You're probably dealing with some version of the same problem I see in many materials R&D organizations. FTIR data lives in one instrument folder. Rheology results sit in a scientist's spreadsheet. Formulation history is buried in ELN entries that nobody searches unless something goes wrong. Scale-up notes exist in slide decks, emails, or paper binders near the pilot line. When a team needs to explain why batch 17 worked and batch 23 failed, they don't have a data model. They have an archaeological dig.
That fragmentation slows far more than reporting. It weakens experiment design, makes handoffs brittle, and turns routine questions into multi-day hunts across shared drives and disconnected software. In materials science, where formulation context matters as much as the final result, missing metadata is often more damaging than missing files. The outcome is familiar. Repeated experiments, delayed root-cause analysis, slow movement from bench to plant, and AI initiatives that stall because the raw data isn't usable.
Table of Contents
- Instrument integration that removes manual handling
- Deep integration with ELN, LIMS, and business systems
- Metadata and version control that preserve meaning
- Collaboration that doesn't lose traceability
- Why traditional informatics often falls short
- What an AI-ready backbone actually requires
- Why this changes experiment planning
- A better way to think about AI in the lab
- Start where the pain is obvious
- Measure outcomes that matter to the CTO
- Why phased rollout beats big-bang deployment
- What actually drives returns
The Data Bottleneck in Materials R&D
A polymer team develops a promising formulation. One scientist has the raw characterization output. Another has the processing conditions in an ELN. A process engineer has extrusion notes from a pilot run. QA has a separate record of deviations. Nobody disputes that the information exists. The problem is that it doesn't exist in one usable system.
That is the fundamental bottleneck in materials R&D. It isn't a lack of experiments. It's a lack of connected experimental memory.
When labs run this way, three problems keep repeating:
- Teams repeat work: Scientists can't easily find prior formulations, failed conditions, or negative results.
- Scale-up slows down: Process engineers inherit incomplete context, not a full data trail from lab to production.
- Digital programs underperform: Analytics and AI efforts start before the data backbone is ready.
Data fragmentation looks like an operations issue, but in practice it becomes a portfolio issue. Programs move slower because the organization can't learn from itself fast enough.
This is one reason spending on lab informatics keeps rising. The lab data management software market was valued at USD 2.8 billion in 2024 and is projected to reach as high as USD 5.8 billion by 2033, with growth tied to the need to solve data fragmentation as a competitive disadvantage, according to lab data management software market projections from MicroMarket Insights.
Why materials teams feel this pain earlier
Materials R&D creates especially messy data environments because the work spans structured and unstructured records at the same time. A sample ID might be cleanly tracked, but the reasoning behind the formulation, the processing nuance, or the observed anomaly often lives in free text, attachments, and local files.
A biology lab can sometimes standardize around narrower workflows. A materials lab usually can't. It has to connect chemistry, process conditions, characterization data, supplier inputs, and manufacturing constraints.
What failure looks like in practice
The signs are usually obvious long before leadership names the problem:
- Search depends on people: The fastest way to find data is still asking the scientist who ran the work.
- Reports are stitched together manually: Teams export, copy, relabel, and reconcile before each review.
- Historical comparison is weak: Scientists can view results, but not reliably compare formulation lineage across projects.
At that point, lab data management software stops being a nice-to-have system upgrade. It becomes infrastructure.
What is Lab Data Management Software?
Lab data management software is the system that turns disconnected lab records into a usable operating layer for R&D. The simplest way to think about it is this. If LIMS manages sample and workflow control, and an ELN records what scientists did, lab data management software acts as the central nervous system that connects those pieces with instruments, metadata, analytics, and downstream teams.
