Your team probably already has the ingredients for better materials discovery. A few years of ELN records. Spreadsheets from pilot runs. Characterization data that lives in separate folders. A handful of chemists who know which formulation knobs matter, but still spend too much time running experiments that mostly confirm what won't work.
That's the setting where Bayesian optimization becomes useful. Not as a research novelty, and not as a generic AI label, but as a practical way to choose the next experiment with more discipline than trial-and-error. In materials work, where every synthesis and characterization cycle consumes time, instrument access, and specialist attention, that matters.
The promise of Bayesian optimization materials workflows is simple. Learn from each result, estimate where the search space looks promising or uncertain, and use that estimate to decide what to test next. When done well, it turns scattered experimental history into a live decision system that helps formulation teams move faster without pretending the lab is noise-free or the objective is single-variable.
Table of Contents
- Multi-objective work needs ranking logic
- Constraints should be encoded early
- Noise is a modeling input, not a surprise
From Trial and Error to Targeted Innovation
Most formulation programs still run on a recognizable pattern. A scientist adjusts composition, process temperature, mixing time, or curing conditions based on intuition and prior runs. Then the team waits for results, reviews them, and chooses the next set of experiments. It's thoughtful work, but it's also slow, especially when many variables interact and the signal only becomes visible after full characterization.
That approach breaks down when the design space gets wider than a person can reason through consistently. One-factor-at-a-time changes feel safe, but they hide interactions. Grid search looks systematic, but it burns effort on combinations that experienced chemists would never choose if they had better probabilistic guidance.
Bayesian optimization addresses that bottleneck by treating materials development as a sequential decision problem. Instead of asking, “What large matrix of experiments should we schedule this month?” it asks, “Given everything we've learned so far, what is the single most informative next run, or the next small batch?”
Why labs move toward Bayesian optimization
A few things usually trigger adoption:
- Experimental cost is high: Synthesis, conditioning, and characterization aren't cheap in time or attention.
- The response surface is opaque: Teams know the variables but don't know how they combine.
- Data is limited: Many materials programs start with sparse, inconsistent historical records rather than huge datasets.
- Targets are practical, not academic: The goal is a viable formulation, not a perfect global map of chemistry.
Practical rule: Bayesian optimization is most useful when each experiment teaches something expensive.
In materials science, that's exactly where it has shown value. Bayesian optimization has re-emerged as a strong method for reducing the number of experiments needed when training data is limited, and target-oriented methods such as t-EGO have shown superior performance in repeated trials, requiring approximately 1 to 2 times fewer experimental iterations than standard EGO/MOAF strategies to reach the same target property.
The important shift isn't just statistical. It's operational. A team stops treating experimentation as a broad fishing expedition and starts treating each run as an information purchase. That mindset is what makes Bayesian optimization useful in enterprise R&D, where budgets, equipment queues, and project deadlines all force prioritization.
The Core Logic of Bayesian Optimization
Bayesian optimization is easiest to understand if you think like a scientist walking a mountain range in fog. You can't see the full terrain. You only know the elevations at the places you've already visited. Your job is to find a high peak quickly, without wandering blindly.
The method has two core components. First, a surrogate model estimates the objective function from the data you already have. Second, an acquisition function decides where to step next.
