A lot of enterprise labs are in the same place right now. Sample records live in one system, formulations sit in spreadsheets, instrument outputs land in shared folders, and the only person who understands the naming logic is the scientist who built it three years ago. When R&D leaders ask for a clean view of what was tested, why it failed, and what should happen next, teams spend more time reconstructing history than advancing a program.
That's why a cloud based lims system has moved from IT discussion to R&D strategy. This isn't only about replacing servers with subscriptions. It's about turning fragmented laboratory activity into a controlled system of record that scientists, quality teams, and digital teams can readily use.
The market shift confirms that this is no longer an early-adopter move. Grand View Research reports that the cloud-based segment held the largest revenue share of over 43.50% in 2025, making cloud the leading LIMS deployment model in the industry according to Grand View Research's LIMS market analysis. For materials organizations, that matters because the underlying problem isn't just sample tracking. It's getting polymer, chemical, and formulation data into a form that supports traceability today and analytics tomorrow.
Table of Contents
- The Modern R&D Challenge Driving Cloud Adoption
- What Is a Cloud Based LIMS System in Practice
- Integration has to include the messy middle
- Control matters more than feature breadth
The Modern R&D Challenge Driving Cloud Adoption
Materials R&D rarely breaks because scientists lack ideas. It breaks because data is hard to trust, hard to find, and hard to compare. A formulation chemist may have the raw results. A process engineer may have the scale-up notes. Quality may hold the approved method. Informatics may have a LIMS that tracks samples but not the full experimental context.
That fragmentation creates a practical bottleneck. Teams can't confidently answer simple but expensive questions. Which resin batches were tested under comparable conditions. Which dispersant change improved stability. Which historical experiments are reusable instead of repeated.
In enterprise settings, the problem gets worse as programs spread across sites. One lab uses local naming conventions. Another exports CSV files from instruments into a shared drive. A third tracks exceptions by email. You still have data, but you don't have a reliable operating model for it.
A lab doesn't become digital because it owns more software. It becomes digital when teams can trace a result back to method, material, operator, instrument, and decision without detective work.
A cloud based lims system addresses that operational gap because it changes where data lives and how teams access it. Instead of each site maintaining its own partial record, labs work in a shared environment built around common workflows, permissions, and auditability.
That's one reason cloud deployment has become the industry default direction rather than a side option. In practice, the attraction is simple:
- Shared access across sites: Scientists, lab managers, and quality teams work from the same controlled record.
- Centralized updates: IT doesn't have to rebuild local environments every time the platform changes.
- Faster standardization: Global templates, methods, and controlled vocabularies become easier to enforce.
- Better readiness for analytics: Structured records are easier to use for dashboards, trend analysis, and later-stage AI work.
For enterprise materials science, the primary driver isn't fashion. It's the need to stop running high-value R&D on disconnected infrastructure.
What Is a Cloud Based LIMS System in Practice
Monday morning, a formulation team in one region is waiting on particle size data generated overnight in another. Quality wants the approved method version. Program management wants to know whether the latest batch used the current raw material spec or an older one. If those answers still depend on shared drives, emailed attachments, and local admin knowledge, the lab has software, but it does not have a dependable operating system for R&D.
