Most polymer R&D teams aren't short on ideas. They're short on clean, connected evidence.
You already have years of formulation work sitting in spreadsheets, ELNs, instrument exports, slide decks, and the heads of senior scientists. You also know the pattern: a new target arrives, the team starts from a familiar chemistry family, a few variables get tuned, and progress depends on who remembers what failed last time. That works until it doesn't. Projects slow down, scale-up surprises appear late, and experimental cycles become expensive ways to rediscover old constraints.
That's where polymer ai becomes useful. Not as a replacement for polymer scientists, and not as a magic generator of breakthrough materials. Used well, it's a disciplined way to turn fragmented historical work into a decision system. The practical shift is simple: instead of asking the lab to search blindly, you use models, structured data, and iterative validation to narrow the search space before you make material.
A 2025 perspective on AI in polymer research describes the field as “rapidly expanding” beyond simple property prediction, while noting that characterization and analytical method development remain largely untapped. That gap matters. It means many organizations are still treating AI as a point tool for isolated modeling tasks, when the bigger value comes from connecting data capture, prediction, experiment planning, and interpretation into one operating loop.
The teams that get real value from polymer ai usually do one thing early. They stop framing AI as a software purchase and start treating it as an R&D capability built on data discipline, model governance, and workflow design.
Table of Contents
- Three model families you'll actually encounter
- Comparing AI approaches in polymer R&D
- What works and what doesn't
- Do we need a huge dataset to start
- How is this different from simulation
- What if our historical data is messy
- Who should own polymer ai internally
- What does a first success usually look like
Introduction Beyond Trial-and-Error in Polymer R&D
Most labs don't call it trial-and-error. They call it experience, screening, platform knowledge, or iterative development. All of that is real. But when data lives in disconnected systems and project knowledge is hard to retrieve, even strong teams end up repeating work they've already paid for.
In polymer development, that inefficiency shows up everywhere. A formulation scientist can't compare old resin systems because naming conventions changed between programs. A process engineer sees performance drift but can't trace it back to lot history or compounding conditions. An analytical chemist spends more time rebuilding methods and data tables than helping the team interpret what the material is doing.
That's why polymer ai matters now. The opportunity isn't just faster prediction. It's better coordination between formulation, processing, characterization, and decision-making.
Where conventional workflows stall
Three patterns usually signal that a team is ready for polymer ai:
- Knowledge is trapped: valuable results exist, but they're buried in reports, unlabeled files, or instrument-specific formats.
- Projects depend on a few experts: when a senior scientist is unavailable, decision quality drops.
- Experiments aren't compounding: each round generates data, but the next round doesn't fully learn from it.
Those aren't software problems alone. They're operating model problems.
The real cost of fragmented polymer R&D isn't only failed experiments. It's the loss of learning between experiments.
A practical polymer ai program changes the unit of work. Instead of treating each project as a fresh campaign, the organization builds a reusable system of formulations, process conditions, analytical outputs, and outcome labels. Once that structure exists, models can support choices that scientists already make every day: what to synthesize, what to test next, which variables matter, and when a result is likely too uncertain to trust.
What mature teams do differently
The strongest teams don't start by asking for an all-purpose model. They start by tightening the link between historical evidence and current decisions.
That usually means:
- Choosing a narrow but valuable use case.
- Cleaning enough historical data to support it.
- Building a feedback loop so new experiments improve the system.
- Making sure scientists can inspect why the model recommended a direction.
Polymer ai works best when it behaves like a disciplined lab partner. It should narrow options, expose trade-offs, and learn from every validated result. If it can't do those things, it becomes another dashboard no one uses.
Understanding Polymer AI The Core Scientific Approaches
Polymer ai is often discussed as if it were one method. It isn't. In practice, teams rely on a mix of statistical learning, scientific constraints, and workflow logic. The important question isn't whether a model is advanced. It's whether it matches the kind of data and decision you have.
Three model families you'll actually encounter
The first family is pure machine learning. These models learn patterns from historical structure-property and process-property data. They're useful when you have enough examples and the relationships are too nonlinear or multivariate for simple regression to capture cleanly.