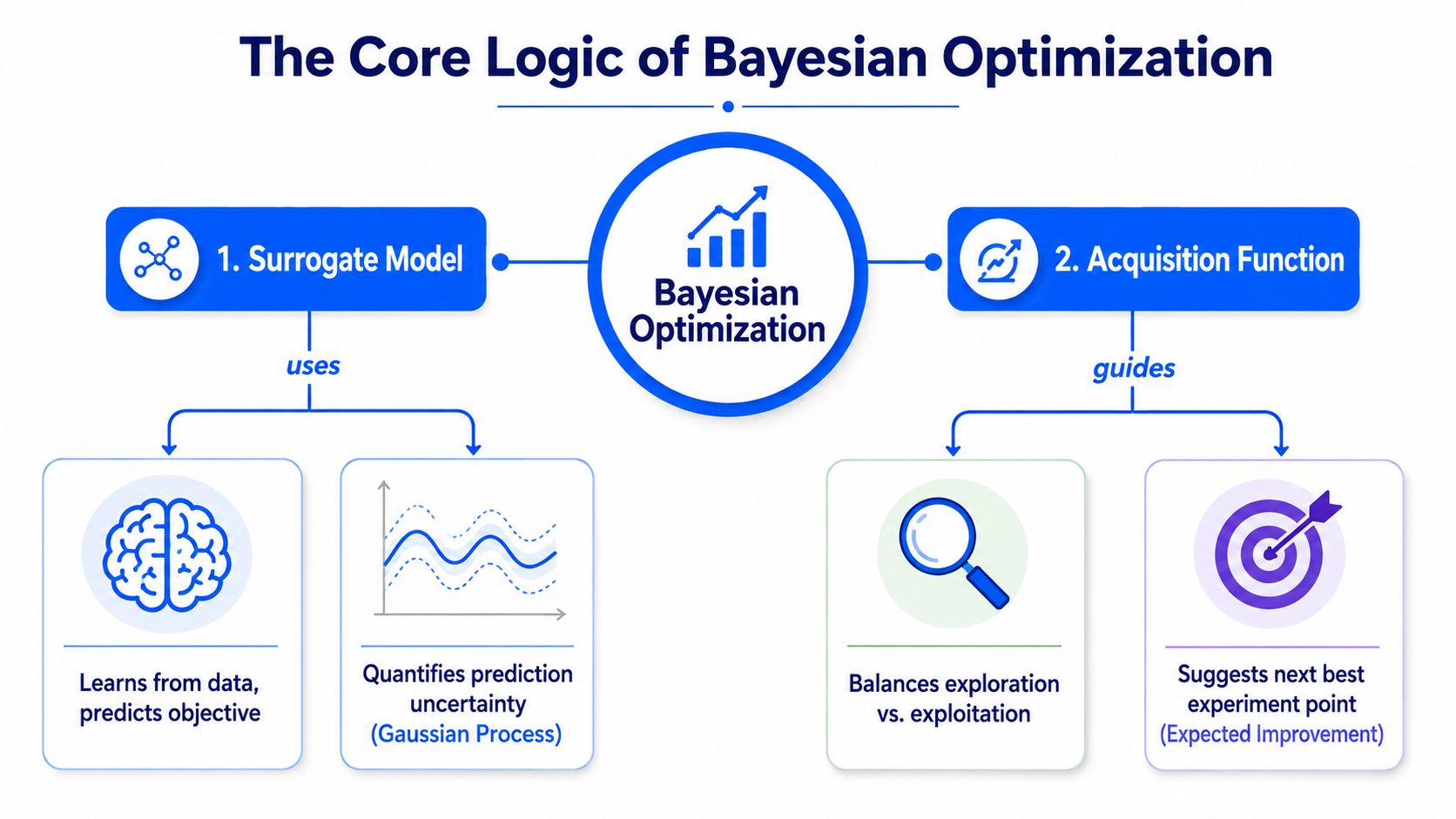
Why the surrogate model matters
In materials work, the actual objective function is usually expensive and messy. It might be tensile strength as a function of monomer ratio, catalyst loading, residence time, and cure profile. It might be conductivity as a function of elemental composition and heat treatment. You can't afford to sample that space densely.
So Bayesian optimization builds an approximation. In many lab settings, that approximation is a Gaussian Process. The practical value of a Gaussian Process isn't just prediction. It gives you a prediction and an uncertainty estimate.
That uncertainty term matters more than most first implementations realize. A plain predictive model can tell you what looks good. A probabilistic surrogate can also tell you where the model is still guessing. In materials discovery, that difference is the line between disciplined exploration and overfitting your last few lucky runs.
A useful way to think about the surrogate model:
| Function | What it does in the lab |
|---|---|
| Prediction | Estimates likely performance for untested formulations or process settings |
| Uncertainty | Highlights where the model has weak coverage or conflicting evidence |
| Generalization | Infers interactions between variables from sparse experiments |
This is why Bayesian optimization works well in limited-data settings. The model doesn't need exhaustive coverage before it starts helping. It starts rough, then gets sharper as new results arrive.