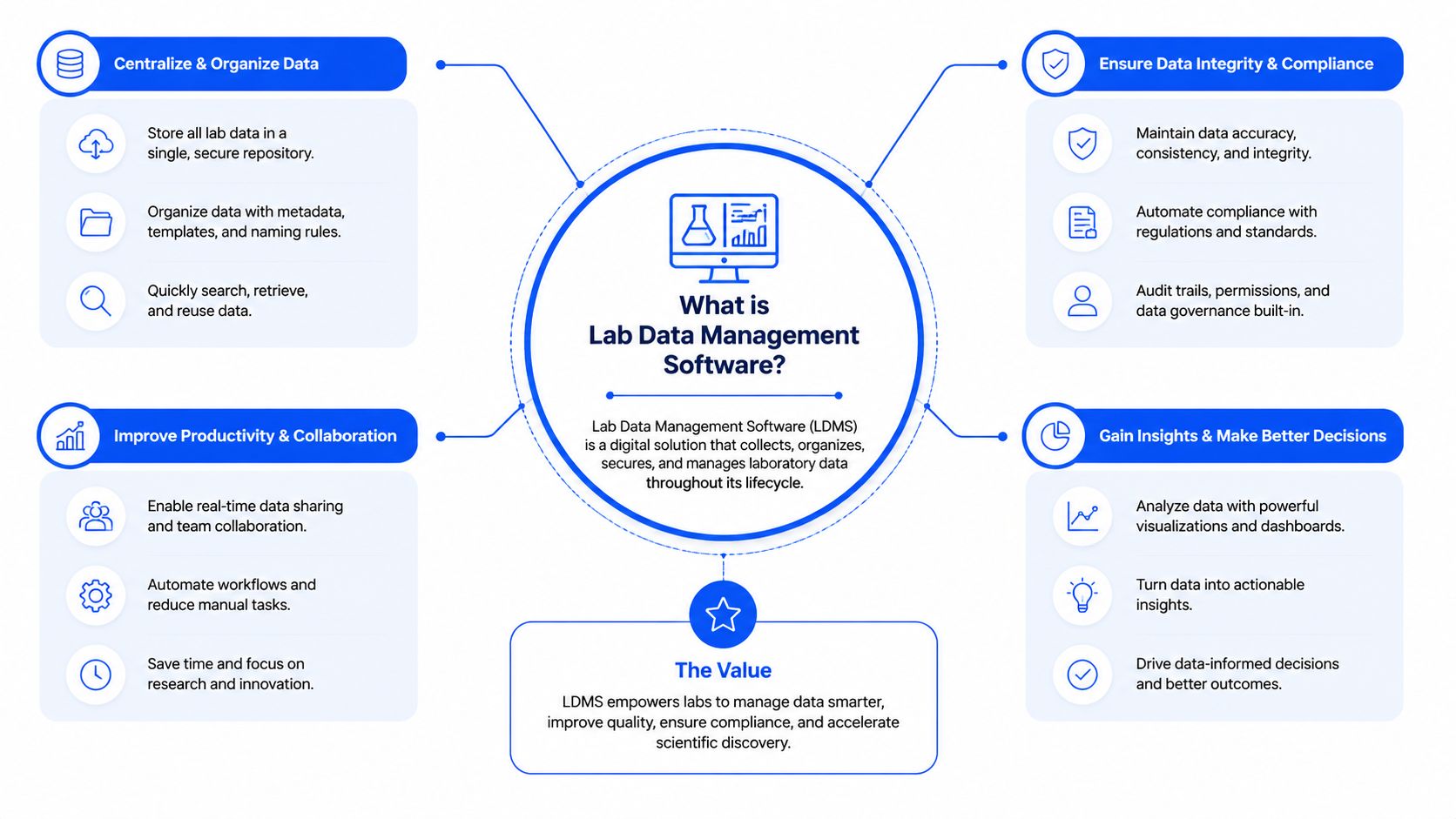
A lot of buying mistakes happen because teams treat this as just another repository. It isn't. A repository stores files. A real data backbone preserves context, relationships, version history, traceability, and access rules across the full R&D process.
It's more than a traditional LIMS
Traditional LIMS platforms are useful, but many were built around sample tracking, workflow enforcement, and compliance. That's valuable in QC and regulated workflows. It's often not enough for materials discovery, formulation work, or process development where much of the insight lives outside rigid sample schemas.
An ELN helps with experiment documentation, but ELNs often stop at recordkeeping. They don't always create a durable, queryable system across instruments, historical formulations, and process transfer.
What modern lab data management software does well is unify all three layers:
- Operational layer: Samples, workflows, approvals, and status tracking
- Scientific layer: Experimental records, observations, attachments, and interpretation
- Intelligence layer: Search, analytics, model-ready datasets, and cross-project learning
What good software changes
When the system is designed properly, scientists don't need to wonder where the “real” record lives. Data from instruments, ELNs, and process tools lands in one governed environment. Formulation history becomes searchable. Handoffs stop depending on heroic memory.
Practical rule: If a platform can't show the relationship between raw instrument output, experimental context, and decision history, it's a storage tool, not a lab data backbone.
That distinction matters to CTOs because software choices made for today's recordkeeping shape what the organization can do two years from now. A lab can tolerate disconnected tools for a while. It can't build reliable AI, scale knowledge across sites, or protect process learning effectively on top of disconnected tools.