A second family is physics-informed AI. These approaches bring in domain constraints, mechanistic priors, or known scientific relationships. They're useful when you want the model to stay grounded in behavior the team already trusts, especially in lower-data settings.
The third family is hybrid modeling, the area where many practical polymer programs are found. You combine empirical data with mechanistic reasoning, engineered descriptors, or simulation outputs so the model can generalize better than either approach alone.
Practical rule: if the model can't respect known chemistry and processing limits, scientists won't trust it when the stakes rise.
An Accounts of Materials Research article on ML-assisted polymer design describes the common workflow as a closed-loop pipeline. Teams define target properties, train property-prediction models on existing structure-property data, generate virtual polymer candidates, screen them in silico, then validate in the lab. The same framework can incorporate transfer learning, multitask learning, graph neural networks, Bayesian optimization, and multifidelity learning to handle sparse, heterogeneous polymer datasets. New experimental results then feed back into the database to refine the models over time.
That last part matters more than many teams expect. A static model is rarely enough in polymer R&D because targets shift, raw materials change, and process windows move.
Comparing AI approaches in polymer R&D
| Approach | How It Works | Best For | Key Challenge |
|---|---|---|---|
| Pure machine learning | Learns correlations from historical polymer, formulation, and test data | Property prediction when past data is reasonably consistent | Weak extrapolation when chemistry moves far outside training data |
| Physics-informed AI | Adds scientific constraints or mechanistic priors | Lower-data programs and cases where explainability matters | Can be slow to build if the scientific assumptions are incomplete |
| Hybrid models | Combines empirical learning with domain knowledge or simulation inputs | Enterprise R&D where multiple data types need to work together | Integration complexity across tools, teams, and data standards |
What works and what doesn't
What works is narrowing the prediction task. Predict glass transition behavior, viscosity trend, or pass-fail likelihood under a defined process condition. What doesn't work is asking one model to predict every downstream property across every polymer family with equal confidence.
What works is representing chemistry and process together. A polymer composition without extrusion temperature, cure schedule, or molecular weight context often tells only half the story. What doesn't work is pretending a material is independent from how it was made and measured.
A useful mental model is this: pure ML is the brilliant student who has seen many examples, physics-based modeling is the experienced scientist who knows the rules, and hybrid modeling is the project team that lets each one correct the other.
The Data Backbone Preparing for AI-Driven R&D
Most failed polymer ai efforts don't fail because the models were weak. They fail because the data foundation never became operational.
Teams often wait for perfect data before they start. That's a mistake. You don't need perfect data. You need traceable, standardized, decision-relevant data. The goal is to build a backbone that links what was made, how it was made, how it was tested, and what happened.

What belongs in the backbone
At minimum, the backbone should connect four record types:
- Material definitions: monomers, additives, resin grades, supplier identifiers, lot information, and composition logic.
- Process context: mixing order, shear history, thermal profile, reaction conditions, residence time, and scale.
- Analytical outputs: raw files, processed values, units, method versions, calibration context, and pass-fail interpretations.
- Program outcomes: target properties, customer requirements, scale-up notes, and final technical decisions.
If one of those layers is missing, model quality drops fast. A tensile result without specimen prep details can mislead. A viscosity value without temperature context is barely reusable. A promising lab result without scale-up notes is dangerous.
How teams get stuck
The first trap is treating data harmonization as an IT cleanup exercise. It isn't. Scientists need to define what fields matter and which ambiguities create downstream model error.
The second trap is over-modeling too early. Don't begin with ontology debates that take months. Start by making the most reused experimental pathways consistent. Then extend.
For many teams, a practical early step is mapping old fields into a smaller canonical schema and then using targeted machine learning feature engineering techniques to convert lab variables into model-ready inputs. In polymer work, that often means encoding formulation ratios, thermal history, categorical chemistry families, and missingness patterns in a way the model can learn from without losing scientific meaning.
Centralization alone doesn't create value. The value appears when a scientist can retrieve comparable prior work in time to change the next experiment.
A secure data backbone also needs governance. Access controls, version history, method traceability, and approval logic aren't bureaucracy. They protect IP and keep teams from training models on conflicting or poorly labeled records.
