A scale-up review goes sideways in a way most R&D leaders know too well. The pilot batch misses a target property. The team knows a similar formulation worked months earlier, under slightly different mixing conditions and with a different raw material lot. Then the search begins. Instrument files sit on one server. Process notes live in a spreadsheet. A scientist has key observations in a personal notebook. The analytical images are named well enough for the original author, but not for anyone else.
That's not a storage problem. It's an organizational memory problem.
In materials and chemical R&D, scattered data behaves like parts stored in unlabeled bins across three warehouses. You still “have” the parts, but rebuilding the machine becomes slow, expensive, and uncertain. Scientific data management software exists to solve that problem by giving experimental data structure, context, and retrievability across the research lifecycle.
That's one reason this category has moved quickly from specialist tooling to strategic infrastructure. The global scientific data management system market was valued at USD 121.95 million in 2024 and is projected to reach USD 4,668.89 million by 2034, implying a 44.00% CAGR from 2025 to 2034, according to Polaris Market Research's scientific data management system market analysis.
The shift, though, isn't just better archiving. It's that R&D teams now need a data backbone that can support search, reuse, reproducibility, and eventually AI-guided experiment planning. If your historical data can't be reconstructed, connected, and computed against, it won't help your scientists make better decisions.
Table of Contents
- Integration is the starting point
- Metadata turns files into usable knowledge
- Search and controls determine daily value
Introduction The Data Chaos in Modern R&D
A lot of R&D organizations still run on heroic effort. Scientists remember where the useful data is. Senior formulators know which instrument output matters. Someone on the team can usually find the method version that produced the best result. That works until a project changes hands, a program scales, or a critical person leaves.
The cost shows up in subtle ways first. Teams repeat experiments because they can't trust or locate previous results. They argue over whether two datasets are comparable because naming conventions changed. Process development inherits a formulation history that's technically complete but practically unreadable.
Poor data flow in R&D looks like a lab problem on the surface. In practice, it becomes a business problem when programs slow down, transfer poorly, or fail to reuse prior learning.
Scientific data management software gives organizations a central system for handling scientific data with enough structure that another team, another site, or another future project can effectively use it. That matters in materials discovery, where the experimental outcome often depends on a chain of context. Raw material source, environmental conditions, instrument settings, sample prep, operator choices, and downstream characterization can all affect interpretation.
Without that context, historical data becomes a warehouse of sealed boxes. With it, the same history becomes searchable institutional knowledge.
Where the breakdown usually starts
The pattern is familiar:
- Instrument silos: Analytical systems generate rich files, but each vendor format lives in its own corner.
- Notebook silos: ELNs and paper notebooks capture intent, but not always the machine-readable result.
- Spreadsheet drift: Key formulation parameters get copied into local files, then fork into multiple “final” versions.
- Weak traceability: Teams know what happened in broad terms, but can't reliably reconstruct how a result was generated.
R&D leaders usually don't need another reminder that data is valuable. They need a way to turn fragmented records into an operational asset that supports daily science and future model-driven discovery.
What Is Scientific Data Management Software
Scientific data management software is specialized software for storing, managing, and manipulating large volumes of scientific data, with core functions that include metadata management, integration from multiple sources, quality control, retrieval, analysis, archiving, and compliance support, as defined by LabKey's overview of scientific data management systems.