The standard to aim for
For materials R&D, the right target isn't “digital lab software.” It's a system of intelligence that makes every experiment easier to find, trust, compare, and reuse.
That's why the software category matters less than the architecture behind it. The winning platforms don't just digitize paperwork. They create a common data language across the lab.
Unifying Your Lab with Core Capabilities
The strongest platforms don't win because they have the longest feature list. They win because they reduce friction in the exact places where labs lose time and data fidelity.

Instrument integration that removes manual handling
In materials labs, instrument data is where fragmentation usually begins. GPC/SEC systems, FTIR spectrometers, rheometers, balances, thermal analyzers, and particle characterization tools all generate outputs in different formats and naming conventions. If scientists still export files, rename them, and attach them manually, errors are inevitable.
Integrated instrument connectivity via open APIs and IoT connectors can reduce manual data entry errors by up to 90%, with some labs reporting a 40 to 60% reduction in data transcription time, according to instrument integration benchmarks from QI-A.
That gain matters for two reasons. First, it improves speed. Second, it improves trust. A rheology curve captured directly from the instrument carries a more defensible chain of custody than a value retyped into a spreadsheet.
Deep integration with ELN, LIMS, and business systems
A standalone platform creates one more silo. A useful platform connects to what your lab already uses.
The integrations that matter most usually include:
- ELN connectivity: Experimental narrative, procedures, and attachments stay linked to analytical results.
- LIMS interoperability: Sample identity, workflow state, and test status remain consistent across systems.
- ERP or MES links: Material codes, batch references, and manufacturing handoff data stay aligned.
Many software evaluations falter at this stage. Vendors showcase polished dashboards but fail to explain how bidirectional synchronization functions when records change across multiple systems. That creates reconciliation work later.
If integration depends on CSV exports and nightly manual checks, the architecture isn't mature enough for a multi-site R&D operation.
Metadata and version control that preserve meaning
Raw results without context aren't very useful in formulation science. A tensile value means little unless it remains linked to resin grade, additive package, drying conditions, processing window, operator notes, and test protocol.
That's why strong lab data management software needs disciplined metadata handling. Not excessive form fields. The right metadata captured automatically, inherited where possible, and governed consistently.
Three capabilities matter here:
- Automated tagging for formulation variables, material classes, and test conditions
- Version history for recipe iterations, calculation updates, and revised interpretations
- Lineage tracking that shows how a result connects to prior experiments and later scale-up work
Collaboration that doesn't lose traceability
Labs often try to solve collaboration with shared folders, email, and presentation decks. That works for conversation, not for traceable decision-making.
A better setup gives formulation scientists, analytical teams, and process engineers access to the same governed record while preserving role-based views. Scientists can collaborate freely without creating parallel “working copies” of the truth.
Some teams also need purpose-built materials platforms rather than general lab systems. Polymerize is one example in this category. It's designed to unify fragmented experimental data across spreadsheets, ELNs, and other lab sources into a centralized data backbone for materials R&D. That kind of domain fit matters when polymer properties, processing conditions, and formulation history need to stay connected instead of being stored as generic files.
Building an AI-Ready Data Foundation
Most lab AI projects don't fail because the models are weak. They fail because the underlying data is inconsistent, incomplete, and trapped in formats that machines can't interpret reliably.
That matters even more in materials R&D, where a large share of the useful information sits in spreadsheets, attachments, comments, characterization files, and semi-structured experiment notes. You can't build good prediction on top of bad context.

Why traditional informatics often falls short
Many organizations assume their current LIMS is already an AI foundation. Usually it isn't. Traditional systems can be strong at sample control and compliance, but weaker at handling the messy reality of formulation science. They often struggle to normalize free text, connect spreadsheet logic, preserve experimental nuance, or model relationships across chemistry, process, and performance data.
The practical problem isn't just storage. It's representation.
If polymer formulation data is spread across separate tables, attached PDFs, and disconnected notebooks, a model won't understand which variables mattered, which conditions changed, or which failures were informative.
What an AI-ready backbone actually requires
An AI-ready data foundation has four characteristics:
- Centralization: Data from instruments, ELNs, spreadsheets, and business systems lands in one governed environment.
- Standardization: Property names, units, test methods, and formulation variables follow consistent structures.
- Context preservation: Raw values stay connected to experiment intent, processing conditions, and decisions.
