Your team has a model that looks impressive in a demo. It predicts tensile strength, flags likely formulation failures, and ranks the next experiments to run. Then it hits the lab. A chemist changes a raw material grade, a process engineer uses production conditions instead of bench conditions, and confidence in the model drops fast.
That's usually the moment leadership asks a basic question with expensive implications: what is ai testing, really?
In materials R&D, the answer has very little to do with flashy automation claims. It's about proving that a model is reliable enough to influence formulation choices, scale-up decisions, and IP-sensitive development work. If a prediction engine can move budget, alter experiment plans, or change go/no-go decisions, it needs its own validation discipline.
Table of Contents
The AI Testing Lifecycle From Unit Checks to CI/CD for Models
Meeting Enterprise Standards Compliance and Regulation in AI
Beyond Code What is AI Testing in R&D
A lot of teams use the term AI testing to mean two different things.
One meaning is using AI to improve software QA. That includes generating test cases, self-healing scripts, or prioritizing regression suites. If you're evaluating integrating intelligent models into QA workflows, that topic matters for digital teams and product engineering.
The other meaning, and the one that matters in a materials lab, is testing AI systems themselves. That means validating whether a model's outputs are scientifically credible, operationally reliable, and safe to use in decisions that affect experiments, scale-up, and production.
Why the distinction matters in scientific computing
This confusion isn't minor. A 2025 Gartner report highlighted that 70% of enterprises misapply “AI testing” terminology, leading to 40% wasted QA efforts in scientific computing, as cited in GeeksforGeeks' overview of AI testing. In practice, that means teams spend time testing dashboards, APIs, and workflows while under-testing the actual model that recommends the next formulation or predicts a property.
For a CTO or lab director, that creates a false sense of control.
You can have excellent software QA and still ship a weak model.
Practical rule: If the system influences scientific choices, test the model separately from the application around it.
What testing AI looks like in R&D
In conventional software, the core question is often deterministic. Given a known input, did the system return the expected output?
In materials R&D, the harder questions are different:
Does the model generalize beyond the narrow conditions it saw in training?
Does it stay stable when data pipelines change, naming conventions drift, or raw data arrives from different sites?
Does its confidence mean anything useful to a scientist deciding which experiment to run next?
Can experts understand why it made the recommendation well enough to trust or challenge it?
That's why traditional QA alone isn't enough. A property prediction model can pass integration tests and still fail where it matters most: under messy, real lab conditions.
A working definition
For R&D leaders, what is ai testing comes down to this:
AI testing is the process of validating an AI model's data integrity, performance, reliability, explainability, and ongoing behavior so the organization can trust it in real scientific work.
In a materials context, that trust has to extend beyond the demo environment. It has to survive formulation changes, sparse historical data, and the jump from lab insight to manufacturing consequence.
The AI Testing Lifecycle From Unit Checks to CI/CD for Models
In materials R&D, model failures rarely begin with the model itself. A viscosity predictor can look strong in development and still mislead a formulation team because one site logged temperature in a different unit, a descriptor job failed unannounced, or a retrained model shifted its ranking logic without anyone noticing. The testing lifecycle exists to catch those failures before they turn into wasted bench work or a bad scale-up decision.
