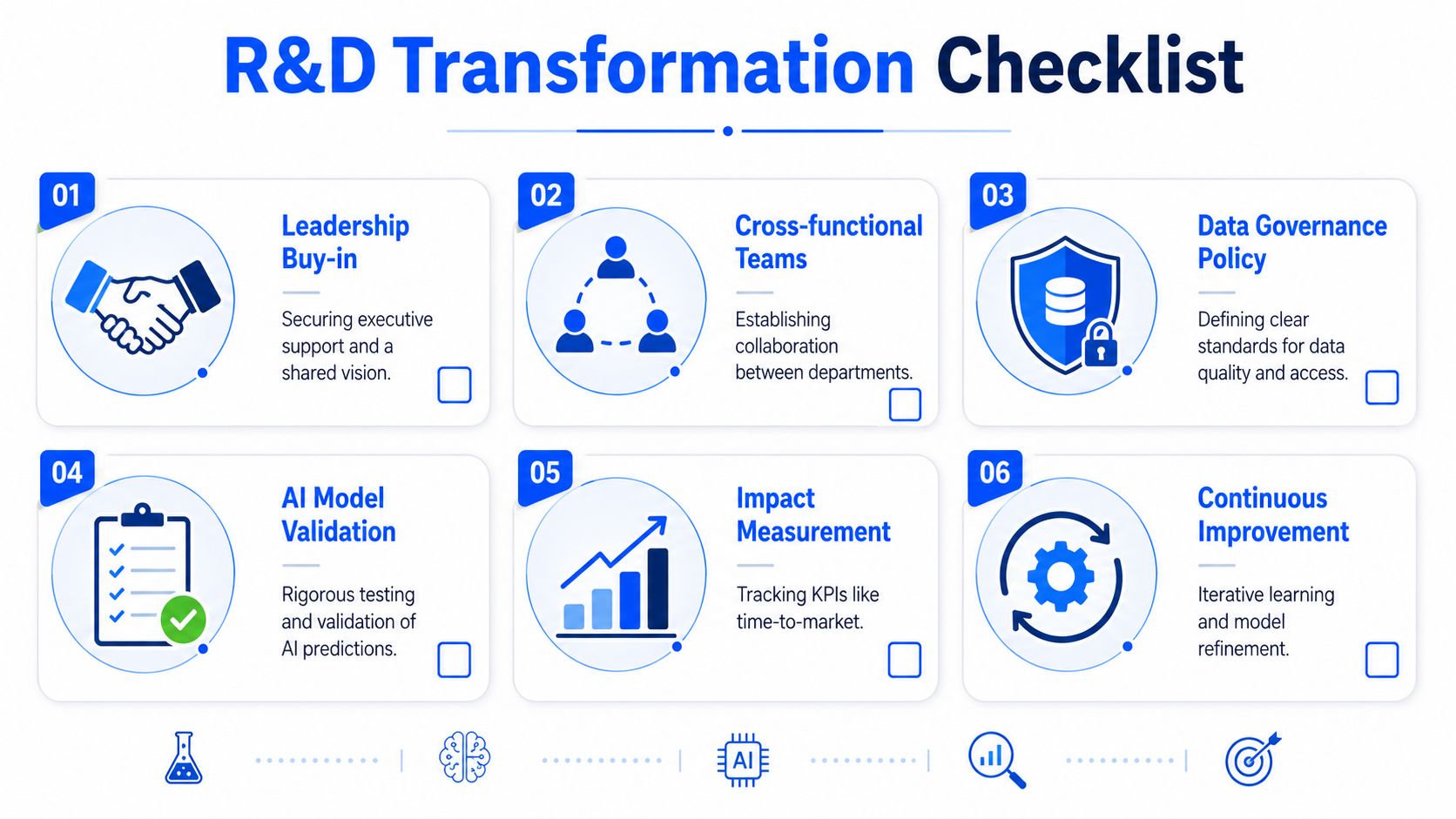
The operating model leadership needs to sponsor
For enterprise adoption, the minimum viable structure is straightforward.
- Executive sponsorship: one accountable leader should own R&D transformation outcomes, not just software selection.
- Cross-functional design: R&D, process engineering, quality, IT, and data governance need a shared operating rhythm.
- IP and security controls: role-based access, auditability, and compliance standards matter because experimental data is core intellectual property.
- Model validation discipline: scientists need clear criteria for when a model is advisory, when it is trusted, and when it must be reviewed manually.
The security conversation can't be an afterthought. Platforms handling proprietary formulations and process know-how should support enterprise controls such as ISO 27001 and SOC 2, along with role-based access and privacy compliance where relevant. In chemical R&D, trust in the system depends as much on protection of IP as on prediction quality.
KPIs that show whether transformation is working
The best KPI set is small enough to manage and close enough to scientific work that teams can influence it directly.
I recommend tracking a balanced scorecard across four dimensions:
| KPI | What it tells leadership |
|---|---|
| Failed experiment rate | whether experiment selection is becoming more targeted |
| Time to achieve target properties | whether teams are converging faster on viable formulations |
| R&D cost per project | whether effort, material use, and iteration load are falling |
| Scale-up success rate | whether development learning is transferring into production reliably |
Don't overload the dashboard. A few operational definitions, applied consistently, are worth more than a long list of vanity metrics. For example, define what counts as a failed experiment, what counts as target attainment, and how scale-up success is measured across sites.
One more point matters. Measure adoption behavior alongside outcomes. If scientists aren't using recommendations, or if they bypass the data capture process, the issue may not be model quality. It may be workflow friction, weak training, or unclear accountability.
A strong implementation starts small, proves value in one workflow, and expands with discipline. That's how leaders accelerate product development in chemicals without turning AI into another disconnected initiative.
If your team is trying to move from scattered lab records to AI-guided formulation and scale-up, Polymerize is one platform built specifically for polymers, chemicals, and advanced materials. It combines data unification, explainable domain models, and experiment planning in a workflow designed for enterprise R&D.