How the acquisition function picks the next run
The acquisition function is the decision layer. It uses the surrogate's predictions and uncertainties to rank candidate experiments. In practical terms, it asks a simple question: should the team test a point that already looks strong, or a point that looks uncertain but potentially valuable?
That is the familiar exploration versus exploitation trade-off.
- Exploitation means pushing into a region that already looks promising.
- Exploration means probing a region where the model's uncertainty is still high.
- Balanced search mixes both, because too much exploitation gets trapped and too much exploration wastes cycles.
A good acquisition function doesn't try to be bold. It tries to be informative.
Bayesian optimization goes beyond predictive analytics. It's not only estimating outcomes. It's actively choosing the next experiment in a black-box optimization process. In target-oriented materials search, BO methods can require approximately 1 to 2 times fewer experimental iterations than standard strategies to reach the same target property, which is the practical reason teams use them in the lab rather than stopping at passive prediction.
The mistake I see most often is treating BO like a one-click recommendation engine. It isn't. The acquisition function only works well when the candidate space is well-defined, the objective is expressed clearly, and the incoming data reflects what was synthesized and measured. When those conditions hold, the method becomes a disciplined experimental planner. When they don't, it just automates confusion.
A Practical Workflow for Materials R&D
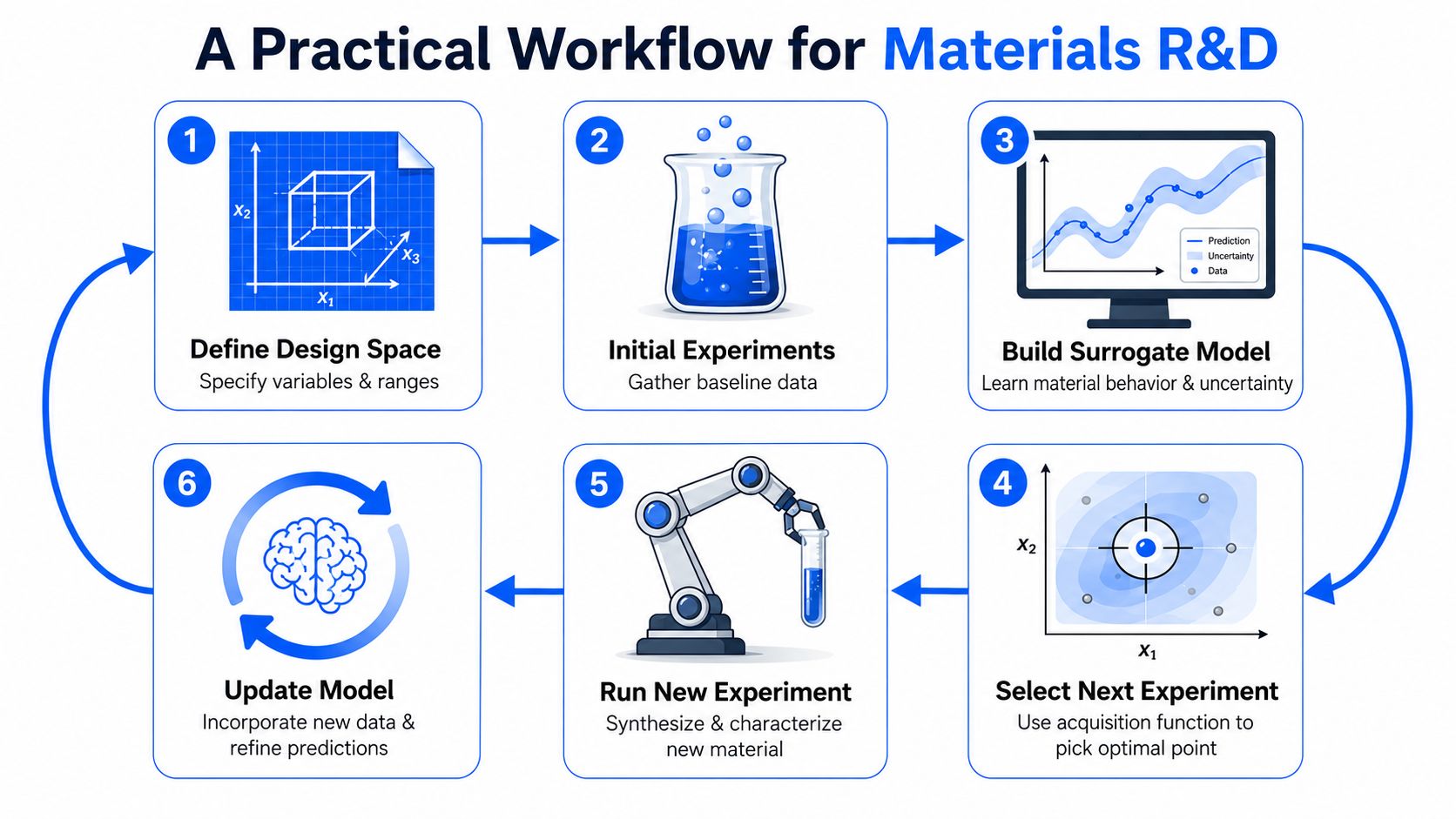
The teams that get value from Bayesian optimization usually keep the workflow simple. They don't start by automating the whole lab. They start by structuring one optimization loop around a real formulation or synthesis problem.