- Interoperability: Data can move cleanly into analytics and ML workflows without heroic cleanup.
Many CTOs need to be stricter than their vendors in this regard. “AI-enabled” means very little if the platform can't unify historical records and create clean training data.
The first AI milestone in a lab isn't prediction. It's getting past the point where every modeling effort starts with manual data rescue.
Why this changes experiment planning
Once the backbone is in place, the value goes beyond dashboards. Teams can start using historical data to support property prediction, formulation optimization, and causal analysis. Instead of asking only “What happened?”, they can ask “What should we try next?” and “What variables most likely drove this outcome?”
That shift is no longer theoretical. While 80 to 90% of lab data in materials science is unstructured, AI-powered platforms that unify this data are reporting up to 50% fewer failed experiments by enabling ML-driven experiment planning, according to Instem's discussion of modern LIMS and strategic data benefits.
A better way to think about AI in the lab
The most useful AI in materials development isn't magic. It's disciplined pattern recognition built on well-structured scientific history.
For a CTO, that means software selection should be judged partly on future model readiness. Can the system map raw spectra to material lots, process parameters, and final performance? Can it expose negative results, not just successful runs? Can it preserve enough context that a prediction is explainable to a scientist, not just statistically convenient?
If the answer is no, the lab may still digitize. It won't become AI-ready.
Ensuring Security and Regulatory Compliance
A centralized data backbone creates a speed advantage, but it also changes your risk posture. In chemicals and advanced materials, experimental history, formulation logic, and scale-up knowledge are all forms of intellectual property. If that information is scattered across laptops, email threads, and unmanaged file shares, access control is weak by design.
Security in lab data management software starts with containment. The platform should define who can view, edit, export, approve, and share each class of information. That usually means role-based access control, project-level segregation, and auditable permissions that can survive staff changes and cross-site collaboration.
Security controls that matter in practice
The most useful controls are usually not the flashy ones. They are the boring controls that hold up during audits, investigations, and partner disputes.
- Audit trails: Every change, approval, and data movement should be traceable.
- Access governance: Scientists should see what they need, not everything the organization knows.
- Controlled sharing: External collaboration should happen through governed workflows, not ad hoc exports.
- Retention and recovery: The system should preserve historical integrity and support business continuity.
For teams reviewing cloud platforms, compliance language also needs scrutiny. Certifications don't replace architecture, but they do establish a baseline for operational discipline. If your internal stakeholders need a plain-English primer before procurement gets too deep, the SOC2Auditors security compliance resources are a useful starting point for understanding what SOC 2 covers and what it doesn't.
Compliance is also a data quality issue
Labs often separate compliance from scientific usability. That's a mistake. A strong compliance posture improves data quality because the same controls that protect IP also preserve provenance, traceability, and record integrity.
For companies in chemicals R&D, adopting cloud-based lab management software with ISO 27001 and SOC 2 compliance can reduce intellectual property risks by as much as 60%, according to QBench's analysis of lab management software and secure cloud adoption.
That's the business case in simple terms. Centralization doesn't just help people work faster. It gives leadership one place to enforce policy, monitor activity, and prove the integrity of the scientific record.
Compliance works best when scientists barely notice it. The system should make the right behavior the default behavior.
How to Evaluate and Select the Right Platform
Most software evaluations fail before the demo starts. The team builds a checklist of features, sends an RFP, and compares screenshots. That approach tends to reward presentation quality, not long-term fit.
A better evaluation starts with your operating model. What data do you produce, who uses it, where does it need to flow next, and what future state are you building toward? In materials R&D, that usually means choosing for interoperability and scale, not just current workflow comfort.
The questions worth asking vendors
Use the product demo to pressure-test architecture, not polish. Ask vendors to show how the platform behaves with your messiest workflows, not their cleanest templates.
| Criterion | What to Ask | Why It Matters |
|---|---|---|
| Interoperability | Can it connect to our instruments, ELN, LIMS, ERP, and analytics tools without custom one-off work? | A disconnected platform creates another silo. |
| Data model fit | Can it represent formulations, process conditions, analytical results, and iterative experiment history in a way scientists can actually use? | Generic schemas often flatten critical materials context. |
| Scalability | How does it handle growth in users, sites, file volumes, and experiment complexity? | The system should survive expansion without redesign. |
| Deployment model | What are the trade-offs between cloud, on-premise, and hybrid for our governance and IT environment? | Architecture choices affect speed, security review, and maintenance load. |
| Search and traceability | Can users find prior experiments, failed runs, and related records without knowing where they were originally stored? | Reuse depends on discoverability, not just storage. |
| AI readiness | How does the platform structure unstructured data and expose it for modeling or advanced analytics? | If this is weak, future AI work will still require manual cleanup. |
| Vendor domain expertise | Do they understand materials workflows such as formulation iteration, characterization, and scale-up handoff? | Domain mismatch creates expensive customization. |
| Portability | How do we extract our data, metadata, and relationships if we change systems later? | This is your protection against vendor lock-in. |
What to watch out for
There are a few recurring traps in this market.