One practical option in this category is Polymerize Connect, which is designed to unify fragmented experimental data from spreadsheets, ELNs, and other silos into a centralized data backbone for materials R&D. Whether you use that kind of platform or build around your existing stack, the requirement is the same: one usable source of truth for formulations, process history, and performance data.
Common AI Workflows in Polymer Development
The useful question in polymer ai isn't “Can we use AI?” It's “Which workflow creates value first?” In most labs, four workflows account for the bulk of practical wins: property prediction, formulation optimization, causal analysis, and experiment planning.
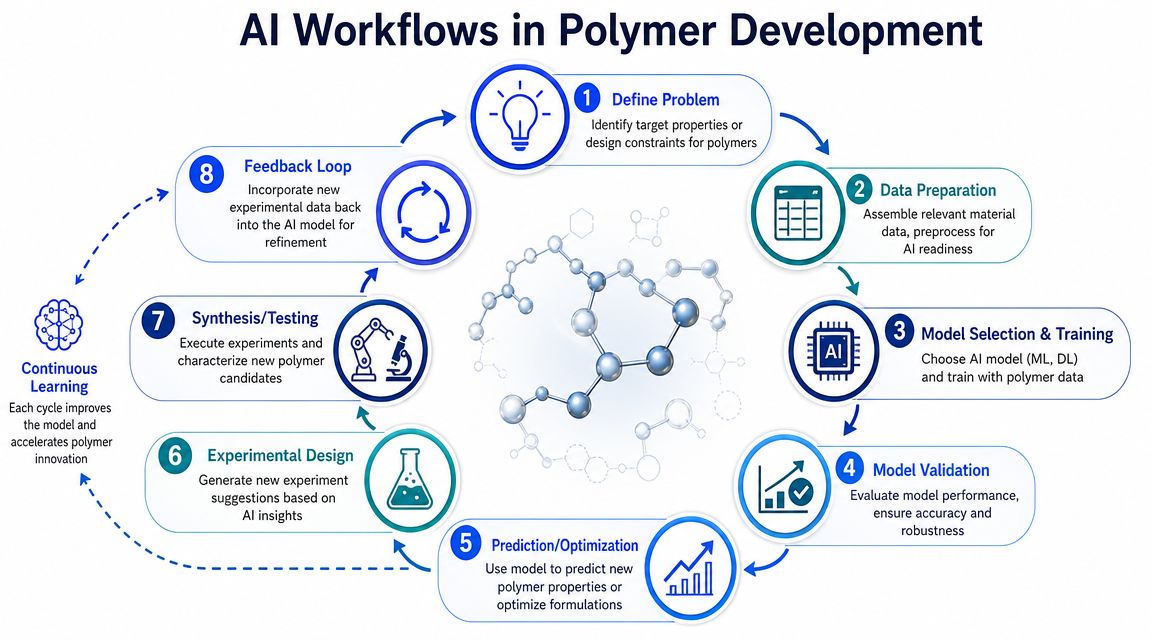
A working loop inside a polymer lab
Consider a team trying to develop a new formulation with a narrow thermal and processing window. They begin by defining the target envelope. That includes the property threshold they must hit and the process constraints they can't violate.
Next, they assemble historical formulations and test outcomes, train a model, and score virtual candidates before they make anything. That's the first gain. The lab avoids spending its first round on low-probability options.
A Citrine example of AI-driven polymer screening shows why workflow design matters. In that project, the platform predicted a thermal property for more than 2,500 novel polymers and supported the design of about 2,000 de novo candidates in roughly 5 months, using a hierarchical model with three different underlying mechanisms affecting the target property. The lesson isn't just speed. It's that polymer AI gets stronger when the property is decomposed into mechanistic submodels instead of forcing every chemistry through one black-box predictor.
This visual captures the full cycle from problem definition through learning and retraining.
What each workflow is good at
Property prediction is the fastest to deploy. You ask the model to estimate a property before synthesis or testing. It's useful when the lab is overwhelmed with options and needs ranking, not certainty.
Formulation optimization is broader. Here the model doesn't just score candidates. It searches combinations against multiple constraints, which is especially helpful when one additive improves one property but degrades another.
Causal discovery is where many teams mature. Correlation is enough to prioritize experiments, but not enough to change platform chemistry with confidence. Causal analysis helps separate strong drivers from convenient but misleading patterns.