Where teams usually get the setup wrong
The first failure mode is a vague design space. If “polymer A loading” or “cure temperature” isn't bounded cleanly, the optimizer can't make sensible trade-offs. The second failure mode is a noisy objective with no decision rule. If one chemist cares about modulus and another cares about processability, but neither is encoded in the objective, the loop stalls.
A usable workflow starts with a crisp experimental frame:
Define the variables
Choose the controllable inputs. Composition, additives, solvent ratio, temperature, pressure, mixing speed, reaction time, post-treatment.Set realistic bounds
Keep ranges physically and operationally meaningful. Include constraints that match what the plant or lab can run.Choose the objective
Pick one optimization target or an agreed ranking logic for multiple targets.Seed the model with initial experiments
Start with a small, diverse set rather than a dense grid.
That discipline matters because Bayesian optimization isn't replacing scientific judgment. It's formalizing it so the algorithm can work with it.
For teams exploring digitally enabled production environments, the broader context from Ekipa AI manufacturing is useful because it shows how optimization methods fit into wider manufacturing and R&D transformation efforts rather than sitting as isolated modeling projects.
The closed loop in day-to-day lab work
Once the problem is framed, the loop is straightforward.
First, the team runs the seed experiments and fits the initial surrogate model. Then the acquisition function ranks the candidate space and recommends the next experiment. The lab executes that one run, measures the outcome, pushes the data back into the model, and repeats.
Here's the practical sequence most labs can operationalize:
- Seed broadly: Pick initial experiments that cover the design space well enough to avoid a biased starting model.
- Run exactly what was proposed: If the planned condition changes at the bench, log the actual condition, not the intended one.
- Update immediately: The model only improves if new outcomes get captured quickly and correctly.
- Review recommendations with a scientist: Use the algorithm as a recommender, not an unquestioned controller.
A short explainer is worth watching before teams build their first loop:
The impact on experiment count can be substantial in the right setting. In thermoelectric materials optimization across five elemental compositions, Bayesian optimization typically required an order of magnitude fewer experiments than traditional Edisonian search methods to identify optimal formulations, as described by the Dowling Lab's thermoelectric BO work.
The strongest operational benefit isn't that BO finds magic formulations. It stops teams from spending weeks on obviously uninformative runs.
That's also why one-factor-at-a-time methods underperform in modern formulation programs. They're easy to explain, but they don't learn interactions efficiently. Bayesian optimization does.
Handling Complex Constraints and Noisy Data
Real materials programs aren't clean benchmark problems. Objectives conflict. Process windows are narrow. Measurements drift with operator, instrument, and environment. A useful optimization method has to survive those conditions without becoming brittle.
Multi-objective work needs ranking logic
Most enterprise materials projects don't optimize a single property in isolation. A polymer team might care about stiffness, elongation, viscosity, and process stability at the same time. A coating team may want adhesion, cure speed, and surface appearance. In practice, Bayesian optimization handles this best when the team explicitly defines how trade-offs will be judged.