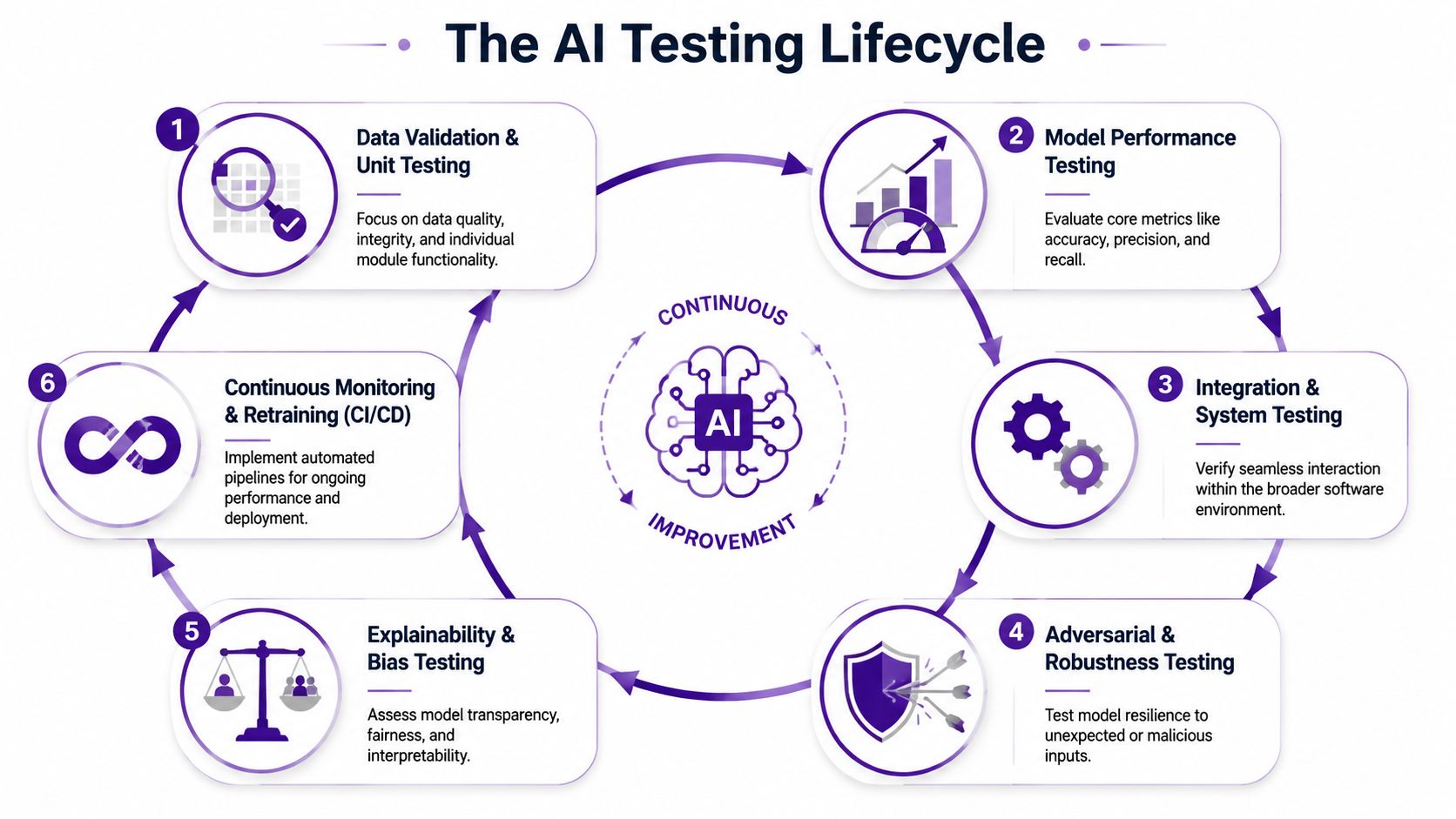
Start with data and pipeline checks
For scientific models, the first test target is usually the data pipeline.
Teams should verify schema consistency, unit handling, record lineage, preprocessing logic, and descriptor generation before they spend time tuning architectures. A practical reference for engineering teams building that foundation is the DataEngineeringCompanies.com guide to testing, especially when model outputs depend on multi-source experimental data.
The goal is repeatability.
| Lifecycle stage | What you test | Typical failure in R&D |
|---|---|---|
| Data validation | Missing values, schema, units, lineage | Mixed units or malformed experiment records |
| Feature unit tests | Descriptor generation, preprocessing logic | Wrong normalization or dropped variables |
| Training validation | Reproducibility of model runs | Different results from the same training recipe |
If the same training recipe produces materially different results from the same inputs, the team does not yet have a dependable development process. In a regulated or high-consequence environment, that alone is enough to stop deployment.
Test model behavior under scientific operating conditions
Once the pipeline is stable, testing shifts from code correctness to decision reliability. Held-out validation data matters, but it is only one checkpoint. R&D teams also need to know how the model behaves on sparse formulations, new chemistries, partially missing records, and edge conditions near process limits.
