Your team already knows the pattern. A promising material concept shows up in the lab, early results look encouraging, and then the process slows to a crawl. Simulation takes too long to support daily decisions. Historical data is too sparse, too noisy, or too inconsistent for a pure machine learning model to trust. Scientists end up making the next experiment based on experience, intuition, and whatever can be stitched together from ELNs, spreadsheets, and old reports.
That's the main gap in materials R&D. It isn't a lack of physics. It isn't a lack of AI. It's the lack of a workable bridge between the two.
Physics based machine learning is that bridge when it's used correctly. It gives R&D teams a way to combine known science, like conservation laws, kinetics, transport behavior, and process constraints, with the pattern-finding speed of modern machine learning. For materials and polymer teams, the value isn't academic elegance. The value is better decisions under real operating conditions: sparse data, messy experiments, pressure to scale, and no patience for black-box outputs that violate chemistry or process reality.
Table of Contents
- Polymer formulation and property prediction
- Faster screening instead of slower simulation queues
- Reactor modeling and process control
- Smart data beats big data
- Design experiments around what the physics does not already fix
- Data quality still decides the outcome
- Why PBML is easier to trust
- Uncertainty is part of the decision, not an afterthought
- What teams should actually review
- Start with a pilot that matters
- Build the data backbone before scaling models
- Pair domain experts with model builders
The Innovation Bottleneck in Materials R&D
Materials development usually breaks down in one of two places. Either the team leans on first-principles models that are scientifically grounded but too slow or too narrow for fast iteration, or it tries a data-driven model that looks impressive in a notebook and then falls apart when the formulation, process window, or feedstock shifts.
That tension is especially visible in polymers. Structure-property relationships are nonlinear. Processing conditions change performance. Lab data often comes from different instruments, operators, and test methods. Scale-up introduces another layer of complexity because the variables that mattered in bench work don't always dominate in production.
Why the old split no longer works
Traditional physics-based modeling is still essential. If you're modeling diffusion, rheology, curing, crystallization, or reactor behavior, physical equations give you causality and guardrails. But these models can be expensive to run, difficult to calibrate, and brittle when the actual system includes unknown interactions, impurities, or hard-to-measure states.
Pure machine learning has the opposite profile. It can fit complex nonlinear relationships quickly, but it needs representative data and it often struggles outside the conditions it has seen before. In R&D, that matters. Teams rarely have clean, balanced datasets covering the full formulation and process space.
Practical rule: If your model can predict a material behavior that violates known chemistry or process constraints, it isn't accelerating science. It's creating rework.
Where physics based machine learning fits
Physics based machine learning works because it doesn't force a false choice. It blends domain knowledge with data-driven learning so the model can learn faster and stay grounded in what scientists already know about the system.
For R&D leaders, the practical implication is straightforward:
- Use physics when the governing behavior is known and important.
- Use machine learning where interactions are too complex, noisy, or expensive to model directly.
- Use both together when experimental data is limited and wrong predictions are costly.
This is why physics based machine learning has become relevant to materials programs trying to shorten development cycles without lowering scientific rigor. It's not replacing simulation or experimentation. It's making both more useful in the actual decision loop.
What Is Physics Based Machine Learning
A useful way to think about physics based machine learning is to compare it to teaching. If you teach someone to write by giving them only a massive pile of documents, they may eventually imitate patterns. But if you also teach grammar, syntax, and rules, they learn faster and make fewer nonsensical mistakes.
That's what physics based machine learning does. It gives the model rules of the world before asking it to learn from data.
