A formulation chemist has a target profile, a tight deadline, and a pile of disconnected evidence. One spreadsheet holds historical blends. An instrument export sits on a shared drive. Stability notes live in an ELN. The senior scientist remembers a failure mode from three years ago, but that knowledge isn't structured anywhere the rest of the team can use before the next batch is mixed.
That pattern doesn't create bad science. It creates slow science.
Most materials organizations still run experimental programs as a sequence of educated guesses, manual screening, and post hoc analysis. That worked when portfolios were smaller and design spaces were narrower. It breaks down when teams need to optimize multiple properties at once, move faster from bench to scale-up, and preserve hard-won knowledge across sites and staff turnover. That gap is why investment in this category is rising. The global R&D analytics market is projected to grow from USD 3.25 billion to USD 10.19 billion by 2036 at a 12.10% CAGR, driven by the need to compress discovery-to-commercialization timelines, according to Future Market Insights on the R&D analytics market.
Table of Contents
- Why category confusion slows buying decisions
- What changes when software guides work before the lab run
- Engine 1 and Engine 2 create the operating base
- Engine 3 and Engine 4 improve decision quality
- Engine 5 keeps acceleration usable at enterprise scale
- Waste falls when teams stop testing obvious dead ends
- Speed matters when formulation windows are narrow
- Better data becomes a strategic asset
The Innovation Bottleneck in Modern R&D
The bottleneck in modern materials R&D usually isn't effort. It's decision quality at the moment an experiment is chosen. Teams often know how to run tests efficiently, characterize samples rigorously, and document outcomes well enough for audit purposes. What they lack is a reliable way to narrow the search space before resources are spent.
That distinction matters. If scientists choose from too many plausible formulations, process windows, or additive packages, the lab fills with activity while learning progresses slowly. A team can appear productive and still be stuck in a loop of local optimization. They run another viscosity screen, another cure profile, another compatibility check, then only later realize the design logic itself was weak.
Where the delay actually comes from
In practice, the delay comes from a few recurring conditions:
- Fragmented prior knowledge: Historical experiments exist, but not in a form that supports comparison across projects, chemistries, or sites.
- Expert dependence: Critical interpretation sits with a handful of senior scientists who know what failed before, but can't manually review every new idea.
- Reactive analysis: Teams analyze after the run, instead of using accumulated data to decide what shouldn't be run at all.
- Scale-up disconnect: Bench work proceeds without enough connection to downstream process constraints, so promising formulas fail later for practical reasons.
Most R&D delays start before sample preparation. They begin when teams can't convert prior evidence into a disciplined experimental boundary.
R&D acceleration software addresses that upstream decision problem. At its best, it doesn't just store more data. It helps scientists frame a smaller, better experimental space, align on what success looks like, and make each run teach something useful.
Why leaders are treating this as a strategic category
The urgency isn't theoretical. Materials teams are under pressure to increase throughput without lowering scientific standards. They need to preserve IP, onboard new talent faster, and avoid repeating work hidden in archives, inboxes, or local files. Those demands push software from support function to operating model.
For R&D leaders, the practical question isn't whether digital tools belong in the lab. It's whether the current stack helps scientists decide better before committing material, instrument time, and formulation effort.
Beyond Spreadsheets What Is R&D Acceleration Software
Many buyers misclassify this category. They see a dashboard, an experiment tracker, or a central repository and assume it's another ELN, LIMS, or project management layer. That misunderstanding leads to weak tool selection and disappointing outcomes.
R&D acceleration software is different because its core job is not documentation after the fact. Its core job is to shape better experimental choices before work starts.

Why category confusion slows buying decisions
An ELN records what happened. A LIMS controls samples, workflows, and traceability. A project management tool tells you who owns the next task. All three can be useful. None of them, by themselves, tell a formulator which region of the design space is most likely to fail, which variable interactions matter most, or which next experiment maximizes learning.
That gap is especially costly in materials science because formulation work rarely has one target variable. Teams balance performance, manufacturability, compliance, stability, and cost all at once. If software only helps organize experiments, the burden of deciding what to test stays with human intuition plus scattered precedent.