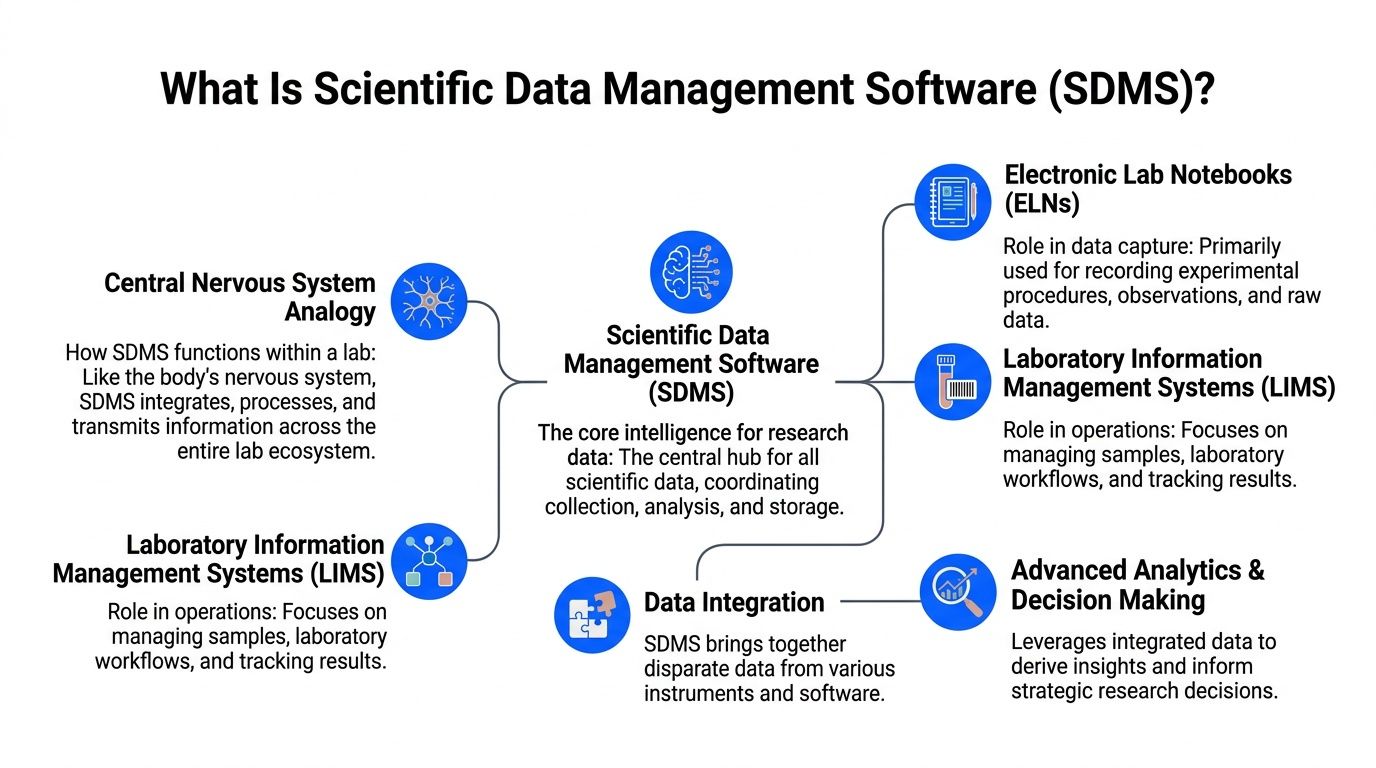
If that sounds broad, it is. The practical way to think about an SDMS is as a specialized librarian with a logistics function. A basic archive stores books on shelves. A good librarian knows the subject, author, edition, cross-reference, and borrowing history. An SDMS does the same for scientific information. It doesn't just hold files. It preserves what those files mean, how they relate, and when they should be trusted.
Where SDMS sits in the stack
Many teams confuse SDMS with adjacent tools, especially ELNs and LIMS. They overlap, but they're not the same thing.
| System | Primary role | What it handles well | What it usually doesn't solve alone |
|---|---|---|---|
| ELN | Experimental documentation | Procedures, observations, experiment records | Broad instrument file integration and enterprise-scale data unification |
| LIMS | Sample and workflow management | Sample tracking, operational workflows, status control | Rich scientific context across heterogeneous research data |
| SDMS | Data integration and contextualization | Instrument outputs, metadata, retrieval, archiving, traceability | It won't replace every workflow tool or scientist-facing record system |
The best deployments treat SDMS as the connective tissue. ELNs capture what scientists intended and observed. LIMS governs sample and process flow. The SDMS links machine outputs, metadata, and related records so data remains usable across systems instead of stranded inside each one.
Why context matters more than storage
The strongest SDMS programs don't start by asking, “Where will we put the files?” They start by asking, “What must a future scientist know to reuse this result?”