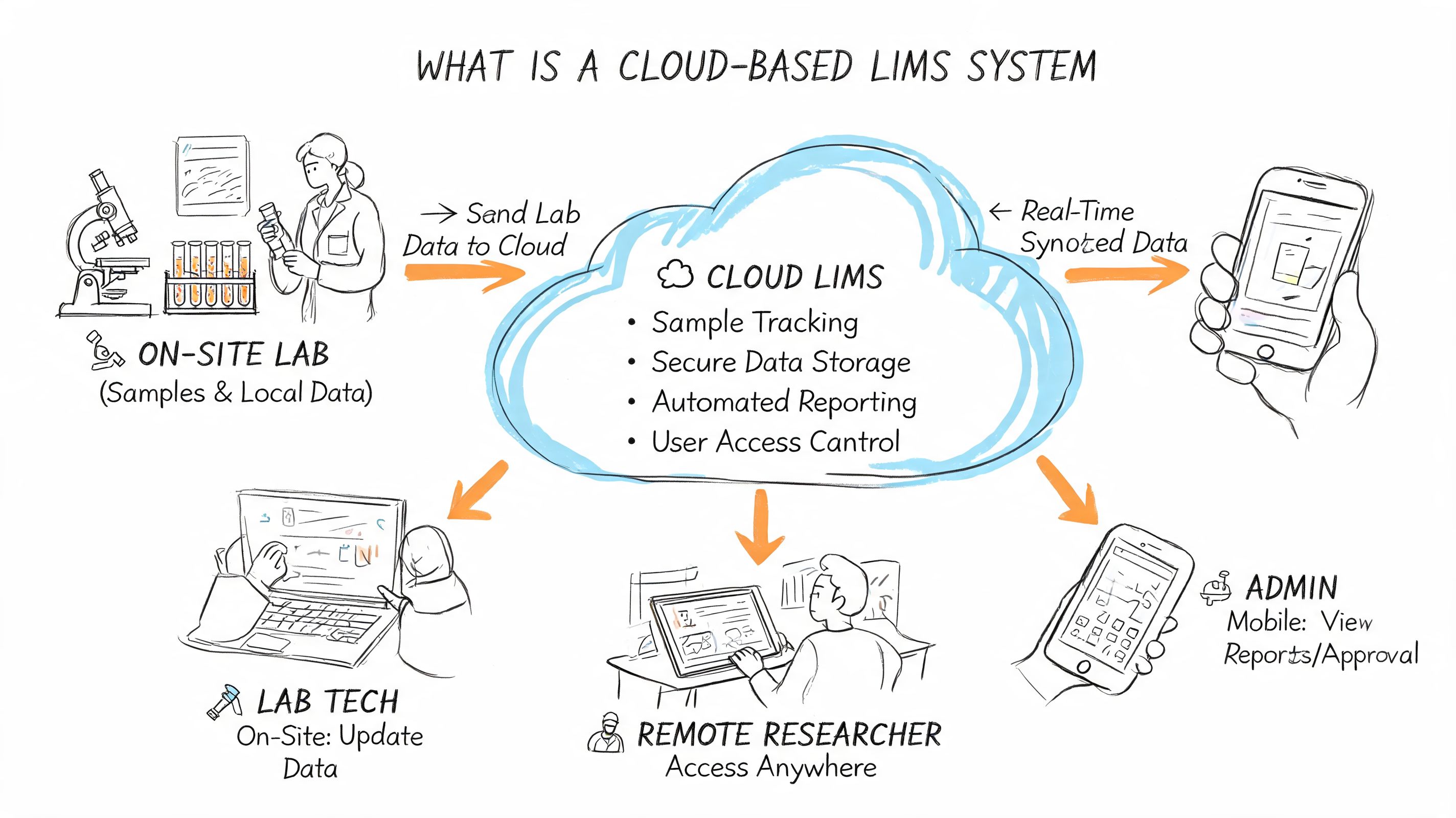
A cloud based lims system puts that operating model into one controlled environment. It manages sample intake, method assignment, result capture, review, approval, permissions, and audit history in a system users reach through the browser rather than through site-by-site installs. The hosting model matters, but the bigger shift is operational. The lab moves from fragmented records to a shared process with one version of the truth.
For enterprise materials organizations, that distinction matters because the work is rarely linear. A single result may depend on formulation version, precursor lot, processing conditions, instrument settings, analyst comments, and later interpretation by another team. If those pieces live in separate tools, traceability breaks at exactly the point where program risk and IP value are highest.
In practice, a cloud LIMS should serve as the system of record for:
- Sample and batch registration with controlled identifiers and metadata
- Method execution records tied to the procedure used
- Result capture from analysts, instruments, and connected applications
- Review and approval workflows with role-based accountability
- Traceability across sites, projects, and product development stages
The broader cloud architecture also matters in this context. If you want a useful non-lab analogy, Pratt Solutions technical consulting insights explain the practical trade-off well: centralized access and reduced infrastructure management in exchange for greater discipline around configuration, integration, and governance. That is a fair description of cloud LIMS reality too.
