Your lab already has the data. It's just trapped in too many places to be useful.
One team logs formulations in spreadsheets. Another stores test results in an ELN. Instrument outputs sit on local drives with filenames only the original operator understands. A process engineer keeps scale-up notes in slide decks. When leadership asks for an AI strategy, people nod, then resort to exporting CSVs by hand. That's the reality in a lot of materials R&D groups.
The problem isn't a lack of experiments. It's fragmentation. Disconnected records make reproducibility harder, slow transfer from lab to pilot, and block the kind of structured learning that materials informatics depends on. If your polymer, chemical, or advanced materials program still relies on analysts stitching together datasets after the fact, your integration model is working against your science.
Data integration best practices matter most in this environment because materials R&D isn't a clean SaaS analytics problem. You have instrument files, evolving formulations, changing test methods, inherited taxonomies, and scientists who need systems that support work in motion, not perfect data entered at the end. The answer isn't a massive centralization project that takes years and collapses under its own scope. It's a practical architecture that starts with the right backbone, enforces quality at the right points, and keeps enough context for downstream modeling.
This blueprint focuses on what works in enterprise R&D. These 10 practices are designed to turn fragmented experimental records into a connected, AI-ready foundation that supports discovery, scale-up, and better decision-making.
Table of Contents
1. Establish a Centralized Data Repository for Experimental Results
A formulation scientist changes one resin ratio, runs DSC and rheology, logs observations in the ELN, and exports a summary table for the team meeting. A week later, process data sits in one folder, instrument output in another, and the “final” result exists in three spreadsheet versions. That is the point where integration stops being an IT cleanup project and becomes an R&D bottleneck.
For materials teams, a centralized repository has one job: make experimental results usable across formulation, process, characterization, and modeling work. It needs to accommodate the nature of lab operations, including spreadsheet formulation logs, ELN entries, LIMS records, raw instrument files, and legacy databases that were built independently.
The common failure mode is overdesign. Teams try to force every source into a perfect enterprise schema before anyone sees value. In practice, a narrower first release works better. Start with the result streams that scientists and data teams already revisit every week, then expand. That same start-small approach shows up in Domo's discussion of data integration best practices.
What belongs in the backbone
The repository should store experimental outcomes in a form that supports both day-to-day research decisions and later AI work. That usually means keeping raw results, curated experiment records, protocol versions, and the context needed to reconstruct how a result was produced. Different platforms can support that architecture. The design choice matters less than the operating principle: one governed system of record for experimental results.
A useful repository usually includes:
- Unified experiment IDs: Tie formulation, synthesis, processing, characterization, and performance data to the same experimental record.
- Versioned records: Preserve changes to recipes, methods, sample definitions, and derived calculations.
- Context with the result: Store instrument, operator, batch, environment, and method details with the measurement.
- Audit history: Keep a trace of edits, imports, and approvals so teams can review what changed and why.
Practical rule: Centralize the datasets that drive active technical decisions first. Leave infrequently used data in place until a real analysis or reuse case justifies the migration.
This matters more in materials R&D than in many other domains. A tensile result without sample prep details is less useful. A conductivity value without process conditions can mislead a model. If the repository only collects end results and drops lab context, it creates a cleaner-looking silo, not an AI-ready foundation.
Trade-offs that matter
A central repository improves cross-experiment analysis, cuts duplicate data entry, and gives scientists a current result set they can trust. It also exposes every inconsistency that local spreadsheets used to hide. Units conflict. Sample names drift. Legacy records lack enough context to compare runs confidently.
That is normal.
The right response is not to delay centralization until the data is perfect. It is to centralize with clear scope, preserve raw records, and accept that some historical data will remain partially usable. Teams get value early when they can answer practical questions faster: Which formulations have already been tested under similar cure conditions? Which instrument output matches the ELN record for this sample? Which results are reliable enough to feed a predictive model?
A good repository does not solve governance by itself. It makes disciplined experimental data management possible, and it gives materials teams a base they can build on.
2. Implement Metadata Standardization and Data Lineage Tracking
A scientist pulls a promising modulus trend from the repository, then realizes three teams used different names for the same thermal treatment and one dataset came from an instrument that was overdue for calibration. The result is familiar. The data exists, but it is not ready for comparison, reuse, or modeling.