Sagentia frames the deeper issue clearly. Corporate R&D processes are often designed to be protective, which leaves teams unable to react quickly. True acceleration requires software that forces data-led boundaries on formulators before experimentation begins, rather than only tracking results afterward, as described in Sagentia's paper on R&D acceleration.
What changes when software guides work before the lab run
The practical shift is from reactive recordkeeping to proactive design support.
A capable platform pulls together historical experiments, metadata, process conditions, and outcomes. It then helps a scientist ask better questions. Which combinations are outside known viable windows? Which ingredients repeatedly trigger instability under certain curing conditions? Which formulation families are worth exploring if tensile strength and biodegradability both matter?
That changes the scientist's role in a useful way. Researchers spend less time generating broad batches of low-value data and more time making high-quality trade-off decisions.
A strong system usually helps with tasks like these:
- Boundary setting: Flagging implausible combinations before lab work begins.
- Hypothesis sharpening: Showing which variables are likely causal rather than merely correlated in historical data.
- Experiment prioritization: Recommending a tighter sequence of tests instead of a long undirected matrix.
- Knowledge transfer: Making past failures visible to newer team members without requiring oral history.
Practical rule: If a vendor talks mostly about dashboards, task tracking, or digital records, you're looking at workflow software. If it helps scientists eliminate bad experiments before they happen, you're looking at real acceleration software.
The Five Core Engines of R&D Acceleration
Good category definitions help, but buying decisions still fail when leaders evaluate these platforms as if one feature carries the whole value case. In practice, useful R&D acceleration software works as a system. One engine without the others creates a demo, not an operating capability.
The scale of the surrounding market explains why this matters. The U.S. Scientific Research & Development industry is estimated at $361.2 billion in 2026 with 78,232 businesses, and software R&D accounted for 42% ($291.7 billion) of total U.S. business R&D in 2022, according to IBISWorld's U.S. Scientific Research & Development industry data. In an ecosystem that large, fragmented tools create expensive coordination problems.
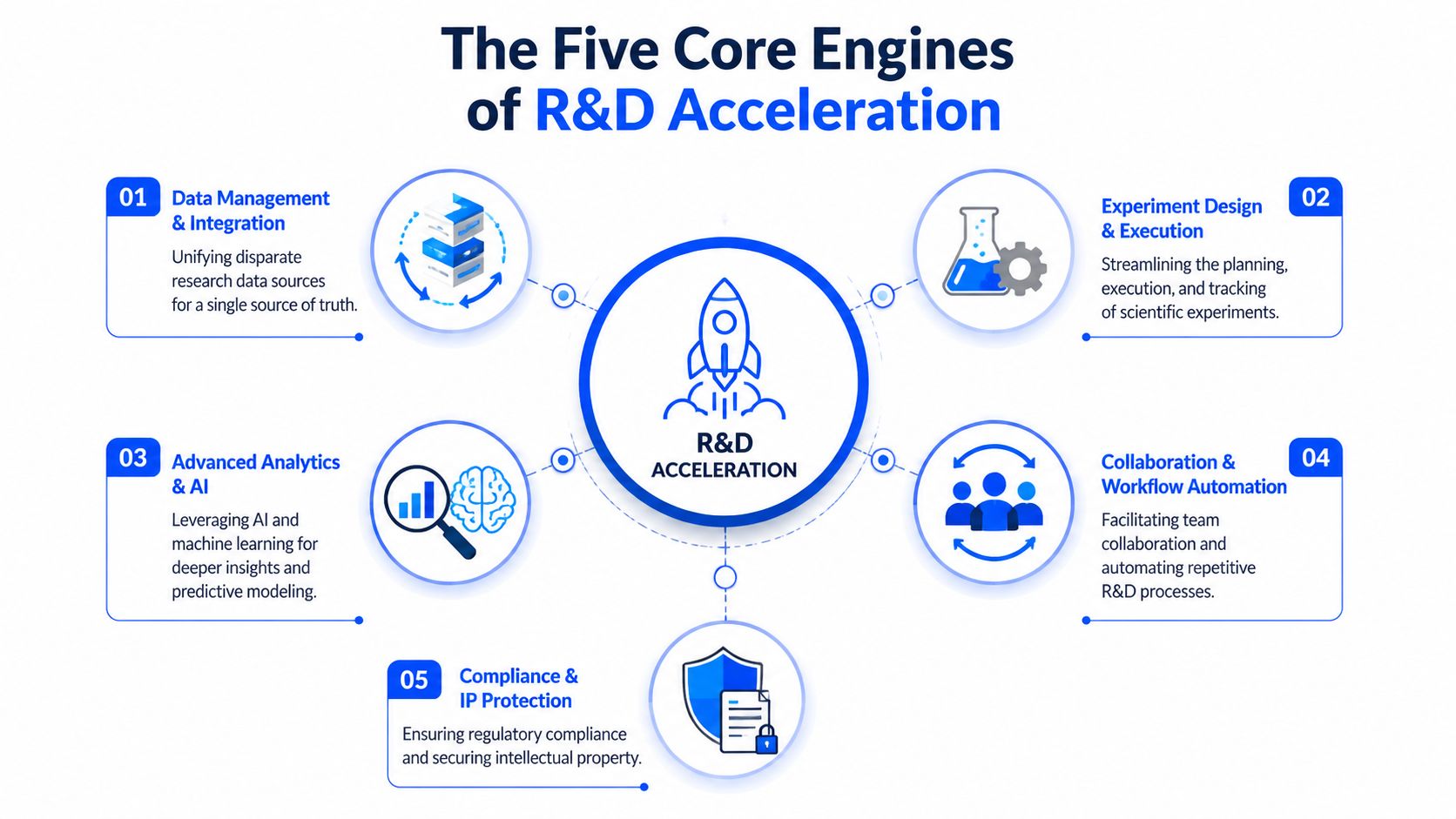
Engine 1 and Engine 2 create the operating base