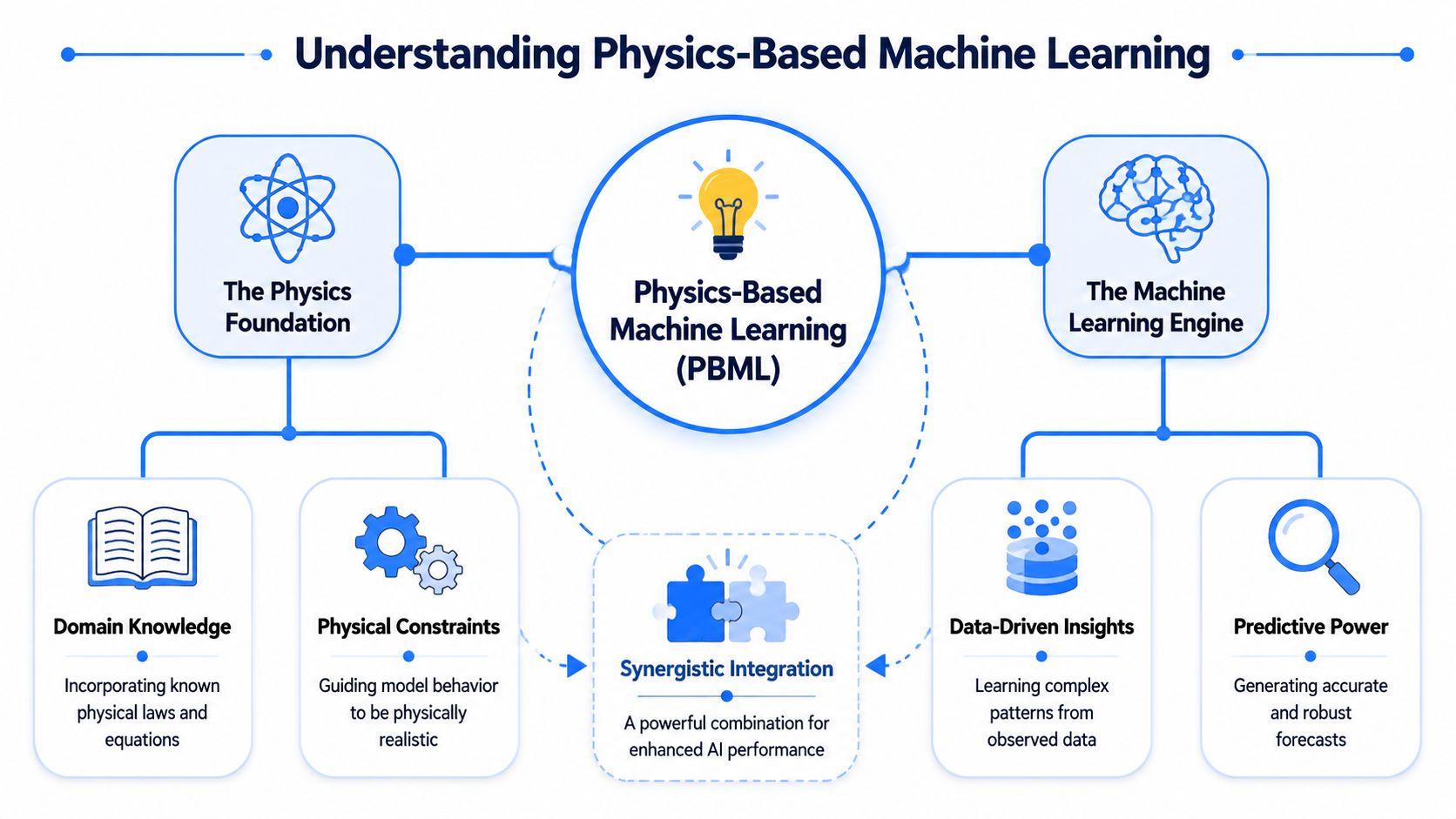
The core idea
Instead of treating the model as a blank slate, PBML embeds physical knowledge directly into the model architecture or training objective. Those constraints can include conservation laws, symmetries, invariances, boundary conditions, constitutive relationships, or known differential equations.
That changes the learning problem in a big way. The model no longer has to discover everything from raw data. It only has to learn the parts the physics doesn't already explain.
According to this overview of physics-informed machine learning, embedding physical constraints into the architecture or loss function can reduce training sample requirements by several orders of magnitude, while helping models generalize better with much less data.