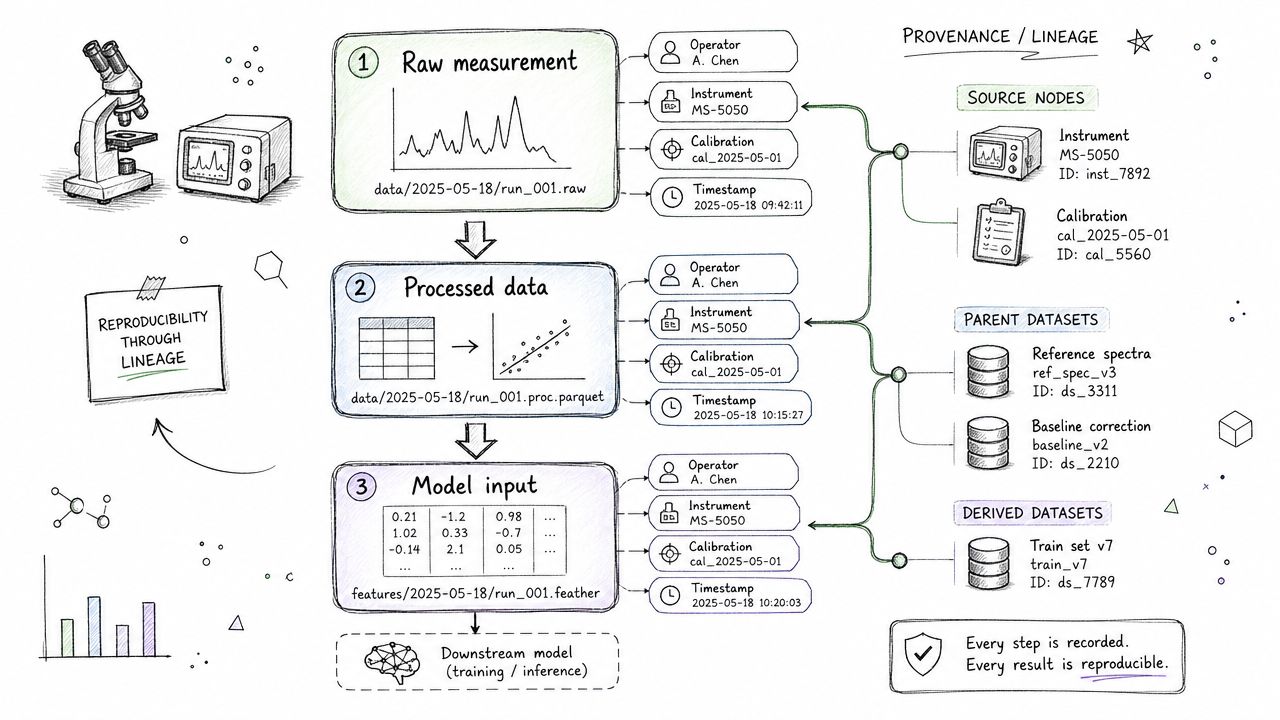
In materials R&D, metadata is not administrative overhead. It is the scientific context that determines whether a result can be trusted. A tensile value without sample geometry, cure history, and test method is easy to store and hard to use. The same is true for spectroscopy files, microscopy images, rheology sweeps, and process logs from pilot equipment.
Lineage matters for the same reason. Teams need to know how raw instrument output became a reported result, which script converted units, which records were excluded, and which feature engineering steps fed a model. That trace matters during root-cause work, method transfer, and model validation. It also matters when a scientist asks a simple question: are these two records scientifically comparable?
What good lineage looks like in practice
Generic warehouse lineage is not enough for lab data. Materials teams need traceability across the full experimental chain, from raw files and ELN entries to cleaned datasets, derived properties, and model inputs. Tools such as Atlan, Alation, and Microsoft Purview can catalog assets and expose lineage, but the metadata model still has to reflect how scientists evaluate evidence.