- Over-customization early: If the vendor wants to rebuild your lab in software before launch, timelines will slip and adoption will suffer.
- Weak integration stories: “We support import/export” is not the same as robust interoperability.
- Science-light implementations: If the implementation team doesn't understand formulations or characterization workflows, they'll model the wrong things.
- AI theater: A dashboard with model language isn't the same as a system that creates AI-ready data.
Buy for the data architecture you need in three years, not just the forms you need next quarter.
A practical selection process
The best evaluations I've seen follow a simple sequence:
- Map the current flow of data across instruments, notebooks, spreadsheets, and downstream systems.
- Prioritize one or two critical workflows such as formulation screening or lab-to-pilot transfer.
- Run vendor scenarios using your real data rather than a generic sample dataset.
- Check extraction and migration paths before legal review, not after.
- Score implementation fit as seriously as product capability.
A platform that looks slightly less polished but fits your lab architecture is usually the better choice.
Driving ROI Through Strategic Implementation
The common assumption is that software implementation is an IT project with some training attached. In lab environments, that assumption causes a lot of disappointment. The technical deployment may succeed while the operational rollout fails.
Scientists don't adopt new systems because leadership says the tool is strategic. They adopt them when the system removes work, preserves scientific nuance, and helps them make better decisions. That means ROI depends as much on rollout design as on software capability.
Start where the pain is obvious
The most effective implementations don't begin with enterprise-wide standardization. They begin with one workflow where the current state is clearly broken and the benefit is easy to measure.
Good candidates include:
- Formulation iteration tracking where historical comparison is difficult
- Instrument-heavy analytical workflows with too much manual data handling
- Lab-to-pilot handoff where process context is routinely lost
Choose a workflow that touches real business outcomes, not just administrative cleanup. That gives you an adoption story the R&D organization will sincerely respect.
Measure outcomes that matter to the CTO
If you want credibility, track operational and strategic indicators together. Don't stop at login rates or training completion.
Useful implementation metrics often include:
- Reduction in repeated experiments
- Time required to assemble technical review packages
- Speed of root-cause investigation
- Quality of lab-to-production handoff
- Use of historical data in new experiment planning
You should also distinguish between software usage and organizational learning. A lab can be active in the system and still not improve decisions if metadata quality, workflow design, or incentives are weak.
The fastest way to lose support is to promise transformation and report only adoption metrics.
Why phased rollout beats big-bang deployment
A phased approach usually works better because it lets the lab prove value while tightening standards incrementally. First unify data. Then improve metadata discipline. Then expose analytics and modeling layers. Teams that try to do all of this at once often create resistance, especially when scientists feel they are being asked to structure data for a future benefit they can't yet see.
This matters financially too. As noted earlier, traditional ROI timelines can be long. Traditional LIMS can take 9 to 18 months to show ROI, while modern hybrid AI-LIMS solutions can deliver measurable returns in as little as 3 months, often by enabling up to 40% faster scale-up from lab to production. That timing difference is part of the same business context discussed earlier in relation to secure cloud adoption and implementation trade-offs.
What actually drives returns
ROI in lab data management software typically comes from a mix of operational improvements:
- Less manual reconciliation between systems and files
- Fewer failed or repeated experiments because prior knowledge is easier to reuse
- Faster technical transfer into pilot and manufacturing environments
- Better portfolio decisions because leadership sees program quality earlier
The systems that create value fastest are usually the ones introduced with clear governance and clear scientist benefit. The ones that stall are often framed as infrastructure first and workflow relief second.
A CTO should treat implementation as a change program with technical components, not the other way around.
If your team is trying to move beyond fragmented spreadsheets and disconnected lab records, Polymerize is worth evaluating as a materials R&D data backbone. It's built to unify experimental data across silos, create an AI-ready foundation for formulation and property prediction work, and support the path from discovery to scale-up without forcing teams to bolt together multiple disconnected systems.
Enhanced by Outrank