That changes design decisions immediately:
- Raw files need lineage: The original instrument output should remain connected to derived results.
- Metadata needs structure: Project, material, batch, operator, method, and conditions should be attached in consistent ways.
- Relationships matter: A characterization result should connect back to a formulation, a sample, and the process used to create it.
Practical rule: If a scientist can find a file but still can't tell whether it applies to the current problem, your data system is archiving records, not managing knowledge.
That distinction becomes decisive once teams want to compare historical experiments, support cross-site collaboration, or prepare data for analytics and AI.
Core Capabilities of a Modern SDMS
Modern SDMS platforms are expected to act as a central integration layer across instrument outputs, ELNs, and LIMS, capturing diverse file types and preserving experimental context through metadata tagging to improve data integrity, auditability, and retrieval, according to G2's description of scientific data management systems.
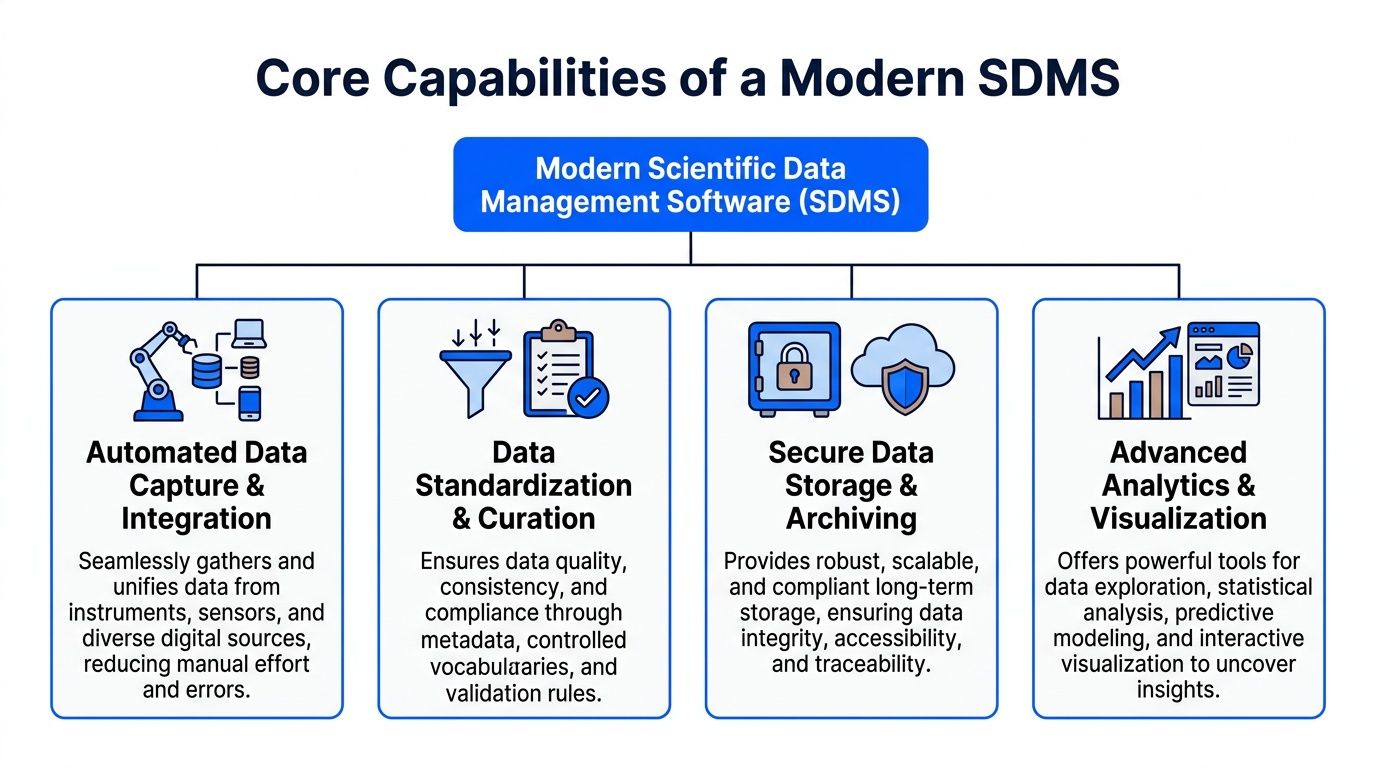
A useful way to judge a platform is to ignore the polished demo first and ask whether it can handle the messy reality of scientific work. Labs produce spectra, images, chromatography outputs, rheology files, formulation tables, simulation results, and handwritten interpretations converted into digital records. If the system breaks when the data becomes heterogeneous, it won't hold up in production.