Start with the fields that change interpretation:
- Material identity: Composition, grade, supplier, lot, internal sample ID, and alias mapping
- Process history: Synthesis route, formulation version, mixing order, drying conditions, cure profile, and any rework
- Measurement context: Instrument, method version, calibration state, fixture or geometry, operator, and environmental conditions
- Transformation record: Parsing logic, unit conversions, outlier handling, derived calculations, and script or notebook version
- Model readiness context: Which variables are measured versus inferred, which records pass quality checks, and which datasets are approved for training use
That last point is where many integration programs fall short. They organize files but do not preserve enough provenance to support predictive modeling. If the goal is AI-ready data, lineage has to connect lab execution, data processing, and downstream feature generation.
Lineage gives scientists a basis for trust. It also gives data teams a way to audit how a model input was created.
Where teams get stuck
The common failure mode is overdesign. If every experiment requires a long form before anyone can save a result, scientists will keep details in side spreadsheets or free text fields, and standardization breaks on day one.
A better approach is a controlled core schema with a small set of required fields, plus governed extensions for technique-specific work. A battery team and a polymer synthesis team do not need identical templates. They do need a shared structure for identity, process, method, units, and derivation.
I have seen this work best when teams standardize vocabularies in stages. Start with the terms that drive cross-project comparison and model quality. Treatment names, sample identifiers, units, method versions, and pass-fail quality flags usually deliver value quickly. Expand from there once people see fewer reconciliation problems and faster analysis.
Preserve raw records, map them to standard terms, and keep the mapping visible. That gives teams a practical path from messy instrument and ELN data to a dataset that can support real decisions.
3. Implement API-First Integration Architecture for Tool Connectivity
Point-to-point integrations look fast at first. Then the fourth instrument arrives, the ELN changes vendors, and someone asks for bidirectional sync with the analytics environment. Suddenly each connection becomes a special case.
API-first architecture avoids that trap. Instead of wiring every source directly to every destination, you expose stable interfaces for reading, writing, and updating experiment data. That gives you a cleaner way to connect ELNs, LIMS platforms, analysis notebooks, robotic workflows, and instrument control software.
Why APIs beat custom file shuffling
For materials teams, API-first doesn't mean every instrument natively supports modern APIs. Many don't. It means your integration layer does. Adapters can handle ugly source formats while your downstream systems consume a consistent interface.
Platforms and tools commonly used in this layer include Postman for API design and testing, MuleSoft for enterprise integration, and event systems such as Apache Kafka when near-real-time orchestration matters. Even simple REST interfaces are better than unmanaged folder drops and manual imports.
What works well:
- Versioned endpoints: So a schema change doesn't break every connected workflow.
- Webhook triggers: So instrument completion or ELN submission can kick off ingestion automatically.
- Event streams: Useful when experiments, approvals, and analysis jobs need to react to changes.
- Authentication layers: Critical when external collaborators or multi-site teams connect to the same backbone.
Trade-offs in the lab environment
API-first is more disciplined than ad hoc ETL. It asks for architecture upfront, naming standards, auth policies, and ownership. That's why some teams delay it.
But once your environment starts evolving, API-first becomes the difference between adding a new tool in a week and rebuilding brittle scripts for a month. In real materials programs, tools change, methods evolve, and data structures drift. Your integration layer has to expect that.
If an instrument upgrade can silently change a field name and break your pipeline, you don't have an integration architecture. You have a collection of fragile exceptions.
4. Establish Data Quality Governance with Automated Validation Rules
A diffraction run finishes at 2:13 a.m. The file lands in the repository. By 9:00 a.m., a scientist has already used it in a comparison chart, even though the instrument software exported the thickness field under a new name and dropped the unit column. That is how bad data enters a materials program. Subtly, early, and inside otherwise legitimate workflows.
Data quality governance has to begin at ingestion, before questionable records reach shared dashboards, model features, or decision reviews. In materials R&D, the goal is not just cleaner tables. It is preserving scientific meaning across instruments, ELNs, LIMS, and analysis environments that were never designed to agree by default.
What to validate automatically
Start with rules tied to how experiments are interpreted.
Useful validation rules include:
- Required experimental context: Reject or quarantine records missing formulation ID, batch, sample identifier, operator, method, or test condition.