What that means for materials teams
In materials R&D, this matters because data is rarely abundant in the way mainstream AI assumes. You may have a small number of high-value experiments, sparse microscopy data, noisy reactor observations, or uneven property measurements across formulations.
PBML is useful when you know part of the system already. Examples include:
- Reaction kinetics: You know the broad governing mechanism, but not every side reaction or rate interaction.
- Transport behavior: Diffusion or heat transfer is understood, but real process conditions introduce deviations.
- Mechanical response: The physical structure suggests constraints, even if the full response surface is hard to fit from experiments alone.
A good PBML model doesn't just fit data. It rejects impossible answers before they become recommendations.
Two common ways teams impose physics
Here's the simplest practical distinction:
| Approach | How it works | Best when |
|---|---|---|
| Soft constraints | Physics is added to the loss function as a penalty | You need flexibility and can tolerate some deviation during training |
| Hard constraints | Physics is built directly into the architecture | Predictions must always remain physically plausible |
For practitioners, the trade-off is familiar. Soft constraints are easier to implement and often easier to tune. Hard constraints are stricter, but they can be more reliable in safety-critical or process-critical settings.
The point isn't to make the model more complicated. The point is to make it wrong less often in ways that matter.
The Three Core Types of PBML Models
Materials teams usually do not need a taxonomy lesson. They need to decide which model class will cut experimental waste, speed up screening, and still hold up when a chemist asks why the prediction changed. In practice, three PBML patterns cover most of that ground: physics-informed neural networks, hybrid or grey-box models, and surrogate models with physics constraints.
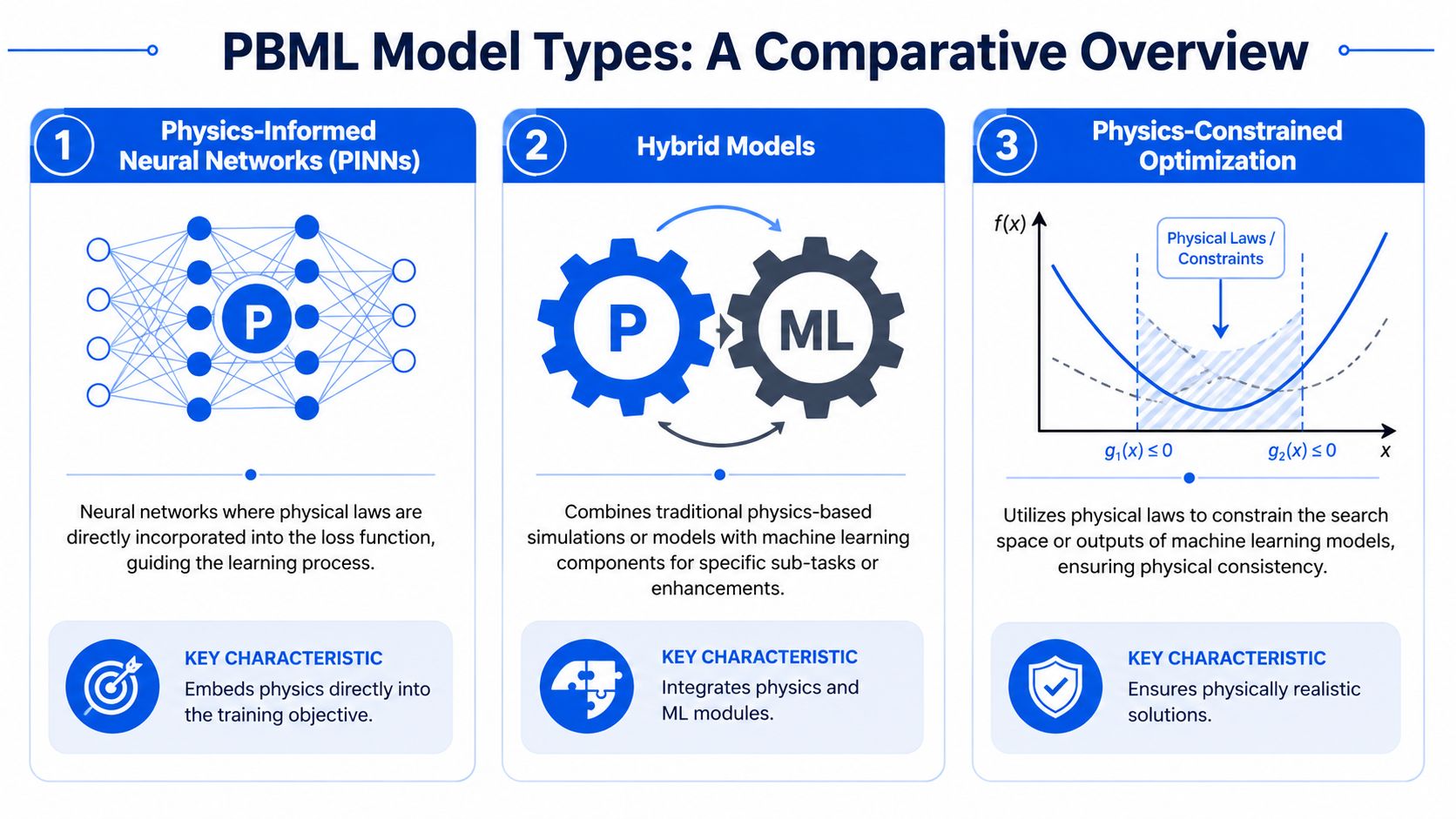
The useful question is not which category sounds more advanced. The useful question is where the bottleneck sits in your R&D workflow.
Physics-informed neural networks
PINNs add governing equations, conservation laws, or boundary conditions directly into training. That makes them a strong fit when the physics is well defined, measurements are limited, and the team needs predictions that stay inside known operating behavior.