Integration is the starting point
Automated data capture is the first capability that separates modern systems from glorified file repositories. Good SDMS platforms ingest data directly from instruments and surrounding systems, or at least provide effective connectors and import pipelines that reduce manual movement.
That matters because manual transfer creates three familiar failures. People rename files inconsistently. They drop key attachments. They copy a result into a spreadsheet and sever it from the source record.
A strong integration layer should support:
- Instrument diversity: It needs to accept many file types without forcing scientists into awkward workarounds.
- System connectivity: ELNs, LIMS, databases, and shared drives should feed into a common record structure.
- Import and export flexibility: Teams need data to move in and out without lock-in or custom heroics every time.
In physical terms, this is the conveyor system of the data factory. If the intake is inconsistent, everything downstream slows down.
Metadata turns files into usable knowledge
Metadata management is where many implementations either become highly effective or disappointing. Teams often assume metadata means extra form fields. It doesn't have to. The best systems automate as much tagging as possible and apply controlled vocabularies where consistency matters.
For materials R&D, metadata should preserve the experimental setting around each result. Not just “DSC file attached,” but which formulation, batch, additive package, cure cycle, analyst, instrument method, and sample history led to that file.
What works:
- Automatic extraction where possible
- Controlled terms for materials, methods, and properties
- Clear provenance between raw, processed, and reported data
What doesn't work:
- Free-text everything
- User-defined naming conventions with no governance
- Late attempts to clean records only when an audit or AI initiative begins
Teams don't build AI-ready datasets by exporting a decade of folders into one cloud bucket. They build them by preserving meaning at the moment data is created.
Search and controls determine daily value
Scientists adopt SDMS when retrieval becomes materially better than the old way. They stop resisting when they can ask a practical question and get a reliable answer. For example: show every tensile result for formulations using a given resin family, processed in a certain temperature window, with microscopy images attached.
That requires indexing, structured metadata, and linkages between related records. It also requires access controls that make scientists comfortable using the platform for active work, not just final archiving.
The core controls should cover:
- Auditability so teams can see who changed what and when.
- Role-based access so sensitive programs stay segmented.
- Archiving integrity so records remain durable and attributable.
- Retrieval performance so data doesn't disappear into a slow, bureaucratic portal.
If a system is secure but hard to search, scientists route around it. If it's searchable but weak on provenance, leaders won't trust it for decisions. Modern SDMS has to do both.
Strategic Benefits for Materials and Formulation R&D
For materials and formulation teams, the biggest upside isn't tidier records. It's better scientific judgment under real-world time pressure.
A central, contextual data backbone changes how teams work in three important ways. First, it reduces avoidable repetition because prior experiments are easier to find and interpret. Second, it improves handoffs between discovery, process development, analytical teams, and manufacturing. Third, it turns old experimental history into something computational systems can use, rather than something only veteran scientists remember.
Better decisions come from usable history
In formulation work, the same nominal recipe can behave differently depending on process path, supplier variation, aging conditions, or how the sample was characterized. When historical records preserve those dependencies, scientists can compare like with like. When they don't, teams either ignore the archive or misuse it.
That's why the fundamental value of scientific data management software is cumulative. Each well-structured experiment increases the usefulness of the whole system. Over time, the organization builds not just a repository, but a navigable map of what has been tried, under what conditions, and with what downstream consequences.