The hard part is not buying access to hosted software. The hard part is deciding what data model the enterprise will live with. I have seen migrations stall because teams tried to bring every legacy field, every local code, and every historical exception into the new platform. That usually creates an expensive replica of old problems. A better approach is to separate data you must preserve for traceability from data you should redesign for future use, then validate the new workflows against real lab scenarios rather than vendor demo scripts.
A cloud based lims system also does not become modern just because it runs in someone else's environment. Some products are still older on-premise applications with hosted infrastructure wrapped around them. The warning signs are familiar: difficult upgrades, weak APIs, customizations that break easily, and routine work that still falls back to spreadsheets.
Practical rule: If scientists still need side files to understand what happened, the LIMS is not functioning as the system of record.
The business question is more concrete than “is it cloud?” Ask whether the platform can support standardized execution, cleaner migration, and defensible validation without driving hidden costs into integration work, support effort, and workarounds. That is what a cloud based lims system looks like in practice.
Core Capabilities for an Enterprise Materials Lab
A materials lab feels enterprise-scale long before the org chart says it is. One site qualifies incoming raw materials, another runs characterization, a third owns customer-specific methods, and all three need to trust the same record. If the LIMS cannot hold that together without side spreadsheets, local naming conventions, and manual status chasing, adoption breaks down fast.
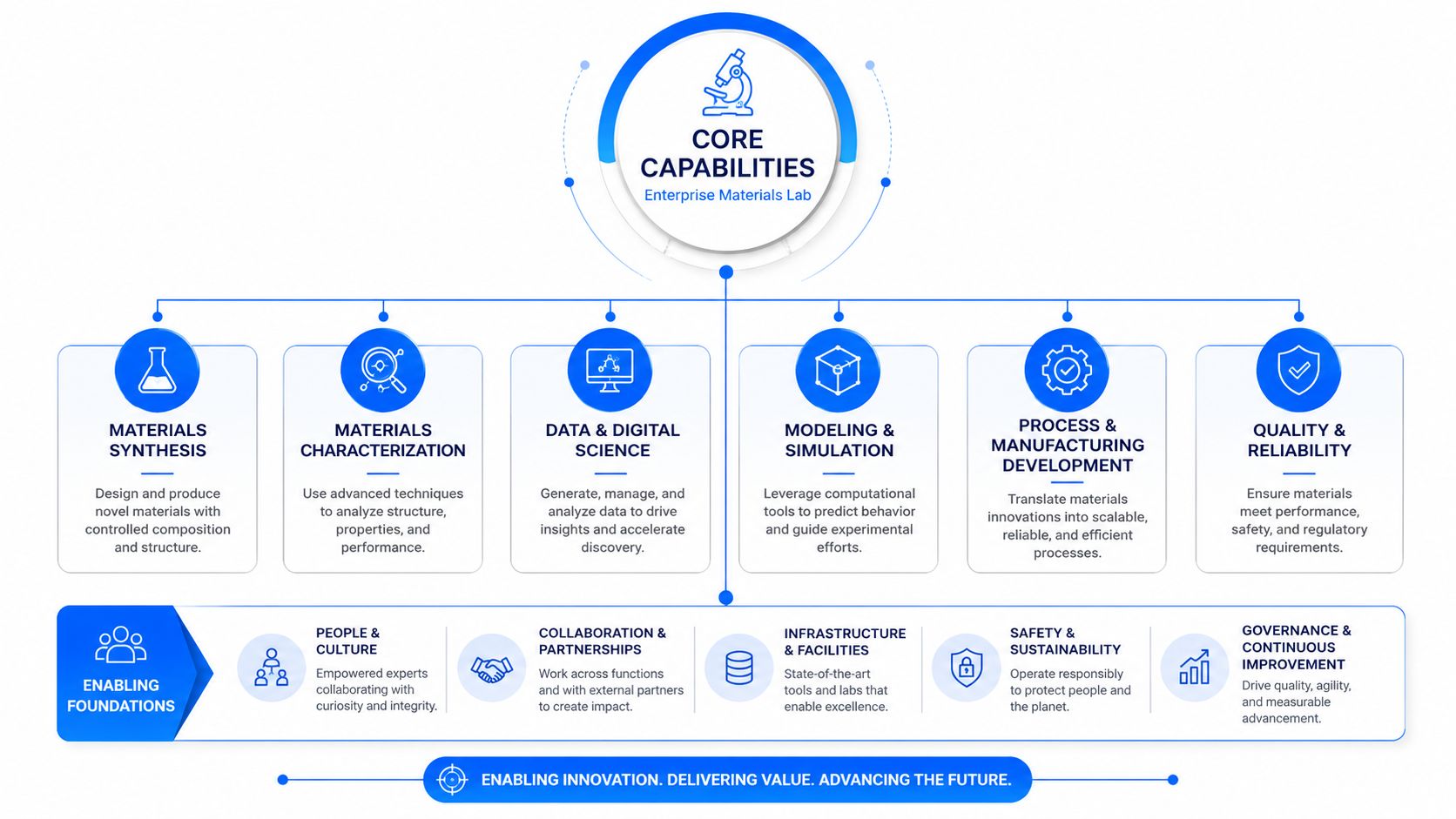
Integration has to include the messy middle
For enterprise materials R&D, the first test is whether the platform can handle imperfect reality. Instruments matter, but the larger failure point is usually between systems: ELN records that do not match LIMS sample IDs, ERP material codes that changed after an acquisition, method names that differ by site, and historical results stored in formats no one wants to defend during validation.