For polymer and materials work, that often means diffusion, heat transfer, cure kinetics, stress fields, or reactor-state estimation. PINNs can also help with inverse problems, such as estimating latent parameters from sparse sensor or lab data.
Use PINNs when:
- The equations are trusted enough to constrain learning
- The measured dataset is thin or uneven
- The hidden parameters matter as much as the forward prediction
- The cost of physically impossible predictions is high
The trade-off is real. PINNs can be harder to train, slower to tune, and sensitive to how the physics terms are weighted in the loss. If your team already has a fast, reliable numerical solver and enough data around it, a PINN may be extra machinery without much operational gain.
Hybrid and grey-box models
Hybrid models are usually the best starting point for enterprise R&D groups because they fit how scientists already work. The mechanistic part handles what is known. The machine learning part captures what the equations miss.
That split is common in polymer development. A baseline model may represent reaction pathways, mass balances, or transport behavior well enough for first-order behavior, while additives, impurities, morphology, and processing history drive the residual error. A grey-box model lets the team keep the physical structure and train the data-driven part only where it adds value.
This approach works well when you need to integrate with existing lab and plant systems instead of replacing them. In many organizations, the fastest path is not a clean-sheet AI stack. It is a model that can sit on top of LIMS records, simulation outputs, historian data, and existing process models with limited disruption.
Hybrid models are also easier to explain to technical stakeholders. That matters when formulation scientists, process engineers, and quality teams all need to trust the same recommendation.
The downside is interface design. If the boundary between the mechanistic block and the learned block is poorly chosen, error propagation gets messy and root-cause analysis becomes harder. Teams that do machine learning for predictive maintenance run into the same issue. The model is only useful when the physics features, sensor signals, and failure logic are partitioned in a way engineers can inspect.
Surrogate models with physics awareness
Surrogate models replace something expensive. Usually that means a finite element run, a molecular simulation, a multiphysics workflow, or a large design-of-experiments campaign that is too slow for daily iteration.