Data unification comes first. If polymer characterization results, formulation recipes, instrument outputs, and scale-up observations remain split across spreadsheets, ELNs, and local folders, no model can provide reliable guidance. In materials work, even basic harmonization is hard because the same property may be labeled differently across teams, measured under different conditions, or stored without enough context.
The second engine is experiment design and execution support, enabling the platform to move beyond storage and into decision support. It should help scientists define constraints, compare candidate formulations, and preserve the logic behind why a test was chosen. For a polymer team, that might mean structuring a campaign around a limited set of resin, plasticizer, and processing variables instead of letting each scientist create a different matrix from scratch.
A lot of technical buyers benefit from revisiting ML basics for tech professionals here, not because they need to become model builders, but because it helps them ask sharper vendor questions about training data quality, explainability, and model fit.
Engine 3 and Engine 4 improve decision quality
The third engine is advanced analytics and explainable AI. The point isn't to produce a black-box score and call it science. The point is to estimate likely outcomes and reveal which variables drive them. In a coatings program, an explainable model might highlight that a particular solvent package looks acceptable on one property but pushes the formulation toward instability when curing conditions shift.
The fourth engine is collaboration and workflow automation. This matters more than many teams expect. Scientists don't just need predictions. They need shared visibility into assumptions, exceptions, and changes. If one group learns that a raw material behaves differently under a revised mixing order, that information must propagate without waiting for a quarterly review or a hallway conversation.
A platform like Polymerize, for example, is built around this combined model. It unifies experimental data, applies explainable models for materials properties and formulations, and supports next-experiment planning in a secure enterprise environment. That's the type of architecture buyers should look for, regardless of vendor shortlist.
Engine 5 keeps acceleration usable at enterprise scale
The fifth engine is compliance and IP protection. Many pilots often stall here. A model may look promising, but if the system can't respect access controls, support regulated workflows, and protect proprietary formulation knowledge, adoption won't spread past a small innovation group.
For enterprise materials teams, security isn't an add-on. It's part of usability. Scientists won't trust a platform that exposes sensitive recipes too broadly, and legal teams won't support rollout if governance is weak.