A capable cloud based lims system needs to support those handoffs cleanly. That means usable APIs, instrument ingestion options, event-driven workflow, and controls for master data. It also means enough configuration discipline to stop every local exception from becoming permanent architecture.
Look for:
- API-first design: Data should move in and out without custom rescue work every time a workflow changes.
- Instrument ingestion options: File watchers, parser support, and middleware compatibility matter more than polished screenshots.
- Event handling: Status changes should trigger review, approval, exception handling, or notification steps automatically.
- Master data governance: Units, material identifiers, methods, specifications, and revision history need controlled ownership.
Migration pressure shows up here too. If a vendor cannot explain how legacy sample types, retired test methods, and incomplete metadata will be handled, the integration story is not mature enough for enterprise use.
Control matters more than feature breadth
Security and role-based access need deliberate design. In materials R&D, the issue is not only user administration. It is protection of formulations, customer-linked programs, proprietary methods, and region-specific access rules without slowing down legitimate collaboration.
Auditability follows the same pattern. Labs need attributable records for method changes, result edits, approvals, retests, and exceptions. Validation teams also need confidence that those records are consistent across sites and releases, because weak traceability turns every investigation into reconstruction work.
Another capability gets underestimated. The system has to preserve experiment context, not just sample status. Materials organizations often split operational records in the LIMS and scientific reasoning somewhere else. That might work for basic tracking, but it creates expensive gaps when teams try to compare formulations, explain unexpected performance, or prepare data for modeling.
A practical enterprise checklist looks like this:
| Capability | Why it matters in materials R&D |
|---|---|
| Integration backbone | Prevents duplicate entry, conflicting identifiers, and isolated records |
| Role-based permissions | Protects formulas, customer data, and program access |
| Audit trails | Supports investigations, validation, compliance, and review |
| Workflow configurability | Fits real methods without custom code for every procedural change |
| ELN adjacency or connectivity | Links sample records to experimental reasoning and decision context |
If analysts trust the instrument interface but scientists still keep the real experiment logic in spreadsheets, the lab has digitized administration, not R&D.
A useful vendor test is a cross-functional walkthrough based on an actual materials program. Ask them to show a raw material lot entering the system, a formulation being prepared, an analytical result arriving, an out-of-spec event being reviewed, and the final dataset being exported for analysis. Then ask what happens when names do not match, metadata is missing, or an old method version has to stay visible for traceability. Those answers tell you far more than a feature checklist.
Platform scope also matters in this context. Some organizations keep LIMS, ELN, and analytics as separate layers and accept the integration overhead. Others choose a broader R&D data environment to reduce handoffs and validation complexity. For example, Polymerize provides a cloud platform that combines LIMS, ELN, and data management capabilities for materials workflows. That model can make sense when the business goal is not only control, but also cleaner downstream data for statistical analysis and AI use.