A practical lifecycle usually includes:
Task performance tests on representative validation data
Regression tests after retraining, feature updates, or preprocessing changes
Integration tests inside the applications scientists use
Stress tests with noisy, incomplete, or out-of-range inputs
Reviewability checks to confirm outputs can be explained well enough for technical teams to challenge them
That last point matters more in materials work than in generic software prediction tasks. If a scientist cannot inspect why a model ranked one candidate above another, adoption slows down even when the average metric looks good.
Include adversarial and edge-case testing
Actual systems face hostile inputs, accidental misuse, and conditions the training set did not cover. Microsoft's Tay chatbot was taken offline in 2016 after users quickly manipulated it into producing offensive outputs, as reported by BBC News. The domain is different, but the testing lesson carries over directly. Systems exposed to the actual world need challenge tests, not just clean validation sets.
In materials R&D, adversarial testing looks less theatrical but just as important. It includes out-of-distribution chemistries, extrapolation beyond trained process windows, malformed instrument exports, duplicated experiments, and records that are technically valid but scientifically misleading.
Test for the failure modes your lab will face.
I usually advise teams to build a small suite of "known ugly cases" early. Those examples often reveal more operational risk than another round of hyperparameter tuning.
Close the loop with CI/CD for models
A model that passed last quarter can drift out of tolerance after a method change, a new raw material source, or a shift in how one facility labels experiments. CI/CD for models should treat every update to data, features, code, and model weights as a controlled change that triggers validation.
A mature setup should automatically:
validate incoming data,
rerun critical test suites after model updates,
compare candidate model behavior against the current production version,
flag drift, calibration shifts, or unexplained performance changes,
require human sign-off before promotion when scientific or operational risk is high.
AI testing emerges as a business control, not simply an ML hygiene practice. It reduces the odds that a model degrades inside an expensive experimental workflow, and it lets R&D teams improve systems faster because they can change them with evidence instead of hope.
Measuring What Matters AI Evaluation Metrics and Benchmarks
The easiest mistake in model validation is using the wrong scoreboard.
A team builds a predictor, reports strong accuracy or a high validation score, and concludes the model is ready. In scientific R&D, that tells only part of the story. A model can look strong on aggregate metrics and still fail where scientists need judgment most: edge cases, unfamiliar chemistries, or borderline recommendations where the cost of being wrong is high.
Standard metrics are necessary but incomplete
For most ML teams, the starting point is familiar. Classification models may use precision, recall, or F1-score. Regression models often rely on fit-oriented metrics and residual analysis. Those are useful because they show whether the model learned signal at all.
But they don't answer deeper operational questions.
A formulation scientist doesn't just need to know whether a model is usually correct. They need to know whether a specific recommendation is dependable enough to justify the next experiment.
Calibration matters more than many teams realize
A well-tested model should not only rank options correctly. Its confidence should be meaningful.
If a system says one candidate has high success likelihood while another is uncertain, that should map to reality well enough that scientists can use those signals to prioritize work. Poorly calibrated models are dangerous because they sound decisive without earning that confidence.
In practice, calibration testing asks questions like these:
When the model is highly confident, is it more likely to be right?
Does uncertainty rise in unfamiliar regions of formulation space?
Do confidence scores collapse when upstream data quality degrades, or do they stay falsely stable?
That last point matters a lot in lab environments where not every record is clean, complete, or comparable.
A useful model doesn't just say “run this experiment.” It also signals when the recommendation deserves skepticism.
Robustness is the lab reality check
Bench data is tidy compared with real development work. Conditions shift. Operators record data differently. Raw materials vary. Scale introduces noise.
Stability testing should therefore probe how the model behaves when inputs are perturbed, partially missing, or slightly outside expected ranges. In materials R&D, this is often more important than chasing a marginal lift in headline model performance.
A practical evaluation set usually includes several slices:
| Evaluation slice | Why it matters | What to watch for |
|---|---|---|
| In-distribution data | Confirms baseline performance | Stable errors and sensible ranking |
| Noisy data | Mimics real lab variation | Graceful degradation, not collapse |
| Sparse or incomplete records | Reflects operational data gaps | Honest uncertainty, not forced certainty |
| Out-of-distribution inputs | Tests generalization limits | Clear fail signals or abstention behavior |
Benchmarks should reflect decisions, not just datasets
For R&D leaders, the best benchmark isn't a generic ML score. It's whether the testing framework supports the decisions the organization makes.