For materials R&D, surrogates are often the highest-ROI option when the problem is screening speed. A good surrogate can rank formulations, narrow process windows, or support optimization loops fast enough for actual decision-making. Physics constraints help keep those fast predictions inside credible bounds.
They are especially useful when:
- Simulation is the bottleneck
- The team needs rapid what-if analysis
- The design space is large but structured
- The output of interest is expensive to measure or compute
Coverage matters more than architecture here. If the training set misses a region of formulation space, the surrogate can fail without indicating its uncertainty and still look confident. For polymer programs, that usually means the experimental design has to span composition, processing conditions, and environmental exposure together, not one variable at a time.
A practical comparison:
| Model type | Best fit in materials R&D | Main advantage | Main limitation |
|---|---|---|---|
| PINNs | Known equations, sparse observations, parameter inference | Strong physical consistency | More training and tuning effort |
| Hybrid models | Partially understood systems with known process logic | Easiest fit with existing R&D workflows | Requires careful partitioning between physics and ML |
| Surrogate models | Slow simulations or expensive screening loops | Fast iteration for design and optimization | Reliability depends on training coverage |
A simple decision rule helps. Start with hybrid models if your team already has mechanistic models and wants business value quickly. Use PINNs if the governing equations are central and the data is limited. Use surrogates if simulation throughput is the constraint and the goal is to evaluate many candidate materials or process settings quickly.
Real-World Applications in Materials and Polymer R&D
The value of PBML becomes obvious when you stop talking about model classes and start looking at daily R&D decisions. Materials teams aren't asking for elegant architectures. They're asking which formulation to test next, which reactor condition to avoid, and whether a promising lab result will survive scale-up.
Polymer formulation and property prediction
Consider a formulation team developing a new polymer blend for mechanical performance under varying humidity and temperature. A pure ML model might fit the available test data, but if it hasn't seen enough edge cases, it can overpredict toughness or miss degradation behavior. A hybrid model is often a better fit.
The team can anchor the model with known physical relationships, then let machine learning learn the residual effects of morphology, additive interactions, or processing history. That's especially useful when the dataset is sparse and noisy. As described in Schrodinger's discussion of AI/ML and physics-based simulations, combining the two creates a bidirectional optimization loop in which physics improves generalizability in small-data settings, while AI speed helps bridge the limitations of traditional solvers. The same approach supports prediction of material properties and microstructural evolution from sparse and noisy datasets.
Faster screening instead of slower simulation queues
A second pattern shows up in specialty chemicals and advanced formulations. Teams often rely on expensive simulation workflows to evaluate candidate compositions or process settings. That's fine for deep analysis. It's bad for broad exploration.
A physics-aware surrogate model can stand in for the slow solver during early screening. Scientists can then use the expensive simulation only on the most promising candidates. In practice, that changes the cadence of development. Instead of waiting for model runs to finish before deciding the next batch of experiments, the team can evaluate many options, reject implausible regions of the design space, and reserve lab work for candidates worth the effort.
This same workflow logic also appears outside formulation design. Reliability teams use related AI frameworks to connect process behavior with equipment health, and resources on machine learning for predictive maintenance are useful when material performance and asset behavior start to interact in production environments.
Reactor modeling and process control
PINN-style approaches become attractive when the challenge is dynamic behavior rather than static property prediction. A polymerization reactor is a good example. Some state variables are measured directly. Others are latent or delayed. The governing physics matters, but the operating environment introduces enough complexity that a first-principles-only model struggles to stay current.
A PBML workflow can combine sensor data, known balances, and process constraints to estimate current state and forecast likely behavior under candidate control actions. That doesn't eliminate process engineering. It makes process engineering more responsive.
When the cost of a bad experiment is high, the best model is the one that narrows choices without violating the science.
For materials organizations, that's the true payoff. PBML helps teams make fewer blind bets.
Designing Experiments and Data for PBML
A polymer team has six weeks of reactor time left in the quarter, a backlog of candidate formulations, and pressure to explain why one batch drifted out of spec. That is usually the point where PBML either becomes useful or gets dismissed for the wrong reason. The deciding factor is rarely model architecture. It is whether the experiments were designed to expose the physics the model needs to learn.