Some groups scalarize multiple objectives into one score. Others use threshold logic, where a candidate only counts if it clears minimum acceptable performance in certain properties. What matters is consistency. If scientists change the ranking rule every review meeting, the optimizer can't accumulate useful preference information.
Constraints should be encoded early
Constraints aren't an inconvenience. They are part of the problem definition.
A few common examples in materials R&D:
- Formulation constraints: Component fractions must sum correctly, or certain ingredients can't exceed a compatibility limit.
- Process constraints: Temperature, pressure, humidity, and residence time have feasible windows.
- Business constraints: Certain feedstocks may be unavailable, restricted, or too risky for scale-up.
- Quality constraints: A candidate with excellent strength but unstable rheology may still be unusable.
When teams encode those constraints upfront, the optimizer searches the region that matters. When they don't, it proposes technically “interesting” but operationally useless experiments.
Field note: If a chemist would reject a proposed experiment immediately on safety, processability, or sourcing grounds, the model should know that before the run is suggested.
Noise is a modeling input, not a surprise
Lab data is noisy. Replicate scatter, sample prep differences, instrument calibration drift, and environmental variation all show up in the measurements. That doesn't invalidate Bayesian optimization. In fact, probabilistic surrogate models are well suited to this reality because they represent uncertainty directly rather than pretending every measured point is exact.
This changes how teams should behave around outliers. Don't overreact to a single unusually strong or weak result. Ask whether the point reflects a real local feature, a process deviation, or a measurement issue. In many cases, the right move is to rerun a nearby condition or add a confirmatory point before changing direction aggressively.
What works in practice is a combination of domain review and statistical humility. The model helps quantify uncertainty. Scientists still need to decide whether a surprising point is discovery, noise, or a logging error.
Case Study Optimizing a Polymer Formulation
A realistic polymer optimization problem usually starts with a mixed objective, not a clean academic one. The team wants stronger mechanical performance, but it also needs acceptable processability and a formulation path that can survive procurement, pilot mixing, and scale-up review.
A realistic polymer search problem
Consider a team developing a polymer blend for a structural adhesive application. They can vary base polymer ratio, plasticizer level, compatibilizer loading, cure package, and cure temperature. The target is to improve tensile performance while keeping the formulation within an internally acceptable cost and processing window.
Without Bayesian optimization, the team would probably begin with expert priors, test a cluster of “safe” formulations, then branch slowly outward. That often produces incremental gains, but it also tends to over-sample familiar regions. Scientists revisit recipes that look chemically comfortable rather than formulations that are maximally informative.
Bayesian optimization changes the rhythm. The team starts with a deliberately varied seed set of experiments, measures the outcome, fits a surrogate, and asks the optimizer for the next candidate. Early recommendations often include points that look slightly counterintuitive to experienced formulators. That's not a flaw. It's the algorithm using uncertainty as part of the search logic.
What the iterations look like in practice
In the first few rounds, the model often explores boundaries. It may test a higher compatibilizer region than the team expected, or a narrower cure band that better separates composition effects from process effects. After a few iterations, the recommendations begin to cluster near a promising region where the model sees both strong response and enough local uncertainty to justify refinement.
A practical loop might look like this:
- Initial phase: Broad formulations establish whether the response surface is smooth, irregular, or strongly interaction-driven.
- Middle phase: The optimizer narrows into a region where composition and curing conditions appear to reinforce one another.
- Late phase: The team runs confirmatory and resilience experiments around the best candidates, checking whether performance holds under realistic variation.
This pattern matches what makes Bayesian optimization useful in synthesis problems more broadly. In materials synthesis optimization, a tuned Gaussian Process Regression approach achieved a 90% probability of identifying the material with maximum physical properties within 13 synthesis trials, outperforming standard algorithms and human experts in search efficiency, according to the reported synthesis benchmark.
For polymer teams, the practical takeaway isn't that every problem will resolve in exactly that number of trials. It's that disciplined sequential learning can compress the search dramatically when the variable space is manageable and the objective is measured consistently.