That may mean asking whether the model helps scientists screen candidates more intelligently, whether it surfaces recommendations worth investigating, or whether it correctly identifies cases where human review should override the output. A model that knows when not to speak with confidence is often more valuable than one that performs slightly better on a static benchmark but fails without warning in novel conditions.
When teams ask what is ai testing in a scientific setting, this is one of the clearest answers: it's the discipline of measuring model usefulness under the conditions where real decisions happen, not just where benchmark scores look clean.
Beyond Black Boxes Data Quality and Explainable AI
Most AI failures in R&D don't begin as algorithm problems. They begin as data problems wearing algorithm clothes.
A model trained on fragmented spreadsheets, inconsistent experiment logs, and loosely mapped metadata will still produce outputs. The danger is that the interface makes those outputs look more authoritative than the underlying evidence deserves.
Data quality is the first trust layer
Materials teams often pull from multiple sources at once. One dataset may come from an ELN, another from spreadsheets managed by a formulation group, and another from process records created during pilot runs. If naming conventions, units, or contextual fields don't align, the model can learn patterns that are accidental rather than scientific.
That's why testing should treat data quality as a formal validation stream, not just preprocessing.
Useful checks include:
Lineage checks so the team knows where each record came from and what transformations touched it
Consistency checks for units, naming, and categorical mappings
Context checks that preserve the conditions under which a result was produced
Historical precedent checks to see whether a new recommendation resembles known successful or failed cases
Without those controls, model explainability becomes cosmetic. The explanation may be mathematically valid, but it still rests on unreliable inputs.

Explainability turns predictions into usable scientific insight
In materials R&D, a black-box answer is rarely enough. Scientists want to know why the model expects a given property outcome, which variables pushed the result, and whether that logic aligns with domain knowledge.
That's where Explainable AI, especially methods like SHAP and LIME, becomes practical rather than academic.
According to the verified materials R&D example in the Diva Portal paper on explainable AI for polymer prediction, XAI frameworks such as SHAP are used to validate models by identifying causal drivers in formulations. That approach led to a 50% reduction in failed experiments within 3 months, and SHAP interaction values helped prevent 25% of common scale-up defects.
Those numbers matter because they show what explainability does in practice. It doesn't just produce nicer charts. It helps teams move from trial-and-error to targeted synthesis.
What SHAP and LIME are actually doing for a lab team
A scientist doesn't need to become an XAI specialist to benefit from these tools. They need interpretable answers to a few concrete questions:
| Question from the lab | What XAI can reveal |
|---|---|
| Why did this candidate fail? | Which descriptors or formulation variables pushed the prediction negative |
| What changed between two similar formulations? | Which interaction terms drove the difference |
| What should we vary next? | Which variables have the strongest local effect on success likelihood |
SHAP is especially useful for ranking feature contributions in a way that's consistent across a model. LIME is useful for local “what-if” analysis around a particular prediction. Together, they turn a prediction engine into something closer to a decision-support system.
The most valuable model explanation is the one a chemist can act on the same day.
Data integrity and explainability have to work together
Good explainability cannot rescue bad data. But when data quality is controlled, explainability becomes a powerful testing layer because it shows whether the model's reasoning aligns with chemistry and process knowledge.
If the model attributes success to a variable that domain experts know is irrelevant, that's a testing signal. If it surfaces an interaction that experienced scientists recognize as plausible, confidence rises. This is why AI testing in materials discovery has to combine both disciplines. One validates the evidence base. The other validates the logic built on top of it.
AI Testing in Practice From Formulation to Scale-Up
The value of AI testing becomes clear when you follow the work as it moves through a real development chain. Not an abstract model card. An actual sequence from formulation choice to process risk.

Formulation screening with uncertainty in mind
Start with a formulation chemist choosing which candidate to run next.