Here is the practical test I use when reviewing platforms:
- Can it ingest ugly real-world data? Clean demo datasets don't prove anything.
- Can scientists understand the recommendation? If not, trust collapses.
- Can it fit existing systems? A tool that demands total process replacement usually dies in procurement.
- Can it survive scale-up realities? Bench-only logic often fails in production-facing organizations.
- Can it protect IP while widening access to insight? That's the central enterprise tension.
Turning Scientific Data into Business ROI
Technical teams often undersell this category internally by describing it as a lab productivity tool. That's too narrow. The primary business case is that better experimental decisions improve capital efficiency, reduce waste, and make development programs more predictable.
Near the start of a buying process, executives usually ask a blunt question. Will this reduce the cost of learning? If the answer is yes, the ROI discussion gets easier.
A concrete benchmark exists in industrial chemical R&D. Capgemini Engineering reports that AI-powered R&D acceleration software integrating physics-based models with experimental data can reduce failed experiments by 50% and accelerate formulation testing by over 20%, as described in Capgemini Engineering's digital acceleration framework for industrial R&D.
Waste falls when teams stop testing obvious dead ends
Every failed experiment isn't equal. Some failures are productive because they eliminate uncertainty in a disciplined way. Others are avoidable because the organization already had enough evidence to predict the likely outcome but couldn't surface it in time.
When software identifies failure points early, labs consume fewer specialty additives, fewer instrument hours, and less scientist time on runs that were weak candidates from the start. In materials programs with expensive raw materials or constrained pilot capacity, that can be the difference between a portfolio that advances and one that stalls.

Speed matters when formulation windows are narrow
The value of faster testing isn't just calendar compression. It changes how teams make strategic bets. If a platform can move scientists through formulation cycles more quickly, they can evaluate more serious options within the same business window. That matters when customer requirements shift, regulations tighten, or a manufacturing partner needs a revised specification quickly.
This video gives a useful industry view of that shift in practice.
Good ROI in R&D doesn't come from making every experiment faster. It comes from making fewer low-value experiments necessary.
Better data becomes a strategic asset
There is a third layer of return that many finance teams miss on first review. Once experimental records, outcomes, and decision logic are structured in a reusable way, the organization builds a proprietary data asset. That asset improves onboarding, strengthens continuity when staff changes, and supports stronger future models.
The compounding effect is practical. A team that captures both success and failure with useful context becomes better at defining boundaries on the next program. That doesn't just lower current project cost. It improves the organization's ability to pursue harder material challenges with confidence.
R&D Acceleration in Action Use Cases for Materials Science
The easiest way to spot whether a platform is real acceleration software is to follow the workflow of a live materials problem. If the tool only becomes useful after a scientist has already chosen the experiment, it is helping with administration. If it changes the choice itself, it is changing R&D.
Use case one bio-based polymer development
A team is tasked with developing a bio-based polymer that needs acceptable tensile performance while still meeting biodegradability goals. In the manual workflow, scientists start with a reasonable shortlist of monomer ratios, plasticizers, and processing conditions. Each scientist contributes a different mental model. One prioritizes mechanical strength. Another worries about moisture sensitivity. A third wants to preserve processing ease for downstream equipment.
They build a large matrix. Early batches produce mixed results. A few look promising on strength but drift on degradation behavior. Others biodegrade well but create processing headaches. The team learns, but slowly, because each round only answers a narrow question and the interactions between variables stay murky.
With R&D acceleration software, the workflow begins differently. Historical experiments from related polymer systems are pulled together, including failed blends, processing notes, and property outcomes. The software highlights feasible regions and warns where ingredient combinations or process windows have historically produced poor trade-offs. Scientists still choose the program, but they start inside a narrower corridor.
That changes the meeting in a noticeable way. Instead of arguing over a broad list of candidate blends, the team debates a smaller set of hypotheses. Why does one ratio family preserve strength better under a given thermal profile? Which additive appears to help one property while hurting another? The software doesn't replace chemical judgment. It gives the team a higher-value problem to solve.