This is especially valuable during scale-up. Process teams don't just need the winning lab recipe. They need the surrounding evidence. Which variants nearly worked? Which process windows were fragile? Which analytical signatures correlated with later failure? Those answers usually exist in fragments long before they exist in reports.
AI depends on structured experimental context
A second shift is underway. Organizations increasingly want SDMS to support not only preservation, but also downstream AI and analytics focused on making data computable and decision-ready, as described by Lawrence Berkeley National Laboratory's work on scientific data management and usable data systems.
That point matters more than many buying guides admit. AI for materials discovery doesn't start with model selection. It starts with whether historical experiments are structured well enough to train on, compare, and trust.
Consider the difference between two archives:
- Archive A stores PDFs, images, and instrument files in project folders.
- Archive B links formulation variables, sample lineage, process conditions, measured properties, and analytical outputs under a consistent ontology.
Only one of those environments is prepared for predictive modeling, recommendation systems, or retrieval of historical precedent at speed.
Leadership teams should reframe their perspective. An SDMS isn't only a compliance or IT purchase. It's the foundation layer for AI-driven materials discovery because it determines whether the organization's past experiments are merely stored or computable.
How to Evaluate Scientific Data Management Software
A weak SDMS choice usually looks acceptable in the demo and expensive in year two. The team can store files, satisfy a few traceability requests, and move on. Then a chemist asks for all historical experiments that used a related resin, a similar curing profile, and the same analytical method, and the system behaves like a warehouse with boxes stacked to the ceiling but no aisle map.
Evaluation should start with a business question, not a feature checklist. Which decisions should improve if this platform works? Faster root-cause analysis, fewer repeated experiments, better handoffs from bench to scale-up, and data that can feed modeling workflows are common goals. If leadership expects AI-assisted materials discovery later, the test is stricter. The system has to capture scientific context in a form that software can use, not just display.
A practical review also treats the platform as infrastructure. Systems built with metadata-rich organization, indexing, and workflow support are better suited for retrieval and reuse across growing R&D environments, as discussed in the SDM Center architecture paper from Lawrence Berkeley National Laboratory.

Questions that expose technical fit
Vendor scorecards often hide the underlying problem. A platform can check every box and still fail under real lab conditions.
Use questions that force operational detail:
- How does the platform ingest instrument data? Ask about native connectors, parser coverage, monitored folders, API options, exception handling, and what happens when file formats change after an instrument software update.
- How is metadata created and controlled? The best systems combine automatic capture with governed vocabularies, templates, and review rules. If metadata quality depends on every scientist typing perfect labels under deadline pressure, quality will drift.
- What can users search and compare? Search should span raw data, processed outputs, formulations, samples, process parameters, analytical methods, and result context. A file search alone is not enough for scientific work.
- How is lineage preserved? Ask to trace a result back to the originating sample, preparation steps, instrument run, method version, and any derived dataset. In materials R&D, lineage works like chain-of-custody for evidence.
- How does the system perform at scale? Request examples with large, messy, mixed-format datasets and concurrent users. Curated demos rarely reveal bottlenecks.
- How does data leave the system for modeling or analysis? Ask about export formats, APIs, schema consistency, ontology support, and whether the data structure remains usable outside the application.
What strong answers sound like
Good vendors answer with process detail. They explain where metadata comes from, how lineage is maintained, how permissions behave in shared projects, and how records stay connected across experiments and teams.
Weak vendors rely on broad claims. “Centralized repository” sounds reassuring, but centralization alone does not improve scientific decisions. The critical test is whether the platform preserves enough experimental context to support comparison, reuse, and machine-readable analysis later.
I usually watch for one specific behavior during demos. Ask the vendor to start with a failed sample, then work backward to formulation inputs and forward to related analytical results. If that path is awkward, the system may store data without structuring it well.