SaaS vs Private Cloud What Is Right for Your Lab
A global materials team approves a new cloud LIMS, then stalls for six months on one question: who owns the risk after go-live? The subscription price is easy to compare. The harder decision is whether the organization can live with vendor-controlled releases, shared validation duties, and standard operating patterns, or whether it needs tighter infrastructure control and is prepared to pay for it in people, process, and delay.
That is the fundamental SaaS versus private cloud decision in enterprise R&D.
Where SaaS usually fits best
SaaS is usually the better choice when the business wants faster standardization across sites and does not want to keep building internal capability for hosting, patching, monitoring, backup, and disaster recovery. The vendor runs the platform. Your team still owns configuration choices, master data discipline, user access, test evidence for intended use, and change control around each release.
That trade-off works well for labs that can accept a cleaner operating model. It works poorly for organizations that say they want standardization but still expect every site, method family, or business unit to preserve old exceptions.
SaaS is often the right fit when:
- IT support is thin: Informatics and infrastructure teams cannot absorb another heavily managed application.
- Sites need to work from one operating model: Global access, common workflows, and shared data matter more than local variation.
- The lab can adapt process where it makes sense: Configuration is acceptable, but code-level customization is not the default answer.
- Release governance is mature: The business can review vendor changes, test impact, and approve updates on a predictable cadence.
There is also a TCO advantage, but it should be stated transparently. SaaS can reduce infrastructure and administration costs. It does not remove validation work, integration effort, data stewardship, or business ownership. Those costs stay. They just move.
Where private cloud earns its keep
Private cloud makes sense when infrastructure control is tied to a real business or regulatory need, not just institutional habit. I usually see a solid case when the company has strict network segmentation rules, customer-driven hosting constraints, region-specific data handling requirements, or legacy integrations that depend on tight control over timing and architecture.
Private cloud can also help when the internal platform team is strong enough to run it properly. That means patching on schedule, documenting changes, supporting qualification, maintaining monitoring, and handling incidents without creating a queue that slows the lab down. If that team is not in place, private cloud often turns into a more expensive version of on-premises complexity.
Hybrid models sit in the middle. They are common during transition, especially where instruments, historians, MES, or restricted environments cannot move at the same pace. Hybrid can be practical. It can also preserve duplicate controls, duplicate integrations, and duplicate validation effort longer than planned.
Here is the comparison that usually matters most in procurement and in operations.
| Criterion | SaaS (Software-as-a-Service) | Private Cloud (IaaS/PaaS) | Hybrid Cloud |
|---|---|---|---|
| Deployment speed | Faster in most cases | Slower, with more setup decisions | Moderate, depends on scope split |
| IT responsibility | Lower day-to-day platform burden | Higher internal ownership | Shared, often harder to coordinate |
| Infrastructure control | Limited | Higher | Mixed |
| Validation model | Shared responsibility, customer validates intended use | More customer-owned evidence and control | Split across environments |
| Update management | Vendor-led release schedule | Customer-managed or tightly coordinated | Mixed, with more governance overhead |
| Cost pattern | Subscription plus implementation and support | Infrastructure, platform, support, and internal labor | Combined costs across both models |
| Best fit | Standardization, speed, multi-site scale | Control-driven requirements with strong internal capability | Phased transitions or segmented estates |
A private cloud deployment can satisfy a security review and still fail operationally if the lab waits weeks for environment changes, interface fixes, or validation support.
The hardest enterprise question is rarely deployment in isolation. It is whether the chosen model makes migration and long-term ownership easier or harder. SaaS can force useful discipline during migration because teams must rationalize workflows, retire weak customizations, and clean data definitions before go-live. Private cloud can reduce disruption for some legacy integrations, but it also makes it easier to carry old complexity into the new environment.
That matters for validation too. In a SaaS model, release cadence is part of the operating reality, so regression testing and impact assessment must be lightweight, repeatable, and tied to intended use. In a private cloud model, the organization gets more control over timing, but it also inherits more documentation, more environment management, and more accountability when something breaks.
The same logic applies to cost. Buyers often compare subscription fees to infrastructure spend and stop there. A better TCO model includes internal labor for vendor management, validation cycles, interface support, security reviews, change control, data remediation, and the inevitable rework caused by unclear ownership. Teams planning an on-premises exit can use guidance from mastering your cloud migration to pressure-test whether the target model reduces complexity or just relocates it.