- Unit conformity: Standardize or block values when tensile strength, viscosity, particle size, or temperature arrive in inconsistent units.
- Plausibility checks: Flag values outside physically credible ranges or outside method-specific limits.
- Schema checks: Detect renamed columns, datatype drift, missing result files, and malformed timestamps from instrument exports or partner submissions.
- Cross-record consistency: Catch mismatches between ELN entries and instrument outputs, such as a sample ID that exists in one system but not the other.
Generic null checks miss too much. A materials dataset can be technically complete and still be unusable for downstream analysis because curing time was captured in free text, composition totals exceed 100%, or a test result is disconnected from the lot that produced it.
Tools such as Great Expectations and Soda are useful when teams want testable rules inside ingestion and transformation pipelines. Observability platforms can help track failure patterns over time, but rule design matters more than vendor choice at the start. I usually recommend beginning with the failure modes that have already delayed decisions, then formalizing those checks before expanding coverage.
Governance without blocking research
Good governance does not mean every exception stops the lab.
Use severity levels. A missing optional comment might pass with a warning. A sample ID mismatch, impossible value range, or missing unit should quarantine the record until someone resolves it. That approach keeps routine work moving while protecting the datasets used for reporting, scale-up decisions, and predictive modeling.
Ownership matters just as much as automation. Assign a steward for each high-value dataset, define who reviews quarantined records, and set a response path for repeated failures. If no one owns the exception queue, validation rules become noise.
A focused approach works best. Apply the strictest controls to the datasets that feed formulation ranking, experiment reuse, and model training. Historical cleanup has value, but trying to perfect every legacy file at once usually burns time without changing decisions. Teams get better results by protecting a smaller set of trusted datasets first, then expanding from there.
This is also where data model discipline pays off. Many recurring quality failures trace back to weak schema design, ambiguous identifiers, or overloaded tables. The principles behind avoiding data pitfalls in product development apply directly here, especially when experimental data needs to stay usable across changing methods, instruments, and AI workflows.
5. Design for Scalability and Performance with Distributed Data Architecture
A data architecture usually looks adequate until the day a second site comes online, three new instruments start streaming files, and the modeling team begins pulling years of history for feature engineering. Then the bottlenecks show up fast. Overnight loads spill into working hours, joins across experiment and characterization data drag, and scientists start keeping local extracts because the central platform no longer keeps pace with the work.
In materials R&D, scale has two dimensions. One is data volume from spectroscopy, microscopy, thermal analysis, process logs, and ELN records. The other is workload conflict. The same environment has to support instrument ingestion, experiment updates, cross-program analysis, and AI-oriented dataset preparation. If those workloads share the same storage patterns and compute path, performance drops exactly where researchers notice it most.
What scales cleanly
Separate capture from consumption.
Keep raw and near-raw data in an ingestion layer that preserves source fidelity, timestamps, and original context. Then publish transformed, query-optimized datasets in a serving layer built for analysis, dashboarding, and model development. That separation gives teams room to reprocess instrument files, update parsing logic, or revise ontology mappings without breaking every downstream workflow.
Platform choice matters less than design discipline. Warehouse, lake, and lakehouse patterns can all work if they support partitioning, schema evolution, workload isolation, and open analytical formats such as Google BigQuery and Parquet-based storage. The practical question is whether the architecture can handle raw instrument output, normalized experimental records, and curated training tables as distinct products with different performance and governance needs.
Layered data models also help. Bronze, silver, and gold naming is common, but the labels matter less than the boundary between stages. Raw SEM output should not share the same shape as a cleaned formulation table used for ranking candidates, and neither should match the narrow feature set used for a prediction pipeline.
What breaks under growth
A single all-purpose table is the failure pattern I see most often. It starts as a shortcut and turns into a long-term tax on every change. New test methods force awkward columns, sparsity grows, write and read contention increases, and any schema revision becomes a coordination problem across engineering, informatics, and research teams.
Another common mistake is designing every pipeline for immediate propagation. Some events deserve low latency, such as experiment registration, sample status changes, or release-critical quality signals. Many do not. Batch processing is often the better choice for routine characterization data, historical harmonization, and lower-priority derived metrics. The right target is decision-relevant speed, not maximum possible speed.