Use this lens during evaluation:
| Evaluation area | Strong signal | Warning sign |
|---|---|---|
| Interoperability | Clear support for instruments, ELNs, LIMS, databases, and APIs | Heavy dependence on custom work for routine connections |
| Scientific structure | Data models reflect experiments, samples, methods, lineage, and results | Flat storage with limited scientific relationships |
| Performance | Search and retrieval remain usable across large heterogeneous datasets | Demo works on carefully prepared examples only |
| Governance | Controlled vocabularies, version history, permissions, and traceability are visible in normal workflows | Governance appears only in admin settings or compliance slides |
| AI readiness | Data can be exported or accessed in structured forms that support analytics and modeling | Data is trapped in documents, dashboards, or proprietary views |
Buy for the decision system you want to build, not just the archive you need today. For materials and formulation teams, that usually means favoring software that treats experimental context as a first-class data object. That choice affects far more than storage. It determines whether historical R&D becomes a searchable record of past work or a usable foundation for faster discovery.
Implementation Best Practices and Common Pitfalls
Buying the platform is the easy part. Getting scientists to rely on it during real project pressure is where most programs succeed or fail.
The healthiest implementations start with a narrow, painful use case rather than an enterprise-wide promise. A formulation group with recurring retrieval problems. An analytical team drowning in instrument outputs. A scale-up program that needs stronger traceability between lab results and pilot outcomes. Pick one area where the current process clearly wastes time or weakens confidence.

What good rollout looks like
A practical rollout usually has these traits:
- Phased scope: Start with a bounded workflow, then expand after the data model proves itself.
- Scientist involvement: Bench users should shape metadata fields, search logic, and daily interaction points.
- Governance early: Decide naming rules, ownership, and minimum metadata requirements before migration accelerates.
- Visible wins: Show that the system saves time finding data or reconstructing experiments. Adoption follows usefulness.
One useful habit is to review adjacent disciplines, not just software docs. Teams that regularly scan latest tech R&D articles often make better implementation decisions because they compare their own rollout assumptions against how other technical organizations handle adoption, systems integration, and change management.
Where teams get stuck
The most common failure is trying to boil the ocean. Leaders approve a broad transformation program. The implementation team responds by designing a perfect enterprise schema before solving any urgent scientific problem. Scientists see extra work, not relief.
Other pitfalls are more operational:
- Messy migration: Historical data comes over without enough cleanup, so the new system inherits old confusion.
- Administrative overload: Scientists face too many manual fields and fall back to side spreadsheets.
- Weak ownership: No one has authority to enforce standards across groups.
- Success defined too narrowly: “System went live” isn't the same as “scientists trust and use it.”
The implementation goal isn't software deployment. It's changing where scientists go first when they need evidence.
When teams keep that target in mind, they make better trade-offs. They simplify metadata to what matters. They prioritize search quality over decorative dashboards. They treat data governance as part of the scientific method, not bureaucratic overhead.
Conclusion Your Next Steps Toward Data-Driven R&D
A good SDMS becomes the lab's load-bearing wall. It holds experimental context in one place so teams can retrieve prior work, compare outcomes across programs, and make decisions without rebuilding the same history from memory.
For materials and chemical R&D, that matters far beyond record retention. The main benefit is operational. A modern SDMS organizes data in a form that scientists can reuse and models can learn from. That is the difference between storing experiments in boxes and arranging them on labeled shelves where people can readily find the right part at the right time.
The next step is to choose the problem worth solving first.
- Audit your current data environment. Map where instrument files, formulation records, analytical results, and process notes live today, and note where context gets lost between systems.
- Set the business outcome before the software decision. Decide whether the first target is faster experiment retrieval, better scale-up traceability, stronger cross-team reuse, or cleaner data for AI and modeling.
- Test platforms on decision support, not feature count. Check whether scientists can preserve enough experimental context to compare results, reuse prior work, and trust the data during project reviews.
Teams that get real value from AI in R&D usually start with structure, not models. They create a reliable experimental record first. Once that foundation is in place, downstream work gets easier: trend analysis, recommendation engines, design-of-experiments support, and model-guided formulation all depend on data that is organized well enough to answer a scientist's next question.
If your team is trying to move from fragmented records to an AI-ready R&D backbone, Polymerize is one platform to evaluate. It is built for materials R&D workflows, with a centralized data foundation designed to unify experiments across spreadsheets, ELNs, and silos so teams can structure data for downstream analysis and decision-making.