Choose the model your organization can govern consistently. For many materials labs, that is SaaS with disciplined configuration and a clear validation process. For others, private cloud is justified, but only when the need for control is real and the operating team to sustain it already exists.
Your Migration and Implementation Checklist
The hardest part of adopting a cloud based lims system usually isn't software selection. It's moving years of inconsistent, partially structured, business-critical data without losing traceability. That concern is valid. It's also why migration needs to be treated as an R&D change program, not a one-time IT task.
Recent guidance for regulated environments frames migration and validation as core decision points in cloud LIMS adoption, not side issues. The buyer question is often how to move legacy experiments, methods, and sample histories safely without losing traceability or delaying operations, as discussed in this practical guide to cloud-based LIMS for regulated environments.
Start with data triage not data optimism
Most labs begin by asking how much data they can migrate. The better question is which data should be migrated in a structured form, which should be archived, and which should be left behind because it has no reliable business value.
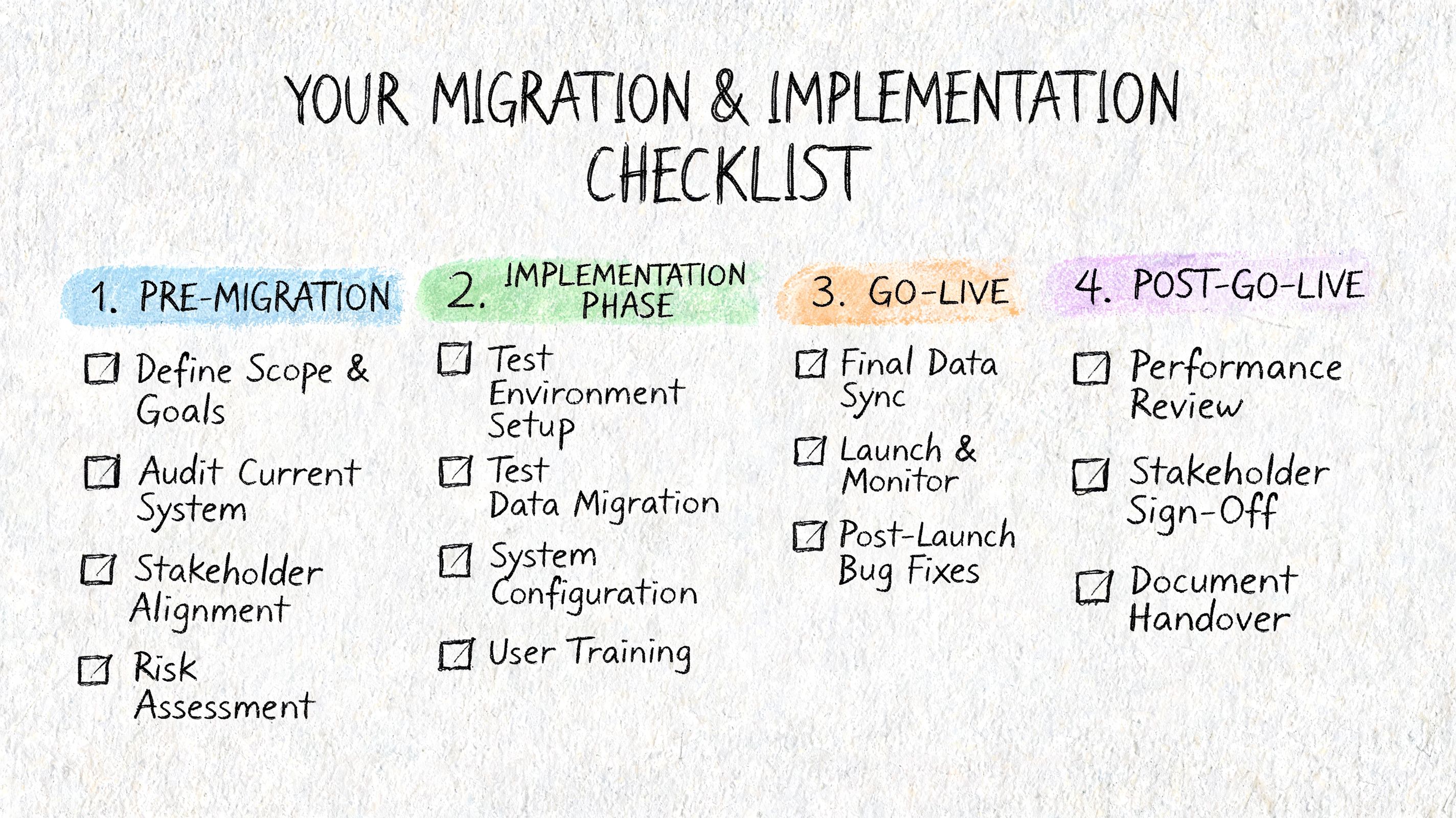
A useful checklist starts here:
Audit current sources Identify every location where sample, method, material, and result data lives. Include spreadsheets, local drives, instrument exports, legacy LIMS tables, and shadow trackers.