A good polymer BO program doesn't just identify one strong formulation. It teaches the team which variables are worth controlling tightly and which ones barely matter.
That knowledge carries into scale-up. It tells process engineers where the key sensitivity lives before they commit scarce pilot resources.
Tools and Enterprise Integration Patterns
A Bayesian optimizer can generate strong next-run suggestions in a notebook. The enterprise challenge is getting those suggestions into the lab, capturing what happened, and updating the model without losing context in email threads, spreadsheets, and instrument files.
That operational gap is where many promising BO programs stall.
DIY stacks versus integrated systems
Teams with experienced data scientists often start with open-source Python libraries, internal experiment trackers, and a review layer built around Jupyter notebooks or lightweight apps. That setup gives tight control over kernels, acquisition functions, and custom constraint handling. It also creates ongoing work for the team that has to maintain data pipelines, user permissions, model validation, and audit trails while the science program keeps moving.
The trade-offs are practical, not ideological.
| Approach | Strength | Limitation |
|---|---|---|
| Open-source stack | Flexible, customizable, suitable for specialized workflows | Integration and validation burden sits on the team |
| Internal platform build | Can fit company-specific processes closely | Slow to mature, costly to maintain across groups |
| Enterprise platform | Connects data, models, permissions, and workflow in one environment | Less freedom to reinvent every component |
The deciding factor is usually data discipline. If formulation fields change between projects, assay labels drift across business units, or process metadata is captured only in free text, BO recommendations become hard to trust. A strong surrogate model does not fix weak experimental records.
What enterprise adoption requires
Academic examples often focus on the optimizer itself. Production use depends just as much on workflow design. In materials teams, that means connecting model recommendations to the systems scientists already use, then preserving enough context that another chemist, engineer, or program lead can review why a candidate was proposed and what happened when it was tested.
A workable enterprise pattern usually includes:
- Centralized experimental data: ELN, LIMS, spreadsheet, and instrument outputs need a common backbone.
- Traceable recommendations: Scientists need to see what the model proposed and what was run.
- Explainable outputs: Teams should understand which variables are influencing the recommendation.
- Governance and access control: R&D data is sensitive, and adoption breaks down if IP handling is unclear.
Two integration choices usually matter most. First, decide whether BO will sit beside the lab workflow as an advisory tool or inside it as part of experiment planning and review. Second, decide who owns model performance over time. In a pilot, that is often one computational scientist. In a scaled program, ownership needs to be shared across data, lab, and program teams.
For organizations that do not want to assemble that stack internally, Polymerize is one example of a platform approach. The practical value is not just model execution. It is the ability to connect fragmented materials data, experiment planning, and decision history in the same operating environment scientists already depend on.
The useful question is whether experiment selection, data capture, and model updating can run as one repeatable process. If they can, Bayesian optimization becomes part of how the lab operates rather than another side project that works only when the original champion is available.
Best Practices for Adopting Bayesian Optimization
It is generally not advisable to begin with the hardest problem. Instead, one should start with a constrained, high-value problem where the variables are controllable, the measurements are available, and the scientists already agree on what “better” means.
That first success matters because Bayesian optimization changes behavior as much as it changes model selection. It pushes teams to define objectives clearly, capture data more carefully, and review experiments as part of a learning loop rather than as isolated attempts.