A model may rank several candidates as promising. A poorly tested system pushes the highest-scoring option and leaves the scientist to discover later that the recommendation came from a narrow region of training data. A well-tested system behaves differently. It pairs the recommendation with uncertainty, shows which variables are driving the prediction, and helps the chemist decide whether to confirm, challenge, or diversify the next experiment.
In practice, that changes behavior. Scientists stop treating the model as an oracle and start using it as a structured decision partner.
Synthetic data for IP-safe stress testing
The next scenario appears when teams want deeper validation without exposing sensitive proprietary data. That's where synthetic data can be useful.
The verified example from NVIDIA's explainable AI discussion shows how advanced testing can generate 1M synthetic polymer samples to validate sensitivity without compromising IP. In that workflow, SHAP analysis found that a 0.12 SHAP delta from catalyst impurity caused an 18% yield drop, and the same approach cut production failures by 35% in Polymerize-like systems, according to NVIDIA's explainable AI powered by synthetic data article.
That's a good example of testing creating operational value, not just audit value. Teams can probe edge cases, inspect sensitivity, and look for failure paths before they expose real formulations or scale production runs.
Scale-up is where weak models usually get exposed
A model that works on bench-scale data often struggles when process conditions shift. The chemistry may be the same, but residence times, impurity effects, equipment differences, or thermal profiles introduce behavior the training data never captured well.
That's where AI stability testing earns its keep. Process engineers can simulate near-boundary conditions, evaluate whether recommendations remain stable, and identify the conditions where the model should defer to human review.
A practical operating pattern looks like this:
Bench phase uses the model to rank candidate formulations and identify influential variables.
Pilot phase tests how sensitive those predictions are to realistic process variation.
Pre-production review checks whether the model remains reliable enough to support process decisions or whether the risk profile has changed.
Here's a short industry example worth watching before building that workflow into your own environment:
What works and what tends to fail
In practice, several patterns show up repeatedly.
What works:
Testing on decision scenarios, not only static holdout datasets
Using explainability during validation, not after deployment
Stress-testing with synthetic or perturbed data when real edge cases are sparse
Flagging low-confidence recommendations instead of forcing a prediction every time
What doesn't:
Treating a lab-scale validation set as proof of production readiness
Assuming a strong average metric means stable edge-case behavior
Hiding uncertainty from scientists to make the interface look simpler
The teams that get value from AI in R&D usually make one strategic move early. They test the model at the point where scientific judgment meets operational consequence.
Meeting Enterprise Standards Compliance and Regulation in AI
An R&D model can look technically sound in validation and still fail an enterprise review in a day. The failure point is rarely the architecture. It is the missing evidence chain behind the prediction.

In materials R&D, that gap matters more than it does in ordinary software QA. A recommendation about a formulation, process window, or material property can influence expensive experiments, technical records, and eventual manufacturing decisions. If the team cannot show what data trained the model, what tests were run, who approved release, and what changed after deployment, the model is not ready for enterprise use.
Compliance starts with documented validation
A compliant AI testing program preserves the full validation story, not just a headline metric on a dashboard.
That record usually includes:
Training data provenance and inclusion rules
Versioned model artifacts and configuration history
Test evidence across development, validation, and deployment
Approval checkpoints tied to risk level and intended use
Monitoring records for drift, retraining, overrides, and incident review
This is what lets a team reconstruct a result six months later when legal, quality, or a program lead asks a simple question: why did the model recommend this path?
For property prediction models, the standard is higher than “the model scored well on a holdout set.” Enterprise review often needs traceability from source data to model output to downstream decision. That is how organizations protect IP, defend scientific decisions, and limit avoidable compliance exposure.
Maintenance overhead is an operating issue
Compliance work becomes expensive when validation lives in scattered notebooks, slide decks, scripts, and email approvals. I have seen teams spend more time rebuilding evidence for review than improving the model itself.
The pattern is common across AI programs. As workflows change, schemas drift, and models are updated, the testing record gets harder to maintain unless versioning, access control, and approval logic are built into the operating process. In practice, weak governance slows deployment, creates review bottlenecks, and makes every retraining cycle harder to justify.
Good compliance design reduces that drag. The goal is not more paperwork. The goal is a repeatable release process that gives technical teams and leadership the same answer from the same record.