Smart experiment planning is the most operationally powerful workflow once the backbone exists. The system proposes the next experiments that are likely to be most informative, not just most promising. That distinction matters because labs need learning efficiency, not only occasional wins.
- Use prediction when the search space is too large for brute-force synthesis.
- Use optimization when trade-offs between properties dominate the project.
- Use causal methods when teams keep debating why a behavior occurs.
- Use active experiment planning when test capacity is the bottleneck.
A strong polymer ai loop keeps all four connected. New results don't just close a project task. They make the next round sharper. That iterative structure is consistent with the closed-loop design workflow described in the earlier research article, where new experimental results continuously refine the model and reduce unnecessary physical cycles.
Enterprise-Ready Polymer AI Security IP and Scale-Up
A lab demo isn't an enterprise deployment. The difference shows up when legal, IT, process engineering, and manufacturing ask whether the system protects IP, controls access, and can support decisions that survive scale-up.
Security and IP are design constraints
Polymer R&D data is unusually sensitive because it combines composition, process know-how, analytical interpretation, customer requirements, and often unpublished application data. If those records are scattered across unmanaged exports and ad hoc analysis notebooks, your AI stack inherits the same risk.
The practical controls are familiar. Encrypt sensitive data. Enforce role-based access. Track model inputs and outputs. Separate exploratory environments from validated workflows. Make sure external collaboration doesn't expose formulation logic beyond what a partner needs to see.

IP protection also needs forethought. If a model suggests a new composition space, who records provenance? Can you reconstruct which data, constraints, and decision steps led to that candidate? If not, you may struggle later with patent support, internal review, or freedom-to-operate discussions.
Secure polymer ai isn't just about preventing leaks. It's about preserving the chain of reasoning behind valuable technical decisions.
Scale-up is where weak AI programs fail
A review on AI for polymer discovery and development points to a major field-wide challenge: closing the loop from virtual candidates to validated, scalable materials. It notes that active learning, explainable AI, and hybrid workflows show promise, but practical guidance for systematically reducing failed synthesis and scale-up attempts remains limited.
That matches what many teams see internally. A model can identify an attractive candidate that wins on predicted performance but loses in the plant because viscosity shifts, mixing order matters, impurity tolerance is narrow, or the analytical method wasn't sufficiently reliable to compare pilot and production outputs.
Three practices help:
- Model processability early: don't wait until handoff to ask whether the material can be made consistently.
- Prefer explainable recommendations: scientists and engineers need to inspect the variables driving a suggestion.
- Carry uncertainty explicitly: a cautious recommendation with clear confidence bounds is more useful than an aggressive one that hides risk.
Scale-up requires the AI program to speak the language of manufacturing. That means recipe windows, raw material variability, equipment constraints, QC methods, and release criteria. If your polymer ai effort never reaches those artifacts, it remains a research prototype.
Your Implementation Roadmap From Pilot to Production
The fastest path is rarely the broadest one. Teams that try to launch polymer ai across every polymer family, every business unit, and every instrument at once usually create complexity before they create trust.
Stage one proves usefulness
Start with a pilot that has three qualities: the problem is important, the historical data exists, and the success criteria are visible to scientists. Good pilot choices include ranking candidates before synthesis, narrowing additive combinations, or recommending the next experiment in a constrained formulation space.
The pilot should also include the people who already own the decisions. Don't build a model in isolation and present it after the fact. Put formulation, analytics, and data staff in the same loop from the start.

A good pilot output isn't a flashy dashboard. It's a decision scientists can compare against their current method.
Stage two makes it repeatable
Once the first use case works, formalize the pieces that let another team reuse it. That includes schema standards, data review rules, model retraining triggers, and ownership boundaries between scientists and data specialists.
This is also when instrumentation and inspection data become more important. If your development program depends on image-based quality checks, microstructure assessment, or visual defect detection, the AI system needs those signals in a usable form. Teams working through manufacturing-facing inspection problems can learn from broader Zephony's vision system expertise, especially when they're connecting laboratory evidence with production quality workflows.