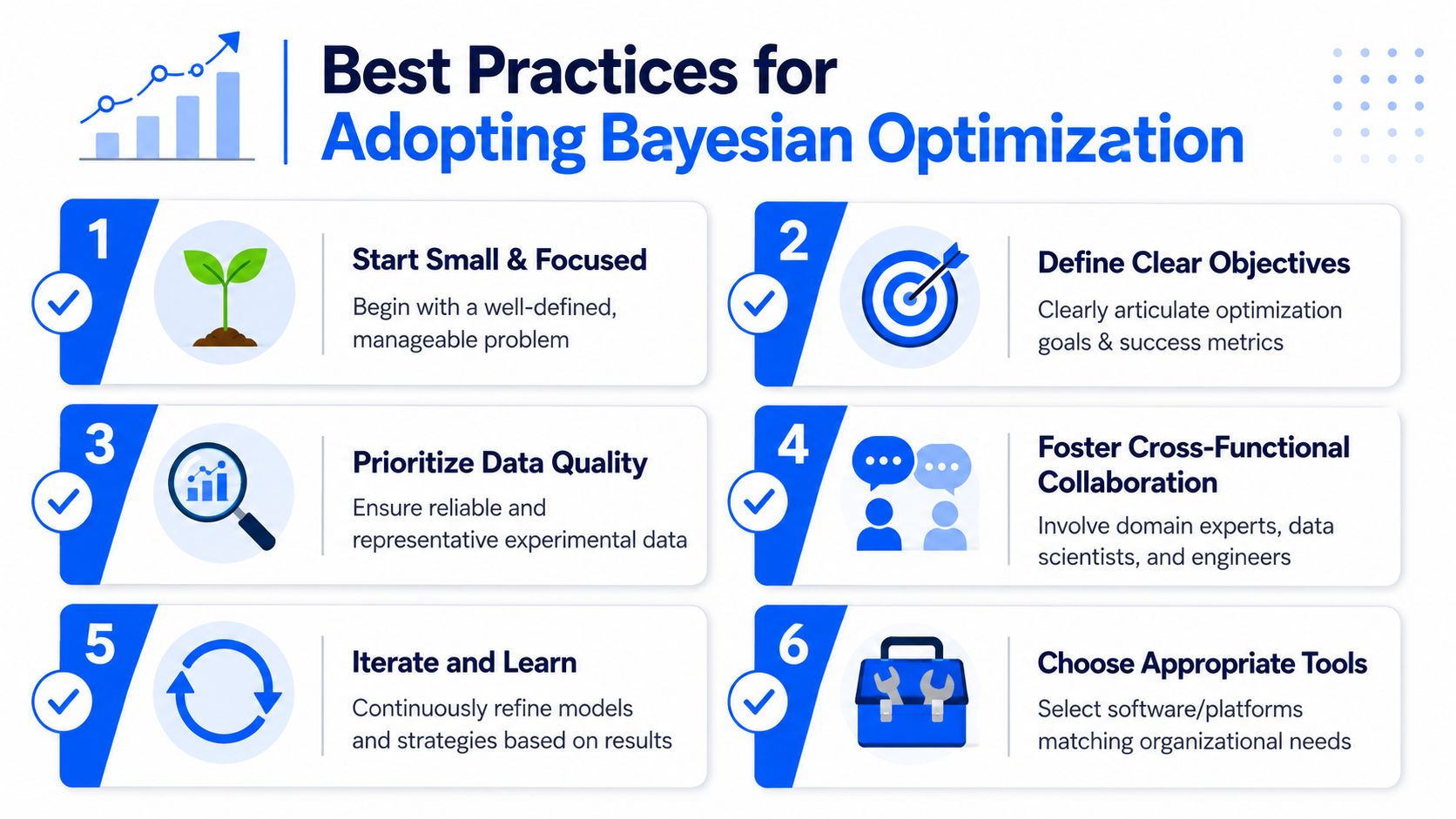
A few adoption practices consistently help:
- Start with one bounded use case: Pick a formulation or synthesis problem with a clear decision owner and manageable variable set.
- Define the objective before modeling: If the team can't agree on the ranking logic, the optimizer won't rescue the program.
- Use the data you already have: Historical records are often imperfect, but they're still useful if cleaned and contextualized.
- Treat noise explicitly: Replicates, uncertainty, and failed runs belong in the learning process, not outside it.
- Keep a scientist in the loop: Recommendations should be reviewed by someone who understands chemistry, process risk, and feasibility.
- Build the data backbone early: Most failures come from fragmented records, not from the BO method itself.
The labs that benefit most aren't the ones with perfect data. They're the ones that create a disciplined feedback loop and improve it quickly.
Bayesian optimization works because it respects the practical economics of materials R&D. Experiments are expensive. Knowledge is incomplete. Progress depends on choosing what to test next with more rigor than intuition alone can provide.
If your team is trying to connect fragmented experimental data with AI-guided experiment planning, Polymerize is worth evaluating as a practical path to operationalize Bayesian optimization inside everyday materials R&D workflows.