Materials groups do not need a giant historical dataset to start. They need experiments that separate mechanisms, preserve process context, and map cleanly into the equations or constraints already trusted by the domain team. In practice, that means planning data collection around decisions the team needs to make. Which formulation should move forward, which process window looks unstable, and which variables deserve another round of lab work.
Smart data beats big data
For polymers, good PBML datasets usually have three properties: they cover the range where behavior changes, they include deliberate contrasts, and they carry enough metadata to reconstruct what really happened in the lab or pilot line.
- Coverage across mechanisms: Include runs near phase transitions, viscosity shifts, cure limits, thermal boundaries, or processing extremes. Staying inside the safe operating window produces tidy data but weak model discrimination.
- Contrast between experiments: Small changes around one baseline often fail to identify what drives the response. Purposeful variation in composition, temperature profile, residence time, shear, or catalyst level creates data the model can use.
- Metadata discipline: Record instrument settings, calibration state, batch lineage, operator context, environmental conditions, and sample handling. Missing metadata is one of the fastest ways to train on artifacts instead of material behavior.
Final properties alone are rarely enough. Intermediate measurements often carry more value for PBML because they connect outcomes to mechanism. In polymer work, that can mean cure profile, molecular weight evolution, torque, pressure history, thermal ramp, residence time distribution, or moisture exposure before testing.
Design experiments around what the physics does not already fix
This is the shift that matters for R&D teams. If the model already encodes mass balance, transport behavior, or known kinetics, repeating experiments that only confirm those relationships adds little value. The better use of lab capacity is to target the parts of the system the physics does not explain well yet.
That changes experiment planning from volume to resolution. The right question is not how many runs to add. The right question is which runs will identify uncertain parameters, expose residual behavior, or show where the mechanistic assumptions break down.
A practical screening table helps:
| Experimental choice | Why it matters for PBML |
|---|---|
| Boundary-condition runs | Tests whether predictions remain physically plausible at operating limits |
| Replicates at key points | Separates measurement noise from real process variation |
| Time-resolved measurements | Supports dynamic models and latent-state estimation |
| Controlled perturbations | Reveals sensitivity, hysteresis, and nonlinear response |
For enterprise teams, this also affects data system design. A PBML-ready experiment should be traceable across ELN, LIMS, process historian, and materials registry records. If formulation IDs, processing steps, and characterization outputs do not line up across systems, model training turns into manual cleanup work, and deployment slows down.
Data quality still decides the outcome
Physics constraints do not correct poor experimental practice. If incoming materials vary without being recorded, labels drift between systems, or assays shift over time, the model learns those errors along with the chemistry. In polymer programs, reagent quality and handling discipline often matter as much as model selection. Teams reviewing reproducibility issues should start with material inputs, and this piece on high-purity reagents for research makes that point well.
PBML is data-efficient, but it still depends on experimental discipline. Teams get the best results when they treat model development and experiment design as one workflow, not two separate handoffs.
Improving Interpretability and Quantifying Uncertainty
One reason scientists resist generic AI tools is simple. The model makes a recommendation, but nobody can tell whether it reflects chemistry, process behavior, or noise in the training data. In materials R&D, that's a serious problem because the point isn't just prediction. The point is deciding what to do next.
PBML has an advantage here because the model is grounded in known physical behavior. That doesn't make every output self-explanatory, but it makes the reasoning far easier to inspect than a black-box model trained only on correlations.