Use case two low-VOC coating formulation
The second case is a formulation chemist developing a low-VOC industrial coating. The brief sounds straightforward until the practical constraints show up. The coating must remain stable in storage, apply consistently, cure under practical plant conditions, and still deliver target performance.
In a guess-and-check process, the chemist modifies solvent balance, resin choice, additives, and cure conditions across many rounds. Data accumulates quickly, but interpretation lags. A formula may look acceptable after application tests, then reveal instability under storage or sensitivity to curing variation. Because the knowledge is fragmented, the same dead-end logic gets revisited under slightly different names.
A software-guided workflow makes the hidden trade-offs visible earlier. Historical formulations and test results are structured so the chemist can compare not just final outcomes, but the conditions under which those outcomes held. The system can flag that one additive package repeatedly creates downstream issues under a certain cure window, even if initial bench results looked fine.
The practical gain isn't that every answer becomes obvious. It's that the chemist spends less time wandering through adjacent failure modes.
A useful implementation also changes collaboration:
- Bench scientists see which variables deserve tight control in the next run.
- Process engineers can comment earlier on manufacturability constraints.
- Project leaders can review evidence in a form that supports decisions, not just status updates.
The strongest use cases don't show software replacing scientists. They show software giving scientists fewer, better choices.
Your Adoption Roadmap and Evaluation Checklist
Most failed adoptions start too big. Leaders buy a broad platform, announce a transformation program, and then ask teams to clean years of inconsistent data while also changing how they work. Momentum drops fast.
A better approach is phased and narrow at the start. The goal of the first phase isn't enterprise transformation. It's to prove that the software can improve one high-friction decision area in a way scientists trust.
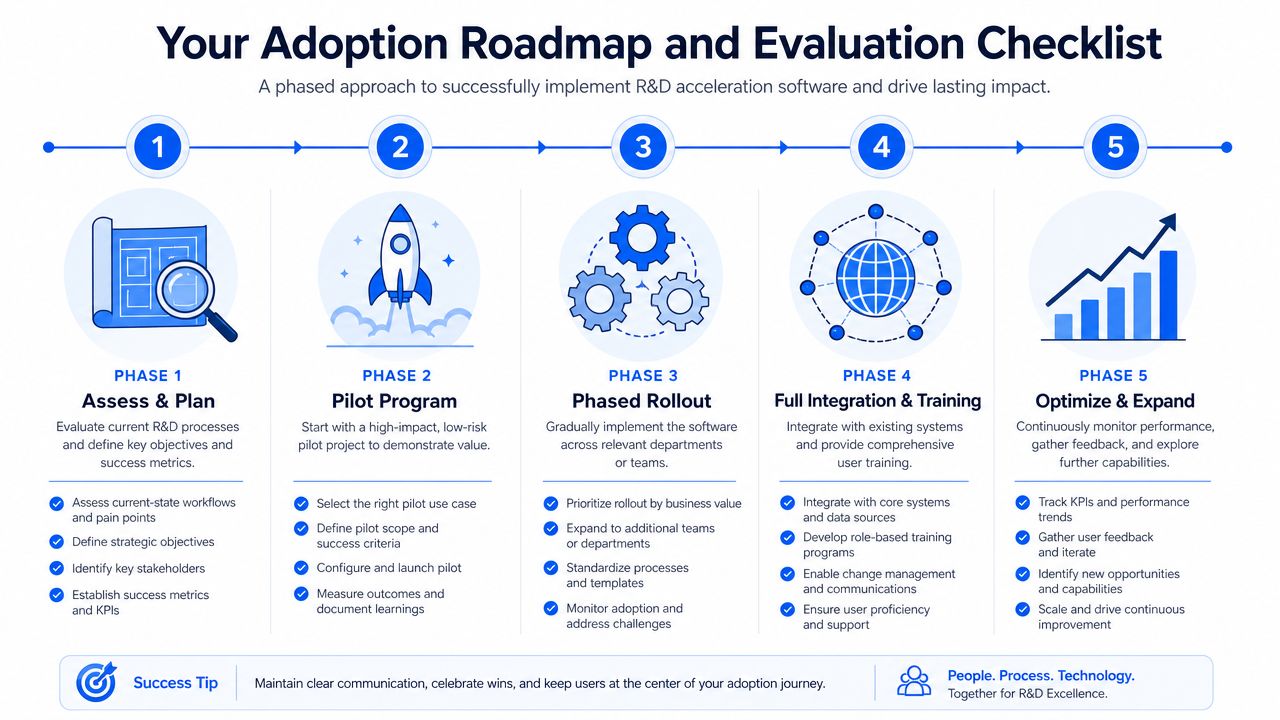
A phased rollout that reduces risk
Start with a pilot where three conditions are true. The problem matters commercially, historical data exists in multiple places, and the team is already frustrated by trial-and-error. In materials organizations, that often means a stubborn formulation family, a recurring scale-up issue, or a product line where property trade-offs are hard to manage.