For teams working through these trade-offs, the same engineering habits behind avoiding data pitfalls in product development apply here. Clear boundaries, stable contracts between layers, and schemas that can evolve without breaking downstream use are what keep a growing R&D data estate usable.
Build for changing methods, rising data volume, and heavier analytical demand. Assume the science will change faster than the first schema.
6. Implement Role-Based Access Control with Data-Level Security
A battery scientist should not need access to catalyst formulations for an unrelated program. A contract manufacturing partner should not see raw supplier pricing. An ML engineer training a yield model may need process history and outcomes, but not the full recipe. In materials R&D, those distinctions are operational requirements, not compliance paperwork.
The answer is a layered security model built around how work happens. Role-based access control sets default permissions by job function. Data-level controls then narrow access by project, material family, customer, site, program stage, or field sensitivity. That matters in environments where instrument files, ELN records, LIMS results, and formulation data all flow into the same integrated estate but should not be visible to the same audience.
Security models that work in enterprise R&D
RBAC alone usually breaks down once programs span external collaborators, multiple business units, or region-specific restrictions. A scientist may be cleared for one polymer platform but not another. A partner may be allowed to review test outcomes while being blocked from precursor identity, process settings, or supplier details. That is why mature teams combine role-based permissions with finer policy rules tied to attributes on the user, the data, or both.
For materials organizations, the useful unit of control is rarely just the table. It is often the experiment, sample, batch, formulation, or even a single field inside a record. If the integration layer cannot enforce those distinctions, teams work around the system. They export data, strip columns by hand, and start maintaining shadow copies. Once that happens, traceability degrades and AI-readiness suffers because the trusted dataset is no longer the dataset people use.
Useful controls in practice:
- Role-based permissions: Set defaults for scientists, lab managers, informatics, external partners, QA, and executives.
- Row-level restrictions: Limit visibility by project, business unit, customer, site, or program code.
- Column masking: Hide formulation ratios, supplier names, cost fields, or sensitive process parameters unless a user has explicit clearance.
- Object-level controls: Separate access to raw instrument outputs, curated analytical datasets, and model-ready feature tables.
- Audit logging: Record who viewed, exported, or changed sensitive records.
The practical trade-off
Granular security adds policy design and administrative work. If access rules are inconsistent, researchers lose confidence in the platform and start asking for exceptions on every project.
The fix is disciplined policy design. Start with a small set of repeatable access patterns that match the operating model you already have, such as internal program teams, cross-site technical leaders, external collaborators, and restricted formulation owners. Document those patterns in plain language. Tie them to data classes and system attributes, not one-off manual grants whenever possible. Then review exceptions quarterly. In my experience, such practices allow access control to stop being a blocker and start supporting faster collaboration.
A good test is simple. If your team can share characterization results broadly, protect recipe-level IP selectively, and prepare governed datasets for modeling without copying data into side systems, the security model is doing its job.
7. Create Data Integration Pipelines with Error Handling and Monitoring
A pipeline that fails loudly is inconvenient. A pipeline that fails unnoticed is dangerous.
In materials R&D, silent failure often looks mundane. Yesterday's instrument files didn't load. A sample mapping job skipped a few rows. A connector retried until timeout, then resumed with partial data. Nobody notices until a dashboard looks odd or a model underperforms.
What resilient pipelines include
Reliable pipelines need more than scheduled execution. They need observability, retries, reconciliation, and controlled failure paths. Tools such as Apache Airflow, Prefect, and Dagster are useful because they combine orchestration with visibility into state and dependencies.
In practice, the best setups include:
- Retry logic: Temporary source failures shouldn't require manual restarts.
- Dead-letter handling: Unprocessable records need a review path, not silent deletion.
- Freshness monitoring: Teams should know when critical datasets are stale.
- Reconciliation checks: Confirm record counts and keys across source and target systems.
The question of how frequently to integrate experimental data is often handled poorly. Guidance usually says to align latency to business need, but teams still need a decision process. The Rudderstack discussion of data integration challenges is useful here because it highlights the need to analyze update notifications, incremental extracts, and latency monitoring rather than assuming everything should be real time.