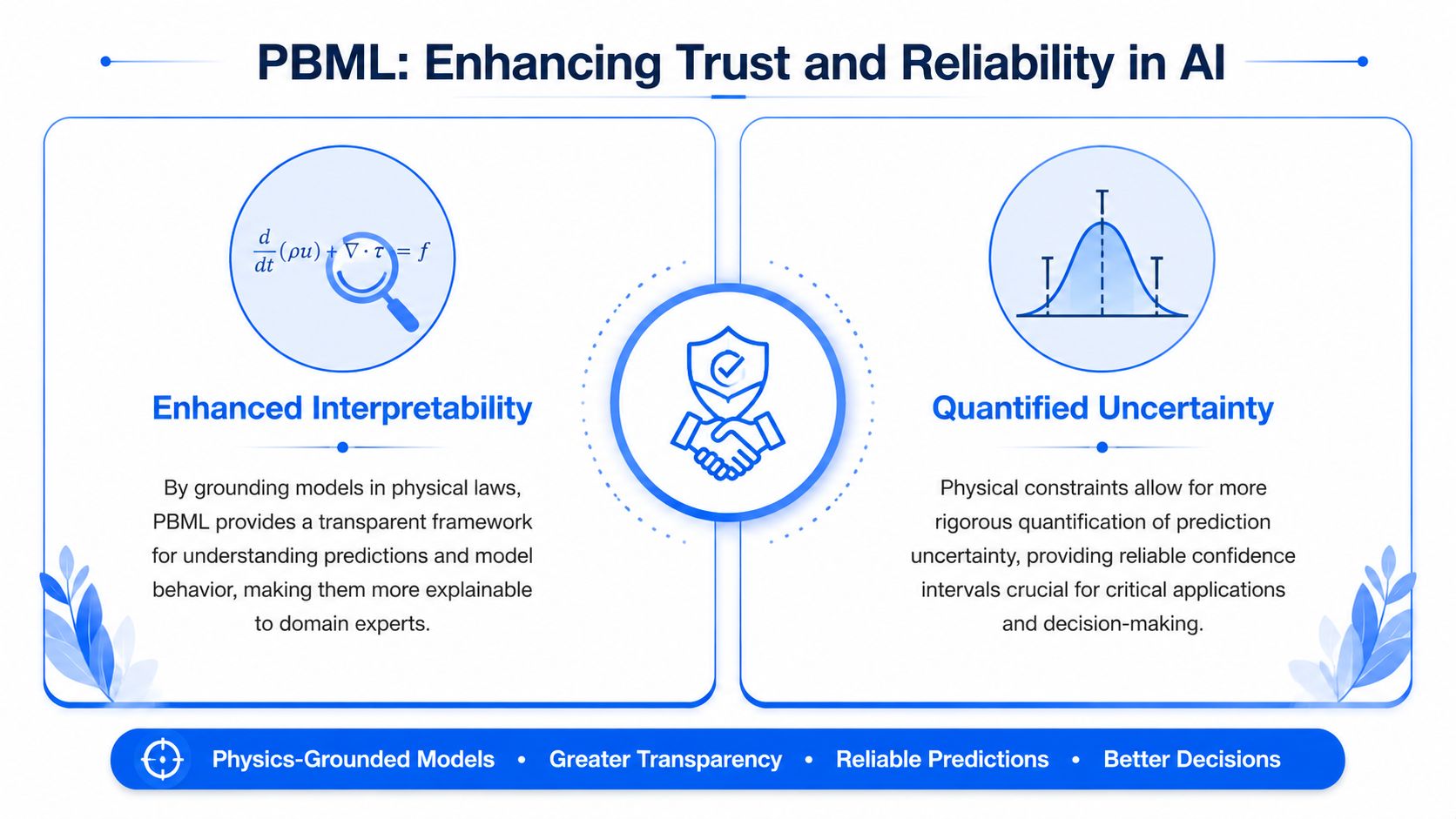
Why PBML is easier to trust
A physics-based model can be interrogated against what domain experts already know. If predicted trends violate conservation, symmetry, plausible kinetics, or expected process directionality, scientists catch it early. That shared frame of reference matters.
Interpretability in PBML usually comes from three places:
- Constraint visibility: Teams can see which physical rules the model is expected to obey.
- Residual analysis: Scientists can inspect where the learned component departs from the mechanistic component.