Security and explainability need to be tied together
Security controls and model explainability are often handled by different teams. In R&D, they belong in one governance model.
A model that cannot provide a usable rationale is harder to approve for high-impact scientific decisions. A system that cannot show who accessed sensitive data, which model version produced an output, or whether an exception was reviewed is harder to defend under audit. Standards such as ISO 27001 and control frameworks such as SOC 2 matter here because they support controlled access, evidence retention, and disciplined handling of proprietary research data.
The practical point is simple. The testing record and the compliance record should be the same record.
What leadership should ask before deployment
Before an AI system influences live R&D decisions, leadership should be able to get direct answers to a small set of questions:
| Leadership question | What a mature testing program should provide |
|---|---|
| Can we explain this recommendation in scientific terms? | A clear rationale, known input drivers, and documented limits of use |
| Can we audit this result later? | Versioned data, model, prompt or configuration history, and test evidence |
| Can we protect sensitive formulations and process data? | Role-based access, usage logs, and controlled data handling |
| Can we detect degradation before it affects decisions? | Monitoring thresholds, review triggers, and a defined response process |
If those answers are vague, the risk is not only model error. The larger problem is that the organization lacks a defensible operating model for testing AI in a regulated, IP-sensitive R&D environment.
Your Practical Checklist for Implementing AI Testing
Most organizations don't need another abstract framework. They need a starting sequence that fits how R&D work gets done.
The most effective rollouts are narrow at first. They target one decision process, one data backbone, and one model family, then build discipline before scaling across the portfolio.
Start with the data foundation
Before testing the model, test whether the organization even has the right ingredients to validate one.
Audit where experimental data lives. Include spreadsheets, ELNs, pilot logs, and manually curated files.
Standardize core fields. Units, naming conventions, formulation identifiers, and process metadata need consistent definitions.
Create traceable lineage. If a scientist can't tell where a record came from, the model team can't defend its output.
This step is less glamorous than model selection, but it usually determines whether the rest of the program will work.
Define success in terms the lab cares about
Don't lead with generic ML goals. Lead with decision outcomes.
A good implementation brief might define success as improving experiment prioritization, reducing avoidable failed trials, or increasing confidence in scale-up recommendations. The point is to tie testing to the scientific workflow, not just to a model development milestone.
Use questions like these:
Which decisions will this model influence?
What kind of error is most expensive for us?
When should the model abstain and defer to human judgment?
Run one pilot with full testing discipline
Choose a use case with visible value and manageable risk. Property prediction, formulation screening, or early scale-up support are often better pilot candidates than fully autonomous decisioning.
For the pilot, require a complete testing stack:
Data validation for source quality and transformation rules
Model performance checks on relevant holdout and edge-case data
Resilience testing under noisy and near-boundary conditions
Explainability review with domain experts, not only data scientists
Monitoring rules for retraining, drift, and version control
If the team skips explainability in the pilot, it usually ends up retrofitting trust after skepticism has already formed.
Build governance before broad adoption
Once a pilot proves useful, resist the urge to scale too quickly. First formalize ownership.
Set clear accountability for model approval, review cycles, incident response, and retirement criteria. Decide who signs off when performance changes, who investigates anomalies, and how exceptions get documented. Those choices are easier to make before the model becomes embedded in daily lab work.
A compact implementation checklist looks like this:
| Action | Why it matters |
|---|---|
| Centralize critical R&D data | Prevents hidden inconsistencies from poisoning validation |
| Tie metrics to business and lab outcomes | Keeps testing relevant to real decisions |
| Add XAI from day one | Builds trust and exposes weak model reasoning early |
| Monitor post-deployment behavior | Catches drift before users lose confidence |
| Document approvals and version history | Supports governance, auditability, and repeatability |
AI testing works best when it becomes part of how the organization makes scientific decisions, not a side exercise run by the data team alone. That's the practical answer to what is ai testing for materials R&D. It's the discipline that makes AI usable in practice.
If your team is trying to operationalize this in polymers, chemicals, or advanced materials, Polymerize is built for that environment. It helps enterprises unify fragmented R&D data, apply explainable domain-specific models, and support AI-guided experimentation with enterprise controls designed to protect IP while accelerating discovery and scale-up.