Classify by business use
Separate active operational data from historical reference data. Don't force old noise into a clean system just because it exists.Clean master data first
Standardize material names, units, test codes, specification labels, and user roles before bulk migration starts. If “PET Black 20% GF” appears in six variants, the new system will only reproduce confusion faster.Map lineage and traceability rules
Decide what relationships must survive migration. Parent-child samples, batch links, method versions, approvals, and exception records often matter more than raw volume.
For teams planning the broader move from legacy environments, mastering your cloud migration is a useful technical reference because it reinforces the need for phased planning, dependency mapping, and governance instead of lift-and-shift thinking.
Validate the workflow you will run
Migration fails when teams validate the software in abstract but don't validate the process they will use in practice. That gap shows up quickly after go-live.
A better implementation path usually includes:
- Configuration against real use cases: Build around actual sample receipt, formulation, testing, review, and release flows.
- Controlled test scripts: Use representative scenarios with exceptions, rework, and failed runs.
- Phased rollout: Start with one lab, one workflow family, or one business unit before expanding.
- Training by role: Analysts, approvers, admins, and managers need different training and different acceptance criteria.
- Hypercare after go-live: Keep issue triage, data review, and process support active until work stabilizes.
One practical mistake shows up often in materials organizations. Teams try to migrate every historical notebook-style experiment into the new transactional model. That usually creates delay and low trust. A cleaner approach is to migrate critical structured records into the cloud LIMS, preserve traceable archives for the rest, and build clear links between them.
The point of migration isn't to recreate your old mess in a new interface. It's to decide what your future operating model needs, then move only what supports that model with integrity.
Evaluating Vendors and Calculating True ROI
A vendor demo goes well. Scientists like the interface, IT likes the hosting model, and procurement sees a subscription that looks lower than an on-premise replacement. Six months later, the budget discussion changes. Integration work is larger than expected, validation takes longer, historical data needs more cleanup, and every workflow decision now affects multiple labs. That is the point where a cloud based lims system stops being a software purchase and becomes an operating model decision.
Cloud deployment can reduce infrastructure burden and shorten time to value, as noted earlier. What often gets underestimated is simple. Subscription price is only one line item.
For enterprise materials organizations, vendor evaluation should answer two hard questions before contract signature. First, can this platform absorb the messy reality of your data and still support controlled migration and validation? Second, what will it cost to run, govern, integrate, and adapt over the next three to five years?
What to ask before you buy
A serious review tests operating fit under pressure. It should expose where the platform bends, where it breaks, and where you will need services, custom code, or process compromise.
Use a shortlist like this:
- Domain fit: Can the vendor model formulations, batches, specifications, stability studies, and method revisions common in materials science?
- Configuration model: Can internal admins change forms, rules, and workflows without paying the vendor for every update?
- Integration depth: How does the platform connect to instruments, ERP, ELN, QMS, data lakes, and identity management?
- Validation support: What documents, test evidence, release controls, and audit support are available for GxP or other controlled environments?
- Migration practicality: What tools exist for mapping legacy fields, handling incomplete records, and separating active data from archive data?
- Data portability: Can you export records, metadata, attachments, and audit-relevant history in a usable form if you switch vendors?
- Release discipline: How often are updates deployed, how are changes documented, and how much regression testing will your team own?
I also look for one behavior during evaluation. Good vendors are willing to review ugly data samples and messy workflows early. Weak vendors stay at the slideware level and postpone those conversations until after signature.