- Domain alignment: Explanations are framed in familiar variables such as temperature, pressure, conversion, morphology, or diffusion behavior.
A model becomes useful when a scientist can disagree with it for a specific reason.
That's a better standard than generic explainability dashboards that highlight variables without showing whether the output respects the system itself.
Uncertainty is part of the decision, not an afterthought
In materials development, uncertainty matters most when choosing the next experiment. If the model predicts a formulation will perform well but confidence is low, the recommendation should be treated differently than a similarly strong prediction with high confidence.
PBML supports stronger uncertainty reasoning because physical constraints narrow the space of plausible outputs. That gives teams a more disciplined way to distinguish between three situations:
- The model is confident and physically consistent. This is a candidate for action.
- The model is uncertain but physically plausible. This is a candidate for targeted experimentation.
- The model is physically inconsistent or unstable. This is a candidate for rejection or retraining.
What teams should actually review
Before operationalizing a PBML model, review more than aggregate fit.
- Check physical consistency: Are predictions violating known boundaries or conservation behavior?
- Inspect uncertainty by regime: Is confidence lower in sparse regions, unusual feedstocks, or scale-up conditions?
- Stress-test extrapolation: What happens when the model sees conditions just outside the training range?
The practical goal isn't certainty. It's controlled risk. PBML earns trust when teams can see both what the model predicts and how much confidence to place in acting on it.
Deploying PBML in Your Enterprise R&D Workflow
Most PBML initiatives fail for operational reasons, not modeling reasons. The science may be solid, but the workflow is fragmented. Data lives in ELNs, LIMS exports, instrument files, PowerPoints, and personal spreadsheets. Model ownership is unclear. Domain experts and data scientists work on parallel tracks instead of the same decision process.
A useful deployment plan starts small and stays close to the actual work.
Start with a pilot that matters
Choose one problem where three conditions are true. The physics matters, data exists but is limited, and the business impact of faster decisions is obvious. Good pilot candidates include formulation-property prediction, reactor-state estimation, process optimization, or simulation acceleration for candidate screening.
Don't begin with the hardest problem in the organization. Begin with a bounded one where scientists can tell whether the model is behaving sensibly.
A good pilot definition includes:
- A specific decision point: For example, ranking formulations, estimating hidden process states, or selecting the next experiment.
- Known physics inputs: Constraints, equations, balances, or boundary conditions the team trusts.
- Operational success criteria: Not vanity metrics. Use measures tied to cycle time, experiment selection quality, or handoff efficiency.
Build the data backbone before scaling models
PBML depends on connected context, not just a modeling notebook. That means linking formulation compositions, process conditions, analytical outputs, simulation results, and sample lineage into a single usable structure.
In practice, enterprise teams should prioritize:
| Workflow need | What to implement |
|---|---|
| Data unification | Connect ELNs, LIMS, spreadsheets, and simulation outputs |
| Version control | Track model versions, data snapshots, and experimental assumptions |
| Human review | Keep scientist signoff in the loop for edge cases and new regimes |
Pair domain experts with model builders
The strongest PBML deployments aren't handed off from one team to another. They're co-developed. Process engineers define the constraints. formulation scientists explain failure modes. Data scientists translate that knowledge into model structure and training logic.
That collaboration also affects maintenance. Physics doesn't change often, but processes, feedstocks, instruments, and operating windows do. Someone has to own model updates when the physical system shifts.
The deployment question isn't “Can we build a model?” It's “Can scientists use it inside the way decisions already get made?”
That's the standard worth holding. If the output can't fit into experiment planning, technical review, and scale-up decisions, the model won't survive beyond the pilot.
Polymerize helps materials teams operationalize this kind of workflow with an AI-native system built for polymers, chemicals, and advanced materials. It connects fragmented R&D data, supports explainable domain-specific modeling, and helps scientists plan better experiments with confidence. If you're evaluating how to bring physics based machine learning into a real enterprise environment, Polymerize is a strong place to start.