Stage three turns it into infrastructure
Enterprise integration happens when polymer ai stops being a special project and starts becoming part of the normal R&D operating system.
That shift usually requires:
- A governed data layer that supports more than one project team.
- A model registry and review process so recommendations remain traceable.
- Workflow integration with ELNs, LIMS, analytics pipelines, and project review meetings.
- Training for scientists so they can challenge model output intelligently rather than either overtrusting or ignoring it.
The maturity test is simple. When a new program begins, does the team automatically ask what historical data, comparable chemistries, and model-guided next experiments are available? If yes, polymer ai has become infrastructure. If no, it's still an isolated initiative.
One caution matters here. Don't scale based only on enthusiasm. Scale when the team can show that the pilot's data definitions, review steps, and decision logic survive contact with a second problem.
Measuring Success KPIs and Example Outcomes
R&D leaders don't need abstract promises. They need metrics that tie model activity to technical and financial outcomes.
KPIs that matter in practice
The first useful KPIs are usually operational, not glamorous:
- Experiment efficiency: are scientists running fewer low-value experiments?
- Cycle time: is the team reaching go or no-go decisions faster?
- Reuse of historical knowledge: are old results being retrieved and used in new programs?
- Scale-up readiness: are more candidates entering pilot work with process constraints already considered?
These measures are often available before revenue impact is fully visible. They're also harder to game than vanity metrics like model accuracy in isolation.
Where measurable ROI shows up first
The clearest quantitative evidence today comes from industrial processing rather than lab discovery. In polymer processing, closed-loop AI optimization has been reported to reduce off-spec production by over 2%, cut natural gas consumption by 10% to 20%, and increase throughput by 1% to 3% according to an industry article on AI optimization in polymer processing. The same source notes that, in large-scale plants, those gains can translate into millions of dollars in annual savings.
That matters because it shows polymer ai has already moved beyond academic interest into recognized industrial deployment. When you can improve throughput and reduce waste without adding new equipment, the conversation changes from experimentation to operational effectiveness.
For R&D groups, the lesson is straightforward. Don't measure success only by whether a model predicts well. Measure whether the system changes how decisions are made, how quickly weak options are eliminated, and how smoothly validated materials move toward manufacturing. Those are the indicators that justify continued investment.
Frequently Asked Questions About Polymer AI
Do we need a huge dataset to start
No. You need a dataset that is relevant, reasonably consistent, and linked to a specific decision. Small but well-labeled historical programs can support useful pilots, especially when scientists narrow the problem and include process context.
Messy but informative data is often better than waiting for a perfect future dataset that never arrives.
How is this different from simulation
Simulation starts from explicit physical models. Polymer ai learns from observed data. In practice, strong programs use both. Simulation can help generate useful descriptors or constrain unrealistic suggestions, while AI helps rank options and learn from experimental results faster.
Use simulation when first-principles fidelity is essential. Use polymer ai when historical evidence can accelerate search and prioritization.
What if our historical data is messy
That's normal. Most organizations begin with mixed naming conventions, partial metadata, and inconsistent test records.
The fix isn't to clean everything at once. Start with one chemistry family or one business-critical workflow. Standardize just enough fields to make records comparable, then expand from there. A limited, reliable dataset beats a massive archive no one trusts.
Who should own polymer ai internally
No single function should own it alone. R&D must define the scientific questions, data teams must structure and govern the inputs, and digital or IT teams must support secure deployment.
If ownership sits only with data science, adoption usually stalls. If it sits only with the lab, governance often weakens. Shared ownership works better, with one business-facing leader accountable for outcomes.
Scientists don't need to become full-time data scientists. They do need enough fluency to question a model, inspect uncertainty, and decide when experimental evidence should override it.
What does a first success usually look like
Usually not a breakthrough polymer. More often it's a narrower gain: a shorter candidate list, a better next-experiment recommendation, or faster convergence on a formulation window.
That's enough. Once the team trusts that the system improves daily decisions, broader adoption becomes much easier.
If your team is trying to move from disconnected experimental records to an AI-guided polymer R&D workflow, Polymerize is one platform built for that operating model. It combines a centralized data backbone for materials data with explainable models and workflow support aimed at helping enterprises discover, develop, and scale polymers more systematically.