A practical rollout usually looks like this:
- Assess and scope: Choose one material class or formulation family. Define the decision you want to improve, not just the data you want to centralize.
- Unify priority data: Bring together the minimum dataset needed for a credible pilot. Don't wait for perfect historical cleanup.
- Model one decision point: Focus on a concrete use case such as screening candidate formulations, identifying likely failure regions, or prioritizing next experiments.
- Test with working scientists: Ask the team to use recommendations in real planning cycles. Adoption fails when only digital or analytics staff touch the system.
- Expand only after trust forms: Scale to adjacent workflows once scientists can explain why the recommendations are useful.
R&D Acceleration Software Evaluation Checklist
| Category | Evaluation Question | Why It Matters |
|---|---|---|
| Data ingestion | Can the platform ingest spreadsheets, ELN exports, instrument files, and process notes without a long custom project? | Most organizations can't wait for a perfect data warehouse before they start. |
| Context handling | Does it preserve formulation context, process conditions, and test metadata instead of flattening everything into generic fields? | Materials data is only useful when the surrounding conditions stay attached. |
| Model explainability | Can scientists see why the model recommends a region, rejects a candidate, or highlights a variable interaction? | Black-box output won't survive technical review. |
| Experiment planning | Does the software support next-best-experiment decisions, not just result storage and visualization? | This is the dividing line between acceleration and administration. |
| Integration | Can it fit with current ELN, LIMS, analytics, and reporting workflows? | Teams won't adopt a tool that creates duplicate work. |
| Security and governance | Does it support enterprise controls such as role-based access and auditable governance? | IP protection determines whether the pilot can scale. |
| Support model | Will the vendor help translate scientific problems into usable workflows and models? | Many failures are implementation failures, not software failures. |
Selection advice: Ask every vendor to walk through a past failed experiment and show how their system would have prevented it or deprioritized it before the lab run.
From Incremental Gains to Exponential Discovery
The strongest argument for R&D acceleration software isn't that it helps teams work faster inside the same trial-and-error structure. It's that it changes the structure itself. Instead of treating experimentation as a wide search followed by analysis, it turns prior data into boundaries, priorities, and evidence-based starting points.
That shift matters most in materials science because complexity compounds quickly. A polymer, coating, adhesive, or specialty chemical program rarely fails from lack of effort. It fails because too much of the search space remains open for too long, and the organization learns too slowly which constraints matter.
The long-term direction is even more consequential. Quantitative modeling of full automation in AI R&D indicates a 24x software acceleration rate that can scale to 270x within a single year, yielding approximately 3.5 years of progress in the first year alone, even without increased computing power, according to this analysis of full automation in AI R&D. That figure comes from software-focused modeling, not a direct claim about today's materials labs. Still, it points to where the operating model is heading. More of the cycle will be software-guided, and more value will come from systems that design, test, and refine hypotheses in tighter loops.
For R&D leaders, the immediate priority isn't full autonomy. It's building the data backbone, decision discipline, and scientific trust required to benefit from the next wave. Teams that do this well won't just run labs more efficiently. They'll define which discoveries become possible.
If you're evaluating platforms built specifically for materials organizations, Polymerize is one example to review. It focuses on unifying fragmented experimental data, applying explainable models to materials and formulations, and helping teams guide discovery before unnecessary experiments are run.