Real-time where it matters, batch where it doesn't
In a materials context, real-time is most valuable when it changes action. Live experiment monitoring, automated handoff to downstream analysis, and process interventions can justify it. Historical backfills, weekly portfolio comparisons, and many external data loads often don't.
Use the lowest-latency pattern that supports the decision you need to make. Anything faster is architecture vanity.
That principle keeps pipeline complexity under control and reduces the temptation to build streaming systems for data no one needs immediately.
8. Design for Interoperability with Industry Standards and Open Formats
If your integration layer only works inside one vendor stack, you haven't solved fragmentation. You've renamed it.
Interoperability matters more in materials R&D than in many business domains because your data needs to outlive specific instruments, ELNs, analytics tools, and even organizational structures. Acquisition, divestiture, lab relocation, and software replacement all test whether your data model is portable or trapped.
Standards worth adopting
The exact standards depend on your subdomain, but the operating principle is consistent. Store canonical identifiers and preserve exports in open, durable formats. Use standard chemical notations where they fit. Support common scientific file types instead of flattening everything into generic tables too early.
Tools and platforms that help here include RDKit for chemistry-aware representations, KNIME for interoperable scientific workflows, and HDF5 ecosystems for structured scientific data storage.
Practical interoperability choices include:
- Open exports: CSV, JSON, and structured scientific formats for long-term portability.
- Canonical identifiers: Consistent material, sample, and experiment IDs that survive tool changes.
- Ontology mapping: Controlled vocabulary alignment for material classes, methods, and outcomes.
- Separation of raw and normalized forms: Preserve original outputs while also maintaining curated, query-ready versions.
What to avoid
Don't force every domain nuance into a public standard that doesn't fit. That often leads to lossy mappings and user workarounds.
Instead, use standards for the stable core and keep extensibility for domain-specific detail. Good data integration best practices don't require purity. They require enough standardization that future systems, partners, and models can still understand what you captured.
9. Implement Data Privacy and Encryption for Sensitive Formulations
Security in materials R&D isn't abstract. It sits inside formulation ratios, additive packages, process windows, supplier selections, and customer-linked test programs. If your integration strategy expands access without protecting those details, you've increased risk while trying to improve visibility.
Privacy and encryption controls need to be built into the platform, not bolted on after a data lake is already in use. That includes encryption in transit, encryption at rest, key management, and selective protection for especially sensitive fields.
Where encryption matters most
The highest-risk records aren't always the obvious ones. Final formulas matter, but intermediate experiments, failed prototypes, and scale-up notes can also expose IP. Protecting only polished datasets misses a lot of what competitors would want.
Common enterprise controls include support from cloud platforms such as AWS Key Management Service, Google Cloud Key Management, and Azure Key Vault. If your architecture extends into cloud environments, this overview of a cloud computing encryption guide is a practical reference point for implementation concerns.
Useful protections include:
- Field-level encryption: Apply stronger controls to formulations, recipes, and proprietary process parameters.
- Transport security: Protect data moving from instruments, sites, and partner systems into the core platform.
- Scoped data sharing: Expose only what's needed when working with CROs, CMOs, or academic collaborators.
- Pseudonymization: Remove identifying details when broader analysis is needed without full disclosure.
The trade-off nobody should ignore
Tighter encryption and privacy controls can complicate analysis, indexing, and sharing. That's normal.
The answer is not to weaken protection. It's to architect secure analysis paths from the start, with clear separation between raw sensitive data, controlled derived data, and collaboration-ready views.
10. Build Feedback Loops to Continuously Improve Data Quality and Integration
A model ranks a candidate material highly. The team tries to reproduce the result and finds that one viscosity stream was mapped with the wrong method code for months. That is the point where data integration stops being an IT project and becomes an R&D risk.
In materials science, bad joins and weak metadata do more than create messy dashboards. They distort structure-property relationships, confuse scale-up decisions, and introduce noise into predictive models. Teams need a way for problems discovered during analysis, modeling, or bench work to feed back into the integration layer quickly.
A useful feedback loop connects three groups that rarely stay aligned on their own: scientists who spot suspicious records, data engineers who own pipelines and parsers, and platform owners who control schemas, master data, and validation rules. The goal is simple. Turn repeated downstream corrections into upstream fixes.