Buy for the cost of change over time. Materials labs change methods, specifications, and product lines far more often than they replace core systems.
How to think about true TCO
True TCO for a cloud based lims system usually falls into five buckets.
| Cost area | What teams often miss |
|---|---|
| Subscription | User growth, module expansion, storage tiers, sandbox environments |
| Implementation | Configuration workshops, project management, testing, site-by-site rollout |
| Integration | Instrument connectors, middleware, ERP or data platform work, identity and access setup |
| Validation and quality | Script authoring, execution, evidence review, release assessments, revalidation after platform changes |
| Internal operating cost | System ownership, governance, training, support coverage, master data stewardship |
The migration piece deserves its own line of scrutiny, even if it sits inside implementation. In practice, budgets slip during this phase. Legacy sample records often carry inconsistent units, local naming conventions, duplicated methods, and missing context that analysts learned to interpret informally. A cloud LIMS will expose those gaps because structured systems are less forgiving than spreadsheets and shared drives.
That does not mean every old record belongs in the new platform. In many programs, the better financial decision is selective migration. Move active specifications, current methods, open studies, and historically important structured data. Keep low-value legacy content in a traceable archive with clear retrieval rules. That approach reduces conversion effort, shortens validation scope, and avoids paying to clean data no one will use.
ROI gets stronger when the business case reflects avoided waste, not just labor savings.
Repeated testing because prior results cannot be found. Manual review cycles caused by inconsistent metadata. Delays in tech transfer because formulation history sits in disconnected systems. Those costs rarely appear on a software quote, but they show up every quarter in cycle time, compliance effort, and duplicated scientific work.
A credible ROI model for enterprise materials R&D usually combines four elements: reduced local IT burden, lower manual administration, avoided rework from poor traceability, and better reuse of experimental data across programs. If one of those elements depends on a major behavior change, write that assumption down and test it. I have seen too many business cases promise productivity gains that only happen if teams adopt new templates, new review paths, and new governance they were never staffed to maintain.
The strongest vendor choice is usually not the cheapest subscription. It is the platform that fits your science, limits custom code, supports defensible validation, and keeps future change affordable.
The End Goal An AI-Ready Foundation for Innovation
A cloud based lims system is not the finish line. It is the data foundation that makes modern materials R&D possible at enterprise scale. Without that foundation, AI projects usually stall for a familiar reason. The data exists, but it isn't structured, connected, or trustworthy enough to support model building and scientific decision-making.
Structured data changes the pace of R&D
When sample records, method context, material lineage, and analytical outputs live in one controlled environment, teams can do more than retrieve history. They can compare experiments across programs, identify repeated failure patterns, and build datasets that reflect how work was performed.
That matters because materials development depends on context. A tensile result without formulation version, processing condition, and test method rarely helps prediction. A cloud LIMS doesn't create insight by itself, but it creates the precondition for insight by preserving scientific relationships instead of scattering them.
The system of record becomes the system of learning
The direction of the market points the same way. Fortune Business Insights reports that the global LIMS market was valued at USD 1.48 billion in 2025 and is projected to reach USD 2.45 billion by 2034, while Grand View Research notes that vendors are adding AI and machine learning to cloud platforms for real-time data access and automated decision-making, as reflected in Fortune Business Insights coverage of the LIMS market. That's an important shift. The cloud LIMS is becoming the operating layer for intelligent lab work, not just digital recordkeeping.
For enterprise materials teams, the practical implication is straightforward:
- First, centralize and standardize experimental records.
- Then, make them traceable across people, sites, and workflows.
- Then, use that data for prediction, optimization, and next-experiment planning.
If you skip the first two steps, AI becomes a slide deck. If you do them well, years of trial-and-error start becoming a reusable learning system.
The organizations that benefit most won't be the ones with the flashiest models. They'll be the ones that built a clean, governed, connected experimental data backbone early enough to use those models well.
If your team is trying to unify scattered formulation, testing, and scale-up data into an AI-ready R&D backbone, Polymerize is worth evaluating. It's built for enterprise materials organizations that need connected experimental records, governed data infrastructure, and a practical path from lab data capture to predictive materials development.