A closed loop usually includes:
- Fast issue capture: Let scientists flag a suspect result, missing unit, broken sample link, or mislabeled instrument output from the ELN, analytics layer, or modeling workflow.
- Clear ownership: Send each issue to the team that can fix it, whether that is the instrument integration owner, metadata steward, ontology maintainer, or application admin.
- Cause analysis: Check whether the problem came from calibration context, file parsing, unit conversion, template design, or manual entry.
- Rule updates: Convert common fixes into automated validation checks, parser revisions, controlled vocabulary changes, or UI constraints.
- Impact tracking: Record which issues affected formulation screening, reproducibility, tech transfer, or model training so remediation work is prioritized by scientific value.
The trade-off is speed versus control. If every issue goes through a formal governance board, scientists stop reporting problems. If every complaint changes the schema, the platform becomes unstable. In practice, the best approach is a triage model. Fix high-frequency and high-impact issues quickly. Batch low-risk cleanup into scheduled releases.
This matters even more in materials R&D because the same data problem can surface in different forms across the stack. A missing humidity field may look like an innocent metadata gap in an ELN, then show up later as unexplained variance in coating performance or failed model generalization. Feedback loops expose those connections.
Start where errors are expensive. Focus first on datasets used for formulation optimization, cross-site comparison, scale-up transfer, and AI model development. Archive data and low-reuse historical records can follow later.
I have found that teams get better results when they review feedback in terms of scientific decisions, not abstract data quality scores. Ask which recurring issues delayed experiment planning, forced rework, or reduced trust in a model. That framing keeps integration work tied to lab outcomes instead of turning into a permanent cleanup queue.
10-Point Data Integration Best Practices Comparison
| Item | Implementation Complexity 🔄 | Resource Requirements ⚡ | Expected Outcomes ⭐ | Ideal Use Cases 📊 | Key Advantages & Quick Tips 💡 |
|---|---|---|---|---|---|
| Establish a Centralized Data Repository for Experimental Results | High, major integration, migration and change management | High, ETL, storage, governance, training | Unified, AI-ready dataset enabling cross-experiment insights and faster discovery | Enterprise R&D, materials informatics, ML model training | Eliminates silos; start with a pilot, enforce governance and incremental migration |
| Implement Metadata Standardization and Data Lineage Tracking | Medium–High, schema design and retrofitting legacy data | Medium, domain experts, tooling for provenance capture | Improved reproducibility, auditability and model trustworthiness | Regulated labs, explainable AI, reproducibility-focused projects | Use standards (ISO/IUPAC), automate metadata capture, tier critical vs optional fields |
| Implement API-First Integration Architecture for Tool Connectivity | Medium, API design, versioning and governance | Medium, developer effort, API management platforms | Flexible, real-time connectivity; faster onboarding of tools and instruments | Heterogeneous tool ecosystems; third-party integrations; dynamic workflows | Design APIs around domain entities, provide docs/sandboxes, use webhooks and async patterns |
| Establish Data Quality Governance with Automated Validation Rules | Medium, rule definition, stewardship and monitoring | Medium, validation engines, dashboards, steward roles | Prevents bad data reaching models; increases confidence in analyses | Regulated environments and ML-driven decisions | Start with high-impact rules, involve scientists, build exceptions and scorecards |
| Design for Scalability and Performance with Distributed Data Architecture | High, distributed DBs, sharding, and performance tuning | High, cloud costs, SRE expertise, monitoring | Supports millions of experiments with consistent performance for training and real-time use | Global R&D, high-throughput experiments, large-scale model training | Use managed cloud warehouses, profile queries, implement lifecycle policies |
| Implement Role-Based Access Control (RBAC) with Data-Level Security | Medium–High, policy modeling and enforcement across many teams | Medium, IAM tools, audit logging, periodic reviews | Protects IP, supports compliance and controlled collaboration | Enterprises with proprietary formulations and regulatory needs | Apply least privilege, use role templates, schedule quarterly access reviews |
| Create Data Integration Pipelines with Error Handling and Monitoring | Medium, orchestration, retries, DLQs and observability | Medium, orchestration tooling (Airflow/Prefect), monitoring | Reliable, observable data flows with alerts and reconciliation | Multi-source ingestion, instrument syncs, SLA-driven pipelines | Use orchestrators, implement retries/DLQs, maintain runbooks and reconciliation checks |
| Design for Interoperability with Industry Standards and Open Formats | Medium, mapping proprietary schemas to standards | Low–Medium, domain expertise and mapping layers | Long-term portability, easier collaboration and reduced vendor lock-in | Cross-institutional sharing, academic partnerships, migration scenarios | Adopt FAIR principles, build flexible mapping layers, participate in standards communities |
| Implement Data Privacy and Encryption for Sensitive Formulations | Medium–High, encryption, key management, compliance controls | Medium–High, HSMs/CMKs, security ops, audits | Strong IP protection and regulatory compliance for sensitive data | Proprietary formulations, external collaborations, regulated industries | Encrypt at application layer, use HSMs/CMKs, test key rotation and conduct pen tests |
| Build Feedback Loops to Continuously Improve Data Quality and Integration | Medium, instrumentation, analytics and governance workflows | Medium, analytics, ML monitoring, data stewardship | Iterative improvements in data quality and better model accuracy over time | MLOps, production models, organizations practicing continuous improvement | Automate low-confidence alerts, hold regular reviews, empower stewards to act on findings |
Turn Data Integration into a Competitive Advantage
Effective data integration in materials R&D has very little to do with building the biggest platform in the shortest time. It has everything to do with making experimental knowledge usable across the full life of a program. That means scientists can find comparable runs, formulation teams can trace what changed, process teams can understand which lab signals survived scale-up, and AI teams can work from data that still carries scientific context.
The strongest programs don't chase a mythical single model for everything. They build a usable backbone, then strengthen it deliberately. They centralize the data that matters first. They define metadata that reflects how scientists evaluate trust. They create integration layers that survive new instruments, changing schemas, and shifting workflows. They treat quality and security as operating requirements, not cleanup tasks.
That matters because fragmented R&D doesn't fail dramatically. It fails subtly. Teams repeat experiments because past results can't be found or compared. Handovers slow down because process context is missing. Modeling efforts stall because input data isn't consistent enough to support reliable learning. None of those issues are fixed by buying one more dashboard tool or asking scientists to "document better." They're fixed by infrastructure choices and governance habits that fit real lab work.
A useful integration strategy also respects a point many generic guides miss. Not all data deserves the same latency, the same controls, or the same investment on day one. Some datasets are operationally critical and should be validated, monitored, and secured aggressively. Others can stay lighter until they prove their value. That kind of prioritization is what keeps transformation programs moving in R&D environments where complexity expands fast.
The opportunity is larger than operational efficiency. Once experimental data is structured, connected, and governed well, it becomes an asset for discovery. Researchers can learn from failed experiments instead of losing them in disconnected files. Teams can compare results across instruments and sites with more confidence. Leaders can see where programs are progressing and where assumptions need to be challenged. Model builders can develop explainable systems on top of data that reflects the scientific process.
Data integration offers a competitive advantage. It shortens the distance between experiment and insight. It reduces the time wasted on reconciliation and rework. It creates the foundation for predictive modeling, smarter experiment planning, and more reliable scale-up decisions. Ultimately, it lets scientists spend more time doing science and less time reconstructing what already happened.
For organizations working across polymers, chemicals, and advanced materials, a platform approach helps turn these practices into a repeatable operating model. With a unified data backbone and AI-ready environment from Polymerize, teams can connect fragmented records across spreadsheets, ELNs, and lab systems, then build toward explainable modeling and faster decision-making without forcing an unrealistic all-at-once centralization effort. That's how R&D groups move from scattered data to a system that supports discovery at enterprise scale.
If you're trying to connect fragmented experimental records, secure proprietary formulation data, and create an AI-ready foundation for faster materials development, Polymerize is built for that job. It brings together data across spreadsheets, ELNs, legacy systems, and lab silos into a centralized backbone designed for enterprise R&D, then layers explainable models on top so teams can plan better experiments instead of spending their time stitching data together.

